
深(浅)入(出)剖析G1(Garbage First)原创
Java从JDK7U9开始支持G1(正式发布),所以,如果要使用G1的话,你的Java版本应该是JDK7U9或者更新的版本。不过,强烈建议JDK8才使用G1,而且最好是JDK8的最新版本,因为在JDK7~JDK8最新版本迭代过程中,Java针对G1垃圾回收期做了大量的优化工作。
G1垃圾回收器是为多处理器和大内存的服务器而设计的,它根据运行JVM过程中构建的停顿预测模型(Pause Prediction Model)计算出来的历史数据来预测本次收集需要选择的Region数量,然后尽可能(不是绝对)满足GC的停顿时间,G1期望能让JVM的GC成为一件简单的事情。G1旨在延迟性和吞吐量之间取得最佳的平衡,它尝试解决有如下问题的Java应用:
-
堆大小能达到几十G甚至更大,超过50%的堆空间都是存活的对象;
-
对象分配和晋升的速度随着时间的推移有很大的影响;
-
堆上严重的碎片化问题;
-
可预测的停顿时间,避免长时间的停顿。
- 开启G1
介绍G1之前先简单的说一下如何开启G1,在JDK9之前,JDK7和JDK8默认都是ParallelGC垃圾回收。到了JDK9,G1才是默认的垃圾回收器。所以如果JDK7或者JDK8需要使用G1的话,需要通过参数(-XX:+UseG1GC)显示执行垃圾回收器。而JDK9以后的版本,不需要任何JVM参数,默认就是G1垃圾回收模式,显示指定G1运行一个Demo程序如下:
java -Xmx1g -Xms1g -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -jar demo.jar
- G1堆
G1的堆结构,是Java发展这么多年,第一次发生这么大的变化。以前,无论是使用SerialGC,ParallelGC,还是CMS,堆的年轻代和老年代都是连续的,且堆结构图都是如下所示:
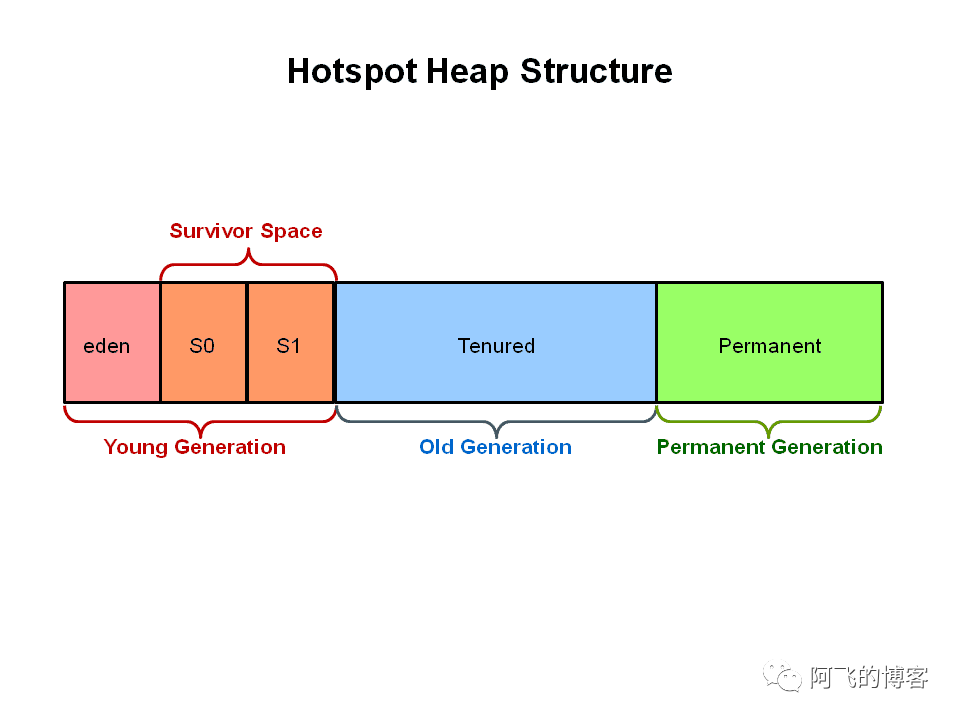
而G1的堆是基于Region设计的,事实上,这些Region本质上就是Eden、Survivor和Old,而且同类型的Region可以不连续。如下图所示:

图片中不同的颜色表示不同的Region,Region被设计为在停止所有其他应用程序线程的情况下并行收集,即是STW的。
另外,除了图中3种常见的Region类型,还有第四种特殊的Region,即:Humongous,它是特殊的老年代Region。这种Region被设计用来保存超过Region的50%空间的对象,它们存储在一系列连续的Region中。通常来说,超大对象只会在最终标记结束后的清理阶段(cleanup)才会被回收,或者发生FullGC时。但是在JDK8U40的时候,JDK更新了一些收集超大对象的特性,以至于在YGC的时候,G1也能回收那些没有任何引用指向的超大对象,可以通过参数-XX:+G1ReclaimDeadHumongousObjectsAtYoungGC控制,这个参数后来被更名为-XX:+G1EagerReclaimHumongousObjects,并且可以通过参数-XX:+G1TraceEagerReclaimHumongousObjects跟踪并输出超大对象回收相关信息。
