
慌了!LinkedHashMap和hashTable的Entry居然有500w之多,还无法回收原创
故障介绍
某一日早上七点,我还在睡梦之中,8点醒来发现运维群内有人at。一看说是用户服务的一个节点挂掉了。然后大概原因是因为OOM,运维还在群里发了一个jstack 的栈dump文件,未必是事故发生时的dump文件。oom.hprof文件太大,只能去公司看了。
初步排查
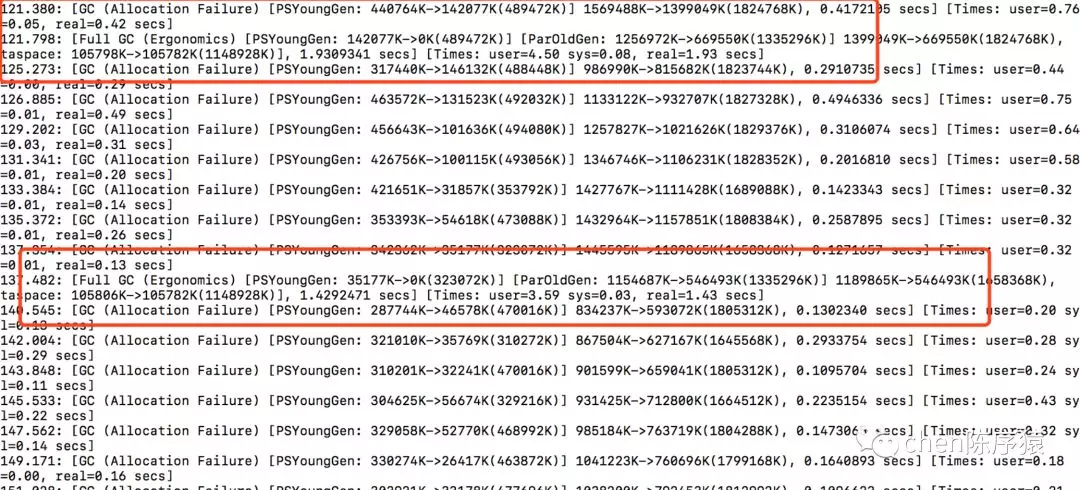
去公司以后就下载了gc.log。发现在应用宕机的时候,有过两次full gc。结合运维的描述,确实当时程序停顿了两次,每次停顿都将尽3~4秒,通过业务日志发现,那时候的dubbo调用是超时的。
另外一个发现就是,我通过gc.log发现,在gc时,内存是被成功回收的。但是回收率不高。
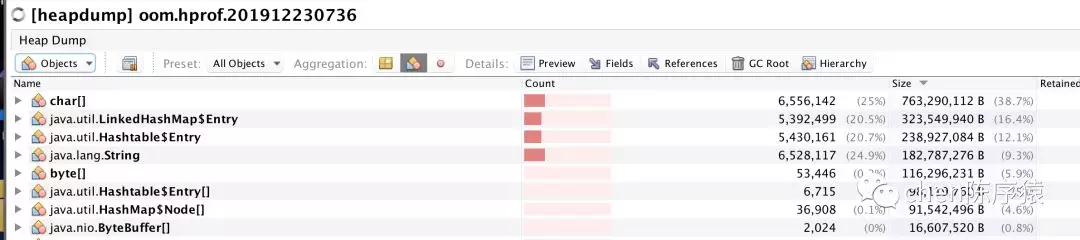
下载oom.hprof。打开看看吧。一打开就吓死了:LinkedHashMap的Entry和hashTable的Entry居然有500w之多,无法回收。而且里面基本上都是String类型的key/value。
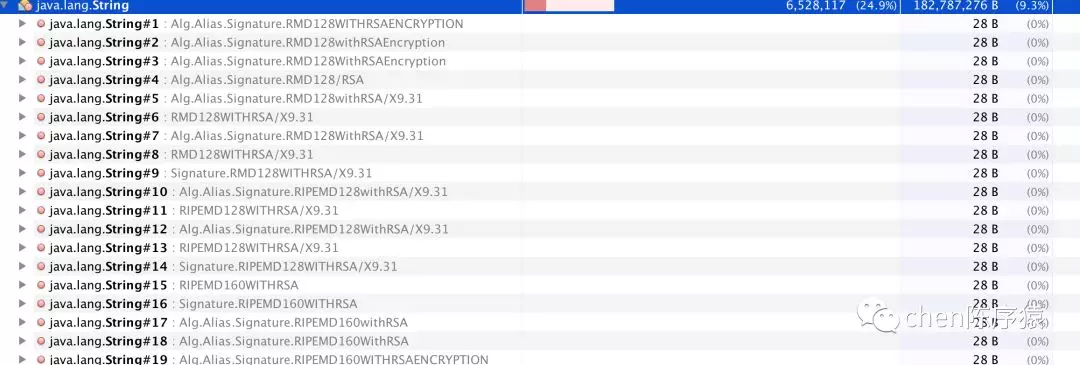
