
如何使用Eclipse内存分析工具定位内存泄漏原创
本文以我司生产环境Java应用内存泄漏为案例进行分析,讲解如何使用Eclipse的MAT分析定位问题
背景
11月10号晚上8点收到报警邮件,一看是OOM
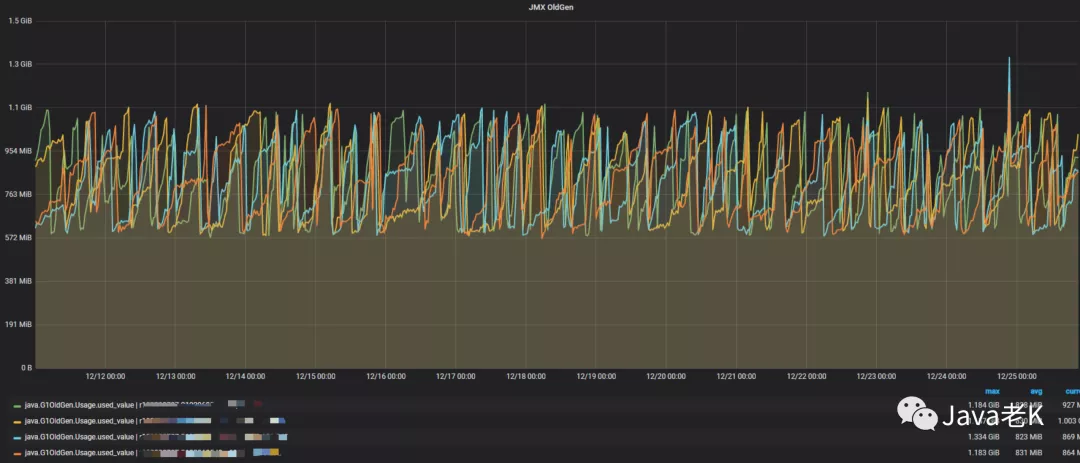
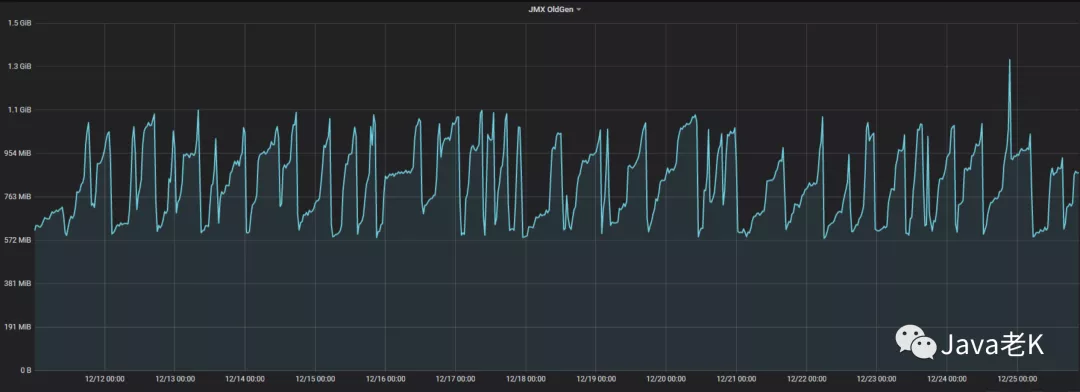
打开公司监控系统查看应用各项指标发现JVM中老年代在持续增长(从上次发布10月30号到11月10号的12天内一直在增长, 存在内存泄漏迹象)
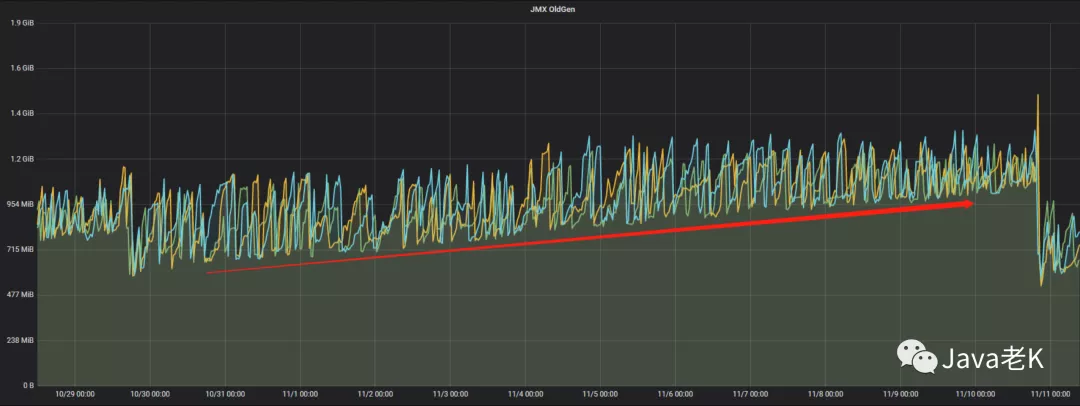
从图中可以看出, 从10月30号发布到11月10号oom期间11天老年代一直在缓慢上涨, 虽然有下降, 但整体趋势是上升的,平均每天泄漏约50M内存, 说明每次都无法完全释放干净
因为生产环境的JVM添加了 -XX:+HeapDumpOnOutOfMemoryError 参数,该配置会把dump文件的快照保存下来供后续分析排查问题,也可以使用jmap或jcmd等jvm命令进行dump:
jmap -dump:format=b,file=文件名 [pid]
jcmd pid GC.heap_dump 文件路径
分析内存泄漏
内存泄漏和内存溢出的区别:内存泄漏从老年代的增长情况看是缓慢上升的, 最终达到老年代上限才会导致溢出,有些内存泄漏可能需要很长的时间发生, 所以说内存泄漏更隐蔽, 不像内存溢出那样容易暴露(内存溢出直接抛出OOM), 而且内存长时间得不到释放会导致服务性能越来越差、gc时间变长、响应变慢:
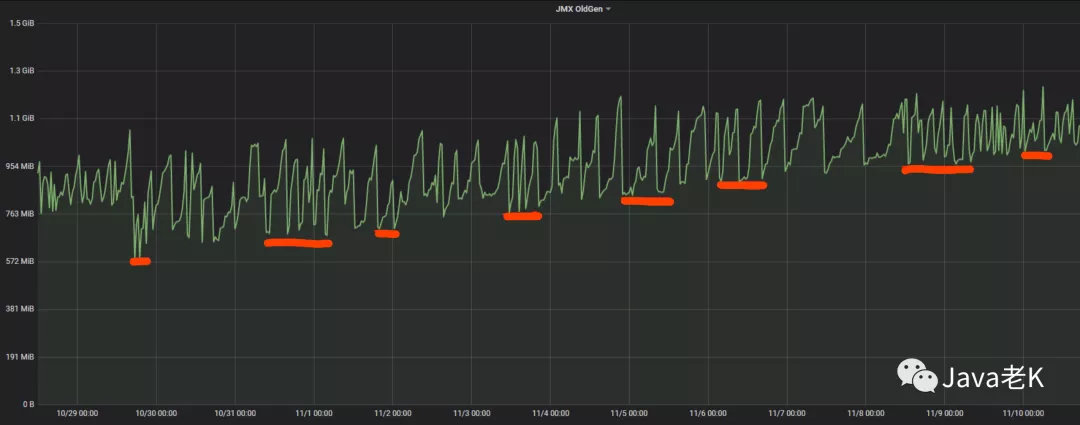
从图中可以看出在12天里每天大概泄漏(增长) 50M 左右, 这种情况下定位泄漏原因需要多次dump采集样本, 然后和上次的比较分析, 即需要多个dump文件进行比较分析才能精确定位问题。 否则很难看出具体泄漏的点, 加上dump文件中大部分是正常的内存使用, 会干扰问题的定位, 增加排查难度。
所以当时的做法是每天固定时间dump一次, 采集足够多的样本, 如下图:
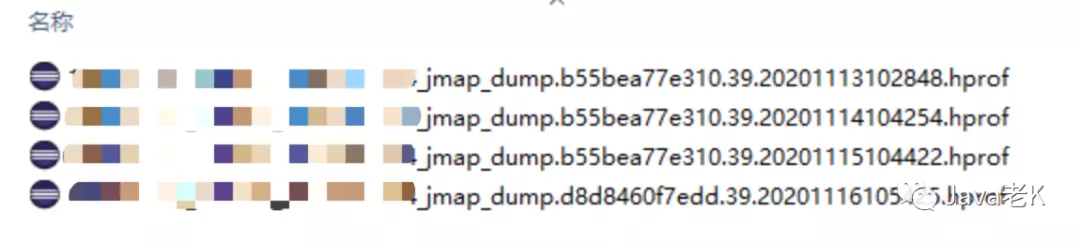
另外测试环境不好重现的主要原因是不清楚是哪个接口调用引起的, 这个Java服务有多个暴露的api, 而且测试环境不方便压测,压测量大了, 底层接口熔断, 压测量小看不出泄漏迹象, 所以得从dump分析入手, 找到问题所在再去测试环境验证。
这里使用Eclipse的memory analysis tool(MAT)工具进行分析
把下载到本地的多个dump文件用mat依次打开(“File → Open Heap Dump”), 如下图:
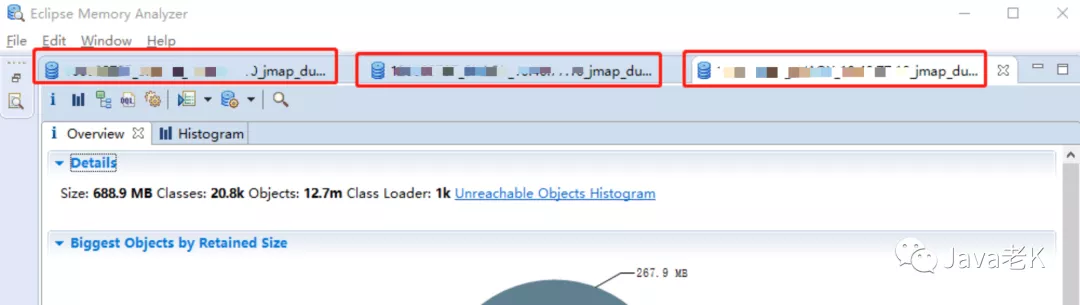
比如我们要分析这3个dump文件(当然你也可以分析更多个, 这样会更精准), 打开后, 使用compare basket功能找出内存泄漏的差异点:
使用 compare basket 功能分析内存泄漏
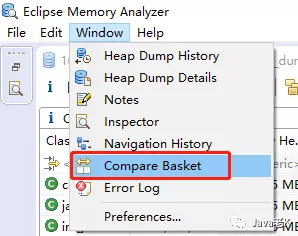
1> 菜单栏 window → compare basket ,打开比较窗口(如果最下面一栏已经有compare basket则这步不需要),如下图:
2> 依次打开3个dump的dashboard面板, 在下方的 Actions一栏点击"histogram"或"dominator tree"生成对应的直方图或支配树列表,如下图:
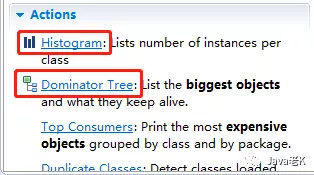
直方图或支配树都可以列出堆中存活的所有对象,但二者的维度不同, 直方图按照类型统计, 支配树是以对象维度统计。
如果你对项目代码比较熟悉, 通过直方图定位内存泄漏会更快,因为它是按照类型全部平铺开的,如果这个项目不是你负责的, 建议使用支配树的方式, 因为支配树包含了对象之间的引用关系(支配树视图可以展开查看内部引用层级)
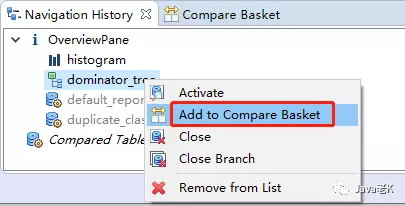