超大对象的分配可能导致过早的发生垃圾回收,每一个超大对象分配时,G1会检查初始堆占用阈值-XX:InitiatingHeapOccupancyPercent,如果占用比例超过了阈值,那么就会触发全局并发标记。如果超大对象的分配导致连续发生全局并发标记,那么请考虑适当增加参数 -XX:G1HeapRegionSize 的值,这样一来,之前的超大对象就不再是超大对象,而是采用常规的分配方式的普通对象。另外,超大对象的分配还会导致老年代碎片化,需要注意。
超大对象从来不会被移动(但是可以被清理),即使发生的是FullGC。这可能会导致过早的FullGC或者一些意料之外的OOM,而事实上还有很多可用堆空间。
JVM启动的时候就会自动设置Region大小,当然,你也可以自己指定Region的大小(例如-XX:G1HeapRegionSize=4m)。Region数量最多不会超过2048个,每个Region的大小在1~32M之间,且必须是2的N次方。这就意味着,如果堆内存少于2048M(2G),那么Region数量就会少于2048个。
以前GC的垃圾收集主要分为年轻代的垃圾收集和老年代的垃圾收集,G1这点类似,主要分为年轻代的垃圾收集,即YGC;以及混合收集,即Mixed GC。接下来,我们深入了解一下G1的这两种垃圾收集。
事实上,G1和CMS还有一个相同点,在并发模式GC搞不定的时候,也会发生FullGC,即整个过程完全STW。
Young GC
G1的YGC回收前是这样的,当Eden满了后,就会触发YGC,这一点和以前的ParallelGC以及CMS+ParNew是一样的:
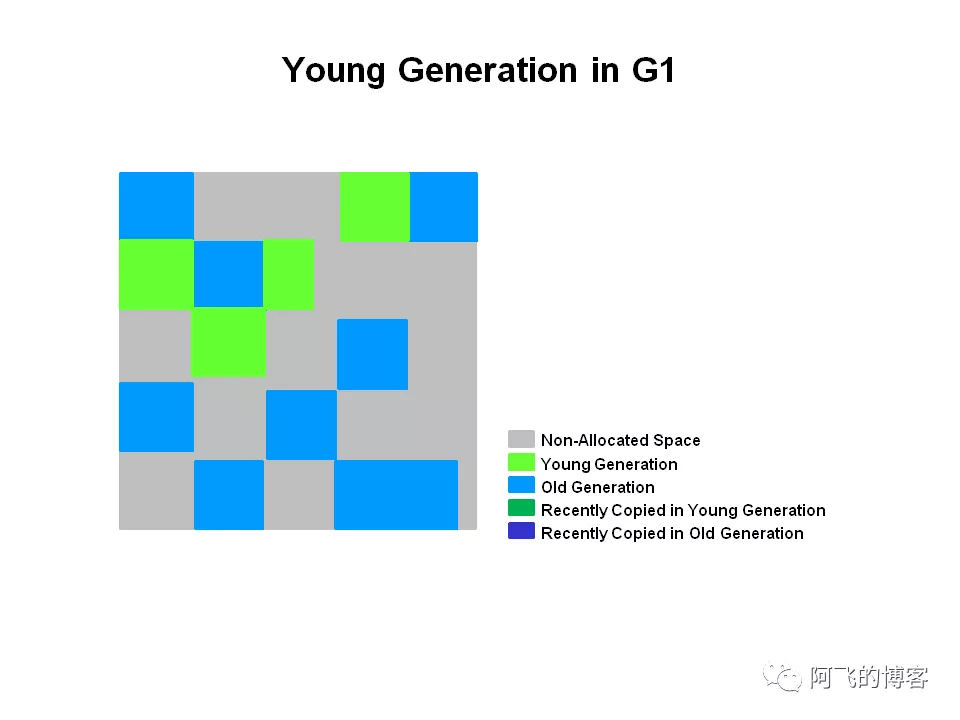
G1的YGC要做的事情如下图所示,年轻代存活的对象会被从多个Region(Eden)中拷贝并移动到1个或多个Region(S区),这个过程就叫做Evacuation。如果某些对象的年龄值达到了阈值,就会晋升到Old区,这一点和以前的GC类似:

G1的YGC也是一个完全STW的过程,且多线程并行执行的阶段,对应的日志如下所示:
[GC pause (G1 Evacuation Pause) (young) 898M->450M(1024M), 0.0005367 secs]
并且为了下一次YGC,Eden和Survivor的大小会被重新计算,计算过程中用户设置的停顿时间目标也会被考虑进去,如果需要的话,它们的大小可能调大,也可能调小。
存活的对象被拷贝并移动到Survivor或者晋升到Old区(如果有满足条件的对象的话):
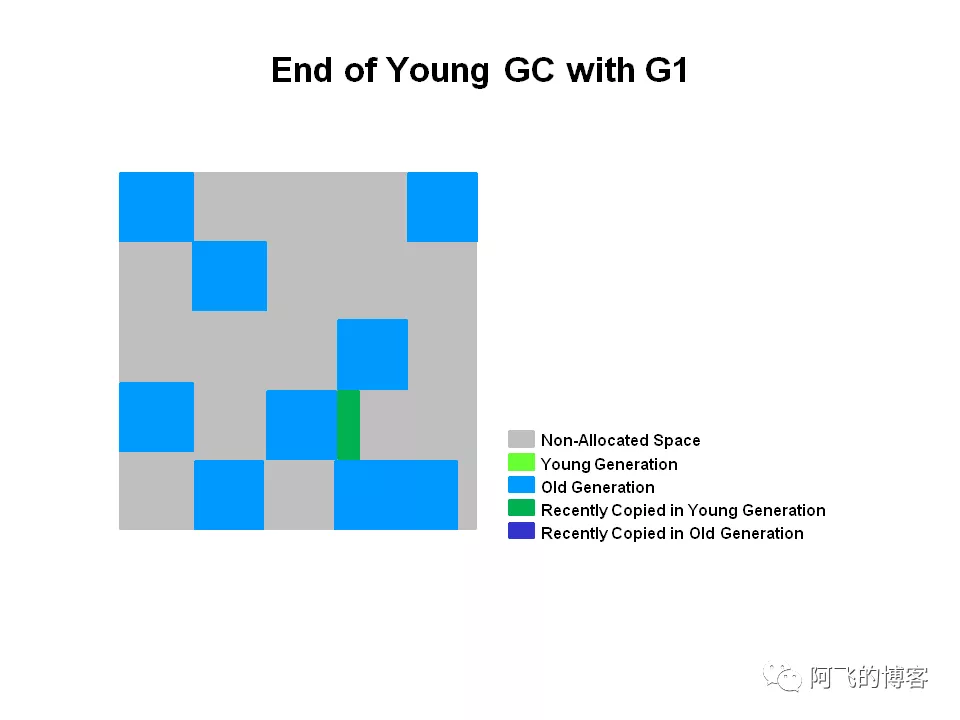
最后对G1的YGC做一个简单的总结:
-
堆是一个被划分为多个Region的单独的内存空间;
-
