
垃圾回收-实战篇原创
JVM 参数简介
在开始实践之前我们有必要先简单了解一下 JVM 参数配置,因为本文之后的实验中提到的 JVM 中的栈,堆大小,使用的垃圾收集器等都需要通过 JVM 参数来设置
先来看下如何运行一个 Java 程序
- public class Test {
- public static void main(String[] args) {
- System.out.println("test");
- }
- }
首先我们通过 javac Test.java 将其转成字节码
其次我们往往会输入 java Test 这样的命令来启动 JVM 进程来执行此程序,其实我们在启动 JVM 进程的时候,可以指定相应的 JVM 的参数,如下蓝色部分。

指定这些 JVM 参数我们就可以指定启动 JVM 进程以哪种模式(server 或 client),运行时分配的堆大小,栈大小,用什么垃圾收集器等等,JVM 参数主要分以下三类
1、 标准参数(-),所有的 JVM 实现都必须实现这些参数的功能,而且向后兼容;例如 -verbose:gc(输出每次GC的相关情况)
2、 非标准参数(-X),默认 JVM 实现这些参数的功能,但是并不保证所有 JVM 实现都满足,且不保证向后兼容,栈,堆大小的设置都是通过这个参数来配置的,用得最多的如下。
| 参数示例 | 表示意义 |
|---|---|
| -Xms512m | JVM 启动时设置的初始堆大小为 512M |
| -Xmx512m | JVM 可分配的最大堆大小为 512M |
| -Xmn200m | 设置的年轻代大小为 200M |
| -Xss128k | 设置每个线程的栈大小为 128k |
3、非Stable参数(-XX),此类参数各个 jvm 实现会有所不同,将来可能会随时取消,需要慎重使用, -XX:-option 代表关闭 option 参数,-XX:+option 代表要关闭 option 参数,例如要启用串行 GC,对应的 JVM 参数即为 -XX:+UseSerialGC。非 Stable 参数主要有三大类
- 行为参数(Behavioral Options):用于改变 JVM 的一些基础行为,如启用串行/并行 GC
| 参数示例 | 表示意义 |
|---|---|
| -XX:-DisableExplicitGC | 禁止调用System.gc();但jvm的gc仍然有效 |
| -XX:-UseConcMarkSweepGC | 对老生代采用并发标记交换算法进行GC |
| -XX:-UseParallelGC | 启用并行GC |
| -XX:-UseParallelOldGC | 对Full GC启用并行,当-XX:-UseParallelGC启用时该项自动启用 |
| -XX:-UseSerialGC | 启用串行GC |
- 性能调优(Performance Tuning):用于 jvm 的性能调优,如设置新老生代内存容量比例
| 参数示例 | 表示意义 |
|---|---|
| -XX:MaxHeapFreeRatio=70 | GC后java堆中空闲量占的最大比例 |
| -XX:NewRatio=2 | 新生代内存容量与老生代内存容量的比例 |
