
记一次线上请求偶尔变慢的排查原创
前言
最近解决了个比较棘手的问题,由于排查过程挺有意思,于是就以此为素材写出了本篇文章。
Bug现场
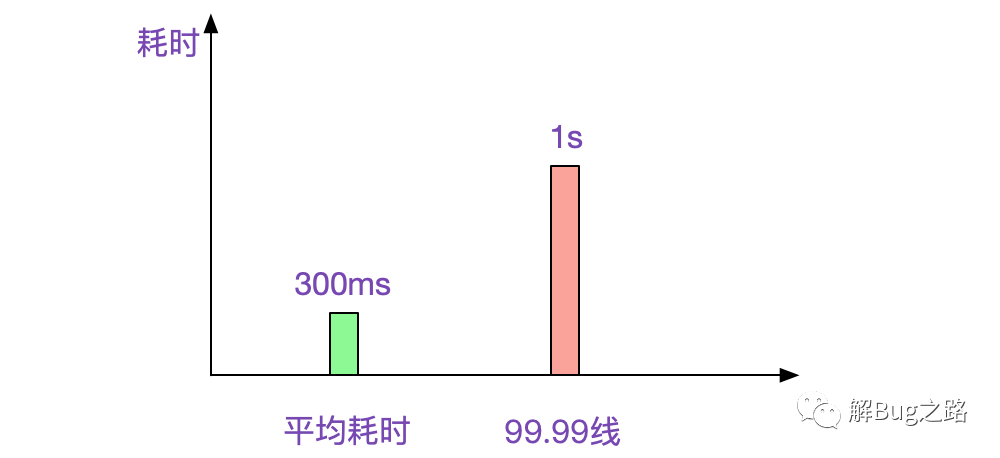
这是一个偶发的性能问题。在每天几百万比交易请求中,平均耗时大约为300ms,但总有那么100多笔会超过1s,让我们业务耗时监控的99.99线变得很尴尬。如下图所示:
为了精益求精,更为了消除这个尴尬的指标,笔者开始探寻起这100多慢请求笔的原因。
先找一笔看看
由于笔者写的框架预留了traceId,所以找到这笔请求的整个调用的链路还是非常简单的。而且通过框架中的拦截器在性能日志中算出了每一笔请求的耗时。这样,非常便于分析链路到底是在哪边耗时了。性能日志中的某个例子如下图所示:
2020-09-01 15:06:59.010 [abcdefg,A->B,Dubbo-thread-1,ipA->ipB] B.facade,cost 10 ms
拉出来一整条调用链路后,发现最前面的B系统调用C系统就比较慢。后面链路还有几个调用慢的,那先不管三七二十一,先分析B调用C系统吧。
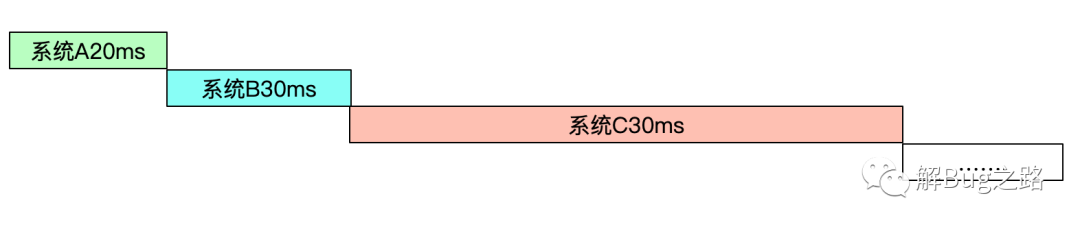
我们从监控系统看出来正常的B系统调用C系统平均耗时只有20ms,这次的耗时增长了10倍!

正常思路,那当然是C系统有问题么,毕竟慢了10倍!去C系统的性能日志里面看看,
2020-09-01 15:06:59.210 [abcdefg,B->C,Dubbo-thread-1,ipB->ipC] C.facade,cost 20 ms
啪啪啪打脸,竟然只有20ms,和平均耗时差不多。难道问题在网络上?B到C之间由于丢包重传所以到了200ms?

甩给网络?
