
线程说:不是我想爆炸,只怪你Nd4j没用好原创
5年前
932829
一、项目介绍
web_rec_comm_ctr
背景:
去年接手了一个排序服务,用于播单、声音、主播排序。接手以来处理过内存溢出问题,后面也没再出现过其他状况。但是最近该项目用于离线任务计算后,出现了问题。并且问题发生时间是在计算量扩量之后。
项目背景:
- 该项目与算法的配合方式:项目提供接口规范,涉及:排序算法加载、自动更新、模型调用、输入参数解析、告知模型所需特征数据(包括特征表、表字段等)。
- 项目需要做的事:加载算法–>解析请求数据–>获取特征数据–>调用模型排序–>解析排序结果–>结果拼装返回。
二、问题背景
1、发现项目的k8s容器会出现重启现象。
发生问题时,容器配置:CPU:4个:排序计算需要; 内存:堆内6G:w2v模型本地加载; 堆外3G:各种算法包计算使用。
三、问题结论:
Nd4j计算框架在做计算时(使用了OpenMP库:OpenMP是一个开源的并行编程API,支持C/C++/Fortran语言。ND4j使用以C++编写的后端,因此我们用OpenMP来改善CPU的并行计算性能。),库里面直接调用pthread_create进行线程创建,多线程并行计算。由于对该领域的包不是很了解,就不深挖该计算框架的优化。直接摒弃该库采用其他方式做计算。
四、问题排查流程
查看监控系统,观察重启发生时,容器实例的资源情况