让我们揭开600w的string的key/value。发现:和RSA加解密相关,都是一些算法类路径和算法类型。
直觉告诉我,应该是程序里RSA的加解密工具类误用造成的内存泄漏吧?于是定位到RSAUtil里一段加密的代码:
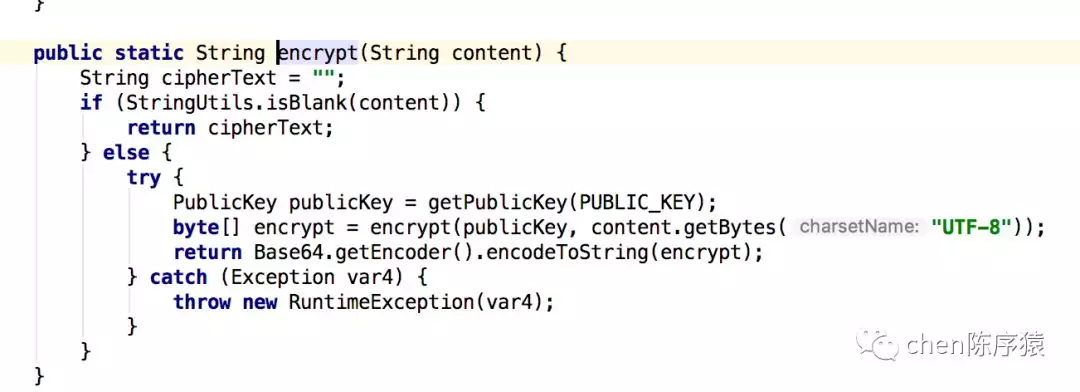
发现每次加解密都会调用一次Secturity.addProvider函数,在这个函数里,每次都new一个BouncyCastlePrivider();
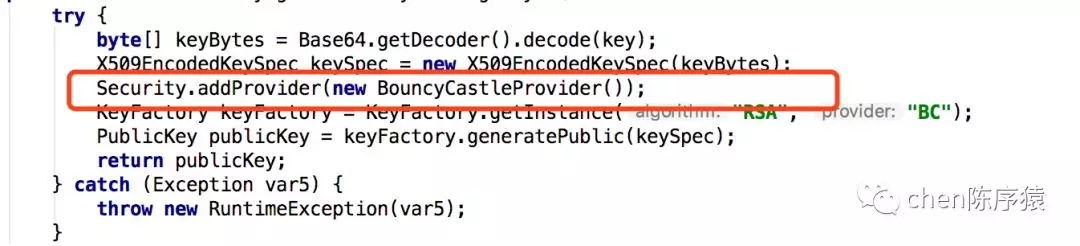
发现BouncyCastleProvider()里一顿put:
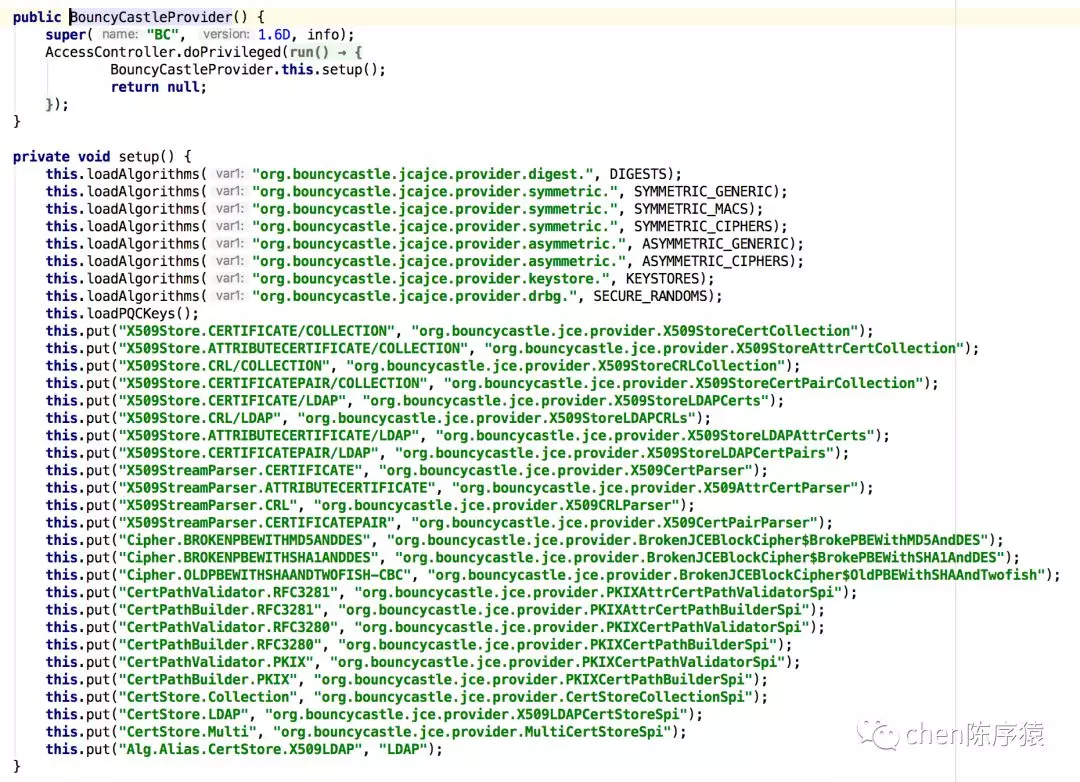
我debug了一下Sectury.AddProvider();发现BouncyCastlePrivider这个对象继承自HashTable。每new一个BouncyCastlePrivider,能直接看到相当于new了size为2615的map。惊呆了。
于是认为这就是一个简单的内存泄漏问题。打算写一段代码复现:不断的加解密,看一下内存变化情况。

