
我司基础组件更新本地缓存策略问题导致young gc时间升高原创
背景
有次想研究一下服务QPS和young gc的时间的关系。假如服务对外提供的接口的平均响应时间是1s,那么最坏情况下该请求用到的对象就应该存活1s(为什么是最坏,因为很多中间变量不需要这么存活这么久)。如果QPS由100升高到200,那么在1s之内存活的对象应该要翻倍,那么在young gc的时候copy时间基本上也要翻倍,root 扫描阶段应该会稍微的升高但是应该不明显。带着这样的假设去看了服务的高峰期和低峰期young gc时间,发现基本上没啥变化。young gc meantime如下图:
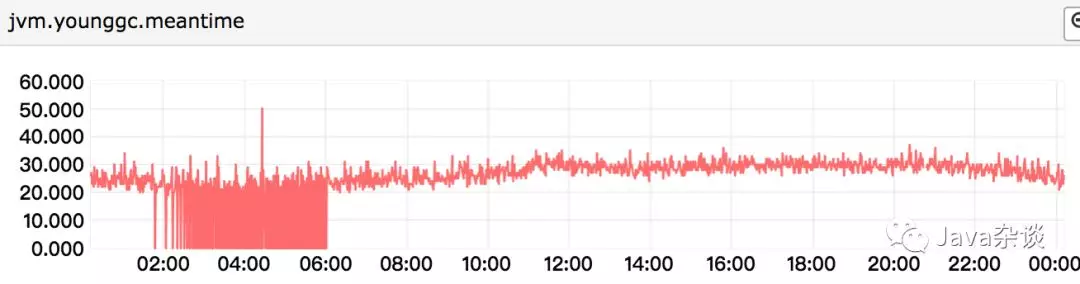
问题追踪过程
于是去看了一下gc log,不管是在业务高峰期还是低峰期,每次从eden区域中晋升到survivor区域中的对象大小都差不多,并且再次young gc的时候这些对象就会释放。gc log 如下:
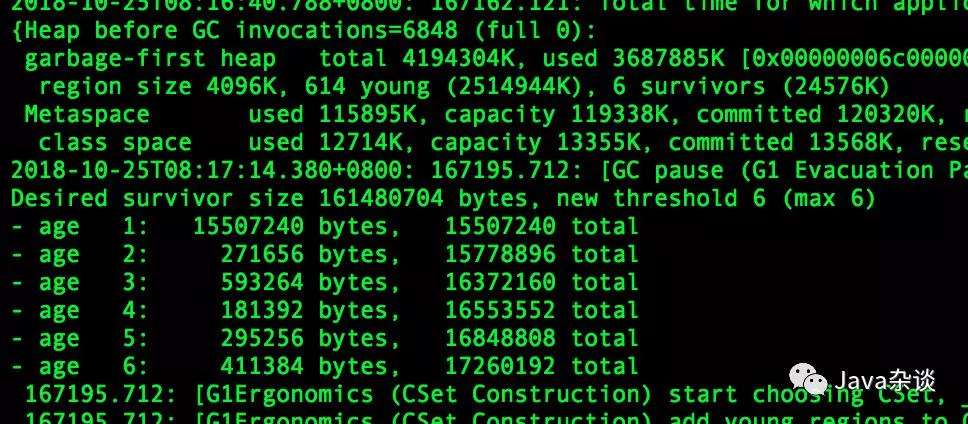