年轻代的内存由多个不连续的Region组成,这样的设计在需要对年轻代大小扩容的时候,变得更容易;
-
G1的YGC是完全STW的,所有的应用线程都需要停止工作;
-
YGC是多线程并行的;
-
存活的对象会被拷贝到新的Survivor或者Old类型的Region中;
并发标记周期
全局并发标记周期,即concurrent marking cycle,G1的全局并发标记周期和CMS的并发收集过程非常相似。不过,G1模式下满足触发全局并发标记的条件由参数(-XX:InitiatingHeapOccupancyPercent=45)控制,这个比例是整个Java堆占用百分比阈值,即Java堆占用这么多空间后,就会进入初始化标记->并发标记->最终标记->清理的生命周期。而CMS是由参数(-XX:CMSInitiatingOccupancyFraction)控制,这个比例是老年代占用比阈值。
G1并发标记周期阶段的GC日志样例参考如下:
[GC pause (G1 Evacuation Pause) (young) (initial-mark) 857M->617M(1024M), 0.0112237 secs]
[GC concurrent-root-region-scan-start]
[GC concurrent-root-region-scan-end, 0.0000525 secs]
[GC concurrent-mark-start]
[GC concurrent-mark-end, 0.0083864 secs]
[GC remark, 0.0038066 secs]
[GC cleanup 680M->680M(1024M), 0.0006165 secs]
由日志可知,G1的并发标记周期主要包括如下几个过程:
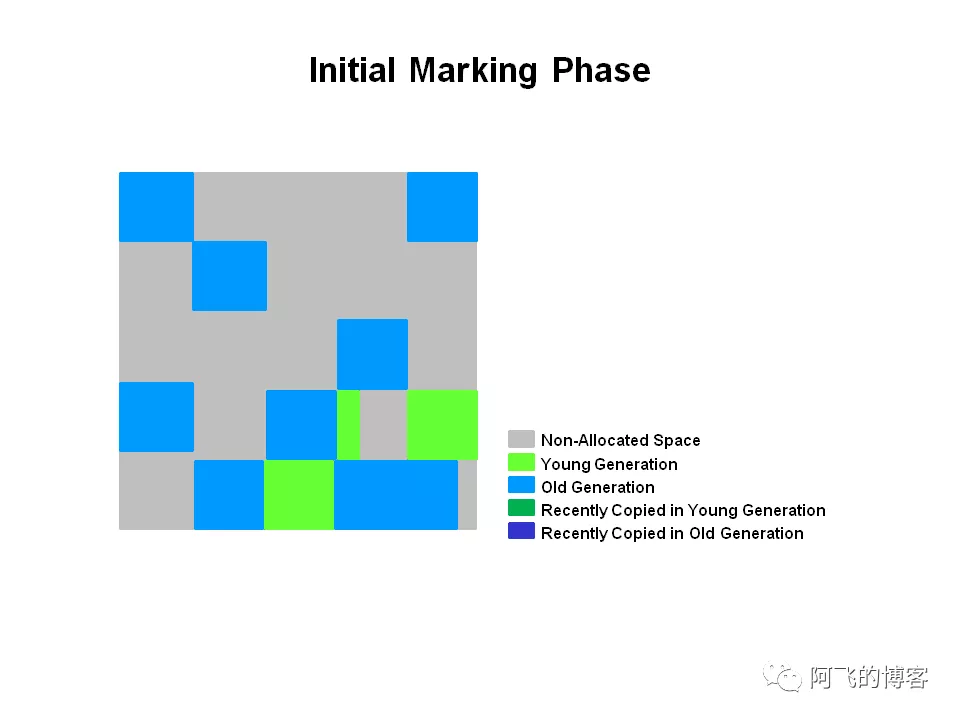
- 初始化标记
STW阶段,在G1中,初始化标记是伴随一次普通的YGC发生的,这么做的好处是没有额外的、单独的暂停阶段,这个阶段主要是找出所有的根Region集合。在GC日志中有[GC pause (G1 Evacuation Pause) (young) (initial-mark)字样:
- 根分区扫描
并发阶段,扫描那些根分区(Region)集合----Oracle官方介绍的根分区集合是那些对老年代有引用的Survivor分区,标记所有从根集合可直接到达的对象并将它们的字段压入扫描栈(marking stack)中等到后续扫描。G1使用外部的bitmap来记录mark信息,而不使用对象头的mark word里的mark bit(JDK12的Shenandoah GC是使用对象头)。另外需要注意的是,这个阶段必须在下一次YGC发生之前完成,如果扫描过程中,Eden区耗尽,那么一定要等待根分区扫描完成还能进行YGC。
- 并发标记
并发阶段,继续扫描,不断从上一个阶段的扫描栈中取出引用递归扫描整个堆里所有存活的对象图。每扫描到一个对象就会对其标记,并将其字段压入扫描栈。重复扫描过程,直到扫描栈清空。另外,需要注意的是,这个阶段可以被YGC中断。如下的GC日志样例所示:
[GC pause (G1 Evacuation Pause) (young) (initial-mark) 963M->962M(1024M), 0.0070962 secs]
[GC concurrent-root-region-scan-start]
[GC concurrent-root-region-scan-end, 0.0000394 secs]
[GC concurrent-mark-start]
[GC pause (G1 Evacuation Pause) (young)-- 1004M->1006M(1024M), 0.0020180 secs]
[GC pause (G1 Evacuation Pause) (young)-- 1024M->1024M(1024M), 0.0005811 secs]
- 最终标记
STW阶段,彻底完成堆中存活对象的标记工作,使用的是SATB算法,它比CMS使用的算法更快。因为,G1这个remark与CMS的remark有一个本质上的区别,那就是这个暂停只需要扫描SATB buffer,而CMS的remark需要重新扫描mod-union table里的dirty card外加整个根集合(这时候年轻代也是根集合的一部分),而此时整个年轻代(不管对象死活)都会被当作根集合的一部分,因而CMS remark有可能会非常慢(所以,很多CMS优化建议配置参数:-XX:+CMSScavengeBeforeRemark,即在最终标记之前执行一次YGC,减轻最终标记的压力)。
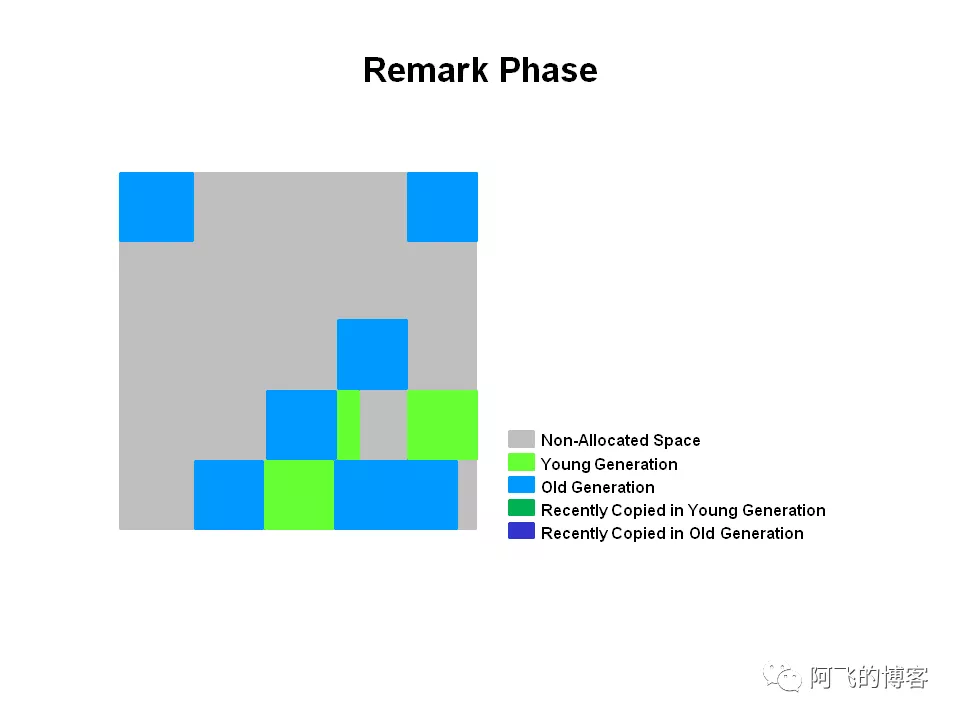
SATB,即snapshot-at-the-beginning,抽象的说就是在一次GC开始的时候,是活的对象就被认为一直是活的,直到这个GC完成,此时堆中所有的对象形成一个逻辑“快照”(snapshot),另外在GC过程中新分配的对象都当作是活的,其它不可到达的对象就是死的了。
- 清理阶段
STW阶段。这个过程主要是从bitmap里统计每个Region被标记为存活的对象,计算存活对象的统计信息,然后将它们按照存活状况(liveness)进行排列。并且会找出完全空闲的Region,然后回收掉这些完全空闲的Region,并将空间返回到可分配Region集合中。需要说明的是,这个阶段不会有拷贝动作,因为不需要,清理阶段只回收完全空闲的Region而已。至于那些有存活对象的Region,需要接下来的YGC或者Mixed GC才能回收。
上面提到的这几个过程就是全局并发标记周期的全过程:初始化标记(initial mark)、根分区扫描(Root region scanning)、并发标记(concurrent marking)、最终标记(remark)、清理阶段(cleanup)。全局并发标记的目的就是为了让G1的Mixed GC可以找出适合的老年代Region来收集,必须在老年代变得无法扩张(也就基本无法收集)之前完成标记。