由于笔者对TCP协议还是比较了解的,tcp第一次丢包重传是200ms,那么加上C处理的时间20ms,即220ms必须得大于200ms。而由于Nagle和DelayAck造成的tcp延迟也仅仅是40ms,两者相加60ms远远小于200ms,所以这个200ms是丢包或者DelayAck的概率不大。

本着万一呢的态度,毕竟下绝对的判断往往会被打脸,看了下我们的监控系统,发现当时流量距离网卡容量只有1/10左右,距离打满网卡还有非常远的距离。
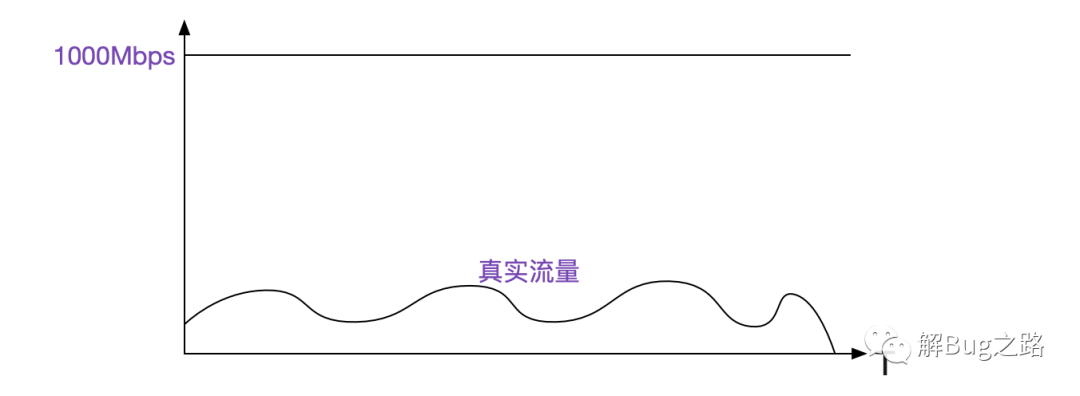
注意,这个监控的是由KVM虚拟机虚拟出来的网卡。看了这个流量,笔者感觉网络上问题的概率不大。
GC了?
笔者第二个想到的是GC了,但是观察了B和C的当时时刻的GC日志,非常正常,没有FullGC,youngGC也在毫秒级,完全不会有200ms这么长。TCP重传+双方都youngGC?这个也太巧了点吧,也不是不可用。不过详细的计算了时间点,并纳入了双方机器的时钟误差后,发现基本不可能。
再看看其它几笔
尽然这个问题每天有100多笔(当然了,也不排除其中混杂了其它不同的问题),那么就试试看看其它几笔,有没有什么共性。这一看,发现个奇怪的现象,就是有时候是A调用B慢,有时候是B调用C慢,还有时候是E调用F慢。他们唯一的共性就是耗时变长了,但是这个耗时增加的比例有5倍的,有10倍的,完全没有规律可循。
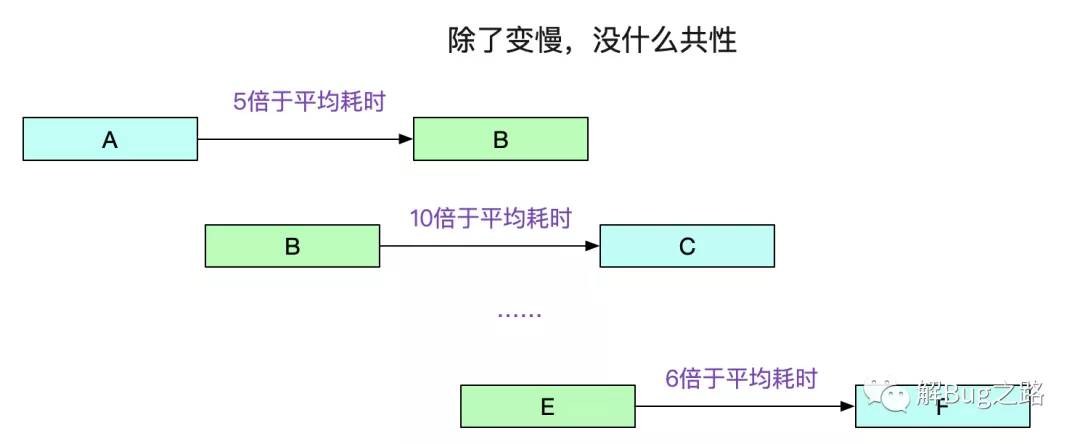
这不禁让笔者陷入了沉思。
寻找突破点
既然通用规律只有变慢,暂时无法进一步挖掘。那么还是去B系统上去看看情况吧,去对应B系统上故意不用grep而是用less看了下,上下扫了两眼。突然发现,貌似紧邻着的几条请求都很慢,而且是无差别变慢!也就是说B系统调用任何系统在这个时间点都有好几倍甚至十几倍的耗时!

