
数学,离一个程序员有多近?原创

作者:小傅哥
博客:https://bugstack.cn
沉淀、分享、成长,让自己和他人都能有所收获!😄
一、前言
数学离程序员有多近?
ifelse也好、for循环也罢,代码可以说就是对数学逻辑的具体实现。所以敲代码的程序员几乎就离不开数学,难易不同而已。
那数学不好就写不了代码吗😳?不,一样可以写代码,可以写出更多的CRUD出来。那你不要总觉得是产品需求简单所以你的实现过程才变成了增删改查,往往也是因为你还不具备可扩展、易维护、高性能的代码实现方案落地能力,才使得你小小年纪写出了更多的CRUD!
与一锥子买卖的小作坊相比,大厂和超级大厂更会注重数学能力。

2004年,在硅谷的交通动脉 101 公路上突然出现一块巨大的广告牌,上面是一道数学题: {e 的连续数字中最先出现的 10 位质数}.com。
广告:这里的 e 是数学常数,自然对数的底数,无限不循环小数。这道题的意思就是,找出 e 中最先出现的 10 位质数,然后可以得出一个网址。进入这个网址会看到 Google 为你出的第二道数学题,成功解锁这步 Google 会告诉你,我们或许是”志同道合“的人,你可以将简历发到这个邮箱,我们一起做点改变世界的事情。
计算 e 值可以通过泰勒公式推导出来:e^x≈1 + x + x^2/2! + x^3/3! +……+ x^n/n! (1) 推导计算过程还包括埃拉托色尼筛选法(the Sieve of Eratosthenes)、线性筛选法的使用。感兴趣的小伙伴可以用代码实现下。
二、把代码写好的四步
业务提需求、产品定方案、研发做实现。最终这个系统开发的怎么样是由三方共同决定的!
- 地基挖的不好,楼就盖不高
- 砖头摆放不巧,楼就容易倒
- 水电走线不妙,楼就危险了
- 格局设计不行,楼就卖不掉
