
记一次JVM OOM 实战优化原创
刚接手的服务,正常稳定运行了很长一段时间,在大家伙收拾东西准备回家过年时,突然就抽风了。
接口失败率居高不下?
看日志!
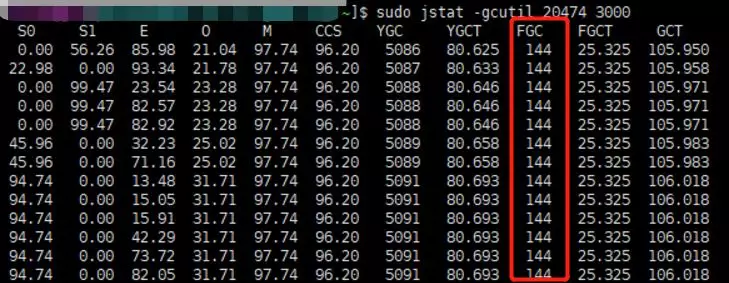
GC overhead limit exceeded
java.lang.OutOfMemoryError:GC overhead limit exceeded
看一下JVM堆栈
sudo jmap -heap port
#eg:sudo jmap -heap 9999
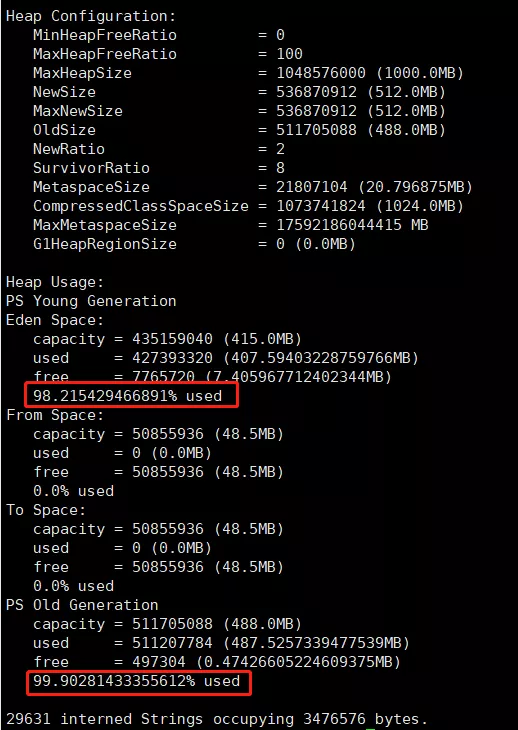
很明显,是内存不够了。
我当时的第一想法就是,应该是内存泄漏!我的思路如下:
1、先入为主,因为之前处理过一次因内存泄漏导致的JVM OOM问题,所以当时高度怀疑内存泄漏。
2、导出JVM堆数据,分析、定位问题。
3、fix bug,重新部署,finish!
我按照这个思路,分析堆栈后,发现堆中有大量对象,这些对象还没来得及回收,其他线程又在申请内存,从而导致了OOM。造成问题的直接原因是业务请求量增加了,而现有的机器资源不够用。至于间接原因,下一篇文章再详细描述。
在揭开问题的谜底后,回过头想一想,如果当时能够仔细分析一下问题,或许问题会被更快解决。
事后反思:服务已经稳定正常运行了一段时间,且一个月内未修改代码和更新服务。如果是代码有问题,那么问题极大可能会在新代码上线后的几天内出现。基于这一点,基本可以排除代码问题。
线上服务出现问题,首要的任务就是尽快恢复服务可用。如果下次出现类似问题,我会选择流程一,而非流程二。
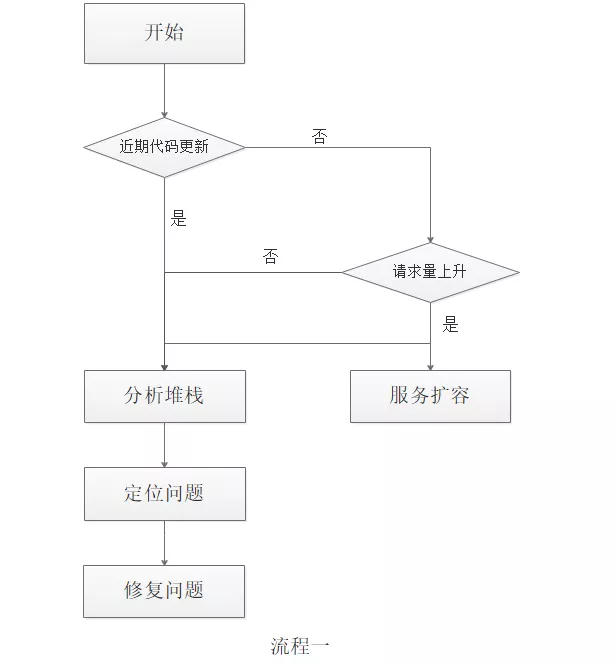
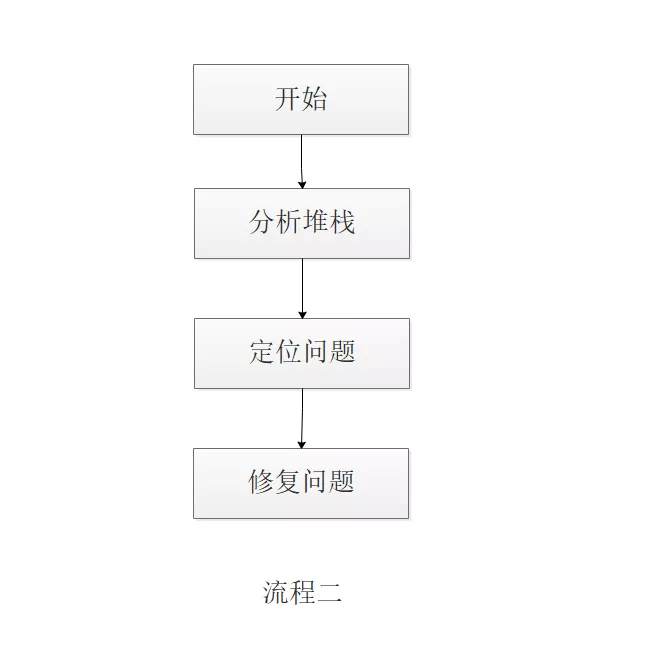
造成服务不可用的直接原因是服务请求量上升,而根本原因是由于下游服务负载过高,导致微服务调用超时,从而引起连锁反应。
下图呈现了用户发起请求到响应完成的大致流程。
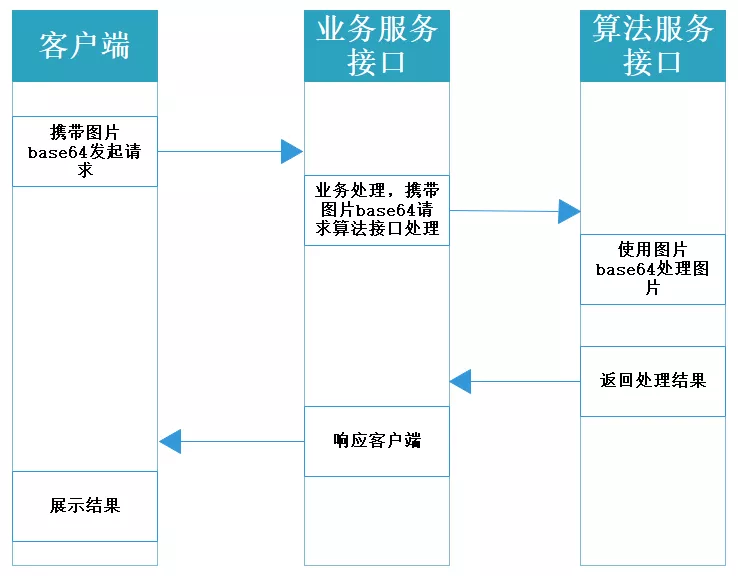
业务服务接口和算法服务接口使用eureka作为服务注册中心,整体来说,这个服务采用相对简单的微服务架构。
服务接口搭配feign来请求算法服务接口。
@FeignClient(value = "image-service")
public interface ImageService {
@PostMapping(value = "/XXX")
String XXX(@RequestParam("img_base64") String imgBase64);
}
上面的代码在执行请求的时候,会将请求参数进行拼接。
image-service/xxx?img_base64=fjsfdgldfgrwdfdmgfdglwefsl
当eureka真正确定请求的服务地址后,又会再做一次拼接处理。
