
浅谈JDK并发包下面的分治思想及分治思想在高并发场景的运用原创
提到分治思想,大家比较容易想起其在归并排序与快速排序中的运用。今天先给大家分享一下JDK并发包下面分治思想的运用,再和大家分享一下如何利用分治思想解决高并发场景下面的一些问题。本文说的分治思想是广义范围的分治。可能和大家之前理解的分治不太一样。我理解的分治思想是并行处理、分开处理。关键在于并行与分开,并行提高速率,分开隔离资源,达到并行且互不影响。如果我说分治时,你想到的是Dubbo集群的负载均衡策略、Redis Cluster下面的节点、Kafka的分区Partition,很可能我理解的分治与你理解的是一样的。为了提高大家的阅读兴趣,先抛出高并发场景下面的两个问题?
- Redis集群下面能支持的QPS只有20,现在有一个热点key的QPS是100,在不扩容的提前下如何支持这个热点key上面的操作?
- 商品的库存采用分布式锁保证正确性(不超卖或少卖),现在分布式锁能支持的QPS只有20,而热门商品QPS为100,如何利用这个分布式锁保证热门商品购买正确性?
JDK并发包下面的分治思想
大家可能都知道JDk7中ConcureentHashMap中采用分段加锁思想来提高ConcurrentHashMap在并发场景下面的效率。在JDK7中ConcurrentHashMap内部维护了一个Segment的数组,一个key会映射到Segment数组中的某一个Segment上,一个线程对于这个key的操作只是对这个Segment进行加锁进行操作;其它线程可以并行的操作其它Segemet上的key,而不会阻塞挂起。这里的分段加锁,便可以理解为我上面说的分治思想。一个ConcurrentHashMap分开为多个Segment,多个线程可以并行处理各个Segment上的key,只要线程操作的key映射的Segment不是同一个,线程就可以并处理。扩容操作也是针对Segment进行隔离的,而不是针对整个ConcurrentHashMap进行扩容,这点与HashMap扩容的实现不一致。