3> 我们以支配树做比对, 在最下面一栏的"Navigation History (window → navigation history)"里(直方图类似)找到在第2步打开的支配树dominator tree图标, 右键添加到compare basket, 如下图:
4> 重复上面的2, 3步骤依次把其他的dump文件添加到"compare basket"栏, 然后点击右上角的红色感叹号, 生成比较结果,如下图:

(注意比较的dump文件的顺序,时间最早的在上面,可以通过右上角的上箭头↑和下箭头↓调整顺序)
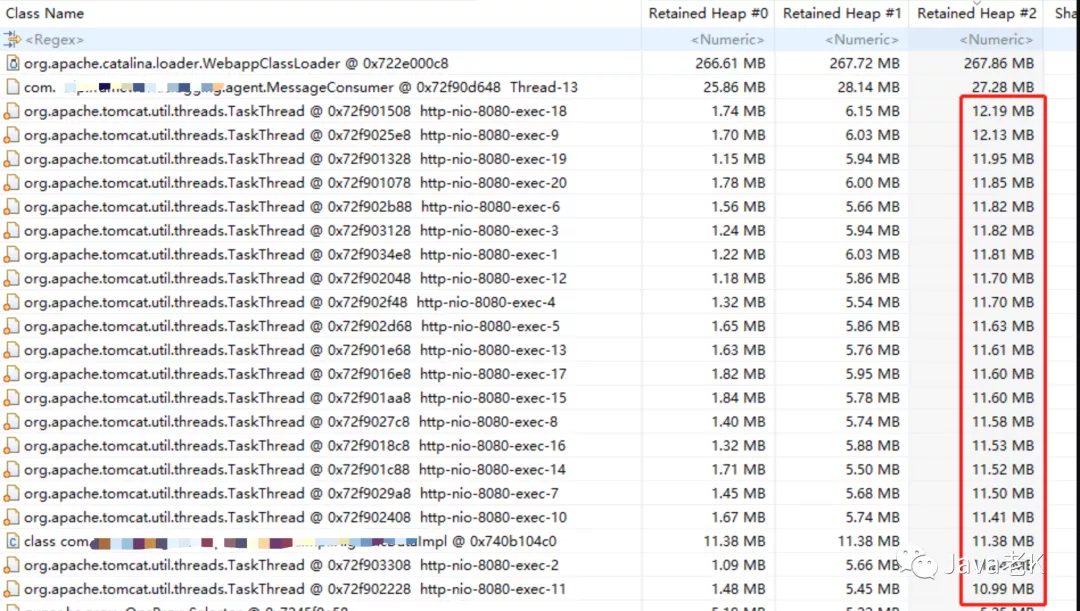
生成的比对结果如下:
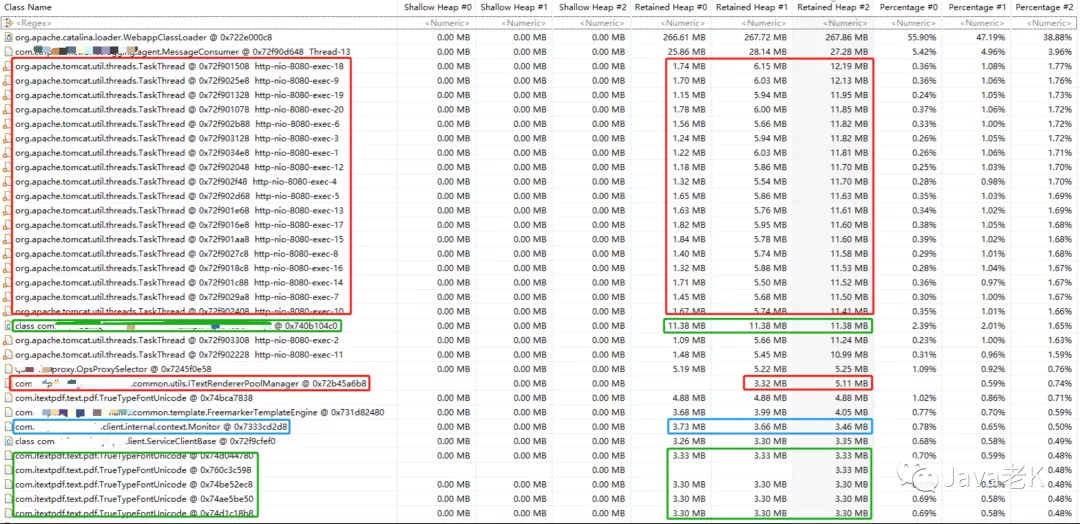
Shallow Heap一列后面的序号 #0, #1, #2 分别对应:
第一个dump文件占用的shallow size, 第二个dump文件占用的shallow size , 第三个dump文件占用的shallow size
Retained Heap #0, Retained Heap #1, Retained Heap #2 这3列分别对应:
第一个dump文件占用的retained size, 第二个dump文件占用的retained size , 第三个dump文件占用的retained size
通过Retained Heap的变化趋势可以看出:
-
红框 圈出的是内存连续增长的对象, 可以通过右边红框的retained heap看出内存变大的趋势
-
绿框 圈出的是没有变化的对象(至少在这3次比较中没有变化)
-
蓝框 圈出的是内存占用下降的对象
一般我们主要关注红框标出的对象, 因为这部分发生内存泄漏的嫌疑最大
这里先区分两个概念:
Shallow Size
-
对象自身占用的内存大小,不包括它引用的对象。
-
针对非数组类型的对象,它的大小就是对象与它所有的成员变量大小的总和。
-
针对数组类型的对象,它的大小是数组元素对象的大小总和。
Retained Size
-
Retained Size=当前对象大小+当前对象可直接或间接引用到的对象的大小总和。(间接引用的含义:A->B->C, C就是间接引用)
-