终于找到了一个突破点,B系统本身或者其所属的环境应该有问题!于是笔者用awk统计了下 B系统这个小时内每分钟的平均调用时长,用了下面这条命令:
cat 性能日志 | grep '时间点 | awk -F ' ' '{print $2, $5}' |.......| awk -F ' ' '{sum[$1]+=$3;count[$1]+=1}END{for(i in sum) {print i,sum[i]/count[i]}}'
发现
15:00 20
15:01 21
15:02 15
15:03 30
.......
15:06 172.4
15:07 252.4
15:08 181.4
15:10 20
15:10 21
15:10 22
在15:06-15:08这三分钟之内,调用时间会暴涨!但奇怪的是B系统明明有几十台机器,只有这一台在这个时间段内会暴涨。难道这个时间有定时任务?笔者搜索了下B系统昨天的日志,发现在同样的时间段内,还是暴涨了!再接着搜索其它调用慢的,例如E->F,发现他们也在15:06-15:08报错!于是笔者,一横心,直接用awk算出了所有系统间调用慢机器白天内的所有分钟平均耗时(晚上的流量小不计入内),发现:
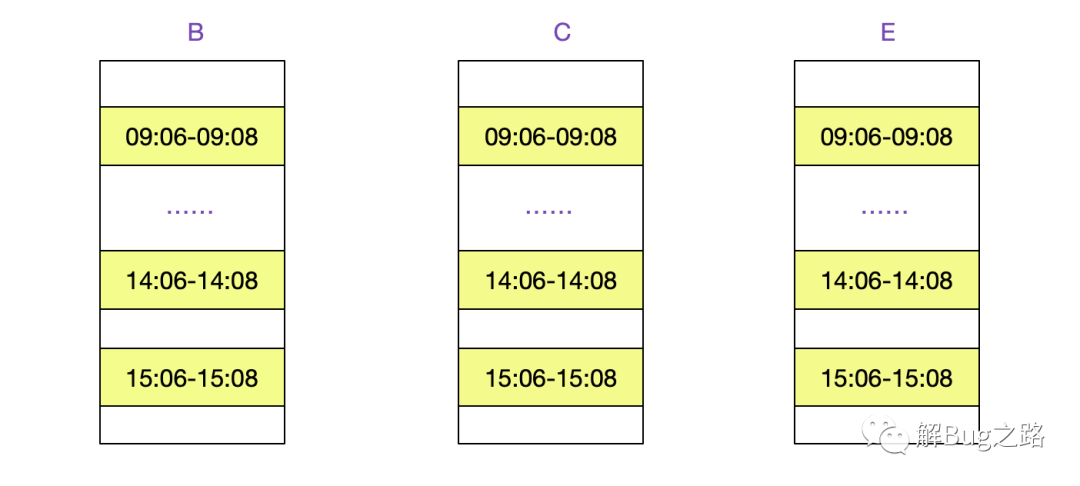
所有调用慢的机器,都非常巧的在每个小时06-08分钟之内调用慢。再观察下慢的请求,发现他们也全部是分布在不同小时的06-08分时间段内!
定时任务?
第一反应是有定时任务,查了下所有调用机器的crontab没有问题。问了下对应的开发有没有调度,没有调度,而且那个时间段由于耗时的原因,每秒请求数反而变小了。翻了下机器监控,也都挺正常。思维陷入了僵局,突然笔者灵光一闪,我们的应用全部是在KVM虚拟机上,会不会是宿主机出了问题。于是联系了下SA,看看这些机器的宿主机是个什么情况。
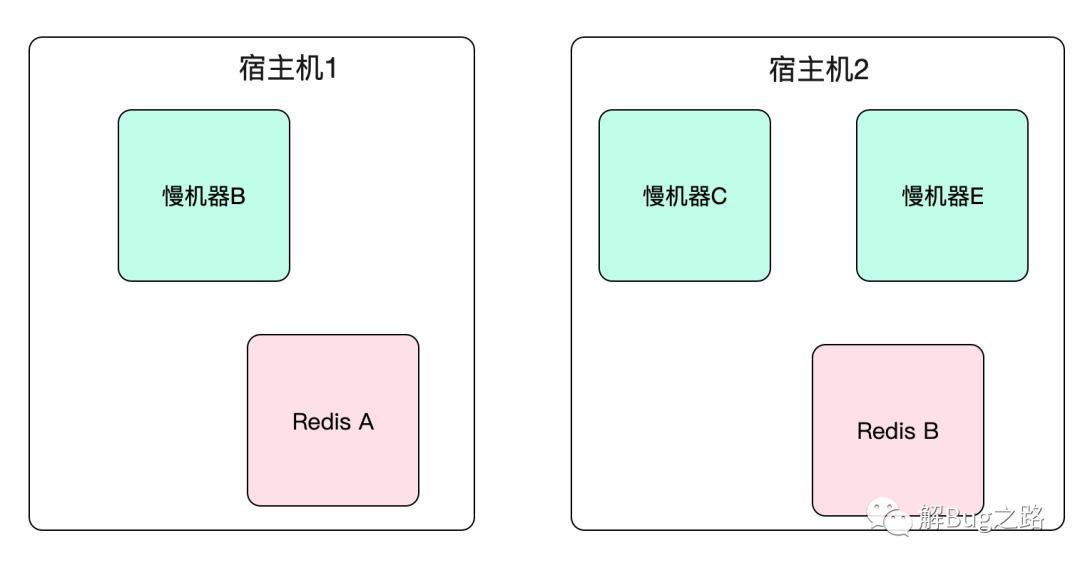
每个变慢的机器的宿主机都有Redis!