这里的地基、砖头、水电、格局,对应的就是,数据结构、算法逻辑、设计模式、系统架构。从下到上相互依赖、相互配合,只有这一层做好,下一层才好做!
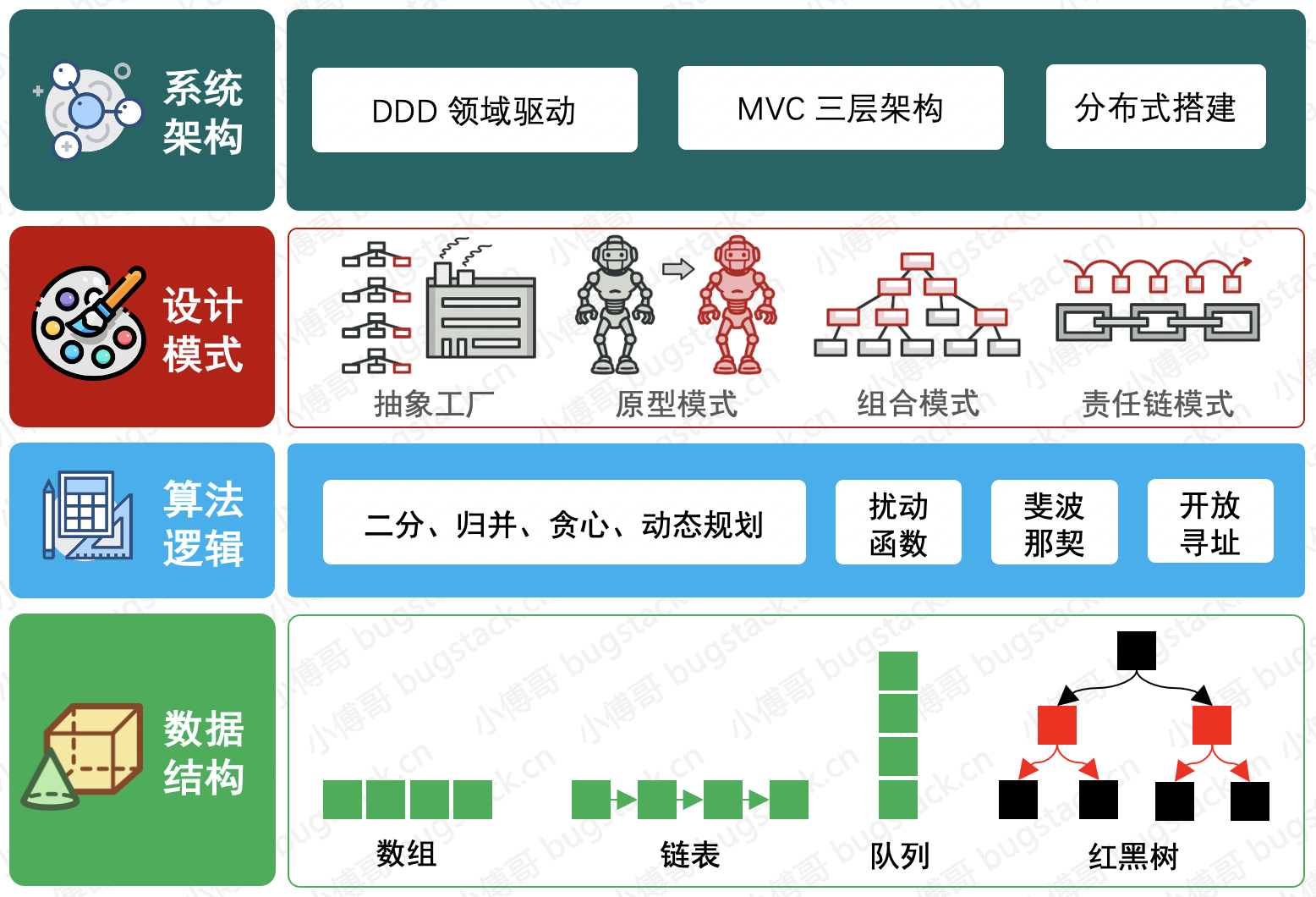
- 数据结构:高矮胖瘦、长宽扁细,数据的存放方式,是一套程序开发的核心基础。不合理的设计往往是从数据结构开始,哪怕你仅仅是使用数据库存放业务信息,也一样会影响到将来各类数据的查询、汇总等实现逻辑的难易。
- 算法逻辑:是对数据结构的使用,合适的数据结构会让算法实现过程降低时间复杂度。可能你现在的多层for循环在合适的算法过程下,能被优化为更简单的方式获取数据。注意:算法逻辑实现,并不一定就是排序、归并,还有你实际业务的处理流程。
- 设计模式:可以这么说,不使用设计模式你一样能写代码。但你愿意看到满屏幕的ifelse判断调用,还是喜欢像膏药一样的代码,粘贴来复制去?那么设计模式这套通用场景的解决方案,就是为你剔除掉代码实现过程中的恶心部分,让整套程序更加易维护、易扩展。就是开发完一个月,你看它你还认识!
- 系统架构:描述的是三层MVC,还是四层DDD。我对这个的理解就是家里的三居还是四局格局,MVC是我们经常用的大家都熟悉,DDD无非就是家里多了个书房,把各自属于哪一个屋子的摆件规整到各自屋子里。那么乱放是什么效果呢,就是自动洗屁屁马桶🚽给按到厨房了,再贵也格楞子! 好,那么我们在延展下,如果你的卫生间没有流出下水道咋办?是不这个地方的数据结构就是设计缺失的,而到后面再想扩展就难了吧!
所以,研发在承接业务需求、实现产品方案的时候。压根就不只是在一个房子的三居或者四居格局里,开始随意码砖。
没有合理的数据结构、没有优化的算法逻辑、没有运用的设计模式,最终都会影响到整个系统架构变得臃肿不堪,调用混乱。在以后附加、迭代、新增的需求下,会让整个系统问题不断的放大,当你想用重构时,就有着千丝万缕般调用关系。 重构就不如重写了!