| -XX:NewSize=2.125m | 新生代对象生成时占用内存的默认值 |
| -XX:ReservedCodeCacheSize=32m | 保留代码占用的内存容量 |
| -XX:ThreadStackSize=512 | 设置线程栈大小,若为0则使用系统默认值 |
- 调试参数(Debugging Options):一般用于打开跟踪、打印、输出等 JVM 参数,用于显示 JVM 更加详细的信息
| 参数示例 | 表示意义 |
|---|---|
| -XX:HeapDumpPath=./java_pid.hprof | 指定导出堆信息时的路径或文件名 |
| -XX:-HeapDumpOnOutOfMemoryError | 当首次遭遇OOM时导出此时堆中相关信息 |
| -XX:-PrintGC | 每次GC时打印相关信息 |
| -XX:-PrintGC Details | 每次GC时打印详细信息 |
明白了 JVM 参数是干啥用的,接下来我们进入实战演练,下文中所有程序运行时对应的 JVM 参数都以 VM Args 的形式写在开头的注释里,读者如果在执行程序时记得要把这些 JVM 参数给带上哦
发生 OOM 的主要几种场景及相应解决方案
有些人可能会觉得奇怪, GC 不是会自动帮我们清理垃圾以腾出使用空间吗,怎么还会发生 OOM, 我们先来看下有哪些场景会发生 OOM
Java 虚拟机规范中描述在栈上主要会发生以下两种异常
-
StackOverflowError 异常
这种情况主要是因为单个线程请求栈深度大于虚拟机所允许的最大深度(如常用的递归调用层级过深等),再比如单个线程定义了大量的本地变量,导致方法帧中本地变量表长度过大等也会导致 StackOverflowError 异常, 一句话:在单线程下,当栈桢太大或虚拟机容量太小导致内存无法分配时,都会发生 StackOverflowError 异常。 -
虚拟机在扩展栈时无法申请到足够的内存空间,会抛出 OOM 异常
在刨根问底—一次 OOM 试验造成的电脑雪崩引发的思考 一文中我们已经详细地剖析了此例子,再来看看
- /**
- * VM Args:-Xss160k
- */
- public class Test {
- private void dontStop() {
- while(true) {
- }
- }
- public void stackLeakByThread() {
- while (true) {
- Thread thread = new Thread(new Runnable() {
- public void run() {
- dontStop();
- }
- });
- thread.start();
- }
- }
- public static void main(String[] args) {
- Test oom = new Test();
- oom.stackLeakByThread();
- }
- }