Retained Size就是当前对象被GC后,从Heap上总共能释放掉的内存。
因为这里我们比较的是支配树, 所以按照retained heap倒序排列, 从左到右依次为: retained heap #0 → retained heap #1 → retained heap #2(以最后一个retained heap #2 倒序, 因为这个是最后一次dump的内存快照, 这样可以看出内存泄漏的增长趋势)
定位内存泄漏
基于上一步得出的比较结果, 可以看出"org.apache.tomcat.util.threads.TaskThread http-nio-8080-exec-*" 有内存泄漏的嫌疑, 查看它的引用关系:
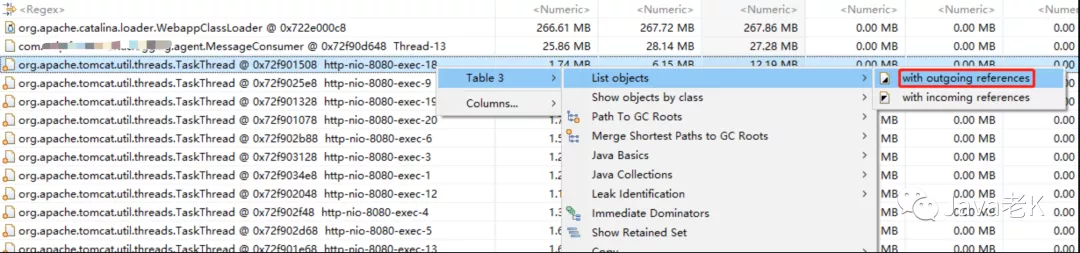
点击"with outgoing references"后逐层展开第一个对象内部的引用关系(以Retained Heap倒序,主要是看retained size排在前面的对象), 如下:
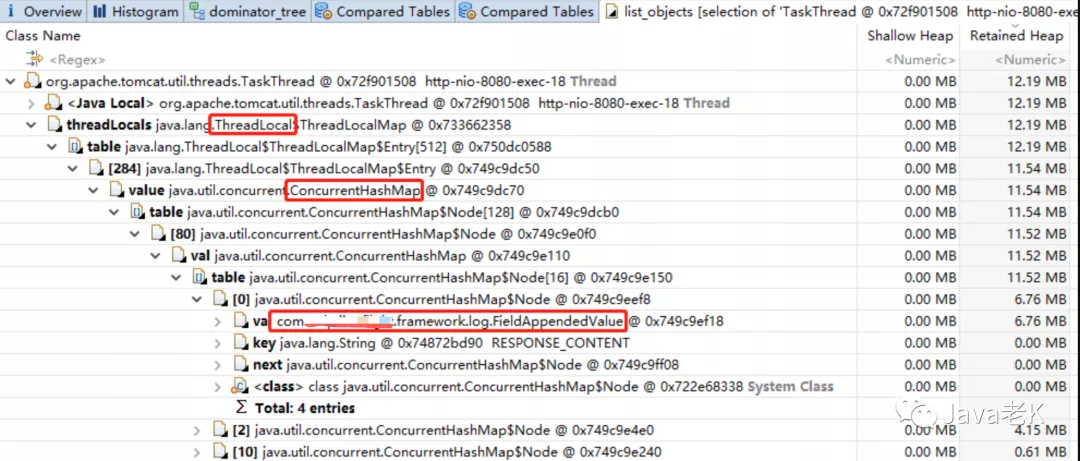
可以看到TaskThead内部有一个threadLocal, threadLocal内部有一个concurrentHashMap,这个map里存的是我们的日志相关对象"com.*.framework.log.FieldAppendedValue",从下面几个map里的key可以确定是我们记录到日志系统(ElasticSearch)的对象, 这些日志对象主要记录调用接口的请求报文、响应报文、SOA接口名称等信息,如下图:
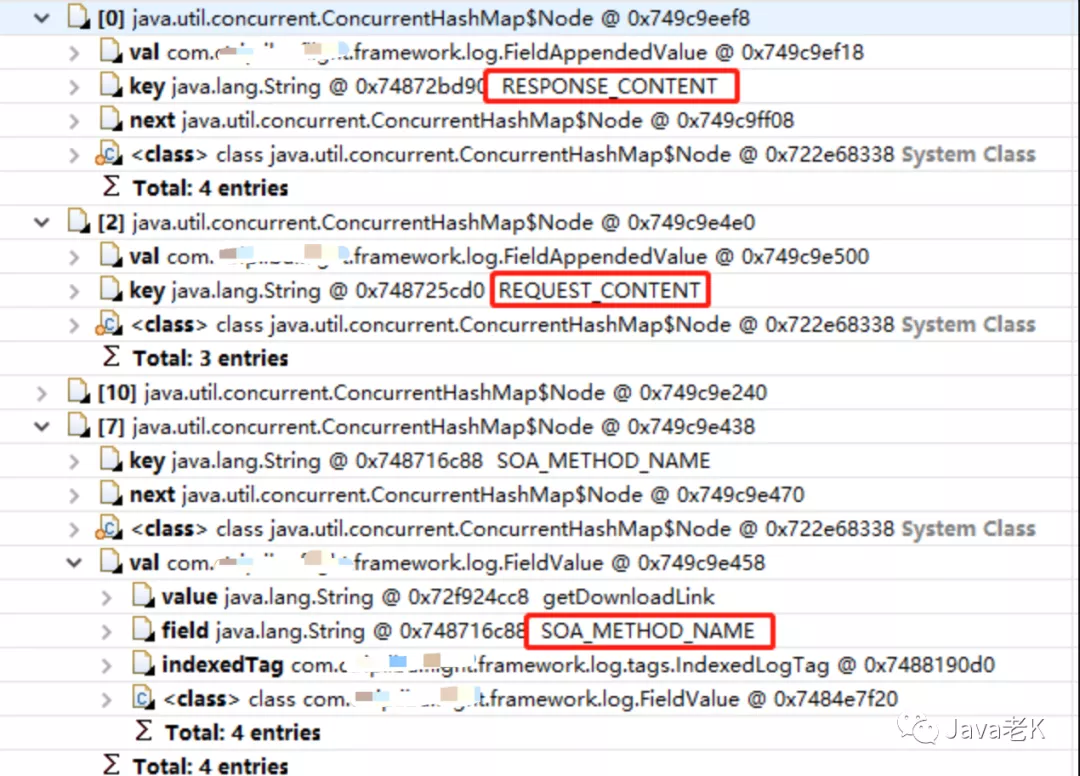
但为什么日志对象会占用这么多内存?而且这里看到的只是其中一个taskThread里,继续展开RESPONSE_CONTENT的val对象FieldAppendedValue内部引用, 如下:

发现FieldAppendedValue内部维护了一个CopyOnWriteArrayList对象, 这个list里竟然存放了10674个值,正常来讲不可能一次接口请求会有这么多的日志对象, 而且接口请求完记录到ES后, 这部分内存就应该释放了才对。