- Evacuation
STW阶段,这个阶段会把存活的对象拷贝到全新的还未使用的Region中,G1的这个阶段的CSet可以有任意多个Region,CSet的选择,完全根据停顿预测模型找出收益尽可能高、开销尽可能小的这类Region。G1的这个过程有两种选定CSet的模式:既可能由YGC来完成,只回收所有的年轻代(GC日志样例:[GC pause (young)])。也可能是Mixed GC来完成的,即回收所有的年轻代以及部分老年代(GC日志样例:[GC Pause (mixed)]):
第一段GC日志--并发标记周期后先YGC然后Mixed GC:
[GC remark, 0.0021950 secs]
[GC cleanup 809M->351M(1024M), 0.0009678 secs]
[GC concurrent-cleanup-start]
[GC concurrent-cleanup-end, 0.0001810 secs]
[GC pause (G1 Evacuation Pause) (young) 380M->380M(1024M), 0.0119252 secs]
[GC pause (G1 Evacuation Pause) (mixed) 416M->406M(1024M), 0.0072944 secs]
第二段GC日志--并发标记周期后只有YGC:
[GC cleanup 763M->279M(1024M), 0.0013693 secs]
[GC concurrent-cleanup-start]
[GC concurrent-cleanup-end, 0.0001920 secs]
[GC pause (G1 Evacuation Pause) (young) 347M->346M(1024M), 0.0178034 secs]
[GC pause (G1 Evacuation Pause) (young) 462M->462M(1024M), 0.0346993 secs]
[GC pause (G1 Evacuation Pause) (young) 602M->602M(1024M), 0.0301031 secs]
[GC pause (G1 Evacuation Pause) (young) (initial-mark) 760M->760M(1024M), 0.1005118 secs]
[GC concurrent-root-region-scan-start]
网上很多文章介绍:初始化标记->根区域扫描->并发标记->最终标记->清理这几个阶段就是Mixed GC的一部分,这种说法是错误的。这几个阶段只是G1的并发标记周期,它是为Mixed GC选取多少个老年代Region服务的,至于接下来是发生YGC还是Mixed GC,都是有可能的,上面的GC日志样例就能验证这个说法。
Mixed GC