三、for循环没算法快
在《编程之美》一书中,有这样一道题。求:1~n中,1出现的次数。比如:1~10,1出现了两次。
1. for 循环实现
long startTime = System.currentTimeMillis();
int count = 0;
for (int i = 1; i <= 10000000; i++) {
String str = String.valueOf(i);
for (int j = 0; j < str.length(); j++) {
if (str.charAt(j) == 49) {
count++;
}
}
}
System.out.println("1的个数:" + count);
System.out.println("计算耗时:" + (System.currentTimeMillis() - startTime) + "毫秒");
使用 for 循环的实现过程很好理解,就是往死了循环。之后把循环到的数字按照字符串拆解,判断每一位是不是数字,是就+1。这个过程很简单,但是时间复杂很高。
2. 算法逻辑实现
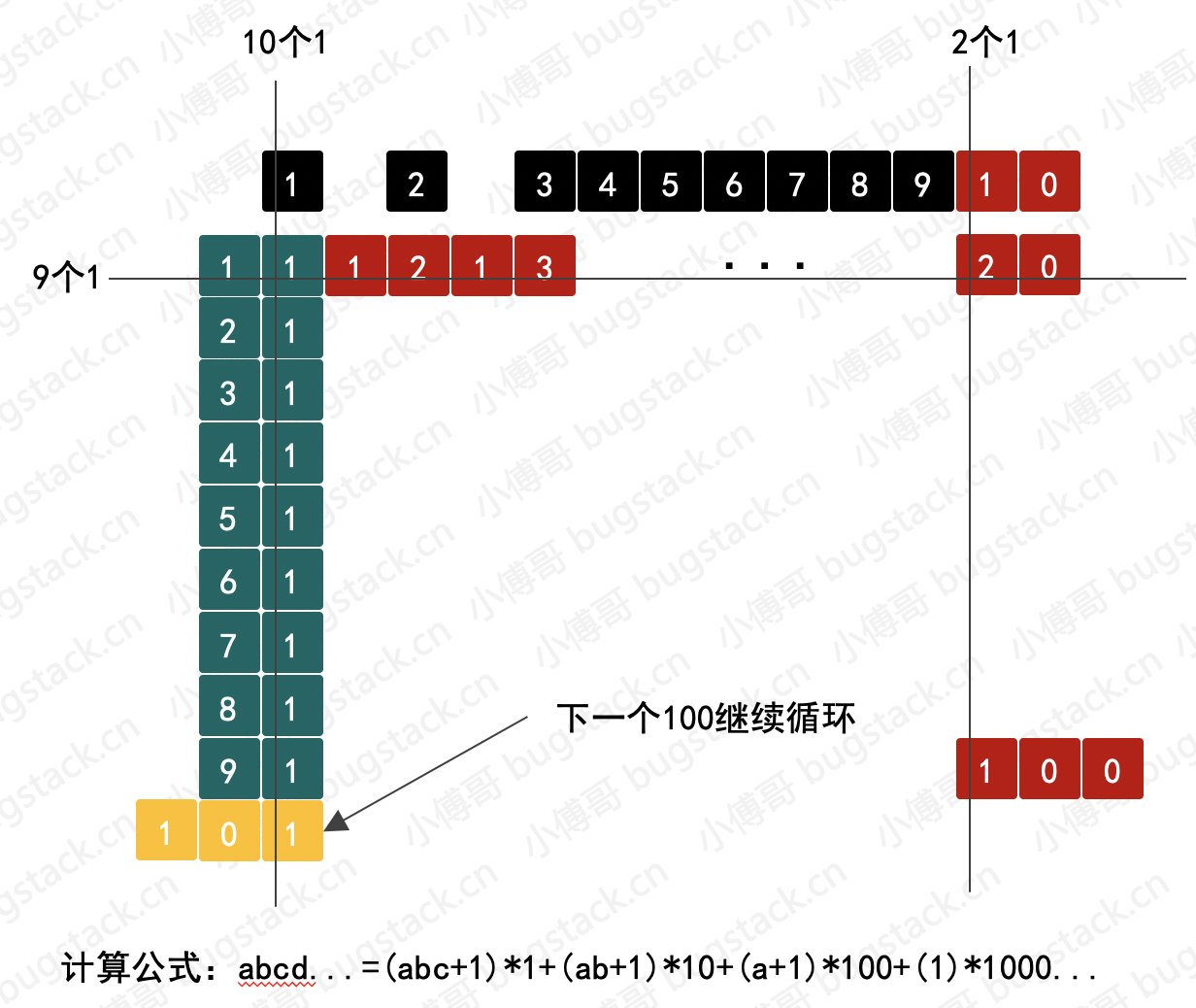
如图 20-3 所示,其实我们能发现这个1的个数在100、1000、10000中是有规则的循环出现的。11、12、13、14或者21、31、41、51,以及单个的1出现。最终可以得出通用公式:abcd...=(abc+1)*1+(ab+1)*10+(a+1)*100+(1)*1000...,abcd代表位数。另外在实现的过程还需要考虑比如不足100等情况,例如98、1232等。
实现过程
long startTime = System.currentTimeMillis();
int num = 10000000, saveNum = 1, countNum = 0, lastNum = 0;
int copyNum = num;
while (num != 0) {
lastNum = num % 10;
num /= 10;
if (lastNum == 0) {
// 如果是0那么正好是少了一次所以num不加1了
countNum += num * saveNum;
} else if (lastNum == 1) {
// 如果是1说明当前数内少了一次所以num不加1,而且当前1所在位置
// 有1的个数,就是去除当前1最高位,剩下位数,的个数。
countNum += num * saveNum + copyNum % saveNum + 1;
} else {
// 如果非1非0.直接用公式计算
// abcd...=(abc+1)*1+(ab+1)*10+(a+1)*100+(1)*1000...