运行以上代码会抛出「java.lang.OutOfMemoryError: unable to create new native thread」的异常,原因不难理解,操作系统给每个进程分配的内存是有限制的,比如 32 位的 Windows 限制为 2G,虚拟机提供了参数来控制 Java 堆和方法的这两部内存的最大值,剩余的内存为 「2G - Xmx(最大堆容量)= 线程数 * 每个线程分配的虚拟机栈(-Xss)+本地方法栈 」(程序计数器消耗内存很少,可忽略),每个线程都会被分配对应的虚拟机栈大小,所以总可创建的线程数肯定是固定的, 像以上代码这样不断地创建线程当然会造成最终无法分配,不过这也给我们提供了一个新思路,如果是因为建立过多的线程导致的内存溢出,而我们又想多创建线程,可以通过减少最大堆(-Xms)和减少虚拟机栈大小(-Xss)来实现。
堆溢出 (java.lang.OutOfMemoryError:Java heap space)
主要原因有两点
- 大对象的分配,最有可能的是大数组分配
示例如下:
- /**
- * VM Args:-Xmx12m
- */
- class OOM {
- static final int SIZE=2*1024*1024;
- public static void main(String[] a) {
- int[] i = new int[SIZE];
- }
- }
我们指定了堆大小为 12M,执行 「java -Xmx12m OOM」命令就发生了 OOM 异常,如果指定 13M 则以上程序就能正常执行,所以对于由于大对象分配导致的堆溢出这种 OOM,我们一般采用增大堆内存的方式来解决
画外音:有人可能会说分配的数组大小不是只有 2 * 1024 * 1024 * 4(一个 int 元素占 4 个字节)= 8M, 怎么分配 12 M 还不够,因为 默认新老代1:2即4,8M都装不下数组,JVM 进程除了分配数组大小,还有指向类(数组中元素对应的类)信息的指针、锁信息等,实际需要的堆空间是可能超过 12M 的, 12M 也只是尝试出来的值,不同的机器可能不一样
- 内存泄漏
我们知道在 Java 中,开发者创建和销毁对象是不需要自己开辟空间的,JVM 会自动帮我们完成,在应用程序整个生命周期中,JVM 会定时检查哪些对象可用,哪些不再使用,如果对象不再使用的话理论上这块内存会被回收再利用(即GC),如果无法回收就会发生内存泄漏
- /**
- * VM Args:-Xmx4m
- */
- public class KeylessEntry {
- static class Key {
- Integer id;
- Key(Integer id) {
- this.id = id;
- }
- public int hashCode() {
- return id.hashCode();
- }
- }
- public static void main(String[] args) {
- Map<Key,String> m = new HashMap<Key,String>();
- while(true) {
- for(int i=0;i<10000;i++) {
- if(!m.containsKey(new Key(i))) {
- m.put(new Key(i), "Number:" + i);
- }
- }
- }
- }
- }