如下图所示,就是Mixed GC示意图,回收所有年轻代Region和部分老年代Region:
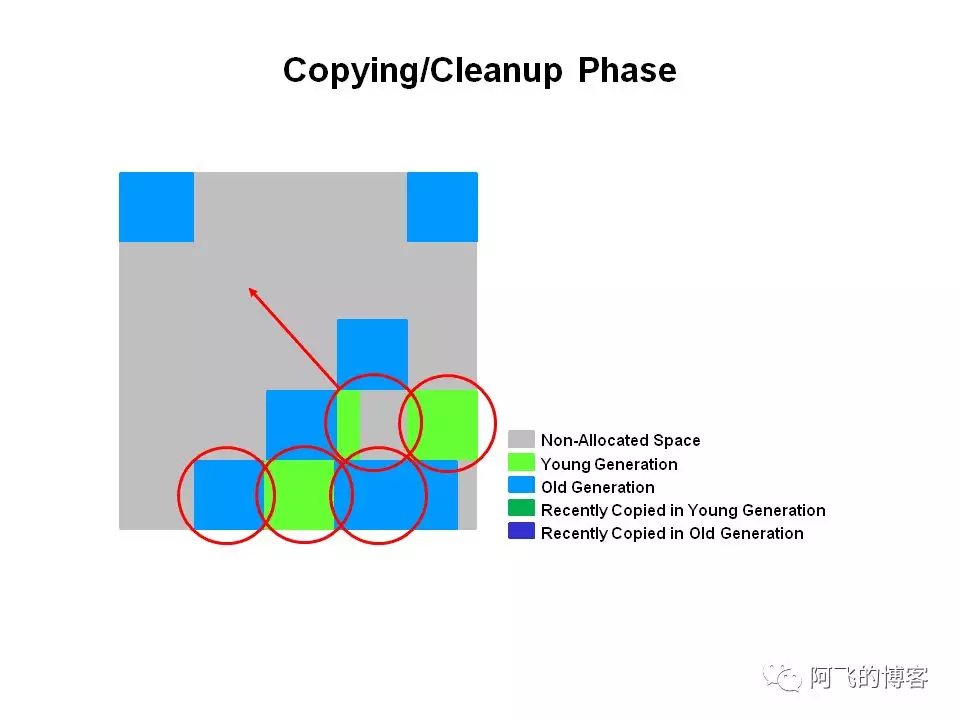
被选中的Region(所有年轻代Region和部分老年代Region)已经被回收,存活的对象被压缩到深蓝色Region(最近被拷贝的老年代Region)和深绿色Region(最近被拷贝的年轻代Region)中:

Mixed GC日志如下所示:
[GC pause (G1 Evacuation Pause) (mixed) 715M->682M(1024M), 0.0114279 secs]
Mixed GC是完全STW的,它是G1一种非常重要的回收方式,它根据用户设置的停顿时间目标,可以选择回收所有年轻代,以及部分老年代Region集合(Collection Set,收集集合,简称CSet,)。在一次完整的全局并发标记周期后,如果满足触发Mixed GC的条件,那么就会执行Mixed GC,并且Mixed GC可能会执行多次(由下面的GC日志可知,并且最大次数由参数-XX:G1MixedGCCountTarget=8控制),直到CSet都被回收,并且尽可能达到用户期望的停顿时间目标。
# 全局并发标记周期 start
[GC pause (G1 Evacuation Pause) (young) (initial-mark) 857M->617M(1024M), 0.0112237 secs]
[GC concurrent-root-region-scan-start]
[GC concurrent-root-region-scan-end, 0.0000525 secs]
[GC concurrent-mark-start]
[GC concurrent-mark-end, 0.0083864 secs]
[GC remark, 0.0038066 secs]
[GC cleanup 680M->680M(1024M), 0.0006165 secs]
# 全局并发标记周期 end
# mixed gc start,连续几次mixed gc
[GC pause (G1 Evacuation Pause) (mixed) 677M->667M(1024M), 0.0136266 secs]
[GC pause (G1 Evacuation Pause) (mixed) 711M->675M(1024M), 0.0101436 secs]
[GC pause (G1 Evacuation Pause) (mixed) 715M->682M(1024M), 0.0114279 secs]
... ...
在选定CSet后,G1在执行Evacuation阶段时,其实就跟ParallelScavenge的YGC的算法类似,采用并行复制(或者叫scavenging)算法把CSet里每个Region中的存活对象拷贝到新的Region里,然后回收掉这些Region,整个过程完全STW。
G1总结