这一看就发现规律了,原来变慢的机器上都和Redis共宿主机!
登陆上对应的Redis服务器,发现CPU果然在那个时间点有尖峰。而这点尖峰对整个宿主机的CPU毫无影响(毕竟宿主机有64个核)。crontab -l 一下,果然有定时任务,脚本名为Backup!它起始时间点就是从06分开始往GlusterFS盘进行备份,从06分开始CPU使用率开始上升=>07分达到顶峰=>08分降下来,和耗时曲线完全一致!
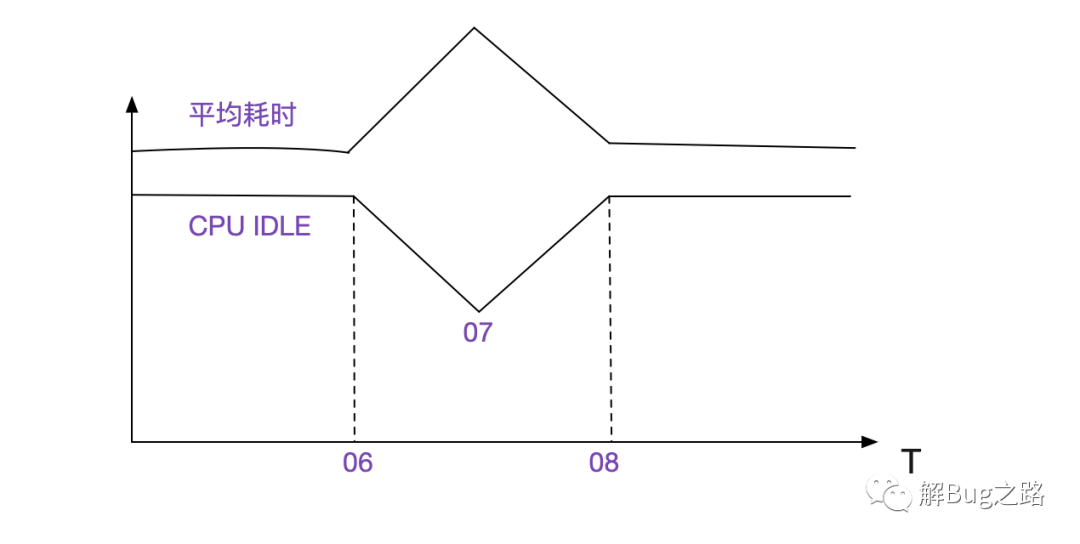
原来Redis往Gluster盘备份占据了大量的IO操作,所以导致宿主机上的其它应用做IO操作时会变得很慢,进而导致但凡是这个备份时间内系统间调用的平均耗时都会暴涨接近10倍,最终导致了高耗时的请求。
为什么调用请求超时1s的概率这么低
由于我们线上每个应用都有几十台机器,而基本每次调用只有几十毫秒。所以只有这个请求连续落到三个甚至多个和Redis共宿主机的系统里面才会导致请求超过1s,这样才能被我们的统计脚本监测到,而那些大量的正常请求完全拉平了平均值。
解决方案
我们将线上实时链路的系统从对应有Redis的宿主机中迁移出来,再也没有那个尴尬的1s了。
总结
在遇到问题,并且思路陷入僵局时,可以通过一些脚本工具,例如grep以及awk或者其它一些工具对众多日志进行分析,不停的去寻找规律,从无序中找到有序,往往能够产生意想不到的效果!欢迎大家加我公众号,里面有各种干货,还有大礼包相送哦!