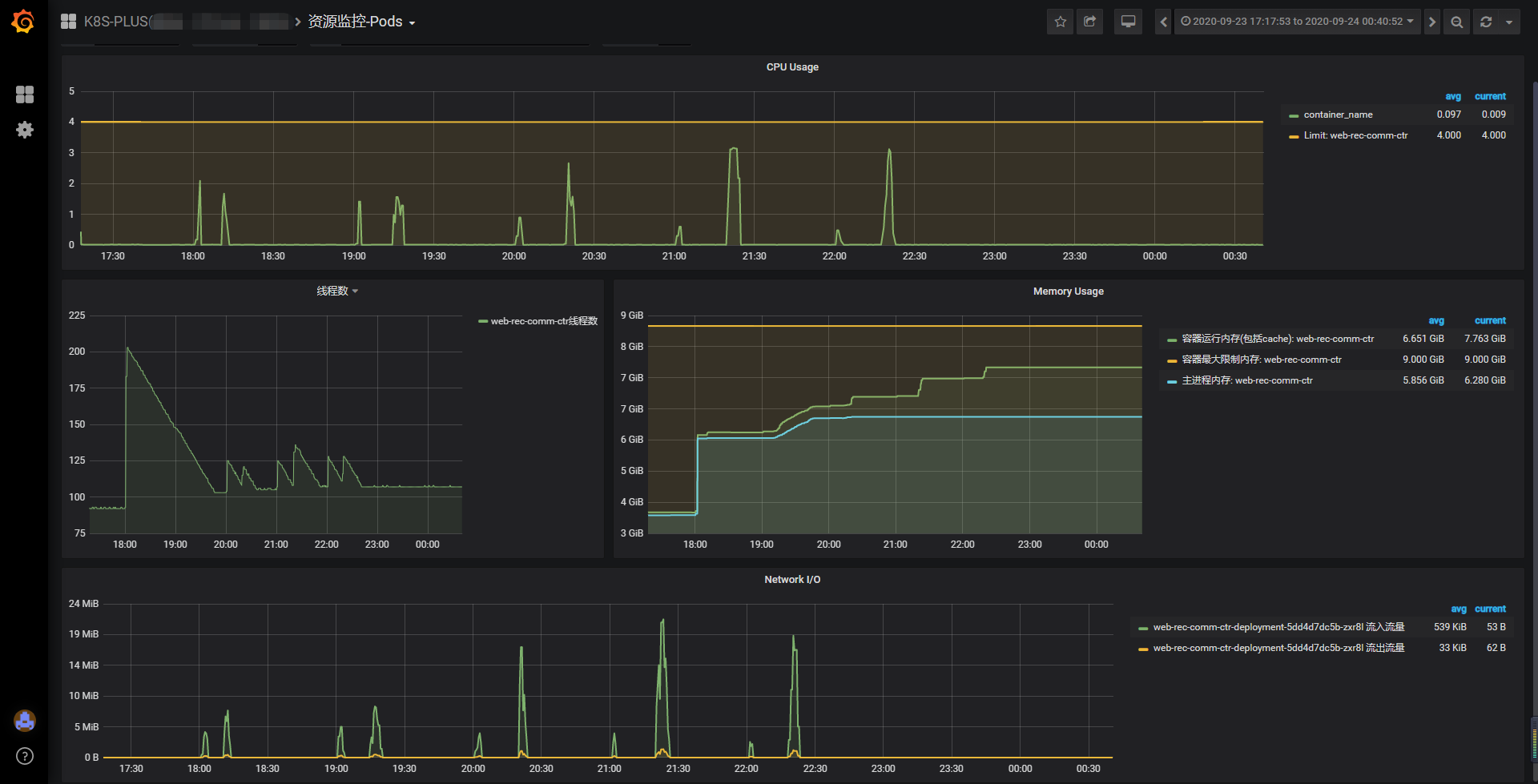
注:先别急着纳闷这个项目的监控数据图看着那么多毛刺。这个排序服务是为离线定时任务服务的。
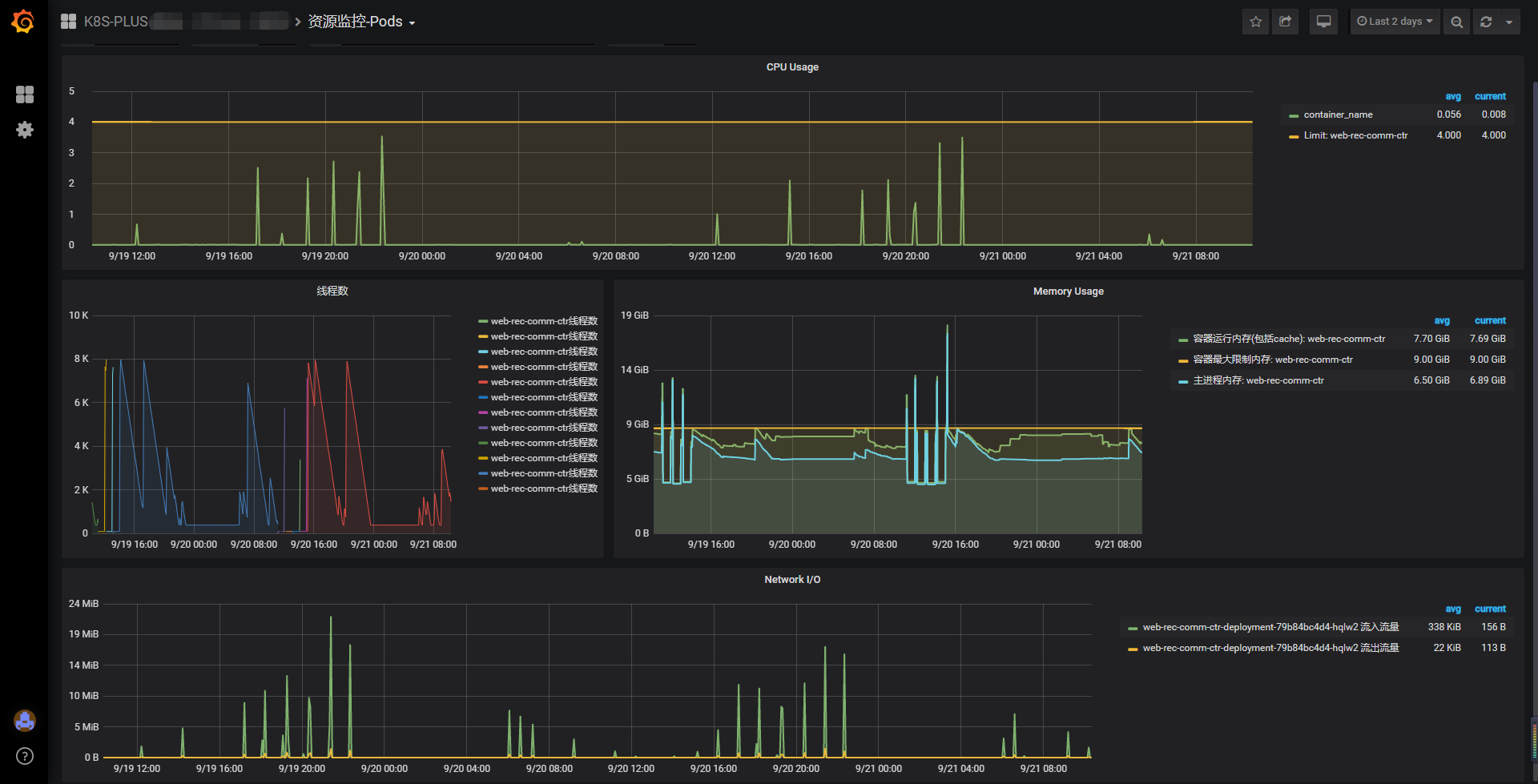
监控数据观察:
- 首先,线程数呈现出异常情况,最高接近8k。
- 其次,发现最开始出现问题的时候,任务的数据量是比较少量,而不是大量计算才发生问题。
- 第三,大部分情况下,重启的时间刚好跟线程达到峰值对上。连续重启一般是:上一次重启的时候,服务拥入大量请求,线程陡增,然后又重启了…
- 第四,也不是每一次任务触发都会发生重启,且根据线程图可以知道,线程是有进行回收的动作,不大可能是永久资源泄漏。好熟悉的感觉,难道又是资源使用后没释放,直到垃圾回收时被动释放资源…
根据第一点,在下次任务来临时,dump下线程栈:jstack pid,使用线程分析网站:fastThread
此时我的表情是这样的:
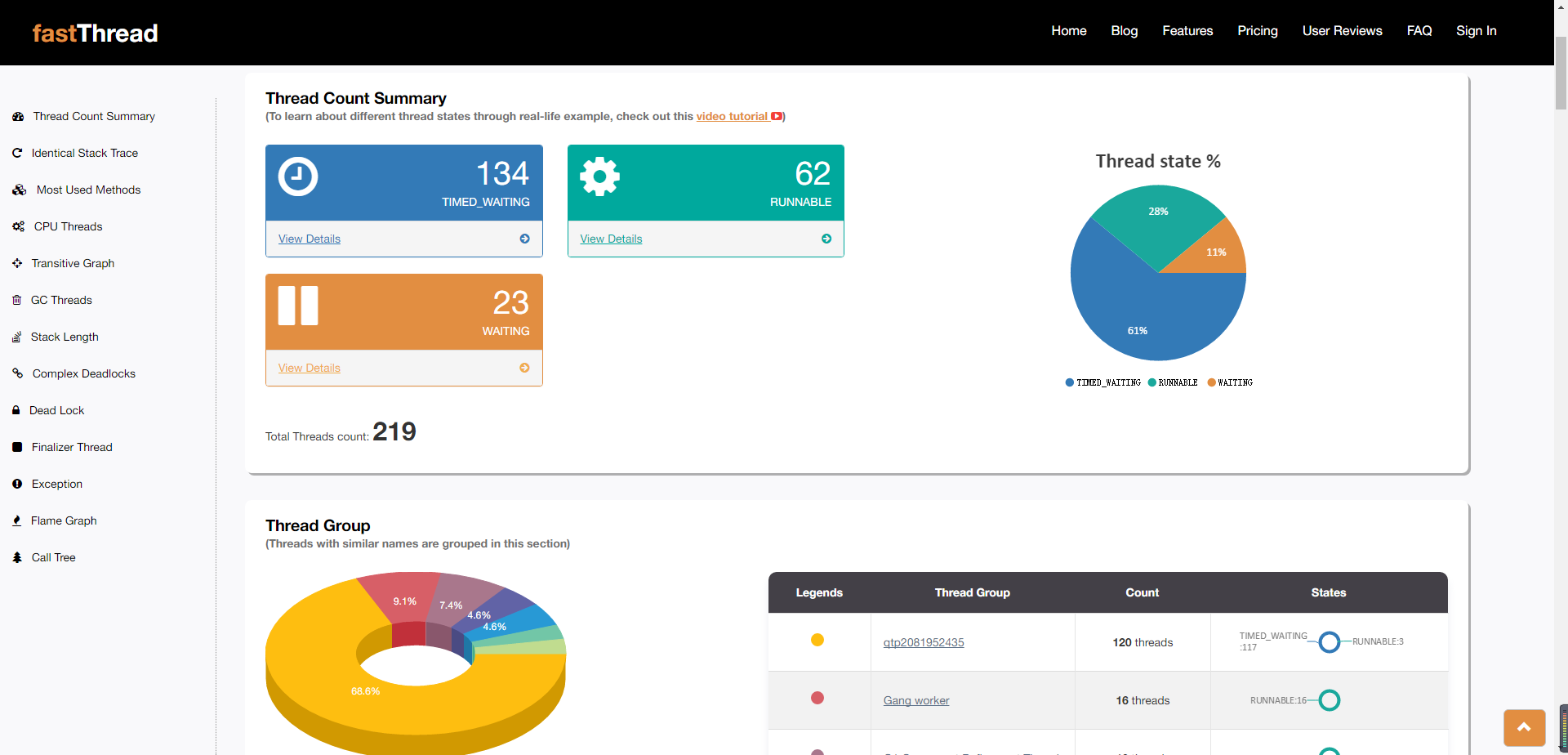

- 说好的8k个线程呢…难道是…我打开的方式不对…好吧,愣了一下。jstack命令dump下来的线程一般是由jvm生成的管理的线程,而native方法产生的线程是不由jvm进行管理的,这也就是为啥jstack命令dump下来的线程栈就只有这么一点。
- 注:别妄想用jstack -m参数dump线程,说实话,dump下来的东西看了之后心态更蹦,好吧其实是我看不懂。