查看CopyOnWriteArrayList内部存储的内容,如下:
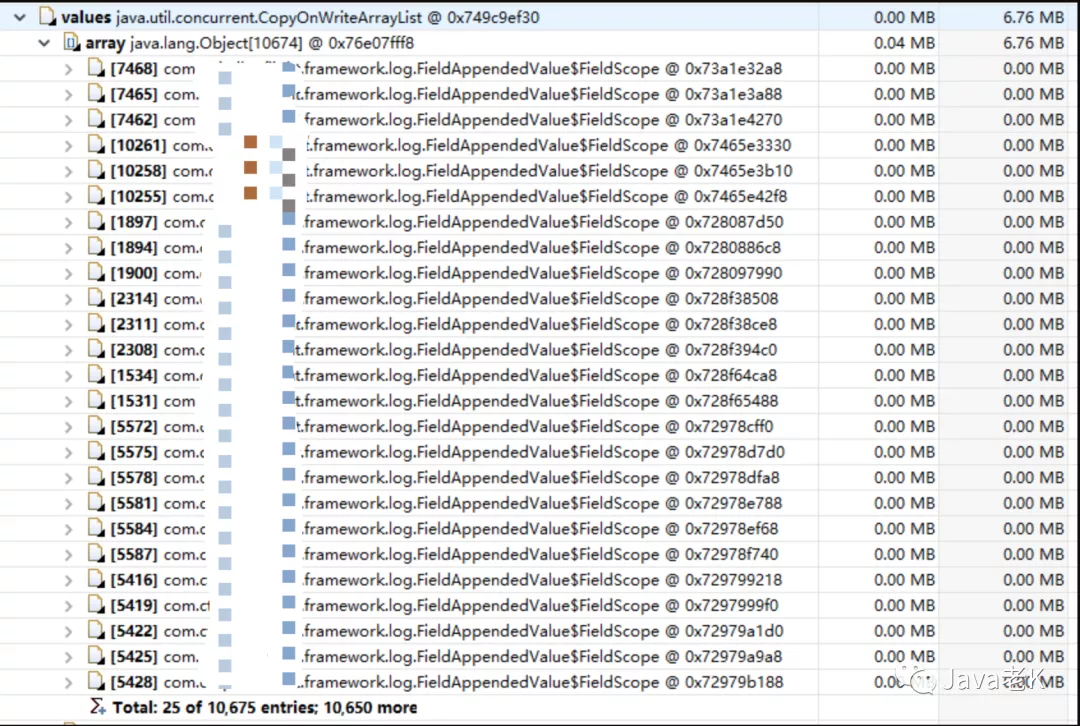
随便打开10675个中的几个FieldAppendedValue, 发现内部存放的都是同一个接口的请求响应报文,如下图:

可以右键copy→ value 把值复制出来查看, 接口报文如下:(响应报文)
{
"ResponseStatus": {
"Timestamp": "/Date(1605583909438+0800)/",
"Ack": "Success",
"Errors": [],
"Build": null,
"Version": null,
"Extension": []
},
"downloadUrl": "https://ii066.cn/hFGBEW"
}
从上面那张concurrentHashMap截图(key : SOA_METHOD_NAME) 可知这个接口名是: getDownloadLink, 也就是说list里10675个日志对象存的都是"getDownloadLink"这个接口的报文。而且这只是其中一个TaskThead内部情况, 加上全部20个对象, 20 * 10675 大概是213500个接口报文,如下图:
这个接口是什么鬼?

代码分析
查看代码得知这个接口并没什么幺蛾子,只是当时的开发同学在调用这个底层接口时新接入了我们部门封装的SOA组件公共类:AbstractSimpleHandler.java(这个公共类主要是通过模板方法在调用接口时记录报文日志埋点、超时时间设置、mock等功能)
这次出现OOM的这个Java项目之前调用soa接口是自己实现了一套公共方法(早于框架之前实现), 也就是说只有这一个接口使用了新的公共类AbstractSimpleHandler,其他的接口调用方式还是原来的方式。
新的工具类AbstractSimpleHandler记录接口报文的代码是通过调用ELKLogUtils.write()实现的, 这个方法的内部大致逻辑如下:
Object value = HttpContext.get(BEHAVIOR_LOG);
if (value == null) {
value = new ConcurrentHashMap<>();
HttpContext.add(BEHAVIOR_LOG, value);
}
HttpContext内部维护的是一个ThreadLocal:
public class HttpContext {
private static final int CONTEXT_DEFAULT_SIZE = 1 << 6;
private static final ThreadLocal<Map<String, Object>> CONTEXT = new ThreadLocal<Map<String, Object>>() {
@Override
protected Map<String, Object> initialValue() {
return new ConcurrentHashMap<>(CONTEXT_DEFAULT_SIZE);
}
};
所有调用soa底层接口的报文日志都是通过ThreadLocal内的map存储的, 然后统一发送到ES日志系统。
我们都知道theadLocal是线程安全的, 但是一般我们的项目都是部署在Tomcat等web容器里, tomcat维护了一个http线程池, 就是前面截图的那个TaskThead Http-nio*线程对象,每次前端app发起请求都会从tomcat的线程池里取一个线程处理前端的请求, 如果复用的是上一个线程, 那他内部的threadLocal没有清空, 还是会保存上次的报文信息,这样的话这次请求又会继续存放接口报文, 就会越积越多。。。
新接入的组件把接口报文存到threadLoacl的代码是在AbstractSimpleHandler.java里的,而清除threadLoacl的代码是在另外一个公共类BaseService.java里做的,也就是说要接入新的公共类除了AbstractSimpleHandler.java外,还要接入BaseService.java 这个公共类!