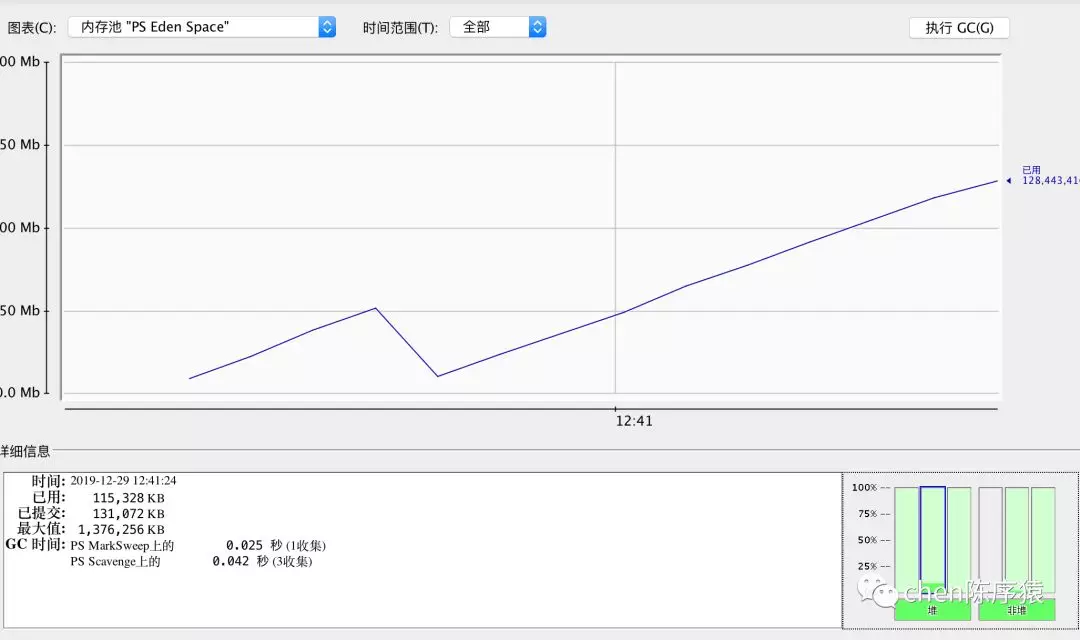
发现eden区的内存会缓慢飙升,但是执行gc的时候,是可以被回收的啊。。
说好的内存泄漏呢?看起来,虽然我们这里每次都new BouncyCastlePrivider() 肯定是误用了。但是并不会直接造成内存oom啊。因为new 出来的BouncyCastlePrivider() 在失去他的作用域以后,在堆区满了以后,发现确实是能够回收的,没道理造成内存OOM。
定位问题
中午吃饭的时候和运维进行了交流,获取了一些更加有用的情报:
-
只有1台机器发生了oom。
-
发生oom的时候这服务的活跃线程数增多。
活跃线程数增多是因为并发造成的?不是,因为请求是平均路由的。其他实例的活跃线程数并不多,单独这台机器活跃线程数多。而线程处于wailt状态,time_wailt状态,是非活跃线程,而线程处于runnable状态和blocked状态,是属于活跃线程。
于是打开了oom文件,去分析线程情况。发现我们用的dubbo框架的2000个业务线程都被blocked了。这就能解释为什么当时活跃线程数增多了,因为du bbo的业务线程被blocked了,新来的请求使用空闲线程执行业务逻辑,然后也被bolcked了。最后2000个线程大部分都是bolcked状态。从监控面板上看,属于活跃线程数突然增多了。