于是先用gdb 去dump了下来survivor区域中的内容,发现了异常点。survivor区域里面有MCC(我司的配置中心)的内容。理论上只要配置中心没有变化,这些值早点应该进入到了old区域啊,不可能在survivor区域。内容如下:
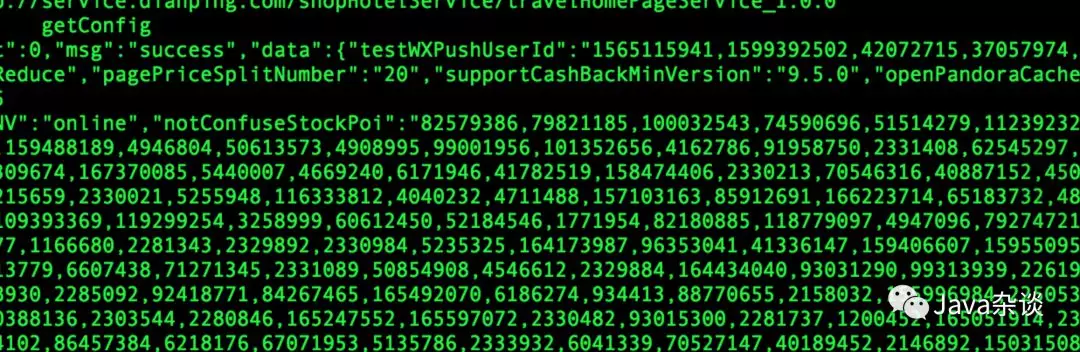
为什么防止误判,我过一段时间就重新dump下内容发现每次都有,有时候会有两份MCC的内容。肯定确定MCC有问题。于是向MCC的人反馈有问题,但是MCC人坚持认为没有问题,他们认为这是定时拉取动作应该有的表现(PS:我觉得他们对于GC这块理解可能有点问题才会认为没有问题)。
之后有事比较忙,这个事情就放下了。前一段时间有时间就重新看了一下这个问题,用vjmap去看了一下survivor区域的内容,发现里面包含大量基础组件的内容不仅仅是MCC,服务依赖的下游服务节点数据都在survivor中存活。对象如下图:
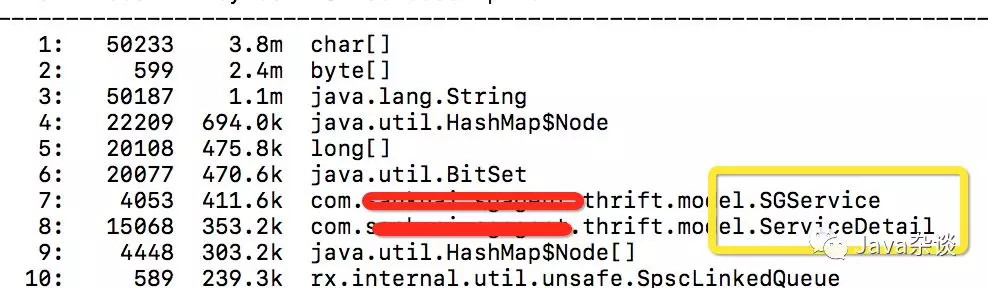
SGService、SGServiceDetail都是基础组件的对象,并且SGService里面包含大量的map,String等信息。
