
没想到,这么简单的线程池用法,深藏这么多坑原创
又又又踩坑了
生产有个对账系统,每天需要从渠道端下载对账文件,然后开始日终对账。这个系统已经运行了很久,前两天突然收到短信预警,没有获取渠道端对账文件。
本以为又是渠道端搞事情,上去一排查才发现,所有下载任务都被阻塞了。再进一步排查源码,才发现自己一直用错了线程池某个方法。
由于线程创建比较昂贵,正式项目中我们都会使用线程池执行异步任务。线程池,使用池化技术保存线程对象,使用的时候直接取出来,用完归还以便使用。
虽然线程池的使用非常方法非常简单,但是越简单,越容易踩坑。细数一下,这些年来因为线程池导致生产事故也有好几起。
所以今天,小黑哥就针对线程池的话题,给大家演示一下怎么使用线程池才会踩坑。
希望大家看完,可以完美避开这些坑~
慎用 Executors 组件
Java 从 JDK1.5 开始提供线程池的实现类,我们只需要在构造函数内传入相关参数,就可以创建一个线程池。
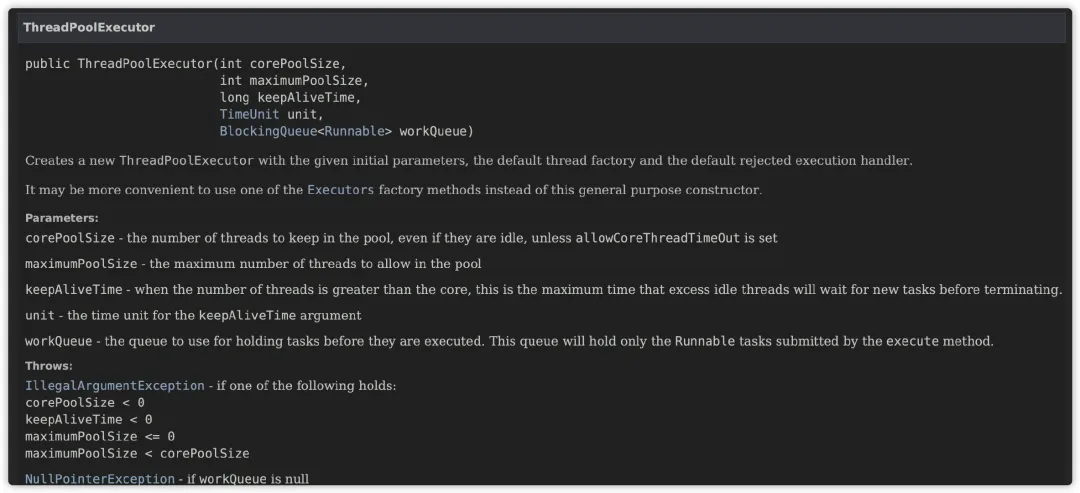
不过线程池的构造函数可以说非常复杂,就算最简单的那个构造函数,也需要传入 5 个参数。这对于新手来说,非常不方便哇。
也许 JDK 开发者也考虑到这个问题,所以非常贴心给我们提供一个工具类 Executors,用来快捷创建创建线程池。
虽然这个工具类使用真的非常方便,可以少写很多代码,但是小黑哥还是建议生产系统还是老老实实手动创建线程池,慎用Executors,尤其是工具类中两个方法 Executors#newFixedThreadPool与 Executors#newCachedThreadPool。
如果你图了方便使用上述方法创建了线程池,那就是一颗定时炸弹,说不准那一天生产系统就会💥。
我们来看两个🌰,看下这个这两个方法会有什么问题。
假设我们有个应用有个批量接口,每次请求将会下载 100w 个文件,这里我们使用 Executors#newFixedThreadPool批量下载。
“下面方法中,我们随机休眠,模拟真实下载耗时。为了快速复现问题,调整 JVM 参数为 -Xmx128m -Xms128m 。
private ExecutorService threadPool = Executors.newFixedThreadPool(10);
/**
* 批量下载对账文件
*
* @return
*/
@RequestMapping("/batchDownload")
public String batchDownload() {
// 模拟下载 100w 个文件
for (int i = 0; i < 1000000; i++) {
threadPool.execute(() -> {
// 随机休眠,模拟下载耗时
Random random = new Random();
try {
TimeUnit.SECONDS.sleep(random.nextInt(100));
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
return "process";
}
程序运行之后,多请求几次这个批量下载方法,程序很快就会 OOM 。

查看 Executors#newFixedThreadPool源码,我们可以看到这个方法创建了一个默认的 LinkedBlockingQueue 当做任务队列。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
这个问题槽点就在于 LinkedBlockingQueue,这个队列的默认构造方法如下:
/**
* Creates a {@code LinkedBlockingQueue} with a capacity of
* {@link Integer#MAX_VALUE}.