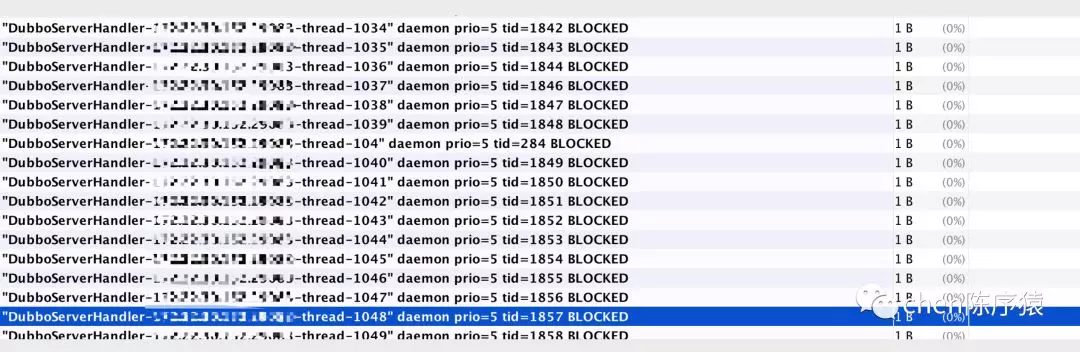
结合上午排查的内存情况来看。我初步估计,是因为2000个业务线程大部分都是bolcked状态,且应该bolcked源在加解密工具类里面,这时候,2000个线程都持有着BouncyCastlePrivider这个对象的栈上的引用,gc是无法清理存活着的对象的占用内存的,于是只好OOM。
上边分析HashTable的entry引用个数为5430169。而每new一个BouncyCastlePrivider对象,上面debug,map.zise 为2651。即是2615个Entry对象。5430169 / 2651 = 2048个线程,5430169个hashentry对象不一定全都是BouncyCastlePrivider对象持有的,应该减去1~2w的entry,是其他对象正常持有的。通过初步估算发现,OOM和map.size 和dubbo的线程池总线程数,是基本能对得上的。
那就review一下BouncyCastlePrivider的构造函数代码吧?到底干了些啥?