于是我就翻看了他们这一块相关的代码,很快就发现了问题。发现他们有个定时拉取的从agent拉取对象的定时任务,拉取之后全量更新本地缓存。代码如下:
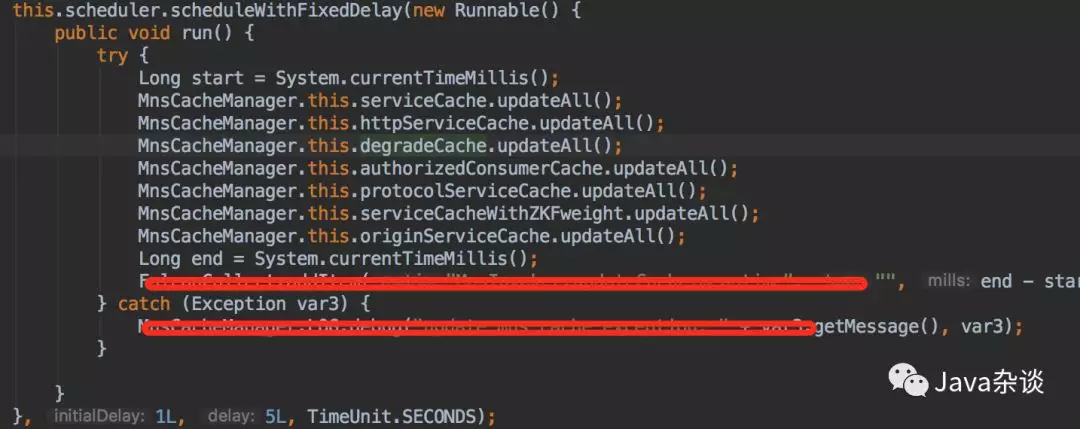
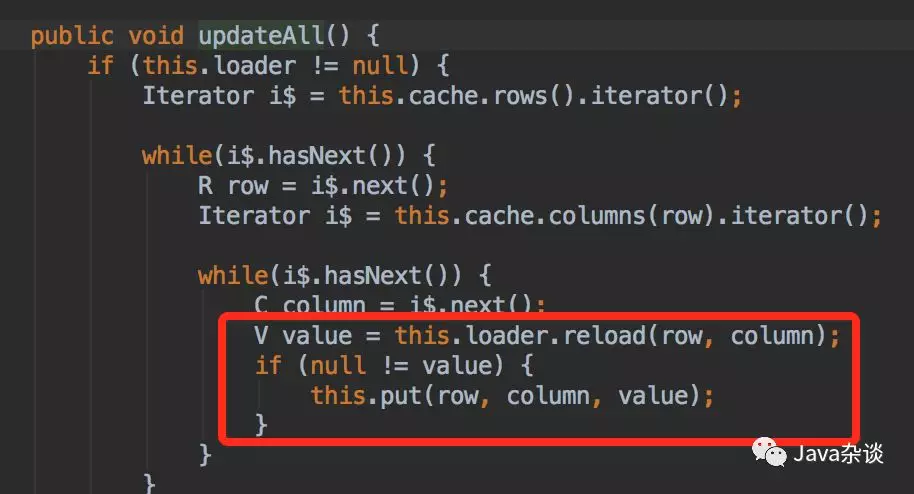
其中reload方法就是从agent上获取拉取实时数据,从agent拿到对象之后直接替换了cache里面的内容,就会导致每次从agent获取的对象都会生存5s,young gc的时候存活下来,copy阶段时间会延长;特别在依赖的下游服务机器比较多的时候。
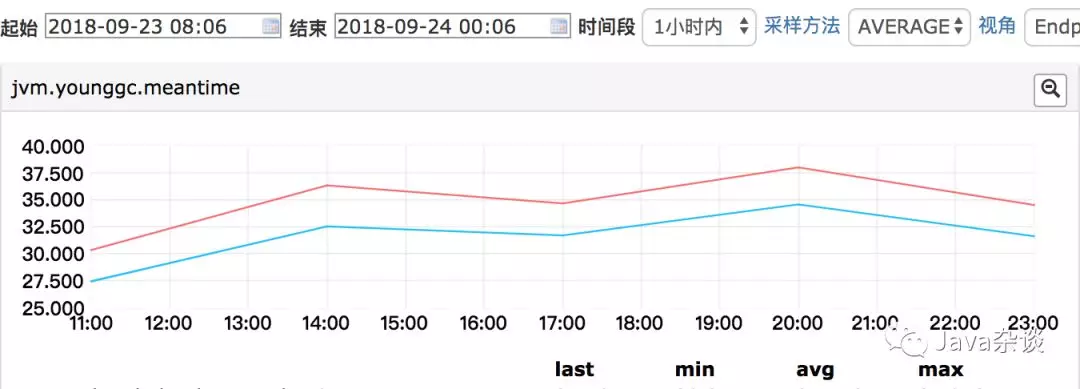
我自己把他们这个定时任务给去掉,重新上线测试了一下,young gc 时间提升还是很明显的,监控如下:
昨天刚好群里也说到基础组件可能有问题的事,我就把这个问题给抛出来了,终于基础组件相关人联系我了并且确认了问题的存在他们需要评估一下修正一下。
总结
在做定时拉取数据的时候,一定要先diff,只有不同的时候在再替换,不要直接以最新的数据替换老的数据。
但是QPS和young gc 时间的关系还没有研究清楚呢。