*/
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
创建 LinkedBlockingQueue 队列时,如果我们不指定队列数量,默认数量上限为 Integer.MAX_VALUE。这么大的数量,我们简直可以当做无界队列了。
上面我们使用 newFixedThreadPool,我们仅使用了固定数量的线程下载。如果线程都在执行任务,线程池将会任务加入任务队列中。
如果线程池执行任务过慢,任务将会一直堆积在队列中。由于我们队列可以认为是无界的,可以无限制添加任务,这就导致内存占用越来越高,直到 OOM 爆仓。
下面我们将上面的例子稍微修改一下,使用 newCachedThreadPool 创建线程池。
程序运行之后,多请求几次这个批量下载方法,程序很快就会 OOM ,不过这次报错信息与之前信息与之前不同。

从报错信息来看,这次 OOM 的主要原因是因为无法再创建新的线程。
这次看下一下 newCachedThreadPool 方法的源码,可以看到这个方法将会创建最大线程数为 Integer.MAX_VALUE 的的线程池。
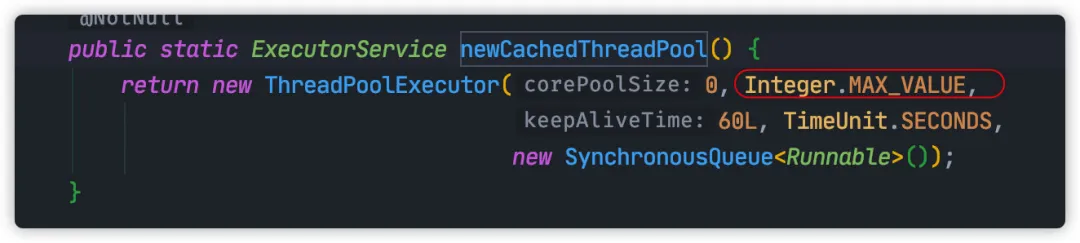
由于这个线程池使用 SynchronousQueue 队列,这个队列比较特殊,没办法存储任务。所以默认情况下,线程池只要接到一个任务,就会创建一个线程。
一旦线程池收到大量任务,就会创建大量线程。Java 中的线程是会占用一定的内存空间 ,所以创建大量的线程是必然会导致 OOM。
复用线程池
由于线程池的构造方法比较复杂,而 Executors 创建的线程池比较坑,所以我们有个项目中自己封装了一个线程池工具类。
工具类代码如下:
public static ThreadPoolExecutor getThreadPool() {
// 为了快速复现问题,故将线程池 核心线程数与最大线程数设置为 100
return new ThreadPoolExecutor(100, 100, 60, TimeUnit.SECONDS, new LinkedBlockingDeque<>(200));
}
项目代码中这样使用这个工具类:
@RequestMapping("/batchDownload")
public String batchDownload() {
ExecutorService threadPool = ThreadPoolUtils.getThreadPool();
// 模拟下载 100w 个文件
for (int i = 0; i < 100; i++) {
threadPool.execute(() -> {
// 随机休眠,模拟下载耗时
Random random = new Random();
try {
TimeUnit.SECONDS.sleep(random.nextInt(100));
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
return "process";
}
使用 WRK 工具对这个接口同时发起多个请求,很快应用就会抛出 OOM。
每次请求都会创建一个新的线程池执行任务,如果短时间内有大量的请求,就会创建很多的线程池,间接导致创建很多线程。从而导致内存占尽,发生 OOM 问题。
这个问题修复办法很简单,要么工具类生成一个单例线程池,要么项目代码中复用创建出来的线程池。
Spring 异步任务
上面代码中我们都是自己创建一个线程池执行异步任务,这样还是比较麻烦。在 Spring 中, 我们可以在方法上使用 Spring 注解 @Async,然后执行异步任务。
代码如下:
@Async
public void async() throws InterruptedException {
log.info("async process");
Random random = new Random();
TimeUnit.SECONDS.sleep(random.nextInt(100));
}
不过使用 Spring 异步任务,我们需要自定义线程池,不然大量请求下,还是有可能发生 OOM 问题。
这是原因主要是 Spring 异步任务默认使用 Spring 内部线程池 SimpleAsyncTaskExecutor 。

这个线程池比较坑爹,不会复用线程。也就是说来一个请求,将会新建一个线程。
所以如果需要使用异步任务,一定要使用自定义线程池替换默认线程池。
如果使用 XML 配置,我们可以增加如下配置:
<task:executor id="myexecutor" pool-size="5" />
<task:annotation-driven executor="myexecutor"/>
如果使用注解配置,我们需要设置一个 Bean:
@Bean(name = "threadPoolTaskExecutor")
public Executor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor executor=new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setThreadNamePrefix("test-%d");
// 其他设置
return new ThreadPoolTaskExecutor();
}
然后使用注解时指定线程池名称:
@Async("threadPoolTaskExecutor")
public void xx() {
// 业务逻辑
}
如果是 SpringBoot 项目,从本人测试情况来看,默认将会创建核心线程数为 8,最大线程数为 Integer.MAX_VALUE,队列数也为 Integer.MAX_VALUE线程池。
“ps:以下代码基于 Spring-Boot 2.1.6-RELEASE,暂不确定 Spring-Boot 1.x 版本是否也是这种策略,熟悉的同学的,也可以留言指出一下。
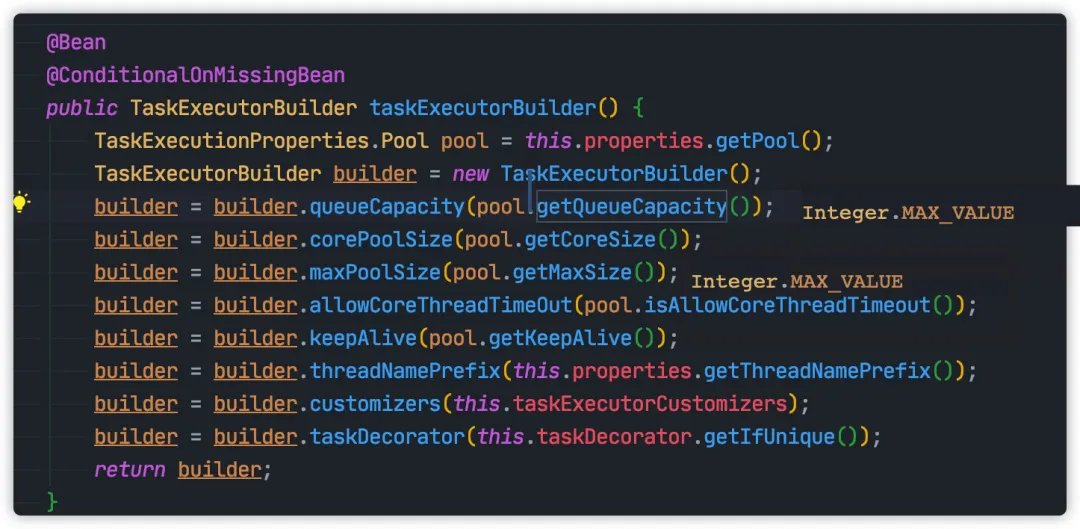
虽然上面的线程池不用担心创建过多线程的问题,不是还是有可能队列任务过多,导致 OOM 的问题。所以还是建议使用自定义线程池吗,或者在配置文件修改默认配置,例如:
spring.task.execution.pool.core-size=10
spring.task.execution.pool.max-size=20
spring.task.execution.pool.queue-capacity=200
线程池方法使用不当
最后再来说下文章开头的我踩到的这个坑,这个问题主要是因为理解错这个方法。
错误代码如下:
// 创建线程池
ExecutorService threadPool = ...
List<Callable<String>> tasks = new ArrayList<>();
// 批量创建任务
for (int i = 0; i < 100; i++) {
tasks.add(() -> {
Random random = new Random();
try {
TimeUnit.SECONDS.sleep(random.nextInt(100));
} catch (InterruptedException e) {
e.printStackTrace();
}
return "success";
});
}
// 执行所有任务
List<Future<String>> futures = threadPool.invokeAll(tasks);
// 获取结果
for (Future<String> future : futures) {
try {
future.get();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
上面代码中,使用 invokeAll执行所有任务。由于这个方法返回值为 List<Future<T>>,我误以为这个方法如 submit一样,异步执行,不会阻塞主线程。
实际上从源码上,这个方法实际上逐个调用 Future#get获取任务结果,而这个方法会同步阻塞主线程。
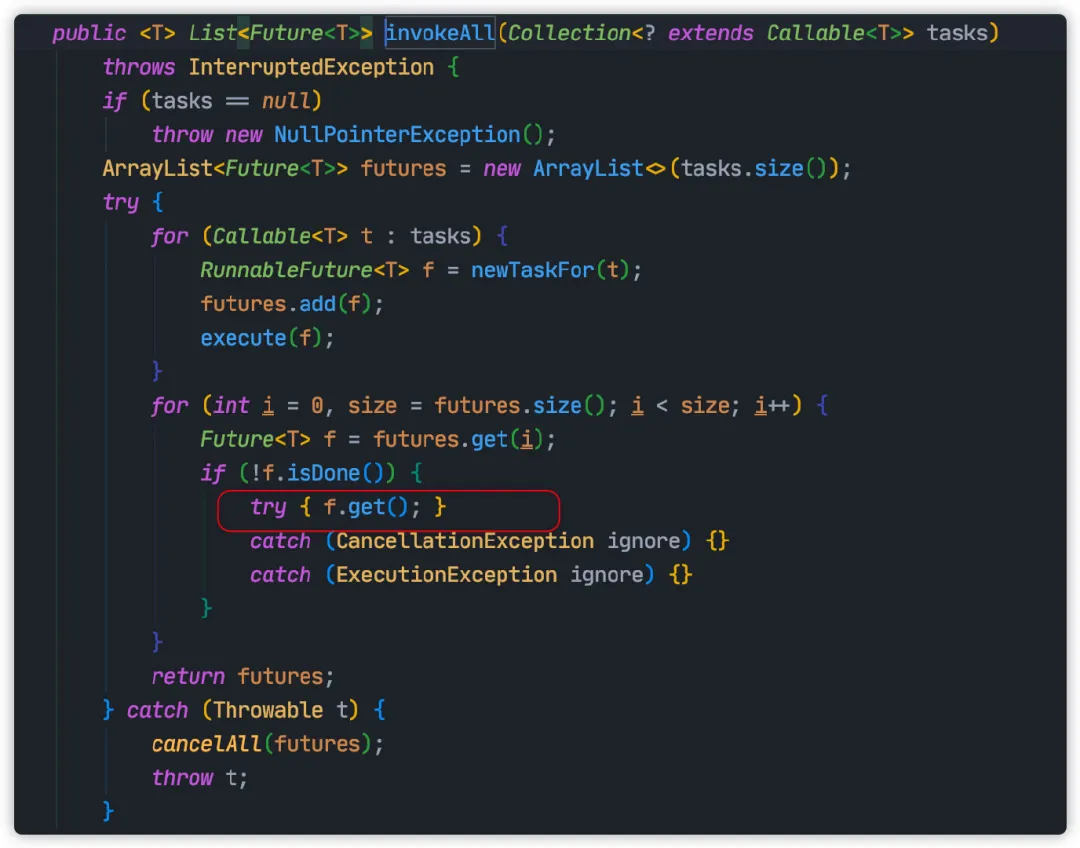
一旦某个任务被永久阻塞,比如 Socket 网络连接位置超时时间,导致任务一直阻塞在网络连接,间接导致这个方法一直被阻塞,从而影响后续方法执行。
如果需要使用 invokeAll 方法,最好使用其另外一个重载方法,设置超时时间。

总结
今天文章通过几个例子,给大家展示了一下线程池使用过程一些坑。为了快速复现问题,上面的示例代码还是比较极端,实际中可能并不会这么用。
不过即使这样,我们千万不要抱着侥幸的心理,认为这些任务很快就会执行结束。我们在生产上碰到好几次事故,正常的情况执行都很快。但是偶尔外部程序抽疯,返回时间变长,就可能导致系统中存在大量任务,导致 OOM。
最后总结一下几个线程池几个最佳实践:
第一,生产系统慎用 Executors 类提供的便捷方法,我们需要自己根据自己的业务场景,配置合理的线程数,任务队列,拒绝策略,线程回收策略等等,并且一定记得自定义线程池的命名方式,以便于后期排查问题。
第二,线程池不要重复创建,每次都创建一个线程池可能比不用线程池还要糟糕。如果使用其他同学创建的线程池工具类,最好还是看一下实现方式,防止自己误用。
第三,一定不要按照自己的片面理解去使用 API 方法,如果把握不准,一定要去看下方法上注释以及相关源码。