这个也是有历史原因的, 这个Java项目本身比较早, 那时候还没有我们部门框架的SOA公共类, 所以自己实现了一套,后来使用新的框架组件调用接口的开发小伙伴没有调研全面, 少接了一个公共类(BaseService)导致了这一问题发生。
所以这个问题的根因是threadllocal使用不当引起的内存泄漏
弄清楚原因后就好办了, 解决办法是在请求完接口后主动调用下框架里的HttpContext.clear(), 清除下框架内部的threadlocal.map即可,当然后续还是要统一接口的调用方式, 不能两套工具类并存。
使用 path to gc root 定位业务代码
还有另外一个内存泄漏的嫌疑是"com.*.common.utils.ITextRendererPoolManager", 如上面比对结果的图:

单独在dominator tree支配树视图展开如图所示:
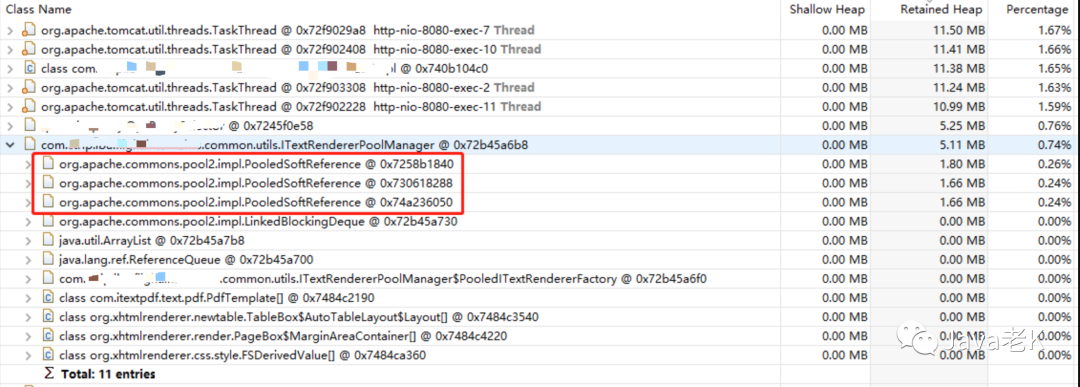
ITextRendererPoolManager内部使用了apache的一个对象缓冲池, 目的可能是为了对象复用, 继续展开,如下图:
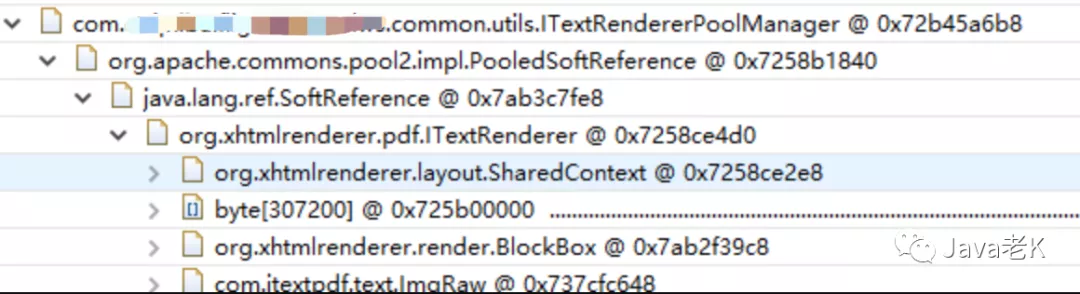
发现是pdf的一个工具类:org.xhtmlrenderer.pdf.ITextRenderer, 这个开源的pdf工具是我们项目的邮件功能在发送附件的时候生成pdf文档时引入的一个第三方jar包,开始怀疑是否是这个开源的pdf工具导致的内存泄漏, 但是不清楚这个jar包是在哪里调用的?
这里可以通过"path to gc root"查看是谁在引用他, 即我们业务代码调用的地方,如下图:
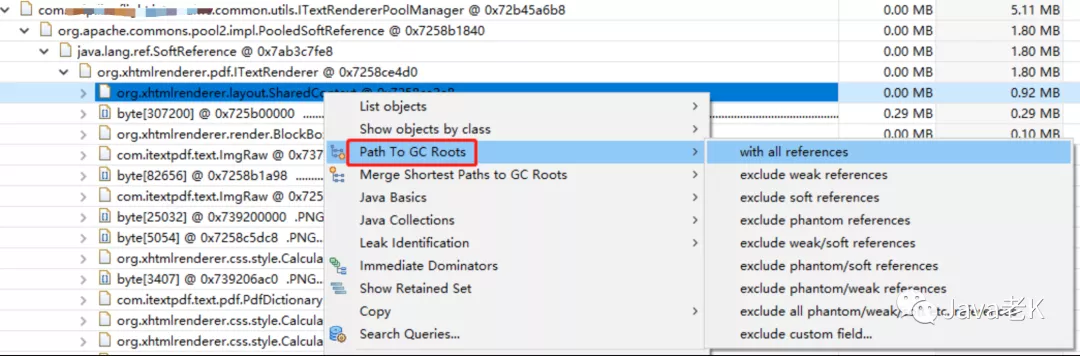
这里先说下"path to gc root"选项的含义:
-
with all references : 所有引用, 包括强引用, 弱引用, 软引用, 虚引用
-
exclude weak reference : 排除弱引用
-
exclude soft reference : 排除软引用
-
。。。。
我们知道软引用, 弱引用这些在发生full gc时可能会被回收掉(回收时机不同, 具体可自行百度), 目的是不造成内存溢出。一般引起内存溢出的都是强引用,所以你可以选择"exclude all ptantom/weak/soft reference"只查看强引用。
但在这个案例中pdf.ITextRenderer是被软引用引用的(从上图中可以看出), 虽然说软引用不会导致溢出, 但可能会引起内存一点点上升(软引用只有在内存不足发生GC时才会被回收), 这个跟本地缓存还不一样, 因为shareContext对象没有达到复用的目的, 而且最重要的是它没有失效机制,只要没有达到堆最大值或发生full gc就会一直存在, 这样的话会拖累JVM的性能,所以我选择"with all references"查看所有类型引用:

发现是被PdfUtil这个类引用, 查看代码发现PdfUtil是我们自己封装的一个pdf工具类, 这个工具类把创建pdf的ITextRenderer对象缓存到了iTextRendererPoolManager对象池里, 这样下次就不需要再重新创建, 代码大致如下:
try (ByteArrayOutputStream outputStream = new ByteArrayOutputStream()) {
iTextRenderer = iTextRendererPoolManager.borrowObject();
......