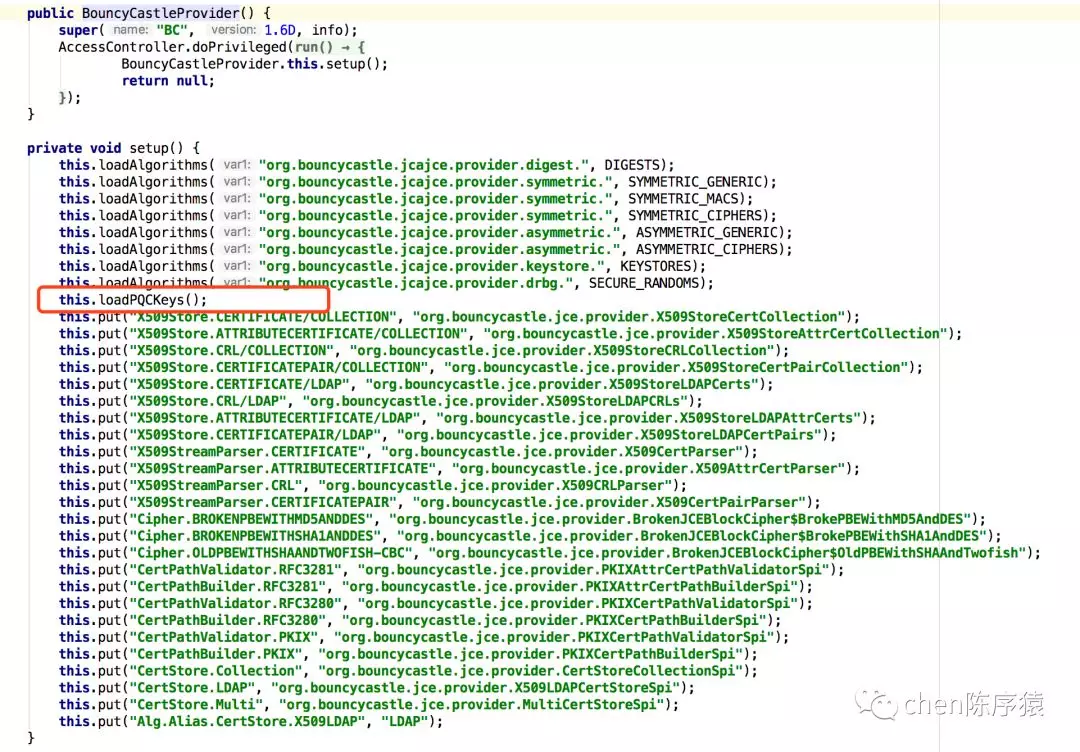
review以后发现在loadPQkeys函数里,调用了7次addKeyInfoConverter函数。而这个函数,加的锁是一个静态锁!
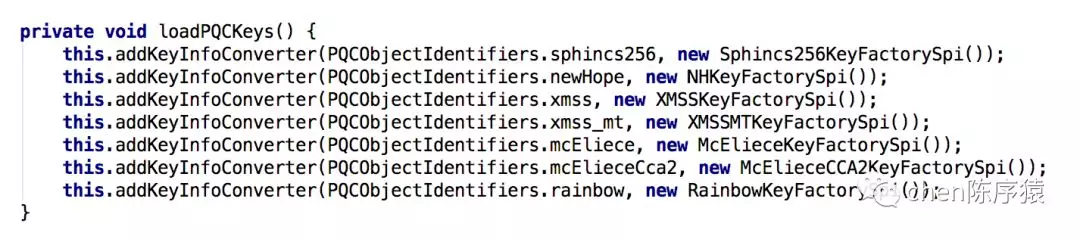

也就是说,多个线程执行BouncyCastlePrivider的构造函数,会竞争7次静态锁,造成线程被blocked 。那写段代码复现一下。这段代码表示500个线程同时发起加密,加密以后500个线程同时发起下一轮加密。
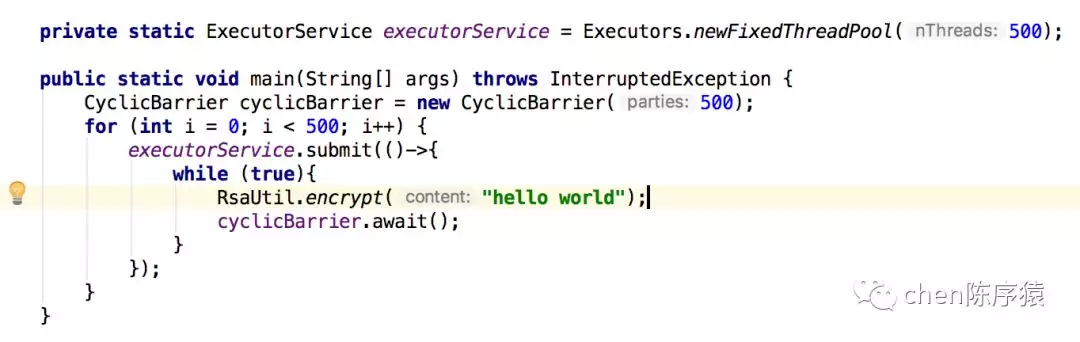
打印实时堆栈:
分析jstack日志。发现确实很多线程在BouncyCastlePrivider内部被blocked。bolcked入口是loadAlgorithms函数。