G1模式下Evacuation阶段有两种选定CSet的子模式,分别对应Young GC与Mixed GC:
-
Young GC:选定所有年轻代里的Region。G1是通过调整年轻代大小,控制年轻代Region数量来控制YGC的开销。
-
Mixed GC:选定所有年轻代里的Region,外加根据global concurrent marking统计得出收集收益高的部分老年代Region,在用户指定的停顿时间目标范围内尽可能选择收益高的老年代Region回收,G1就是通过控制回收老年代Region数量来控制Mixed GC的开销的。
我们可以看到无论发生的是YGC还是Mixed GC,年轻代Region总是在CSet内,因此G1不需要维护从年轻代Region出发的引用涉及的RSet更新。 G1的正常工作流程就是在YGC与Mixed GC之间视情况切换,大部分是YGC,Mixed GC次数少很多,背后定期做全局并发标记(满足参数-XX:InitiatingHeapOccupancyPercent条件时,G1的并发动作只出现在全局并发标记周期,YGC和Mixed GC都是完全STW的)。当并发标记周期正在工作时,G1不会选择做Mixed GC,反之,如果有Mixed GC正在进行,G1也不会启动并发标记周期(从initial marking开始)。
- G1模式下的FullGC
在G1的正常工作流程中没有Full GC的概念,老年代的收集全靠Mixed GC来完成。
但是,毕竟Mixed GC有搞不定的时候,如果Mixed GC实在无法跟上程序分配内存的速度,导致老年代填满无法继续进行Mixed GC,就会切换到G1之外的Serial Old GC来收集整个堆(包括Young、Old、Metaspace),这才是真正的Full GC(Full GC不在G1的控制范围内),进入这种状态的G1就跟-XX:+UseSerialGC的Full GC一样(背后的核心代码是两者共用的)。
这就是为什么不建议G1模式下参数-XX:MaxGCPauseMillis=200 的值设置太小,如果设置太小,可能导致每次Mixed GC只能回收很小一部分Region,最终可能无法跟上程序分配内存的速度,从而触发Full GC。
顺带一提,G1模式下的System.gc()默认还是Full GC,也就是Serial Old GC。只有加上参数 -XX:+ExplicitGCInvokesConcurrent 时G1才会用自身的并发GC来执行System.gc();
说明:JDK10已经将G1的Full GC优化为Parallel模式。可以参考JEP 307: Parallel Full GC for G1:https://openjdk.java.net/jeps/307
比较其他GC
接下来总结一下G1和另外两个使用最多的GC的不同点:
- Parallel GC
为吞吐量而生的垃圾回收器,Parallel GC 只能把老年代的空间当作一个整体来压缩和回收,且整个过程完全STW。而G1把这些工作分为几个耗时更短的收集过程,且部分阶段是并发的,而且可以只回收老年代的部分Region,这样能缩短停顿时间,但是可能会牺牲吞吐量。