JDK8中引入了LongAdder类。该类在高并发时性能优于AtomicLong,AtomicInteger等类。AtomicLong的原子增加(getAndIncrement)、原子减少(getAndDecrement)等操作,依赖于不断地自旋CAS操作。如果在竞争激烈的情况下,大量线程的CAS操作将失败,这些线程将不断地自旋尝试CAS操作直到对应值设置成功,这势必造成大量的CPU消耗。为此LongAdder采用了分治的思想,当并发量不太高时其直接通过不断地在其内部成员变量base上进行自旋CAS操作设置值,这时实际与AtomicLong实现一致;当并发量很高时,不同线程的自旋CAS操作会映射到LongAdder内部Cell数组中的某一个Cell上,从而减少了单个值上面自旋CAS操作失败的次数,降低了CPU因为CAS自旋操作失败的消耗。
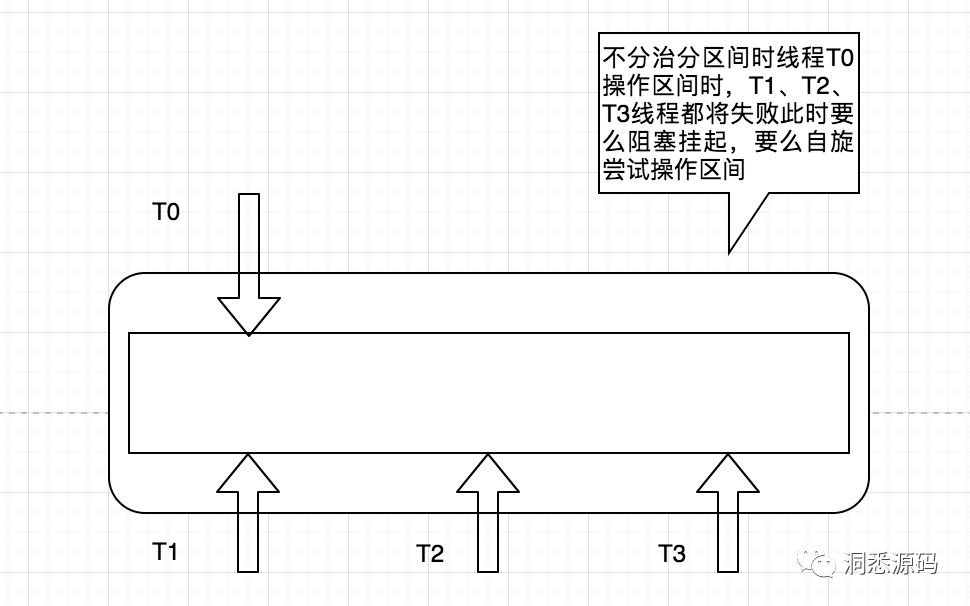
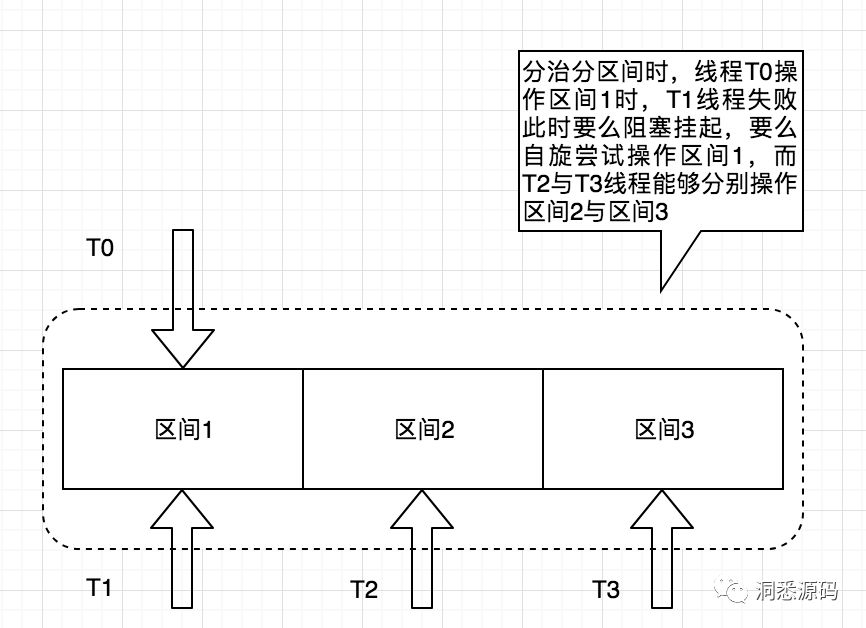
上面说的ConcurrentHashMap与LongAdder都采用分治的思想将并发的请求分发不同的区间,实现上各区间相互隔离,互不影响。ConcurrentHashMap是通过Segement数组进行分治,而LongAdder则通过Cell数组进行分治。下图简单描述通过分区分治的思相来提高整体并行度。
分法思想在高并发场景的运用
1、Redis集群下面能支持的QPS只有20,现在有一个热点key的QPS为100,在不扩容的提前下如何支持这个热点key上面的操作?
热点key的QPS为100,而Redis集群支持的QPS只有20,如果能够利用分治思想将热点key拆分为5个映射的MapKey,每次对热点key操作采用一定的算法转换为对映射的MapKey操作,这时5个映射的MapKey整体能支持的QPS将为100,最终达到了热点key在Redis集群支持的QPS只有20时,能达到保证热点key的QPS达到100。下图给出了采用分治思想,将热点key拆分为5个映射的MapKey的整体过程。
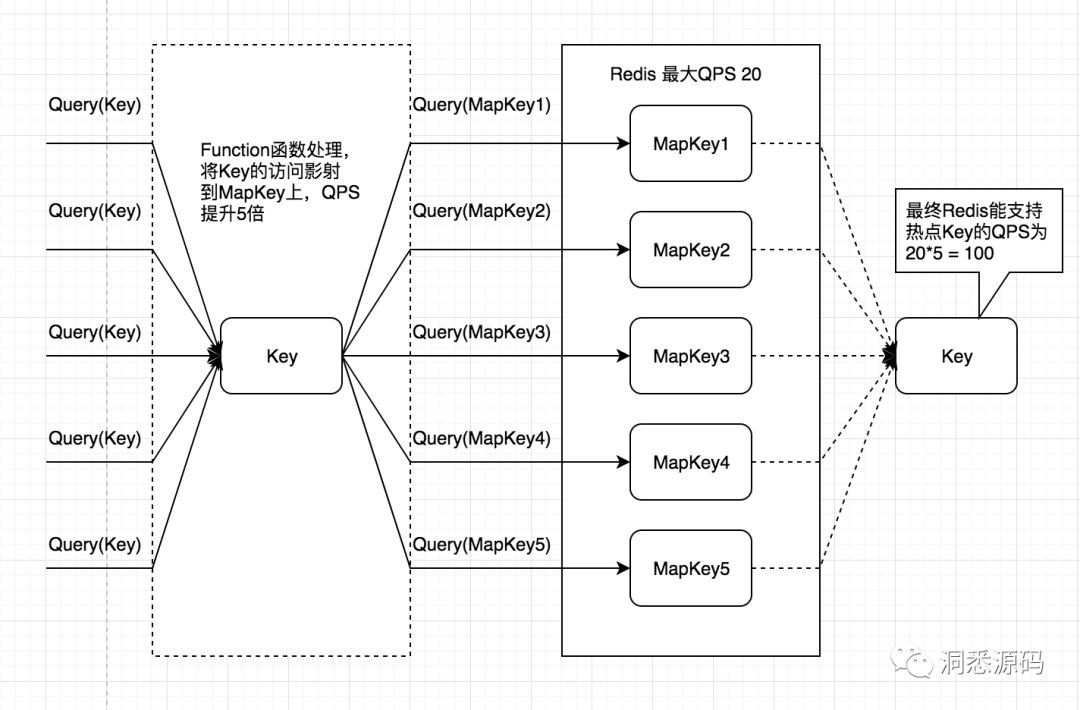
上面提到每次对热点key操作采用一定的算法转换为对映射的MapKey操作,这里面说的一定的算法大家有没有联想到什么?Dubbo集群负载均衡LoadBalance算法,Random LoadBalance、RoundRobin LoadBalance、LeastActive LoadBalance、ConsistentHash LoadBalance。针对不同的业务场景可以借鉴LoadBalance算法,将热点key的操作转为映射MapKey上的操作。分治的本质就是减少单一个体上的压力,这个个体可以是一个节点(Dubbo中服务节点、Redis集群中的节点)、可以是热点Key、也可以是资源(商品库存)等。JDK中的ConcurrentHashMap与LongAdder则分别是Segement与Cell,只不过Segement下面聚集一下很多的key,而Cell保存了具体要进行原子操作的value。
2、商品的库存采用分布式锁保证正确性(不超卖或少卖),现在分布式锁能支持的QPS只有20,而热门商品QPS为100,如何利用这个分布式锁保证热门商品购买正确性?
结合上面热点key的解决思路,采用分治的方式,将热门商品分成5份分别存储,当对热门商品的请求到来时按一定算法将请求转换为对这5份中的某一份的请求,此时分式锁将加在这5份中的某一份上面,而不是直接加在热商品上面。达到最终热门商品QPS支持100的效果。
总结
今天给大家分享了我对分治思想的理解,从JDK的ConcurrentHashMap与LongAdder,聊到了两个具体的高并发场景,如何利用分治进行优化。大家下次再碰到数据量很大或者QPS很高的问题时,首先要想到的就是分治法,这招应该基本能应对大部分问题,关键在对什么进行分治,采取什么策略分治。数据量很大或者QPS很高本质都是大规模,一个是针对于空间维度,另一个是针对时间维度。分治思想要解决的就是这种大规模问题。写这篇文章的目的一个是为了归纳总结,另一个是时刻提醒自己下次再阅读源码时能多思考提炼其中的精华然后能迁移到实际场景中。可能JDk7中ConcurrentHashMap分段加锁与LongAdder的Cell数组分摊单个数据上并发操作量,不足以让我们马上想到这是分治。但当我们去不断地思考、归纳、联系、总结时,我们会发现其中背后的核心思想与本质是分治。我能说我在这个时候感受到搞马哲人的屌不?不得不说一个字服。水平有限写的不对的地方欢迎拍砖。