- 通过跟运维大佬请教,监控中使用了ps命令的-L参数,使用ps -efL | grep pid | wc -l果然跟监控系统的统计是对的上的。
- 此时怀疑是本地线程使用泛滥导致的。
定位那些native线程是由什么创建的:(以下方法来自李老师的指导,向李老师学习。)
- 这个时候只能祭出cat /proc/$pid/maps了,至于maps文件是干嘛的…嗯,可以参考一下:/proc/{pid}/maps解读,虚拟内存 、 linux proc maps文件分析
- 然后用pstack看看那些多余的线程堆栈的是什么,用地址对比一下就找到openmp这个库了。
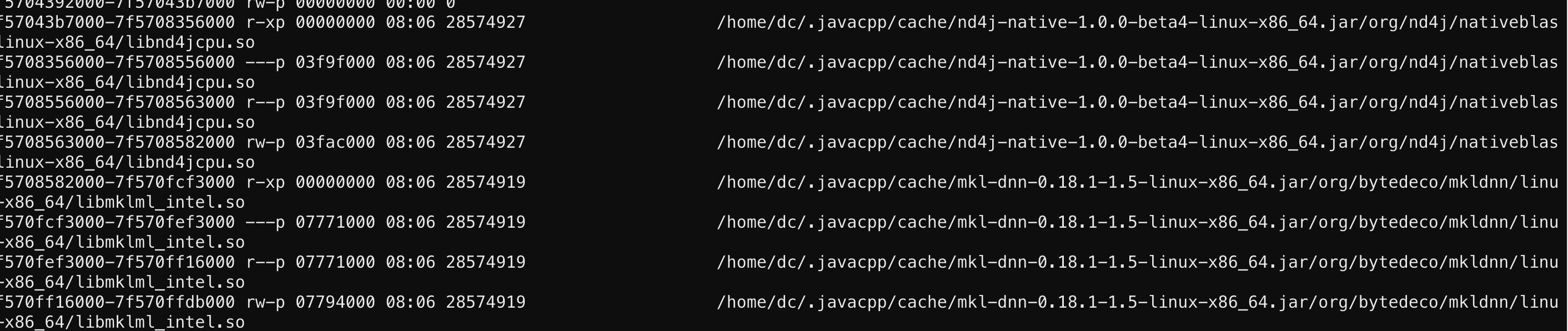
- 根据上图可以锁定mkl和nd4j,在项目中瞅瞅是哪里引入:mvn dependency:tree
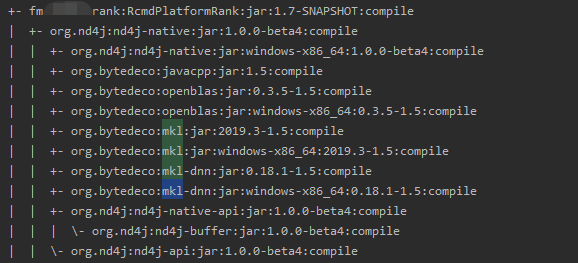
- 该库的引入来自于算法同事提供的模型计算包。翻看代码中,在做计算时确实用到了该库,以下随机抽了使用片段。
public float[] userWord2Vec(List<HashMap<String, Object>> list, Word2VEC word2vecModel, int audioVectorDim,
int topK, boolean norm){
/*
