
记一次网络请求连接超时的事故原创
从HTTP请求超时、重试机制、操作系统网络等层面剖析了事故的原因,最终解决业务问题。
这里先抛两个问题:
1)你遭遇过由于网络连接或请求超时造成的生产事故吗?
2)你知道操作系统默认的网络连接超时是多少秒?
问题背景
最近同事出现这么一个问题,简单业务场景:
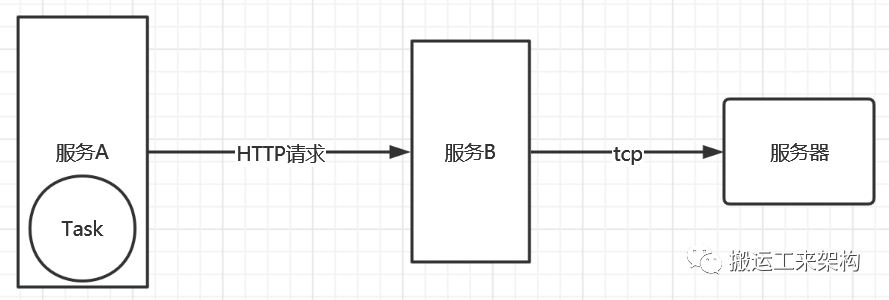
服务A使用HTTP请求服务B接口m。服务A起了一个定时任务Task:
从db查询数据总共有1200+条,每条记录对应一次请求,循环调用m接口。服务B收到请求会使用TCP连接其它服务器机器,进行命令的交互。注意这里并不是异步并发去请求接口,因为如果异步并发请求,可能就造成服务B的处理线程很快用光,从而造成不会再很好的处理更多请求,甚至会造成大面积请求超时或服务宕机等等问题。
此时定时任务到时间跑起来了,过不了多久,服务A出现向B请求Hand住,最终出现超时。
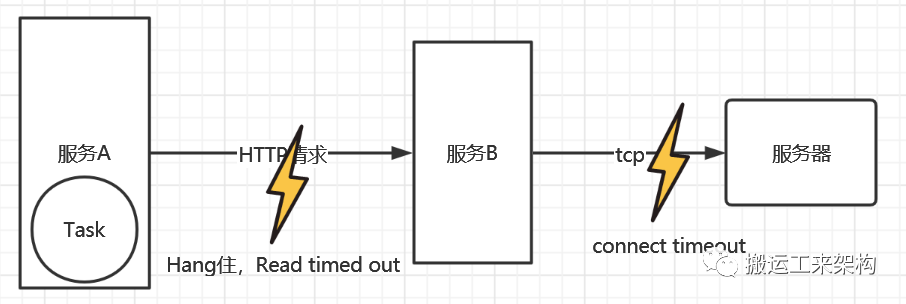
如下超时日志Read timed out:
虽然服务A自身查询DB等服务是正常的,但是服务A和服务B之间的交互也很重要,如果两者之间出现问题,必然会对业务处理或者系统等方面造成影响。
所以到底是为什么,这里涉及了什么问题呢?
问题解决
1、重试机制加快问题出现
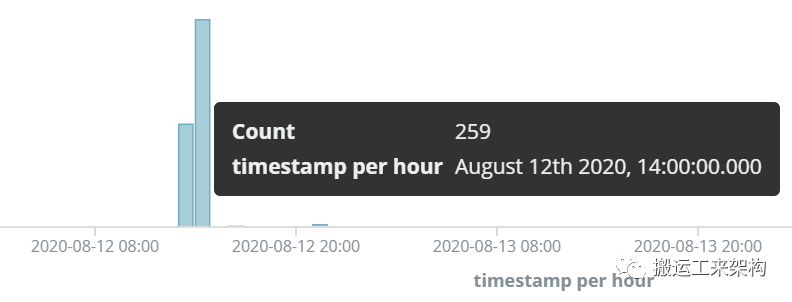
此时在服务A上进行排查,通过elk日志发现异常日志,异常日志数量激增。如下截图:
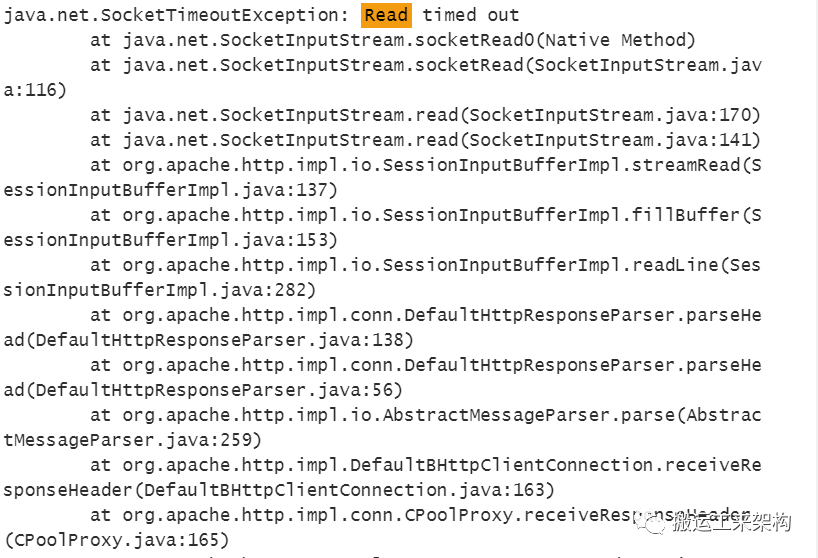
异常日志明细:
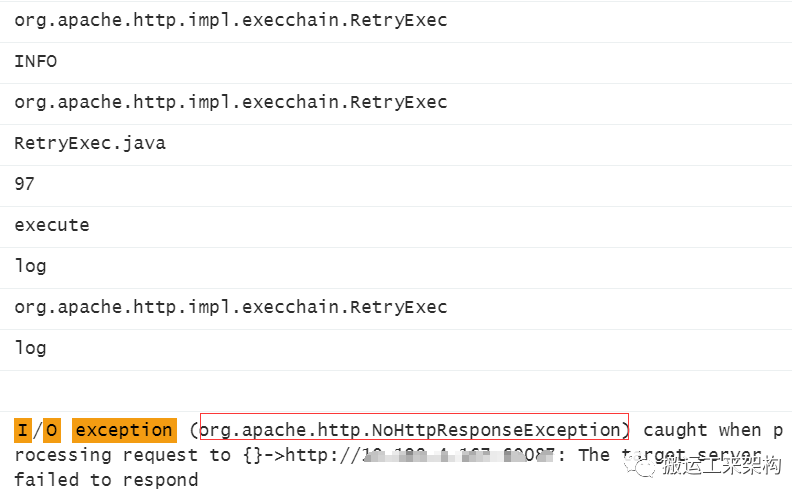
org.apache.http.impl.execchain.RetryExec,由此可知应该跟http重试机制相关。
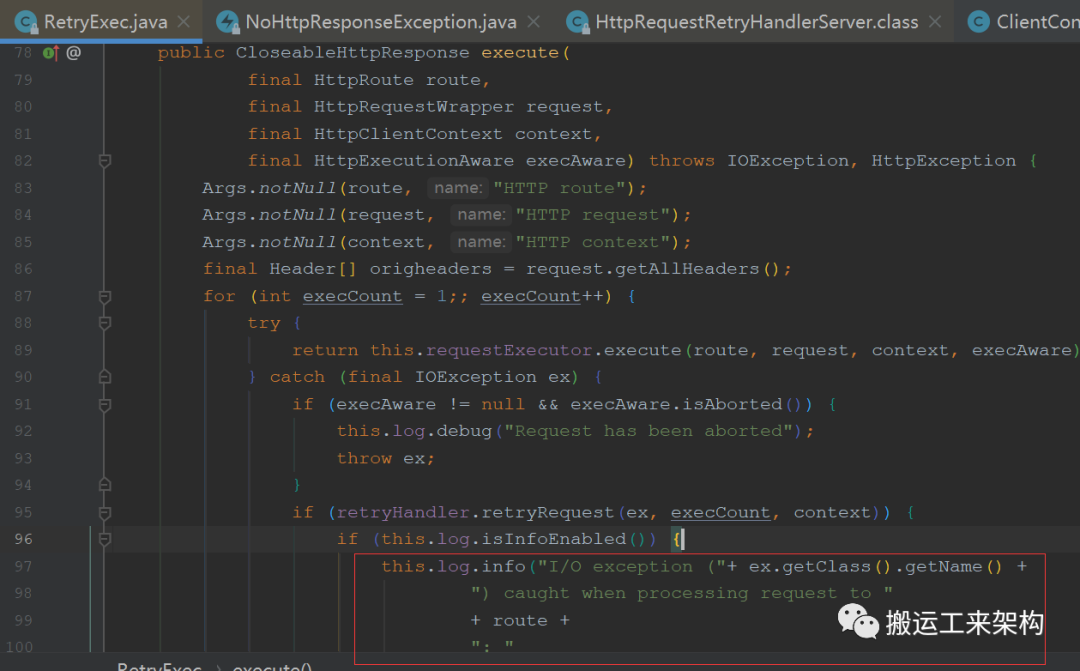
由RetryExec源码可知,当http执行请求时,如果正常请求则立即返回;否则IOException异常时,则进入重试环节。
这里要注意下,for循环进行重试是死循环的方式,这里的重试次数由实现者控制,如果无需重试,默认则不会进行重试,而是直接抛出异常。
查看RetryHandler的自定义实现源码:
@Component
public class HttpRequestRetryHandlerServer implements HttpRequestRetryHandler {
protected static final Logger LOG = LoggerFactory.getLogger(HttpRequestRetryHandlerServer.class);
@Override
public boolean retryRequest(IOException e, int retryCount, HttpContext httpCtx) {
if (retryCount >= 3) {
LOG.warn("Maximum tries reached, exception would be thrown to outer block");
return false;
}
if (e instanceof org.apache.http.NoHttpResponseException) {
LOG.warn("No response from server on {} call", retryCount);
return true;
}
return false;
}
}
从源码知道,重试次数最多3次,并且只针对这种异常NoHttpResponseException,从命名知道这是HTTP无响应异常(源码注释是:Signals that the target server failed to respond with a valid HTTP response.)。
那么服务A为什么会进入重试流程呢?
由上面的异常知道,可以排除是由于网络连接超时出现的异常,而是正常请求,但是由于可能某种原因,迟迟没有得到正常响应结果。由前面的异常Read timed out知道是出现读超时异常,这里就考虑到可能是跟网络数据传输等参数相关。
查看默认配置:
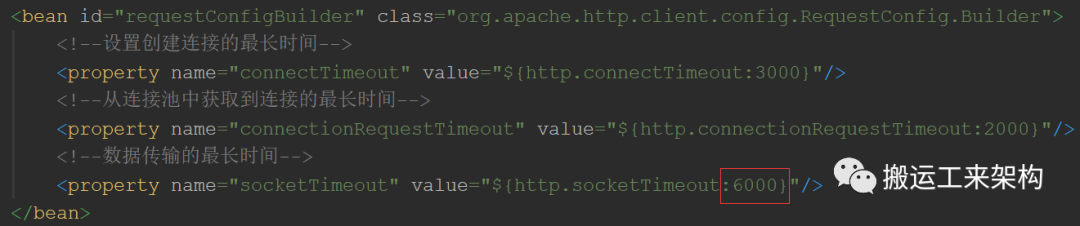
由此可知,6秒是数据传输的最长时间(读超时)。http请求时等待数据结果如果超过6秒,就会中断当前的请求,抛出Read timed out异常。所以基本上就可以知道这个异常的原由了。
2、重试机制加快问题-解决方法:
分析当前场景,于是做下调整:
1)由于此场景http请求无需进行重试,则将其关闭:
@Bean
public CloseableHttpClient noRetryHttpClient(HttpClientBuilder clientBuilder) {
// 重试次数为0,不进行重试
clientBuilder.setRetryHandler(new DefaultHttpRequestRetryHandler(0, false));
return clientBuilder.build();
}
2)由于此业务请求,服务B可能出现超过6秒的处理时长,则socketTimeout调整为15秒:
# http pool config
http:
maxTotal: 500
defaultMaxPerRoute: 100
connectTimeout: 5000
connectionRequestTimeout: 3000
socketTimeout: 15000
maxIdleTime: 1
keepAliveTimeOut: 65
3、机器连接超时的锅
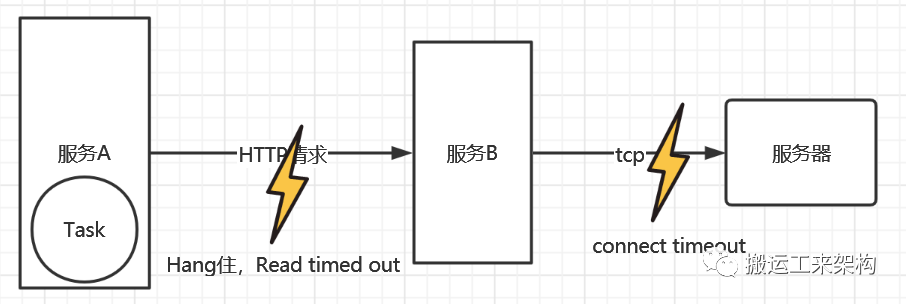
接下来再排查服务B到底是怎么了?也就是上图的右侧“闪电”。为什么需要这么长的处理时间。
服务A发起Http请求时,服务B接收请求后进行跟服务器进行连接后交互数据。服务B与服务机器通信只要是使用Tcp ssh的方式,也就是会进行网络通信。
经过排查服务B的日志:
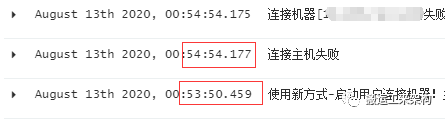
可知,进行连接服务器时出现异常。注意这个连接耗时时长为:63秒左右。并且确认排查目标服务器确实没有正常工作,而是已经停机许久。
由于进行的是Unix平台的网络连接,当前的操作系统是Linux CentOS。那么为什么这个超时时间是63秒,而不是5秒、15秒、60秒等比较规整的数据呢?
此时查看网络连接的代码:
connection.connect();
可知这里并没有指定连接超时等参数,那么应该是使用了操作系统内核的默认参数了。
Linux 系统默认的建立 TCP 连接的超时时间为 127 秒。这个对于客户端一般都是比较长了,更多的业务场景基本不会使用默认值,而是根据业务场景进行设置合理的连接超时时间。那么这个时间是怎么来的?为什么是127?
其实这个时间参数是由:net.ipv4.tcp_syn_retries配置的等级来确定的。
net.ipv4.tcp_syn_retries 的设置,表示应用程序进行connect()系统调用时,在对方不返回SYN + ACK的情况下(也就是超时的情况下),第一次发送之后,内核最多重试几次发送SYN包;并且决定了等待时间。
Linux上的默认值是 net.ipv4.tcp_syn_retries = 6 ,也就是说如果是本机主动发起连接,(即主动开启TCP三次握手中的第一个SYN包),如果一直收不到对方返回SYN + ACK ,那么应用程序最大的超时时间就是127秒。
第 1 次发送 SYN 报文后等待 1s(2 的 0 次幂),如果超时,则重试;
第 2 次发送后等待 2s(2 的 1 次幂),如果超时,则重试;
第 3 次发送后等待 4s(2 的 2 次幂),如果超时,则重试;
第 4 次发送后等待 8s(2 的 3 次幂),如果超时,则重试;
第 5 次发送后等待 16s(2 的 4 次幂),如果超时,则重试;
第 6 次发送后等待 32s(2 的 5 次幂),如果超时,则重试;
第 7 次发送后等待 64s(2 的 6 次幂),如果超时,则超时失败。
接下来查看我们的机器上的tcp syn 参数:

而我们的服务器设置的tcp_syn_retries为5,即默认超时为=1+2+4+8+16+32=63秒。刚好与当前问题完美符合,这就是为什么出现63秒超时原由了。
4、那么在Windows平台,又是怎么样的呢?
(本来这部分不准备阐述的,希望读者自行查阅资料,但是还是做个完整的吧。)
因为我是用Windows10作为开发机器的,所以顺便想了解下在Windows平台下,它的超时时间是多少。写了个测试用例,一测,竟然是21秒左右。这又是什么原理??
查阅相关资料:
TcpMaxConnectRetransmissions
Determines how many times TCP retransmits an unanswered request for a new connection. TCP retransmits new connection requests until they are answered, or until this value expires.
TCP/IP adjusts the frequency of retransmissions over time. The delay between the original transmission and the first retransmissions for each interface is determined by the value of TcpInitialRTT (by default, it is 3 seconds). This delay is doubled after each attempt. After the final attempt, TCP/IP waits for an interval equal to double the last delay and then abandons the connection request.
TcpInitialRTT
Determines how quickly TCP retransmits a connection request if it doesn’t receive a response to the original request for a new connection.
By default, the retransmission timer is initialized to 3 seconds, and the request (SYN) is sent twice, as specified in the value of TcpMaxConnectRetransmissions.
由资料可知,在Windows平台上是由此参数:TcpMaxConnectRetransmissions和TcpInitialRTT控制,TcpMaxConnectRetransmissions默认值一般为2,TcpInitialRTT默认是3秒。
也就是会进行2次重试,每次是上次的2倍时间,即21秒为:3+32+(32)*2=3+6+12=21秒。
通过命令查询Windows参数:
netsh interface tcp show global
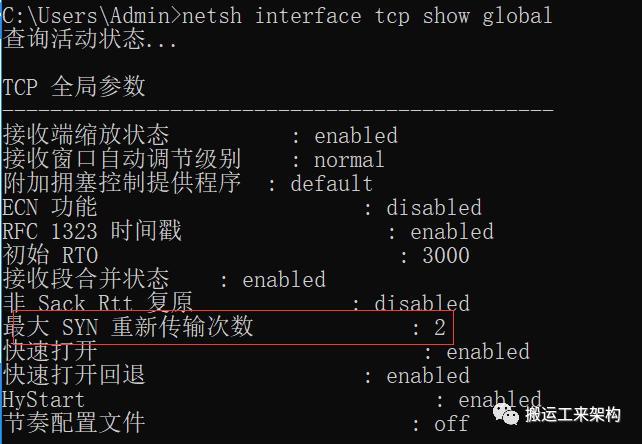
这个最大SYN重新传输次数我的公司开发机器是2,但是我的个人机器却为4(那么默认连接超时时长为:3+6+12+24+48=93秒),虽然都是Windows10系统,但是为什么不同这个就不得而知了。
5、机器连接超时的锅-解决方法:
服务B网络连接服务器时设置连接超时时间为5秒:
connection.connect(null, 5000, kexTimout);
这样只要超过5秒还没能连接上,就做超时异常处理,及早释放资源,不再阻塞当前处理线程。
6、结果:
通过相关的调整优化,重新发布服务验证,最终服务稳定运行,不会再出现异常等情况。
perfect!
总结
1)虽然这次事故造成的罪魁祸首不是服务A的HTTP重试机制,但是也是它加快了问题的出现速度。
所以我们要清楚是否需要重试机制,如果不需要就不要设置,不然非常浪费资源,甚至会压垮服务提供方系统等问题。
2)网络连接一般有TCP和HTTP等,防止超时时间太久影响业务、甚至造成服务宕机等严重问题,一般都要设置合理的超时时间(连接超时时间和数据传输时间等)。
因为操作系统设置的是比较通用的默认参数,并不会考虑具体的业务场景。
网络数据传输时间:具体的业务场景是非常不同的,比如默认6秒的数据传输时间,在实际的场景下并不一定合理,此时需要根据实际进行调整,比如我这边的情况是调整为15秒。
网络连接超时:比如Windows平台网络连接超时默认一般是21秒,Linux(Centos)有默认阶梯超时机制,默认127秒,而在我这台机器上则是63秒。
3)学习操作系统超时机制。比如Linux或Windows,在连接超时时可以在前面的超时时间增加倍数,可以学以致用到我们的业务开发中去。