- CMS
G1出来之前,低延迟场景下最好的也是最难控制垃圾回收器。G1和CMS类似,G1并发执行部分老年代的回收工作,但是CMS不能解决Old区的碎片化问题,导致一定会出现长时间停顿的FullGC。G1也有碎片化问题,但是比起CMS好很多,另外G1也会有FullGC,但是频率远没有CMS那么高。
一些建议
接下来要介绍的是使用G1的最佳实践,如果没有充分的压测数据,不建议违背这些建议:
-
年轻代大小:也就是说,如果配置了-XX:+UseG1GC,那么尽量避免配置-Xmn(或 -XX:NewRatio 等其他相关选项显式设置年轻代大小)。如果设置该参数,G1将不能在需要的时候调整年轻代的大小,也不能根据设置的暂停时间调整收集策略。换句话说,如果配置了-Xmn,也就关闭了参数-XX:MaxGCPauseMillis=200设定的停顿目标,具体YGC的停顿时间,那就完全由-Xmn直接决定了。
-
停顿时间:不要使用平均响应时间作为设置参数-XX:MaxGCPauseMillis=200的衡量标准,而应该根据90%(或者更高比例)响应时间来设置这个参数。需要强调的是,这个参数设定的只是一个目标,而不是一定达到的保证。不建议将这个参数设置的过低,例如100ms以内,除非针对你的应用,有充分的压测数据佐证你的设置。
-
CMS or G1,什么时候选择CMS,什么时候选择G1?这是一个伪命题。其实CMS在较小的堆、合适的workload的条件下暂停时间可以很轻松的短于G1。以JDK8高版本为例(JDK7到JDK8,G1的实现经过了很多的优化),大概在6GB~8GB也可以跟CMS有一比,我之前见过有在-Xmx4g的环境里G1比CMS的暂停时间更短的个案。总之,G1更适合大堆,比如20G,30G,50G,不要犹豫选择G1吧。而对于4G,8G这种中小堆,如果谨慎的话,建议压测后再决定。否则CMS也是一个保(不)守(错)的选择。
需要说明的是,这里只是建议,而不是绝对。毕竟每个应用的特性,以及运行的环境千差万别。Java官方是不建议显示设置年轻代大小的,但是笔者一些朋友遇到这样的问题:默认目标停顿时间200ms,且堆非常大的情况下,Eden区非常小,Young区也非常小。下面就是一段这样的GC日志,我们可以看到整个堆是(约等于)7G,但是Eden区只有300多M。为什么G1把这个Eden区大小调的这么小呢?我们再看一下停顿时间,这一次YGC耗时190ms,非常接近目标停顿时间。如果G1再调大Eden区大小,那么YGC时停顿时间就非常可能超过200ms:
[Eden: 350.0M(350.0M)->0.0B(306.0M) Survivors: 0.0B->44.0M Heap: 410.1M(7000.0M)->135.2M(7000.0M)]
[Times: user=0.60 sys=0.15, real=0.19 secs]