countNum += (num + 1) * saveNum;
}
saveNum *= 10;
}
System.out.println("1的个数:" + countNum);
System.out.println("计算耗时:" + (System.currentTimeMillis() - startTime) + "毫秒");
在《编程之美》一书中还不只这一种算法,感兴趣的小伙伴可以查阅。但自己折腾实现后的兴奋感更强哦!
3. 耗时曲线对比
按照两种不同方式的实现逻辑,我们来计算1000、10000、10000到一个亿,求1出现的次数,看看两种方式的耗时曲线。
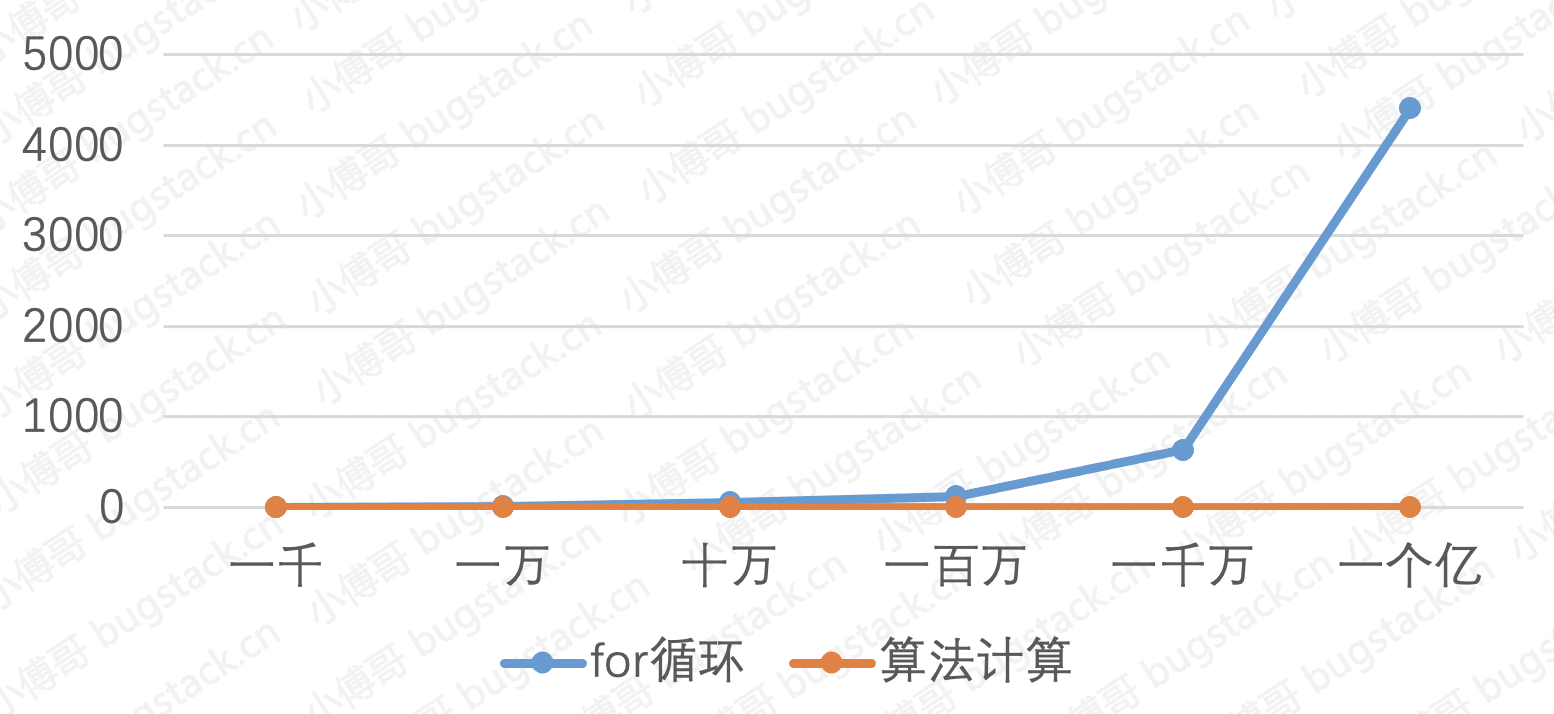
- for循环随着数量的不断增大后,已经趋近于无法使用了。
- 算法逻辑依靠的计算公式,所以无论增加多少基本都会在1~2毫秒内计算完成。
那么,你的代码中是否也有类似的地方。如果使用算法逻辑配合适合的数据结构,是否可以替代一些for循环的计算方式,来使整个实现过程的时间复杂度降低。
四、Java中的算法运用
在 Java 的 JDK 实现中有很多数学知识的运用,包括数组、链表、红黑树的数据结构以及相应的实现类ArrayList、Linkedlist、HashMap等。当你深入的了解这些类的实现后,会发现它们其实就是使用代码来实现数学逻辑而已。就像你使用数学公式来计算数学题一样
接下来小傅哥就给你介绍几个隐藏在我们代码中的数学知识。
1. HashMap的扰动函数
未使用扰动函数

已使用扰动函数

扰动函数公式
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- 描述:以上这段代码是HashMap中用于获取hash值的扰动函数实现代码。HashMap通过哈希值与桶定位坐标 那么直接获取哈希值就好了,这里为什么要做一次扰动呢?
- 作用:为了证明扰动函数的作用,这里选取了10万单词计算哈希值分布在128个格子里。之后把这128个格子中的数据做图表展示。从实现数据可以看到,在使用扰动函数后,曲线更加平稳了。那么,也就是扰动后哈希碰撞会更小。
- 用途:当你有需要把数据散列分散到不同格子或者空间时,又不希望有太严重的碰撞,那么使用扰动函数就非常有必要了。比如你做的一个数据库路由,在分库分表时也是尽可能的要做到散列的。
2. 斐波那契(Fibonacci)散列法
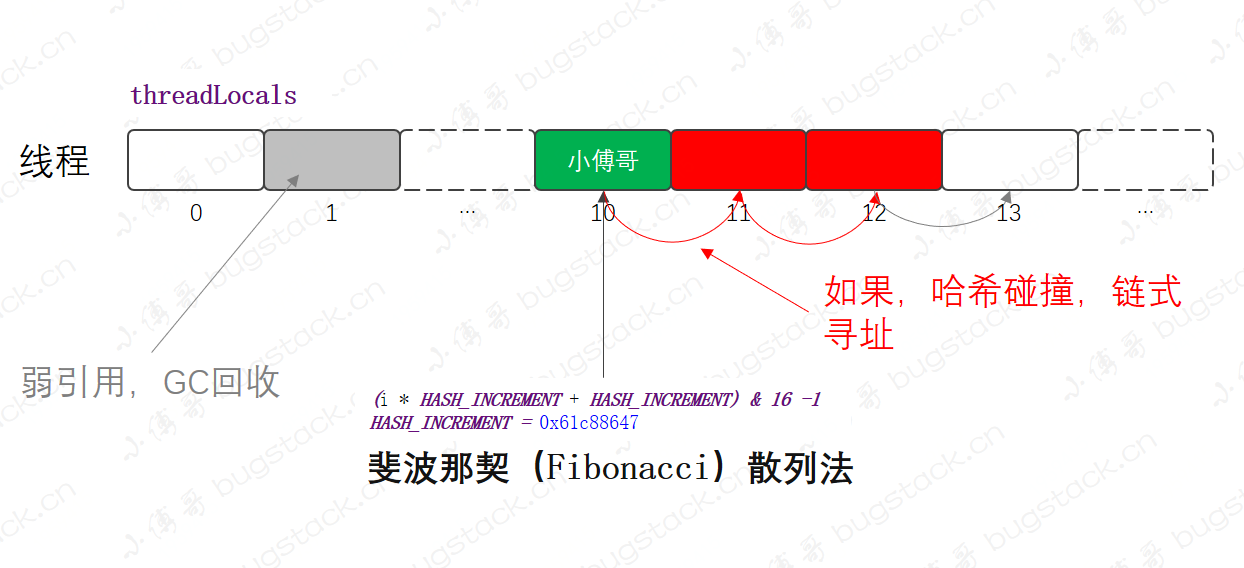
- 描述:在 ThreadLocal 类中的数据存放,使用的是斐波那契(Fibonacci)散列法 + 开放寻址。之所以使用斐波那契数列,是为了让数据更加散列,减少哈希碰撞。具体来自数学公式的计算求值,公式:
f(k) = ((k * 2654435769) >> X) << Y对于常见的32位整数而言,也就是 f(k) = (k * 2654435769) >> 28 - 作用:与 HashMap 相比,ThreadLocal的数据结构只有数组,并没有链表和红黑树部分。而且经过我们测试验证,斐波那契散列的效果更好,也更适合 ThreadLocal。
- 用途:如果你的代码逻辑中需要存储类似 ThreadLocal 的数据结构,又不想有严重哈希碰撞,那么就可以使用 斐波那契(Fibonacci)散列法。其实除此之外还有,
除法散列法、平方散列法、随机数法等。
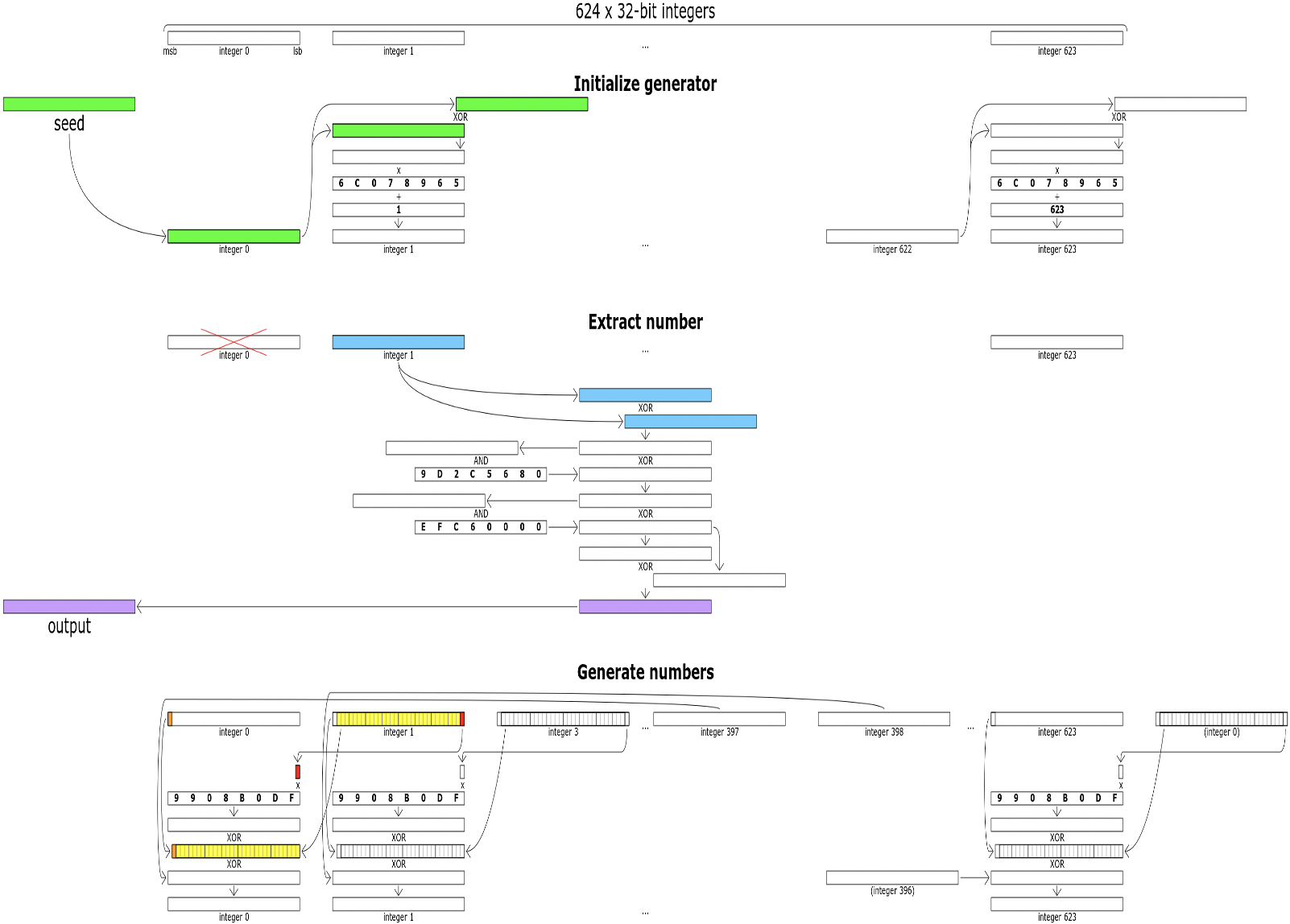
3. 梅森旋转算法(Mersenne twister)
// Initializes mt[N] with a simple integer seed. This method is
// required as part of the Mersenne Twister algorithm but need
// not be made public.