* @描述: 获取用户的分布式表示[将播放序列的节目向量的和或者均值作为用户的向量表示]
* @参数: [list, topK, norm]
* @返回值: float[]
* @创建时间: 7/23/19
*/
float[] userVec_ = new float[audioVectorDim];
INDArray userVec = Nd4j.create(userVec_, new int[]{1, audioVectorDim});
- 翻看算法同事的代码发现,INDArray对象使用后,并未做资源释放,尝试修改代码,在计算后,对使用的资源进行释放。但遗憾的是,尽管加入释放代码,发版后依然出现相同的状况。
- 此时只能硬着头皮翻翻源码了,毕竟问题现象是线程泛滥,看看有没有地方可以设置,限制该库的线程使用数,牺牲并发度。以下为org.nd4j:nd4j-api:jar:1.0.0-beta4:compile依赖下ExecutorServiceProvider类源码
public class ExecutorServiceProvider {
public static final String EXEC_THREADS = "org.nd4j.parallel.threads";
public final static String ENABLED = "org.nd4j.parallel.enabled";
private static final int nThreads;
private static ExecutorService executorService;
private static ForkJoinPool forkJoinPool;
static {
int defaultThreads = Runtime.getRuntime().availableProcessors();
boolean enabled = Boolean.parseBoolean(System.getProperty(ENABLED, "true"));
if (!enabled)
nThreads = 1;
else
nThreads = Integer.parseInt(System.getProperty(EXEC_THREADS, String.valueOf(defaultThreads)));
}
- 通过上图,尝试在启动参数里加入-Dorg.nd4j.parallel.enabled=false,直接将并发计算一刀切。so sad,结果依然是线程泛滥。此处设置应该是限制单次计算由并行改为单线程计算,并没有解决线程资源未回收的问题。
- 无奈只能求助google:工作区指南 、Deeplearning4j的本机CPU优化 尝试修改线程、垃圾回收等配置,但依然毫无改善问题。(ND4J确实不了解,工作区概念什么的也看懵了…)
五、解决方案