执行以上代码就会发生内存泄漏,第一次循环,map 里存有 10000 个 key value,但之后的每次循环都会新增 10000 个元素,因为 Key 这个 class 漏写了 equals 方法,导致对于每一个新创建的 new Key(i) 对象,即使 i 相同也会被认定为属于两个不同的对象,这样 m.containsKey(new Key(i)) 结果均为 false,结果就是 HashMap 中的元素将一直增加,解决方式也很简单,为 Key 添加 equals 方法即可,如下
- public boolean equals(Object o) {
- boolean response = false;
- if (o instanceof Key) {
- response = (((Key)o).id).equals(this.id);
- }
- return response;
- }
对于这种内存泄漏导致的 OOM, 单纯地增大堆大小是无法解决根本问题的,只不过是延缓了 OOM 的发生,最根本的解决方式还是要通过 heap dump analyzer 等方式来找出内存泄漏的代码来修复解决,后文会给出一个例子来分析
java.lang.OutOfMemoryError:GC overhead limit exceeded
Sun 官方对此的定义:超过98%的时间用来做 GC 并且回收了不到 2% 的堆内存时会抛出此异常

导致的后果就是由于经过几个 GC 后只回收了不到 2% 的内存,堆很快又会被填满,然后又频繁发生 GC,导致 CPU 负载很快就达到 100%,另外我们知道 GC 会引起 「Stop The World 」的问题,阻塞工作线程,所以会导致严重的性能问题,产生这种 OOM 的原因与「java.lang.OutOfMemoryError:Java heap space」类似,主要是由于分配大内存数组或内存泄漏导致的, 解决方案如下:
-
检查项目中是否有大量的死循环或有使用大内存的代码,优化代码。
-
dump 内存(后文会讲述如何 dump 出内存),检查是否存在内存泄露,如果没有,可考虑通过 -Xmx 参数设置加大内存。
java.lang.OutOfMemoryError:Permgen space
在 Java 8 以前有永久代(其实是用永久代实现了方法区的功能)的概念,存放了被虚拟机加载的类,常量,静态变量,JIT 编译后的代码等信息,所以如果错误地频繁地使用 String.intern() 方法或运行期间生成了大量的代理类都有可能导致永久代溢出,解决方案如下
-
是否永久代设置的过小,如果可以,适应调大一点
-
检查代码是否有大量的反射操作
-
dump 之后通过 mat 检查是否存在大量由于反射生成的代码类
java.lang.OutOfMemoryError:Requested array size exceeds VM limit
该错误由 JVM 中的 native code 抛出。JVM 在为数组分配内存之前,会执行基于所在平台的检查:分配的数据结构是否在此平台中是可寻址的,平台一般允许分配的数据大小在 1 到 21 亿之间,如果超过了这个数就会抛出这种异常

碰到这种异常一般我们只要检查代码中是否有创建超大数组的地方即可。
java.lang.OutOfMemoryError: Out of swap space
Java 应用启动的时候分被分配一定的内存空间(通过 -Xmx 及其他参数来指定), 如果 JVM 要求的总内存空间大小大于可用的本机内存,则操作系统会将内存中的部分数据交换到硬盘上
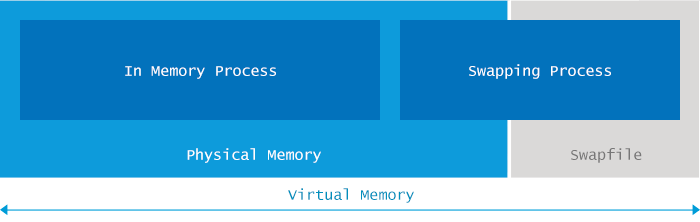
如果此时 swap 分区大小不足或者其他进程耗尽了本机的内存,则会发生 OOM, 可以通过增大 swap 空间大小来解决,但如果在交换空间进行 GC 造成的 「Stop The World」增加大个数量级,所以增大 swap 空间一定要慎重,所以一般是通过增大本机内存或优化程序减少内存占用来解决。
Out of memory:Kill process or sacrifice child
为了理解这个异常,我们需要知识一些操作系统的知识,我们知道,在操作系统中执行的程序,都是以进程的方式运行的,而进程是由内核调度的,在内核的调度任务中,有一个「Out of memory killer」的调度器,它会在系统可用内存不足时被激活,然后选择一个进程把它干掉,哪个进程会被干掉呢,简单地说会优先干掉占用内存大的应用型进程

解决这种 OOM 最直接简单的方法就是升级内存,或者调整 OOM Killer 的优先级,减少应用的不必要的内存使用等等
看了以上的各种 OOM 产生的情况,可以看出:GC 和是否发生 OOM 没有必然的因果关系! GC 主要发生在堆上,而 从以上列出的几种发生 OOM 的场景可以看出,空间不足无法再创建线程,或者存在死循环一直在分配对象导致 GC 无法回收对象或者一次分配大内存数组(超过堆的大小)等都可能导致 OOM, 所以 OOM 与 GC 并没有必然的因果关系。
OOM 问题排查的一些常用工具
接下来我们来看下如何排查造成 OOM 的原因,内存泄漏是最常见的造成 OOM 的一种原因,所以接下来我们以来看看怎么使用工具来排查这种问题,使用到的工具主要有两大类
使用 mat(Eclipse Memory Analyzer) 来分析 dump(堆转储快照) 文件
主要步骤如下
运行 Java 时添加 「-XX:+HeapDumpOnOutOfMemoryError」 参数来导出内存溢出时的堆信息,生成 hrof 文件, 添加 「-XX:HeapDumpPath」可以指定 hrof 文件的生成路径,如果不指定则 hrof 文件生成在与字节码文件相同的目录下
使用 MAT(Eclipse Memory Analyzer)来分析 hrof 文件,查出内存泄漏的原因
接下来我们就来看看如何用以上的工具查看如下内存泄漏案例
- /**
- * VM Args:-Xmx10m
- */
- import java.util.ArrayList;
- import java.util.List;
- public class Main {
- public static void main(String[] args) {
- List<String> list = new ArrayList<String>();
- while (true) {
- list.add("OutOfMemoryError soon");
- }
- }
- }
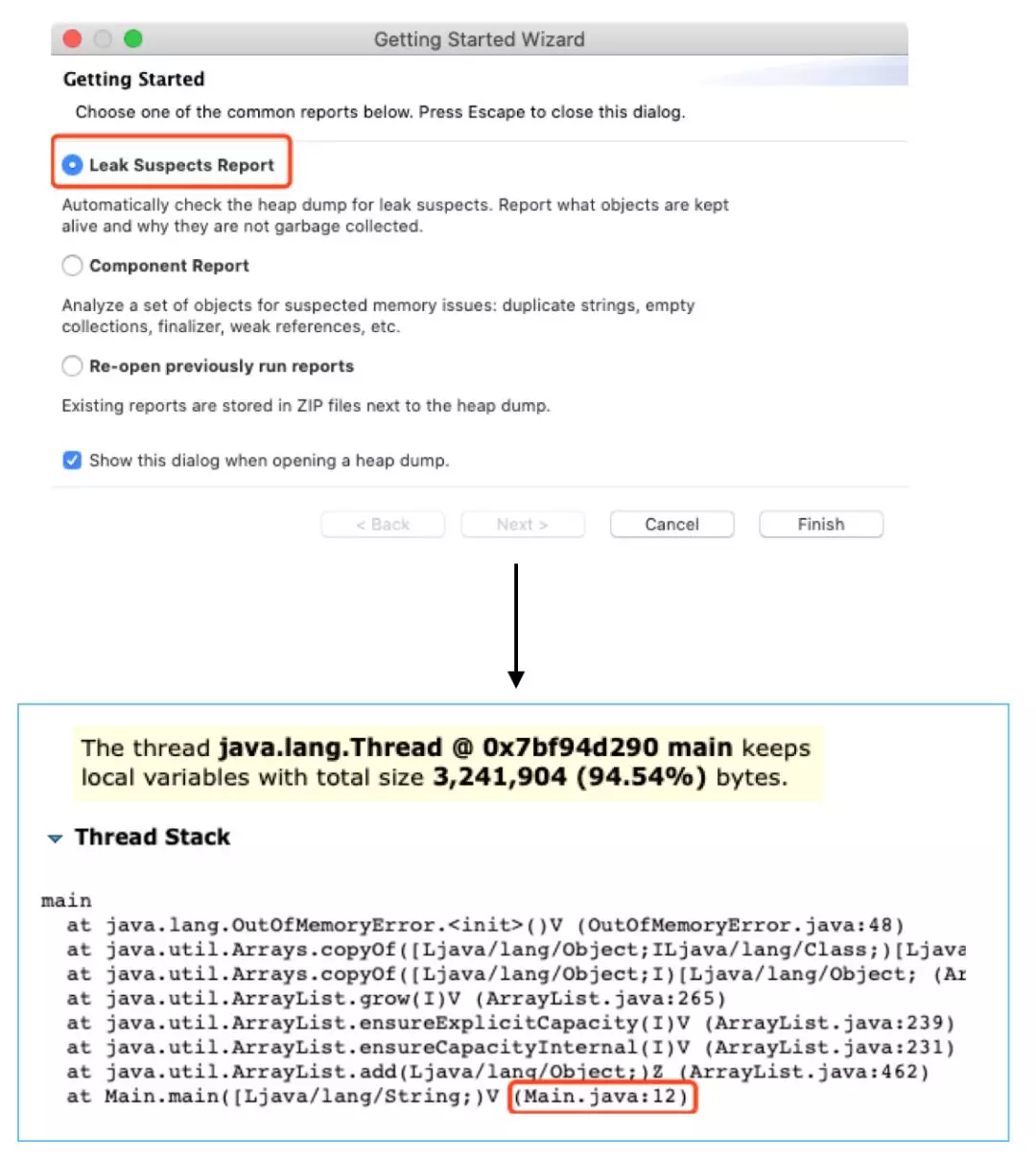
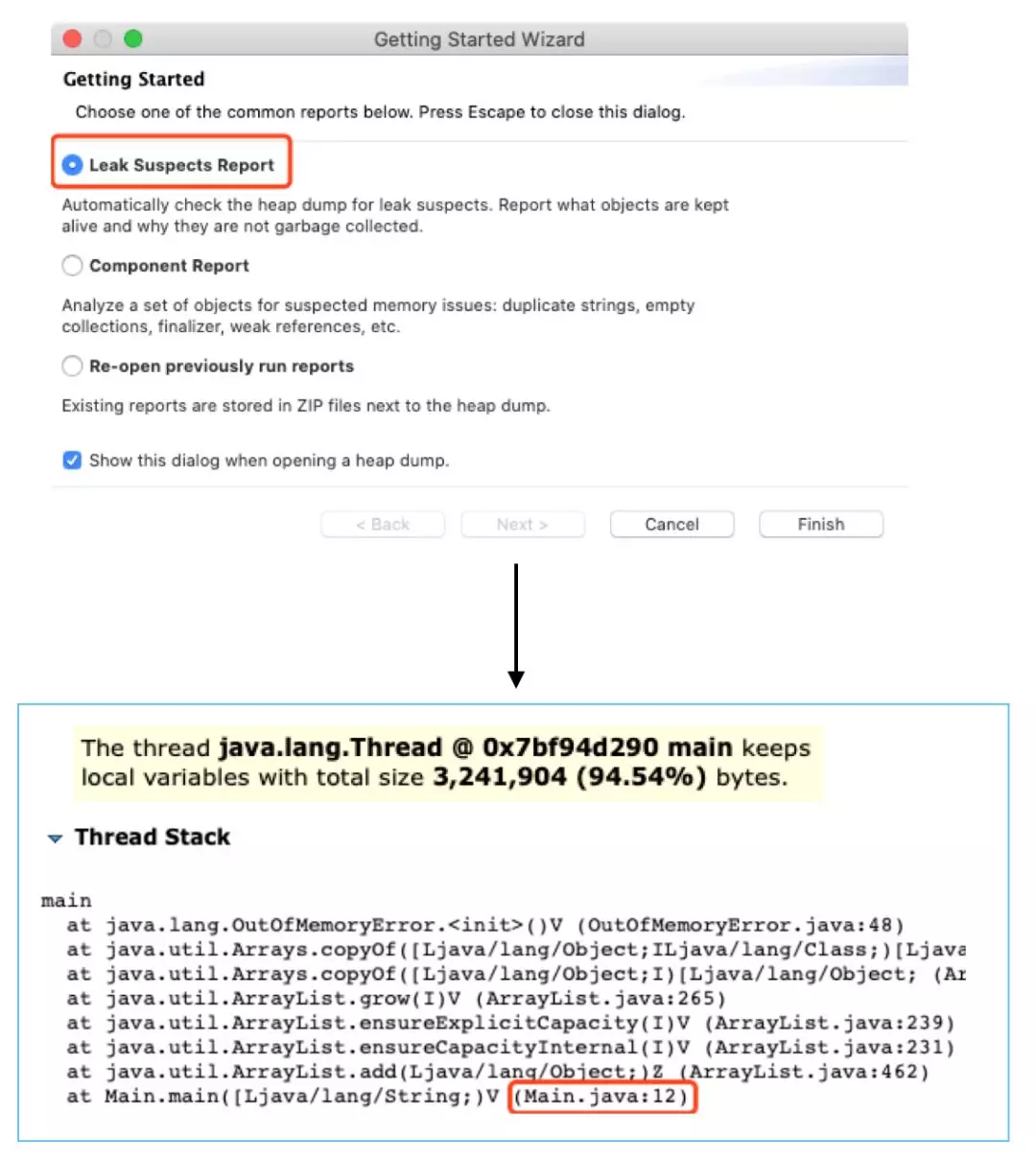
为了让以上程序快速产生 OOM, 我把堆大小设置成了 10M, 这样执行 「java -Xmx10m -XX:+HeapDumpOnOutOfMemoryError Main」后很快就发生了 OOM,此时我们就拿到了 hrof 文件,下载 MAT 工具,打开 hrof,进行分析,打开之后选择 「Leak Suspects Report」进行分析,可以看到发生 OOM 的线程的堆栈信息,明确定位到是哪一行造成的
使用 jvisualvm 来分析
用第一种方式必须等 OOM 后才能 dump 出 hprof 文件,但如果我们想在运行中观察堆的使用情况以便查出可能的内存泄漏代码就无能为力了,这时我们可以借助 jvisualvm 这款工具, jvisualvm 的功能强大,除了可以实时监控堆内存的使用情况,还可以跟踪垃圾回收,运行中 dump 中堆内存使用情况、cpu分析,线程分析等,是查找分析问题的利器,更骚的是它不光能分析本地的 Java 程序,还可以分析线上的 Java 程序运行情况, 本身这款工具也是随 JDK 发布的,是官方力推的一款运行监视,故障处理的神器。我们来看看如何用 jvisualvm 来分析上文所述的存在内存泄漏的如下代码
- import java.util.Map;
- import java.util.HashMap;
- public class KeylessEntry {
- static class Key {
- Integer id;
- Key(Integer id) {
- this.id = id;
- }
- public int hashCode() {
- return id.hashCode();
- }
- }
- public static void main(String[] args) {
- Map<Key,String> m = new HashMap<Key,String>();
- while(true) {
- for(int i=0;i<10000;i++) {
- if(!m.containsKey(new Key(i))) {
- m.put(new Key(i), "Number:" + i);
- }
- }
- }
- }
- }
打开 jvisualvm (终端输入 jvisualvm 执行即可),打开后,将堆大小设置为 500M,执行命令 java Xms500m -Xmx500m KeylessEntry,此时可以观察到左边出现了对应的应用 KeylessEntry,双击点击 open
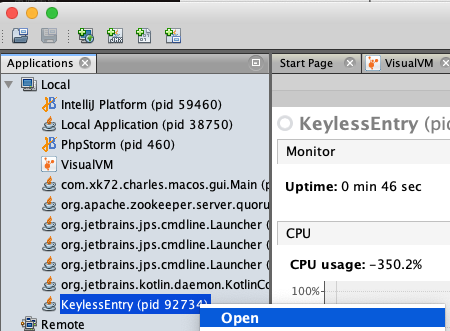
打开之后可以看到展示了 CPU,堆内存使用,加载类及线程的情况
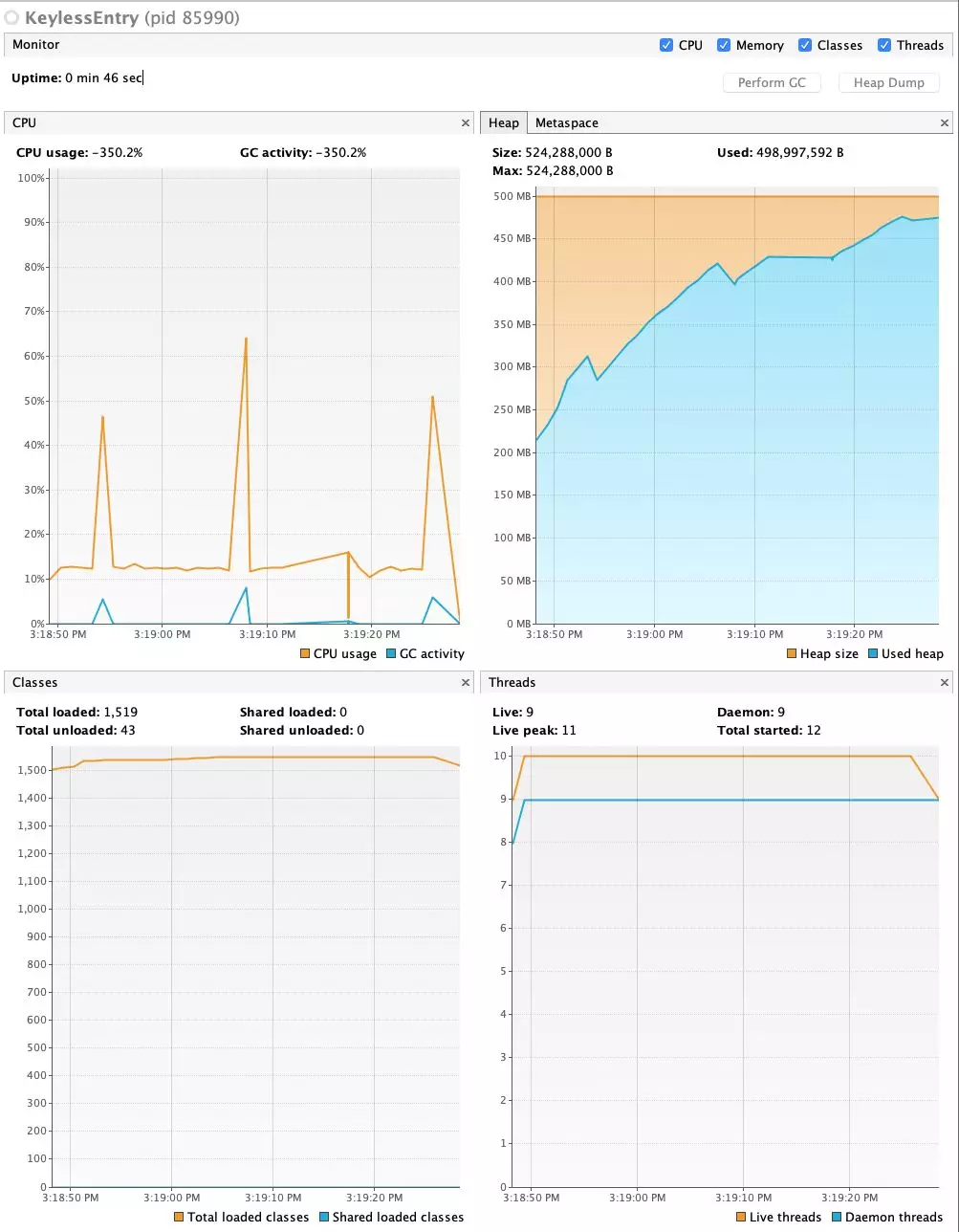
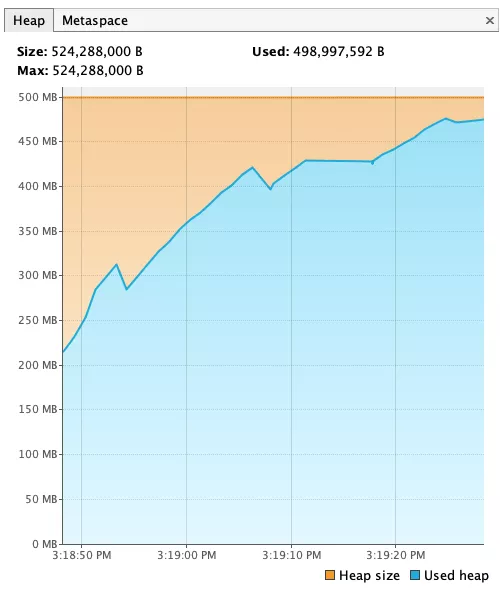
注意看堆(Heap)的使用情况,一直在上涨
此时我们再点击 「Heap Dump」
过一会儿即可看到内存中对象的使用情况
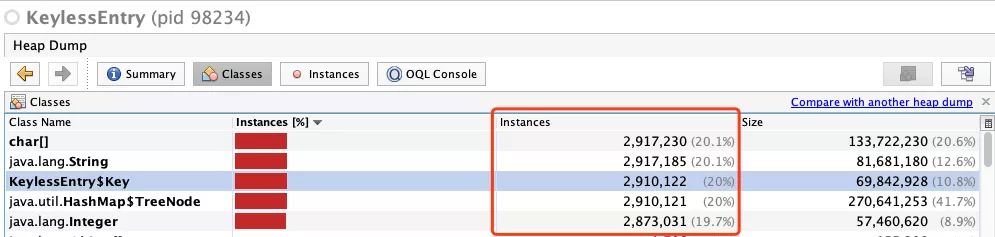
可以看到相关的 TreeNode 有 291w 个,远超正常情况下的 10000 个!说明 HashMap 一直在增长,自此我们可以定位出问题代码所在!
使用 jps + jmap 来获取 dump 文件
jps 可以列出正在运行的虚拟机进程,并显示执行虚拟机主类及这些进程的本地虚拟机唯一 ID,如图示
拿到进程的 pid 后,我们就可以用 jmap 来 dump 出堆转储文件了,执行命令如下
- jmap -dump:format=b,file=heapdump.phrof pid
拿到 dump 文件后我们就可以用 MAT 工具来分析了。
但这个命令在生产上一定要慎用!因为JVM 会将整个 heap 的信息 dump 写入到一个文件,heap 比较大的话会导致这个过程比较耗时,并且执行过程中为了保证 dump 的信息是可靠的,会暂停应用!
GC 日志格式怎么看
接下来我们看看 GC 日志怎么看,日志可以有效地帮助我们定位问题,所以搞清楚 GC 日志的格式非常重要,来看下如下例子
- /**
- * VM Args:-verbose:gc -Xms20M -Xmx20M -Xmn10M -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseSerialGC -XX:SurvivorRatio=8
- */
- public class TestGC {
- private static final int _1MB = 1024 * 1024;
- public static void main(String[] args) {
- byte[] allocation1, allocation2, allocation3, allocation4;
- allocation1 = new byte[2 * _1MB];
- allocation2 = new byte[2 * _1MB];
- allocation3 = new byte[2 * _1MB];
- allocation4 = new byte[4 * _1MB]; // 这里会出现一次 Minor GC
- }
- }
执行以上代码,会输出如下 GC 日志信息
- 10.080: 2[GC 3(Allocation Failure) 0.080: 4[DefNew: 56815K->280K(9216K),6 0.0043690 secs] 76815K->6424K(19456K), 80.0044111 secs]9 [Times: user=0.00 sys=0.01, real=0.01 secs]
以上是发生 Minor GC 的 GC 是日志,如果发生 Full GC 呢,格式如下
10.088: 2[Full GC 3(Allocation Failure) 0.088: 4[Tenured: 50K->210K(10240K), 60.0009420 secs] 74603K->210K(19456K), [Metaspace: 2630K->2630K(1056768K)], 80.0009700 secs]9 [Times: user=0.01 sys=0.00, real=0.02 secs]
两者格式其实差不多,一起来看看,主要以本例触发的 Minor GC 来讲解, 以上日志中标的每一个数字与以下序号一一对应
开头的 0.080,0.088 代表了 GC 发生的时间,这个数字的含义是从 Java 虚拟机启动以来经过的秒数
[GC 或者 [Full GC 说明了这次垃圾收集的停顿类型,注意不是用来区分新生代 GC 还是老年化 GC 的,如果有 Full,说明这次 GC 是发生了 Stop The World 的,如果是调用 System.gc() 所触发的收集,这里会显示 [Full GC(System)
之后的 Allocation Failure 代表了触发 GC 的原因,在这个程序中我们设置了新生代的大小为 10M(-Xmn10M),Eden:S0:S1 = 8:1:1(-XX:SurvivorRatio=8),也就是说 Eden 区占了 8M, 当分配 allocation4 时,由于将要分配的总大小为 10M,超过了 Eden 区,所以此时会发生 GC
接下来的 [DefNew,[Tenured,[Metaspace 表示 GC 发生的区域,这里显示的区域名与使用的 GC 收集器是密切相关的,在此例中由于新生代我们使用了 Serial 收集器,此收集器新生代名为「Default New Generation」,所以显示的是 [DefNew,如果是 ParNew 收集器,新生代名称就会变为 [ParNew`,意为 「Parallel New Generation」,如果采用 「Parallel Scavenge」收集器,则配套的新生代名称为「PSYoungGen」,老年代与新生代一样,名称也是由收集器决定的
再往后 6815K->280K(9216K) 表示 「GC 前该内存区域已使用容量 -> GC 后该内存区域已使用容量(该内存区域总容量)」
0.0043690 secs 表示该块内存区域 GC 所占用的时间,单位是秒
6815K->6424K(19456K) 表示「GC 前 Java 堆已使用容量 -> GC 后 Java 堆已使用容量(java 堆总容量)」。
0.0044111 secs 表示整个 GC 执行时间,注意和 6 中 0.0043690 secs 的区别,后者专指相关区域所花的 GC 时间,而前者指的 GC 的整体堆内存变化所花时间(新生代与老生代的的内存整理),所以前者是肯定大于后者的!
最后一个 [Times: user=0.01 sys=0.00, real=0.02 secs] 这里的 user, sys 和 real 与Linux 的 time 命令所输出的时间一致,分别代表用户态消耗的 CPU 时间,内核态消耗的 CPU 时间,和操作从开始到结束所经过的墙钟时间,墙钟时间包括各种非运算的等待耗时,例如等待磁盘 I/O,等待线程阻塞,而 CPU 时间不包括这些耗时,但当系统有多 CPU 或者多核的话,多线程操作会叠加这些 CPU 时间,所以 user 或 sys 时间是可能超过 real 时间的。
知道了 GC 日志怎么看,我们就可以根据 GC 日志有效定位问题了,如我们发现 Full GC 发生时间过长,则结合我们上文应用中打印的 OOM 日志可能可以快速定位到问题
jstat 与可视化 APM 工具构建
jstat 是用于监视虚拟机各种运行状态信息的命令行工具,可以显示本地或者远程虚拟机进程中的类加载,内存,垃圾收集,JIT 编译等运行数据,jstat 支持定时查询相应的指标,如下
- jstat -gc 2764 250 22
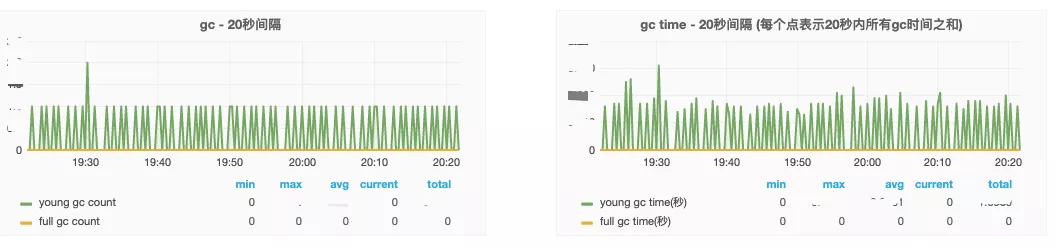
定时针对 2764 进程输出堆的垃圾收集情况的统计,可以显示 gc 的信息,查看gc的次数及时间,利用这些指标,把它们可视化,对分析问题会有很大的帮助,如图示,下图就是我司根据 jstat 做的一部分 gc 的可视化报表,能快速定位发生问题的问题点,如果大家需要做 APM 可视化工具,建议配合使用 jstat 来完成。
再谈 JVM 参数设置
经过前面对 JVM 参数的介绍及相关例子的实验,相信大家对 JVM 的参数有了比较深刻的理解,接下来我们再谈谈如何设置 JVM 参数
1、首先 Oracle 官方推荐堆的初始化大小与堆可设置的最大值一般是相等的,即 Xms = Xmx,因为起始堆内存太小(Xms),会导致启动初期频繁 GC,起始堆内存较大(Xmx)有助于减少 GC 次数
2、调试的时候设置一些打印参数,如-XX:+PrintClassHistogram -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:log/gc.log,这样可以从gc.log里看出一些端倪出来
3、系统停顿时间过长可能是 GC 的问题也可能是程序的问题,多用 jmap 和 jstack 查看,或者killall -3 Java,然后查看 Java 控制台日志,能看出很多问题
4、 采用并发回收时,年轻代小一点,年老代要大,因为年老大用的是并发回收,即使时间长点也不会影响其他程序继续运行,网站不会停顿
5、仔细了解自己的应用,如果用了缓存,那么年老代应该大一些,缓存的 HashMap 不应该无限制长,建议采用 LRU 算法的 Map 做缓存,LRUMap 的最大长度也要根据实际情况设定
要设置好各种 JVM 参数,还可以对 server 进行压测, 预估自己的业务量,设定好一些 JVM 参数进行压测看下这些设置好的 JVM 参数是否能满足要求
总结
本文通过详细介绍了 JVM 参数及 GC 日志, OOM 发生的原因及相应的调试工具,相信读者应该掌握了基本的 MAT,jvisualvm 这些工具排查问题的技巧,不过这些工具的介绍本文只是提到了一些皮毛,大家可以在再深入了解相应工具的一些进阶技能,这能对自己排查问题等大有裨益!文中的例子大家可以去试验一下,修改一下参数看下会发生哪些神奇的现象,亲自动手做一遍能对排查问题的思路更加清晰哦