private final void setSeed(int seed) {
// Annoying runtime check for initialisation of internal data
// caused by java.util.Random invoking setSeed() during init.
// This is unavoidable because no fields in our instance will
// have been initialised at this point, not even if the code
// were placed at the declaration of the member variable.
if (mt == null) mt = new int[N];
// ---- Begin Mersenne Twister Algorithm ----
mt[0] = seed;
for (mti = 1; mti < N; mti++) {
mt[mti] = (MAGIC_FACTOR1 * (mt[mti-1] ^ (mt[mti-1] >>> 30)) + mti);
}
// ---- End Mersenne Twister Algorithm ----
}
梅森旋转算法(Mersenne twister)是一个伪随机数发生算法。由松本真和西村拓士在1997年开发,基于有限二进制字段上的矩阵线性递归。可以快速产生高质量的伪随机数,修正了古典随机数发生算法的很多缺陷。 最为广泛使用Mersenne Twister的一种变体是MT19937,可以产生32位整数序列。
- 描述:梅森旋转算法分为三个阶段,获得基础的梅森旋转链、对于旋转链进行旋转算法、对于旋转算法所得的结果进行处理。
- 用途:梅森旋转算法是R、Python、Ruby、IDL、Free Pascal、PHP、Maple、Matlab、GNU多重精度运算库和GSL的默认伪随机数产生器。从C++11开始,C++也可以使用这种算法。在Boost C++,Glib和NAG数值库中,作为插件提供。
五、程序员数学入门
与接触到一个有难度的知识点学起来辛苦相比,是自己不知道自己不会什么!就像上学时候老师说,你不会的就问我。我不会啥?我从哪问?一样一样的!
代码是对数学逻辑的实现,简单的逻辑调用关系是很容易看明白的。但还有那部分你可能不知道的数学逻辑时,就很难看懂了。比如:扰动函数、负载因子、斐波那契(Fibonacci)等,这些知识点的学习都需要对数学知识进行验证,否则也就学个概念,背个理论。
书到用时方恨少,在下还是个宝宝!
那如果你想深入的学习下程序员应该会的数学,推荐给你一位科技博主 Jeremy Kun 花了4年时间,写成一本书 《程序员数学入门》。
这本书为程序员提供了大量精简后数学知识,包括:多项式、集合、图论、群论、微积分和线性代数等。同时在wiki部分还包括了抽象代数、离散数学、傅里叶分析和拓扑学等。

作者表示,如果你本科学过一些数学知识,那么本书还是挺适合你的,不会有什么难度。书中的前三章是基础数学内容,往后的难度依次递增。
- 书籍获取:关注公众号:bugstack虫洞栈,回复:
程序员数学,下载这本书 - 在线Wiki:https://jeremykun.com/primers/
六、总结
- Programming is one of the most difficult branches of applied mathematics; the poorer mathematicians had better remain pure mathematicians. https://www.cs.utexas.edu/users/EWD/transcriptions/EWD04xx/EWD498.html
- 单纯的只会数学写不了代码,能写代码的不懂数学只能是CRUD码农。数学知识帮助你设计数据结构和实现算法逻辑,代码能力帮你驾驭设计模式和架构模型。多方面的知识结合和使用才是码农和工程师的主要区别,也是是否拥有核心竞争力的关键点。
- 学习知识有时候看不到前面的路有多远,但哪怕是个泥坑,只要你不停的蠕动、折腾、翻滚,也能抓出一条泥鳅。
知识的路上是发现知识的快乐,还学会知识的成就感,不断的促使你前行。