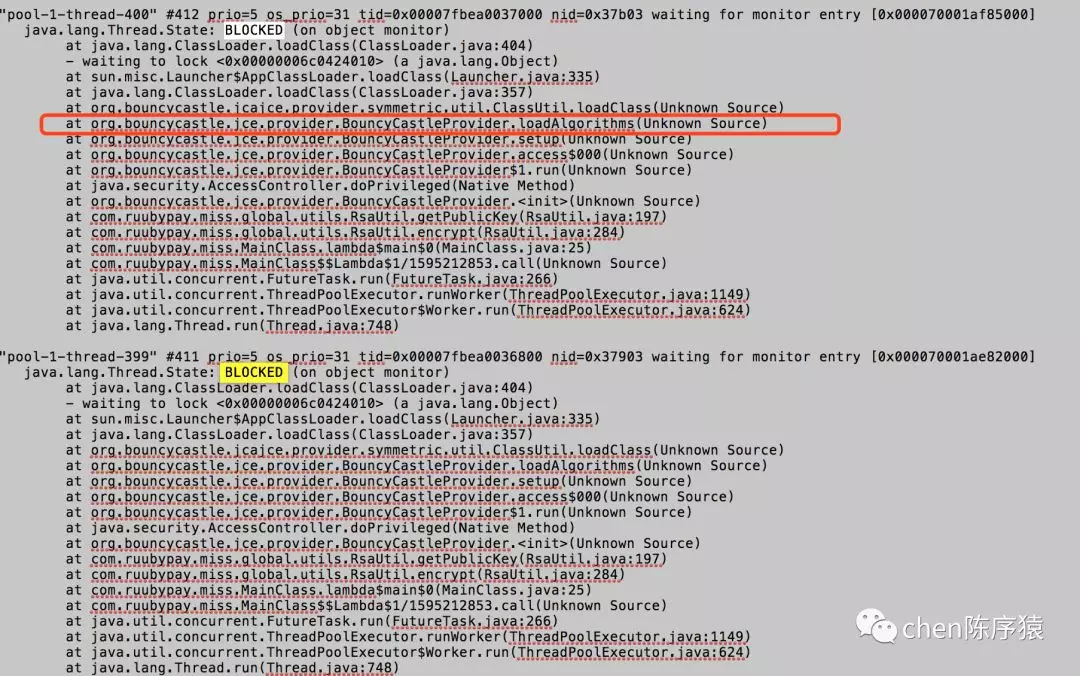
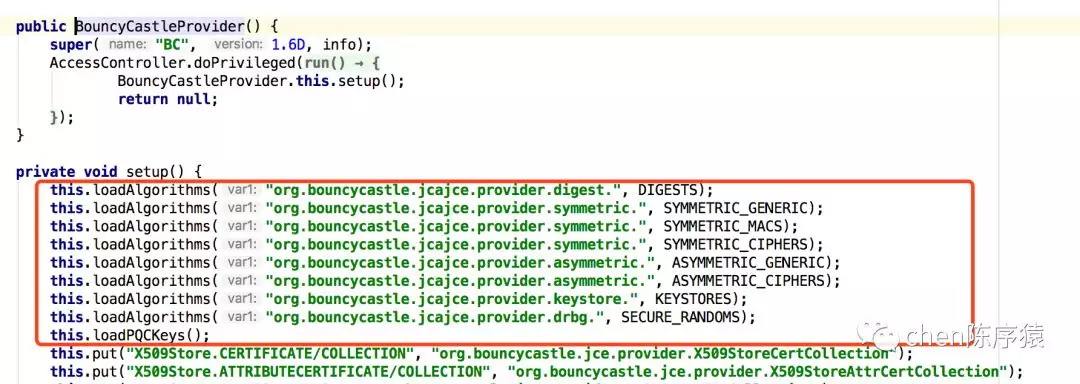
追到底层,原来是因为BouncyCastlePrivider每次构造函数调用都会重复加载8个类。而类加载器里面加载一个类,会根据类名称进行加锁。相同的类在加载时互相等待锁,而从jar包加载一个类本身就是比较耗时的。因此造成线程被blocked。
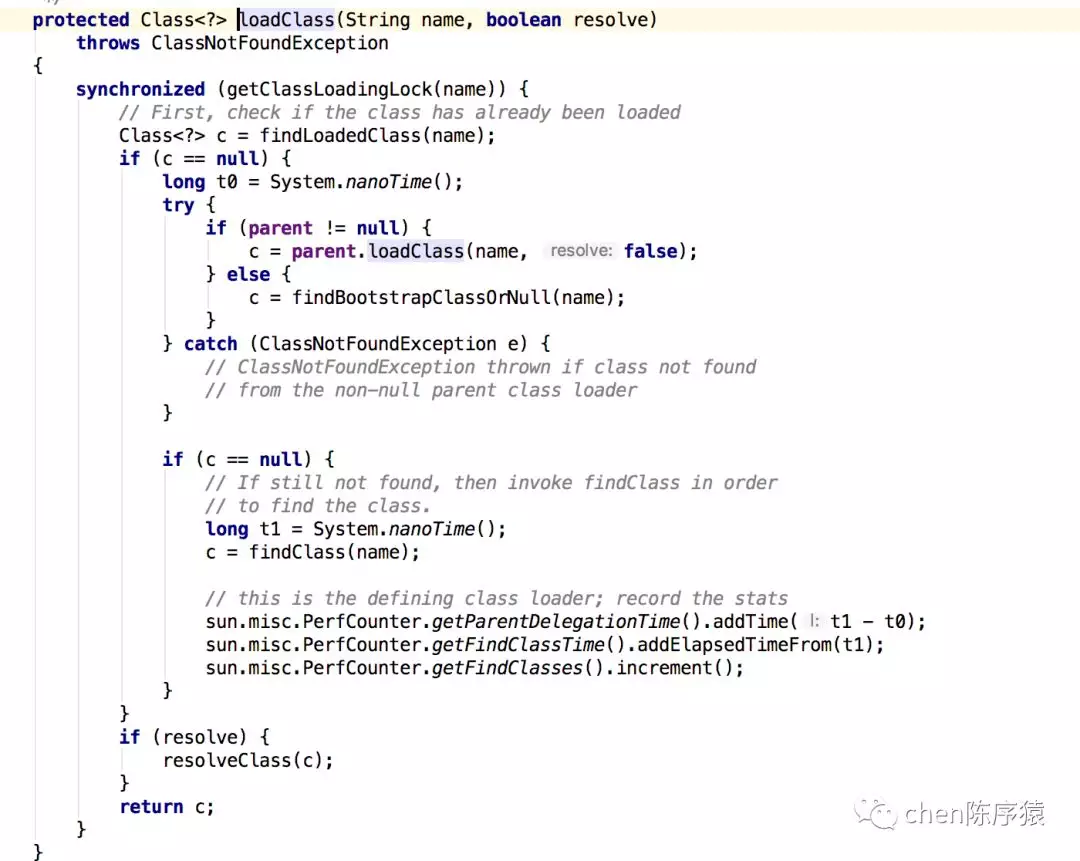
其他疑问:
- 为什么这个加解密算法的使用早就有问题了,为什么现在才爆出来?
实际上是因为业务逻辑已知的修改,造成了加解密函数的被调用次数增多了。之前没出现问题是因为调用次数少,而且这个问题并不是死锁问题,仅仅是竞争多了会造成bolcked而已。
- 为什么这个服务多个实例,只有一台机器有问题呢?
暂时原因不明,可能是那台机器性能本身就开始有问题,从而诱发了线程执行耗时慢,而搭配我发现的这个代码问题,雪上加霜,从而造成了OOM。
结论
本次故障的原因,表面看上去是内存泄漏。实际上是因为大量线程bolcked导致的引用的内存不能即使释放 + 误用BouncyCastlePrivider对象,生成大量重复对象造成了无用内存占用 同时发生造成的OOM。
经验教训1:在使用别人家的类库的时候,我们一定要搞清楚这个对象是有状态的,还是无状态的,是很重,应该实例化一次,还是每次都要实例化。
经验教训2:不能网上粘的代码就随便乱用。实际上很多网站别人公开的代码都是有很多坑的。应该养成能分析网上的代码合理不合理的能力。这次加解密函数的故障,就是因为之前这些代码都是网上直接拷贝的。
本文来自公众号:chen陈序猿



