
导致程序出现OOM的因素,夜深人静的时候,程序OOM异常追踪原创
作为Java程序员, 除了享受垃圾回收机制带来的便利外, 还深受OOM(Out Of Memory)的困惑和折磨.
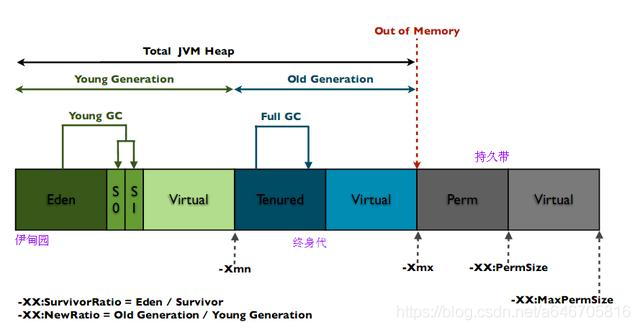
先来看下java的内存分布
堆溢出(heap)
编写如下例程:
public static void main(String[] args) {
List<byte[]> datas = new ArrayList<byte[]>();
while ( true ) {
datas.add(new byte[1024 * 1024]);
}
同时设置虚拟机参数, 使得java进程能够快速生成heapdump.
-Xms20m -Xmx20m -XX:+HeapDumpOnOutOfMemoryError
评注: 设置heap的内存限制在20m, Xms/Xmx分别对应heap的初始和最大heap大小。
产生的异常信息:

mat进行内存分析
从这边能看出, 这边聚集了众多的对象, 占据了99%的内存量.

栈溢出(stack)
栈溢出的异常, 还是具有明确的指向性的. 暂略.
永久代溢出(常量池/方法区)
String.intern()和cglib动态代理类的两个例子.
其错误也很有指向性:
Exception in thread “main” java.lang.OutOfMemoryError: PermGen space
这边讲述下, 小编(mumuxinfei)很久之前做的一个项目.
OOM的原因分类
导致程序出现OOM的因素有多种. 大致我们可以把OOM简单的分为堆溢出(Heap), 栈溢出(Stack), 永久代溢出(常量池/方法区), 直接内存溢出.
- outOfMemoryError 年老代内存不足。
- outOfMemoryError:PermGen Space 永久代内存不足。
- outOfMemoryError:GC overhead limit exceed 垃圾回收时间占用系统运行时间的98%或以上。
在这里我们就要结合代码,观察是否大量应该被回收的对象在一直被引用或者是否有占用内存特别大的对象无法被回收。
问题展示
导致程序出现OOM的因素,夜深人静的时候,程序OOM异常追踪
日志文件:

时间戳 [http-nio-端口号-exec-1] ERROR ResponseExceptionHandle:26 - Handler dispatch failed; nested exception is java.lang.OutOfMemoryError: GC overhead limit exceededorg.springframework.web.util.NestedServletException: Handler dispatch failed; nested exception is java.lang.OutOfMemoryError: GC overhead limit exceeded****中间一大段****Caused by: java.lang.OutOfMemoryError: GC overhead limit exceeded
这个时候要是有可视化界面就好了(或者拥有运维的电脑,自己用Arthas上去),没办法,只能让运维线程栈信息以及内存信息下载下来。
Linux上生成文件命令
#生成堆转储快照dump文件命令jmap -dump:format=b,file=heapdump.hprof pid# 生成堆栈信息文件命令jstack -l pid >> stack.txt
堆栈信息查看
"http-nio-端口号-exec-1" #37 daemon prio=5 os_prio=0 tid=0x00007f789d236800 nid=0x650e waiting on condition [0x00007f7851409000] java.lang.Thread.State: WAITING (parking)at sun.misc.Unsafe.park(Native Method)- parking to wait for <0x00000000faa51ba0> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)at java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)at org.apache.tomcat.util.threads.TaskQueue.take(TaskQueue.java:103)at org.apache.tomcat.util.threads.TaskQueue.take(TaskQueue.java:31)at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61)at java.lang.Thread.run(Thread.java:745) Locked ownable synchronizers:- None****等等容器内其他线程
上面只是我截取整个线程堆栈信息的一个容器线程状态查看,整个文件下来是没有发现死锁的发生,那线程方面是没有问题的,不会有线程相互竞争资源造成服务内部请求阻塞而造成OOM的情况发生。
堆转储快照查看
我们通过上面那条指令,以hprof二进制格式转储Java堆到指定filename的文件中。按照普通的文件方式打开肯定是行不通的(你在想啥呢?醒醒)。我这边是有两种方式去处理分析这种文件的。
利用jhat

利用JDK里面的指令去分析文件(有时dump出来的堆很大,在启动时会报堆空间不足的错误,可加参数:jhat -J-Xmx512m 。这个内存大小可根据自己电脑进行设置。):
接着你就可以在浏览器里面输入 http://localhost:7000/进行访问:
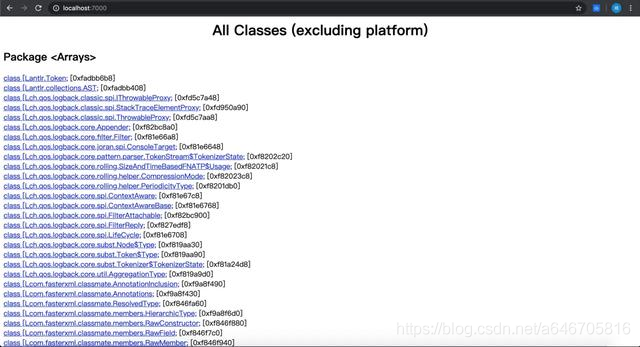
当前页面是展示了当前容器内包含的类以及id。页面的最下面是导航栏了:

一般查看堆异常情况主要看这个两个部分:
- Show instance counts for all classes (excluding platform),平台外的所有对象信息。
- Show heap histogram,以树状图形式展示堆情况。
要注意的是,一般不会直接在服务器上进行分析,因为jhat是一个耗时并且耗费硬件资源的过程,一般把服务器生成的dump文件复制到本地或其他机器上进行分析。
利用Memory Analyzer
打开mat(MAC端安装MAT)然后导入文件:
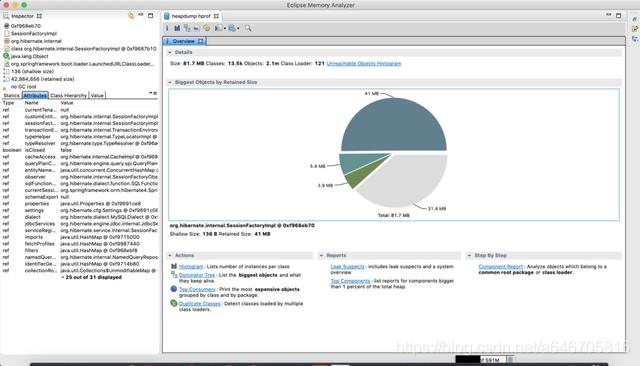
这里面参数说明很多
Shallow Heap 表示一个对象消费的内存的总量。对象 X 的 Retained Set 指的是一旦 X 被垃圾回收后也会随之被 GC 回收掉的对象的集合。对象 X 的 Retained heap 指的是 X 的 retained set 中所有对象的 shallow heap 之和,或者说是因为对象 X而保持 alive 的内存的大小。
我们查看下面的选项:
我们看到最大的那个区域就好(占用了41MB的):我们可以看到左下角是显示对象的名称:org.hibernate.internal.SessionFactoryImpl。我们的技术栈持久层框架使用的是hibernate
我们点击Leak Suspects,然后出现:

经过MAT出现了两个怀疑内存泄露相关的问题:

我们通过查看下面的问题描述知道:
Question1:被LaunchedURLClassLoader类加载器加载的一个SessionFactoryImpl实例中的BoundedConcurrentHashMap堆积着内存空间,占据了42,984,656字节。
Question2:该内存中存在被SystemClassLoader加载的7,941个Class对象,占据了10,075,768字节。
从Q1入手进行查看:
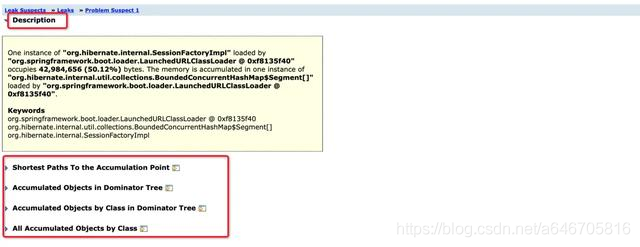
我们这里就选择从下面三个都可以进行查看当前容器内部的内存堆积问题。上面的第二个是从堆积点一直追踪到线程,可以看到每一个线程对应的Shallow Heap以及Retained heap。
我们这里就查看第三个:
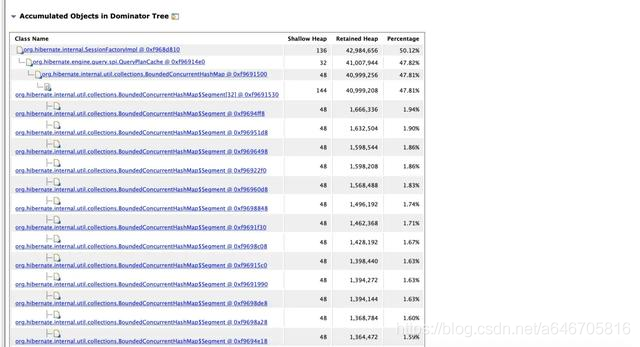
我们查看到是SessionFactoryImpl中的QueryPlanCache中存在一个Map集合,该集合占据了大量的内存空间。这个类实际运用中还没有使用到过,不过看这个提示以及名称,个人觉得跟ConcurrentHashMap相似(有大佬对BoundedConcurrentHashMap了解的嘛,可以评论下让我涨涨知识)。通过QueryPlanCache的名字,就可以知道它是用来缓存查询计划的,也就是缓存sql语句,以便于后边的相同的sql重复编译。
总结:
本人故障定位中查到的N多OOM问题,原因不外乎以下3类
1、线程池不管理式滥用
2、本地缓存滥用(如只需要使用Node的id,但将整个Node所有信息都缓存)
3、特殊场景考虑不足(如采用单线程处理复杂业务,环境震荡+多设备下积压任务暴增)
利用gc.log进行OOM监控=========
针对JVM的监听,JDK默认提供了如jconsole、jvisualVM工具都非常好用。