127.0.0.1:5000/xxx?img_base64=fjsfdgldfgrwdfdmgfdglwefsl
算法服务接口的处理时间与图片的大小正相关,图片越大,处理时间越长。由于处理图片是一个相对耗时的操作,接口会出现超时的情况。如果请求失败(超时),那么feign会进行重试。
图片base64字符串的长度与图片大小呈正相关关系,图片越大,base64字符串长度越长。一张306K的图片,转成base64格式后,字符串长度为429196。

因此处理一次正常的请求消耗的内存比较大。图片越大,算法处理时间越久,超时失败后,feign重试,重试之后又失败,导致一个恶性循环(幸好有超时次数限制,否则如此递归下去,后果不堪设想)。
如图是JVM OOM后拿到堆栈的数据,最大的图片base64的大小有5M。
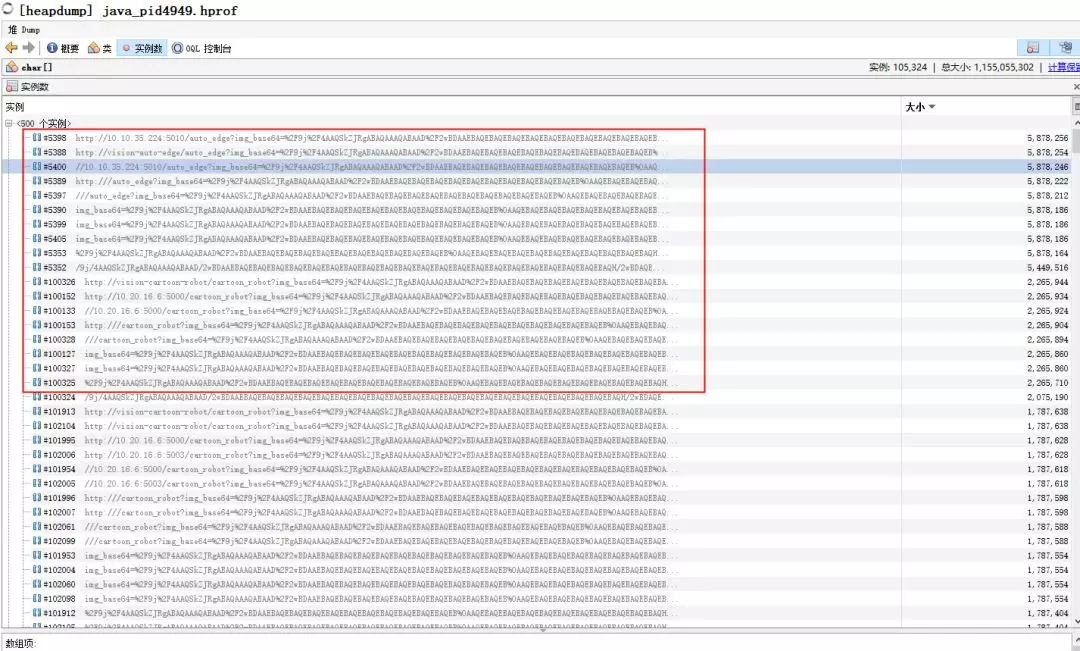
jdk1.8 JVM参数PretenureSizeThreshold的默认值是2M。

当base64字符串超过2M时,会直接分配到老年代,这无疑加大了JVM老年代的内存压力,导致频繁Full GC。
为何使用image base64传输图片?
1、历史原因。
2、开发相对简单。
该如何优化?
1、提高feign请求的超时时间。
2、提高机器配置。
3、将image base64放到请求体中,减少因feign框架对参数进行拼接带来的内存开销。