最终只能求助于算法大佬,看能否换其他库做计算或者自己实现计算。首先确认改动成本有多大,确保以最小的代价去解决:
- 该项目中大部分排序算法已迁移到“模型服务平台”中,剩余的算法也只是支持少量的计算工作,所以此处仅需修改在还在改项目中使用的算法。(嗯…其实就剩两个了。)
- 使用到的算法中,对于Nd4j的使用是在于矩阵计算,而非复杂的模型训练或者模型计算。所以替换的计算逻辑完全可以由其他工具包快速替换或者快速手写实现。
- 算法大佬修改实现后,重新引入发版观察。谢天谢地,总算回归正常。
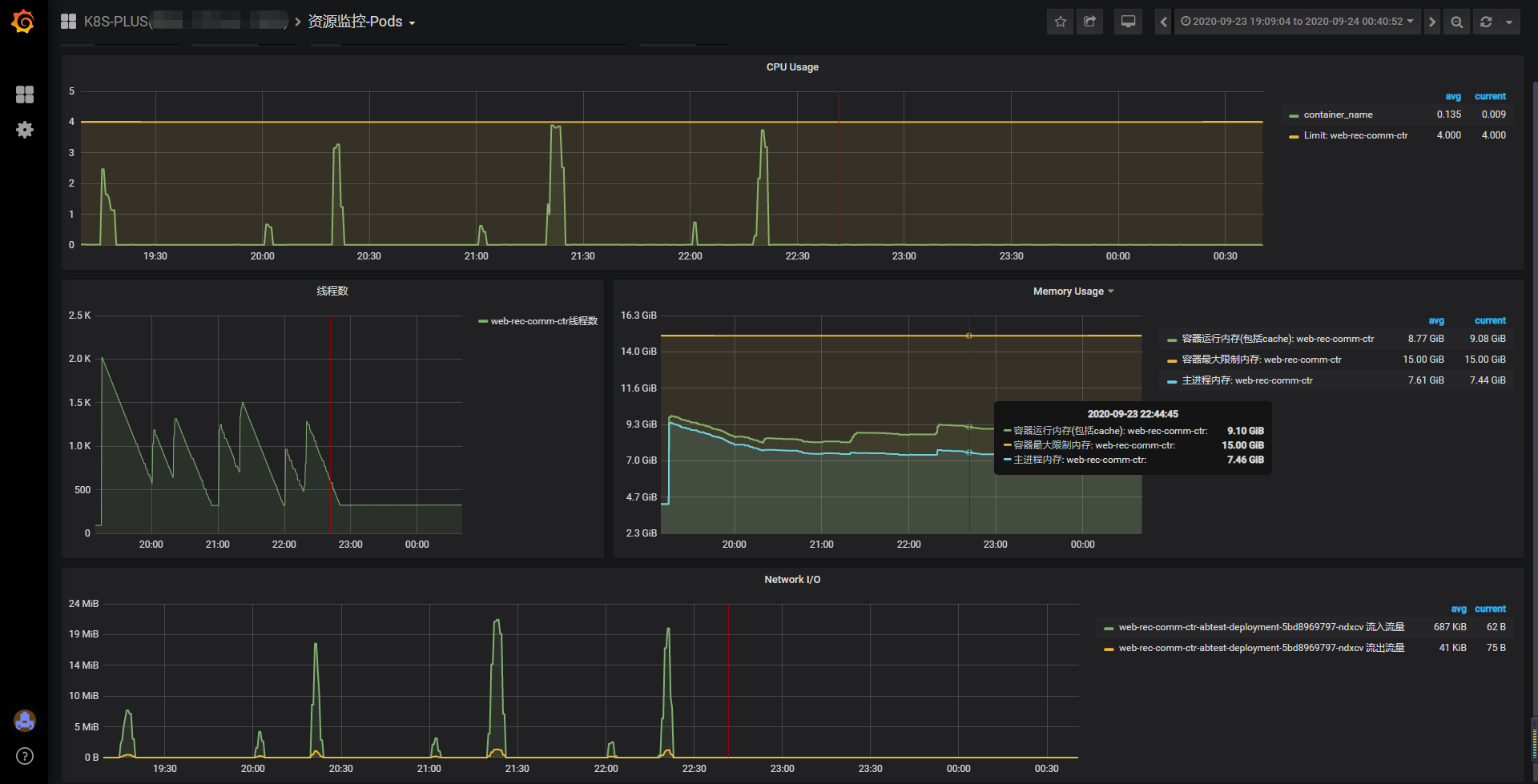
- 其实在解决发版后,又偷偷发了一个节点,版本是解决问题前的。将内存提升到15G,堆内依然是6G,堆外预留9G。留着该节点且预留大堆外内存是为了验证本次修改是否解决问题。果然该节点发版后,虽然未出现重启现象。但是其内存一度超过9G,如果未扩容,应该又是一次重启。且线程数又出现陡增情况。但是线程又出现回收情况,此处猜想是GC带来的影响,堆内的对象被回收之后,其指向外部的资源也被回收利用了。后续有时间将了解一番。现在持续观察是否再出现问题。
六、总结
涉及native方法调用的第三发库使用最好先了解其工作原理再进行使用,尽量能做到资源使用可控,及时释放资源。虽然本次问题触及的知识领域比较陌生,还是尽可能去了解自己项目里面引入的东西会该来什么影响。
点赞收藏
分类:



