
Elasticsearch调优篇-慢查询分析笔记原创
前言
-
elasticsearch提供了非常灵活的搜索条件给我们使用,在使用复杂表达式的同时,如果使用不当,可能也会为我们带来了潜在的风险,因为影响查询性能的因素很多很多,这篇笔记主要记录一下慢查询可能的原因,及其优化的方向。
-
本文讨论的es版本为7.0+。
慢查询现象
查询服务超时
最直观的现象就是提供查询的服务响应超时。
大量连接被拒绝
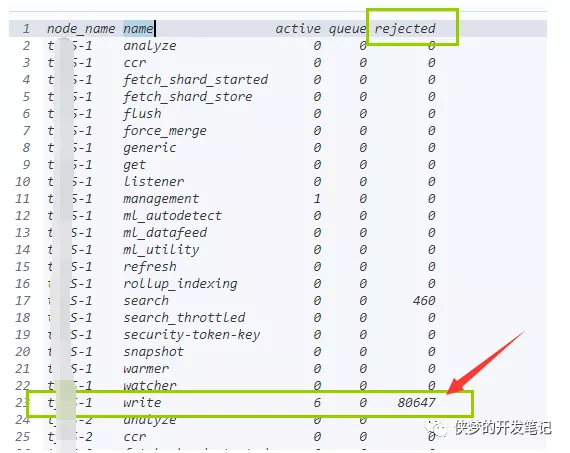
我们有时候写查询,为了图方便,经常使用通配符*来查询,这有可能会匹配到多个索引,由于索引下分片太多,超过了集群中的核心数。就会在搜索线程池中造成排队任务,从而导致搜索拒绝。
查询延迟
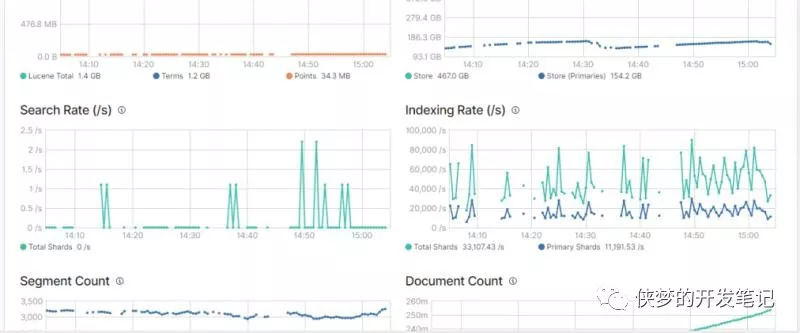
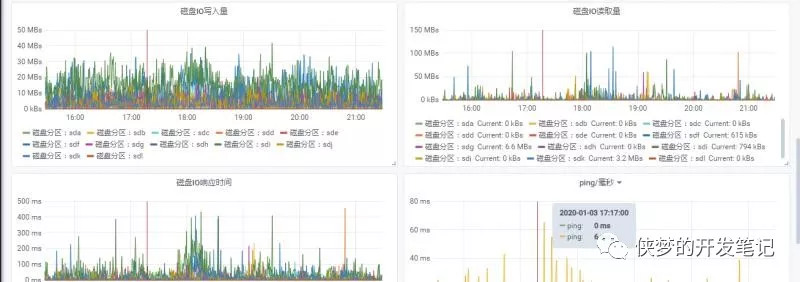
主机CPU飙高
另一个常见原因是磁盘 I/O 速度慢,导致搜索排队或在某些情况下 CPU 完全饱和。
除了文件系统缓存,Elasticsearch 还使用查询缓存和请求缓存来提高搜索速度。所有这些缓存都可以使用搜索请求进行优化,以便每次都将某些搜索请求路由到同一组分片,而不是在不同的可用副本之间进行交替。这将更好地利用请求缓存、节点查询缓存和文件系统缓存。Es默认会在内存使用75%时发生FullGC ,做好主机和节点的监控同样重要。
优化方法
根据查询时间段动态计算索引
elasticsearch支持同时查询多个索引,为了提高查询效率,避免使用通配符查询,我们可以计算枚举出所有的目标索引,一般es的数据都是按时间分索引,我们可以根据前端传入的时间段,计算出目标索引。
控制分片数量
分片的数量和节点和内存有一定的关系。
最理想的分片数量应该依赖于节点的数量。数量是节点数量的1.5到3倍。
每个节点上可以存储的分片数量,和堆内存成正比。官方推荐:881GB 的内存,分片配置最好不要超过20**。
注意from/to查询带来的深度分页问题
举例假如每页为 10 条数据,你现在要查询第 200 页,实际上是会把每个 Shard 上存储的前 2000条数据都查到一个协调节点上。如果你有 5 个 分片,那么就有 10000 条数据,接着协调节点对这 10000 条数据进行一些合并、处理,再获取到最终第 200 页的 10 条数据。实在需要查询很多数据,可以使用scroll API 滚动查询。
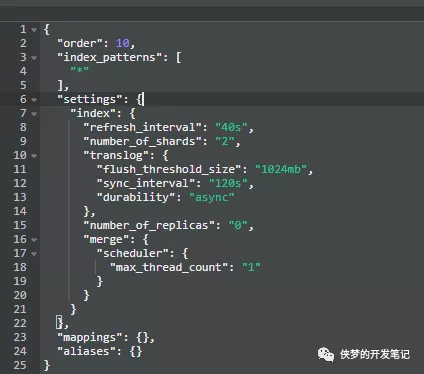
为你的索引配置索引模板
在低版本的es中默认的分片是5个,在高版本中改成了1,我们需要根据索引的索引量来动态调整分片数量,这里推荐设置一个默认匹配规则,将优先级设置高一些(ps:order高的会覆盖order低的模板),避免查询扫描过多的分片,合理利用集群资源。
避免数据分桶太多
对于分桶数量太大的聚合请求,应该将所有数据切片,比如按时间分片,多次请求,来提高查询效率,并且避免内存OOM。
独立协调节点
集群中应该有独立的协调节点,专门用于数据请求(node.master=false node.data=false),并给它们设置足够的内存。通过数据节点与协调节点分离,可以避免节点挂掉之后,导致整个集群不可用,或者长时间响应迟钝。
Routing数据路由
es是一个准实时的搜索框架,这就意味着,从索引一个文档直到文档能够被搜索到有一个轻微的延迟,也就是 index.refresh_ interval ,默认值是1秒,适当的增加这个值,可以避免创建过多的segment(segment是最小的检索单元)。
配置慢查询日志
通过在 Elasticsearch 中启用 slowlogs 来识别运行缓慢的查询。slowlogs 专门用于分片级别,仅适用于数据节点。协调/客户端节点不具备慢日志分析功能,因为它们不保存数据。通过它,我们可以在日志中看到,那个查询语句耗时长,从而制定优化措施。
index.search.slowlog.threshold.query.warn: 10s
index.search.slowlog.threshold.query.info: 5s
index.search.slowlog.threshold.query.debug: 2s
index.search.slowlog.threshold.query.trace: 500ms
index.search.slowlog.threshold.fetch.warn: 1s
index.search.slowlog.threshold.fetch.info: 800ms
index.search.slowlog.threshold.fetch.debug: 500ms
index.search.slowlog.threshold.fetch.trace: 200ms
index.search.slowlog.level: info
配置熔断策略
es7.0后版本提供一系列的断路器,用于防止操作引起OutOfMemoryError。每个断路器都指定了可以使用多少内存的限制。此外,还有一个父级断路器,用于指定可在所有断路器上使用的内存总量。
indices.breaker.request.limit:请求中断的限制,默认为JVM堆的60%。
indices.breaker.total.limit:总体中断程序的启动限制,如果indices.breaker.total.use_real_memory为,则默认为JVM堆的70% false。如果indices.breaker.total.use_real_memory 为true,则默认为JVM堆的95%。
network.breaker.inflight requests.limit 限制当前通过HTTP等进来的请求
使用内存不能超过Node内存的指定值。这个内存主要是限制请求内容的长度。默认100%。
script.max_compilations_rate:在允许的时间间隔内限制动态脚本的并发执行数量。默认值为75 / 5m,即每5分钟75。