iTextRenderer.layout();
} catch (Exception e) {
LOGGER.error(e);
} finally {
if (iTextRenderer != null) {
iTextRendererPoolManager.returnObject(iTextRenderer);
}
}
但是在放回对象池前没有对ITextRenderer里面的sharedContext属性清空, 这样的话下次从对象池里如果还是获取到这个对象,就会对ITextRenderer内部的属性sharedContext继续叠加。。。
查了下官方使用手册发现没有这样的用法, 所以导致这个问题的原因应该是我们使用的姿势不对
解决方法一种是继续使用对象池,但在放回对象池之前先清除下SharedContext, 或者简单点不再用对象池,每次new一个, 因为是在方法内部创建的局部变量, 不会逃逸出方法外, 方法调用完就自动释放了。
验证结果
修复上述两个问题后在测试环境验证通过然后发布上线从12月10号一直截止到今天,大概18天里内存再没有泄漏迹象, 堆外内存(RSS-JVM内存)也稳定下来,如下图:
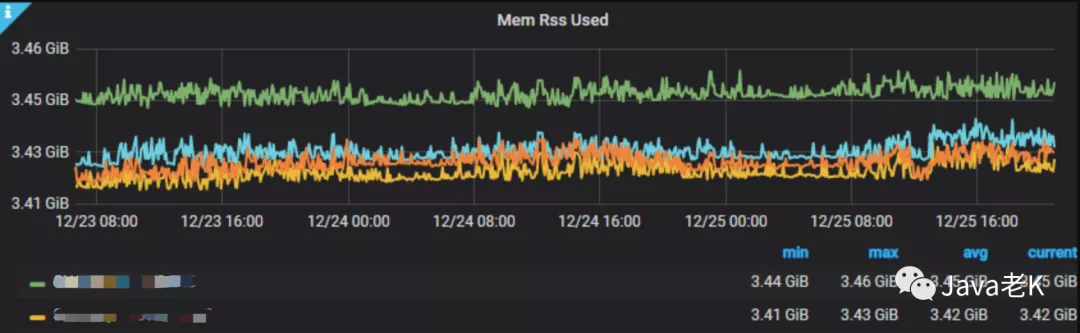
至此, 内存泄漏问题算是告一段落。
总结
查看git提交记录发现这个问题在线上存在有一段时间了(10月30号之前就有泄漏迹象),之前一直没报出来主要是每周都有发版,发布肯定会重启清空内存,发布频繁也就掩盖了这个问题,所以这个问题其实是一直存在的

但测试环境又很难重现出来,很少有应用在测试环境压测10天以上的,压测频率高了,接口容易熔断。。。
而且有些泄漏也不是"真正的泄漏", 比如本地缓存的失效策略设置不合理、写多读少、内存占用持续上升,直到触发抛弃策略等。
其实下面的三种情况都属于广义上的内存泄漏:
-
仍然具有GC ROOT根引用但从未在应用程序代码中使用的对象。这也是传统意义上的内存泄漏
-
对象太多或太大。意味着没有足够的堆可用于执行应用程序,因为内存中保存了太大的对象树(例如缓存)
-
临时对象太多。意味着Java代码中的处理暂时需要太多内存
第一种是大家都熟悉的内存泄漏,后两种多半属于写代码不规范,或业务流程上设计不合理或写代码时没充分考虑缓存的使用场景,所以:
-
写代码时要加强这方面的意识,包括review的人
-
发布上线后要定时监控,及早发现这类问题
MAT工具使用相关事项
使用mat前最好把初始化内存设置大一点,因为一般生产环境的dump文件都比较大,mat内存大小至少要cover住dump文件的大小,否则打开会报错,配置文件如图:
比如下面堆内存的最大(Xmx)最小(Xms)设置为4G(具体以你dump文件大小为准):
-startup
plugins/org.eclipse.equinox.launcher_1.3.100.v20150511-1540.jar
--launcher.library
plugins/org.eclipse.equinox.launcher.win32.win32.x86_64_1.1.300.v20150602-1417
-vmargs
-Xms4g
-Xmx4g
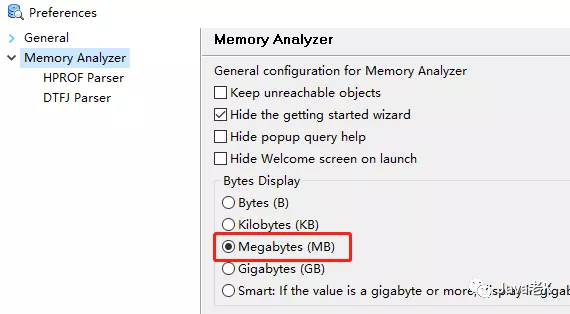
另外最好设置下显示单位, 以兆 M或G 为单位更便于理解,如图:
本文来自公众号:Java老K,互联网一线java开发老兵,工作10年有余,梦想敲一辈子代码,以梦为码,不负韶华。



