
服务响应时间飙升问题排查记原创
这个case大概发生在一年前,现在拿出来给大家做个分享。
现象
下游有server服务上线一台机器,导致上游服务调用下游服务时间升高,young gc 增多,cpu利用率增高,但是从下游server服务看各项指标都很正常。
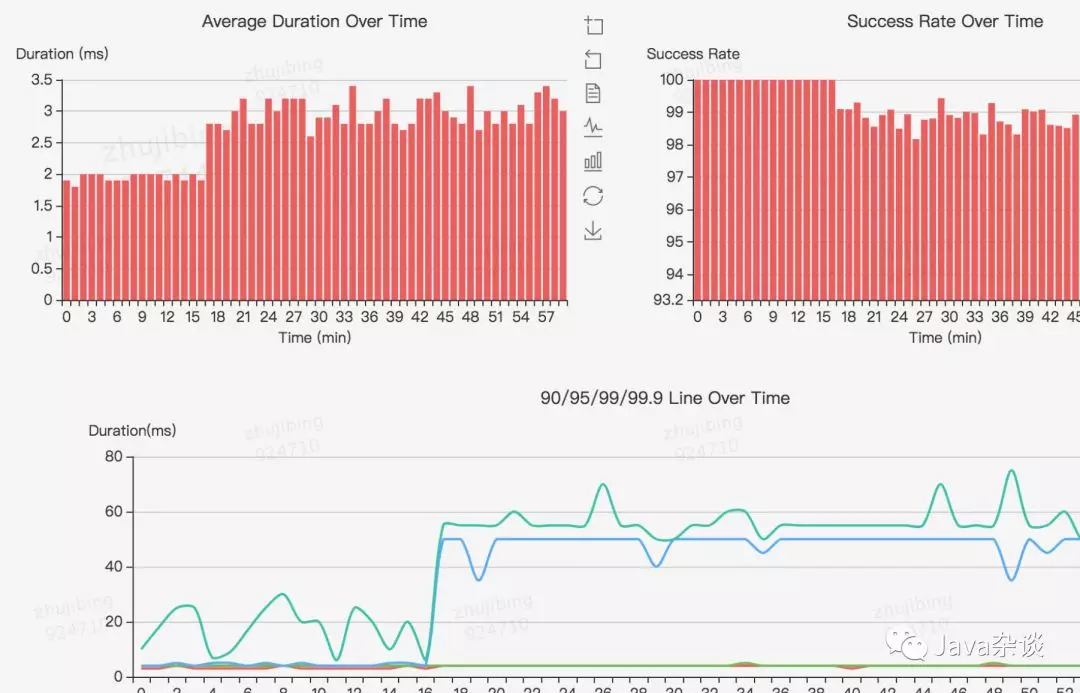
从client看调用下游服务监控
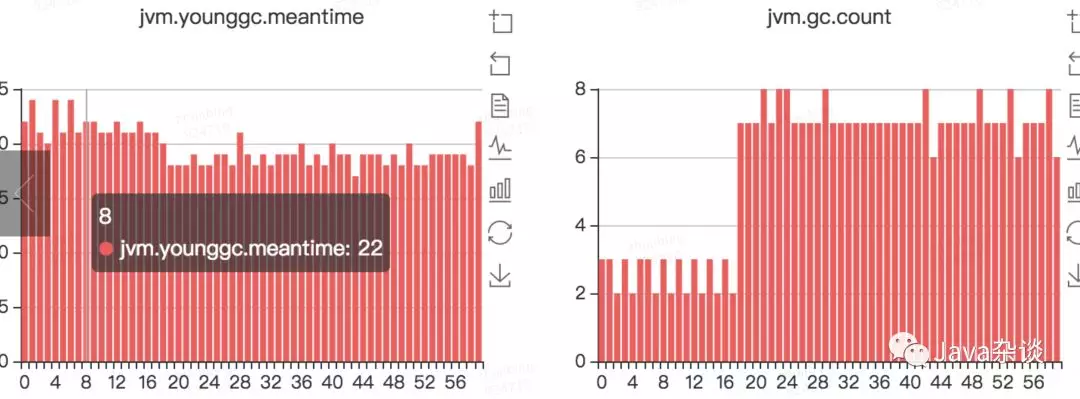
young gc监控
问题排查过程
因为是cpu飙升很多,于是就在监控系统cat上看了一下出问题时候的堆栈信息,关键信息如下:

看堆栈信息应该是加载类的时候未加载到,询问下游服务负责人是否在RPC接口中增加新的返回字段,被告知并没有。
再次查看服务本身,发现服务使用到了pigeon和thrift两种RPC框架,使用pigeon框架的服务接口都飙升了,而使用thrift框架的服务接口却是正常了。这样说明服务延迟上升不是由于cpu升高、young gc次数增多导致的。应该是其他原因导致的。cpu升高、young gc次数和服务响应时间升高都是结果。
作为RPC框架,他们基本上有类似的信息流向:
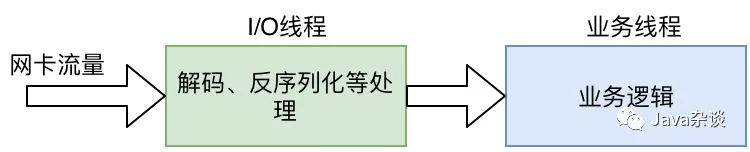
在业务逻辑监控下,发现业务逻辑的响应时间都是正常的,和业务逻辑没有关系。那么pigeon的接口飙升的原因基本上只能在I/O线程里。
查看pigeon这块源码发现,发现调用下游的服务都是共用了一个I/O线程,并且在I/O线程处理逻辑如下:
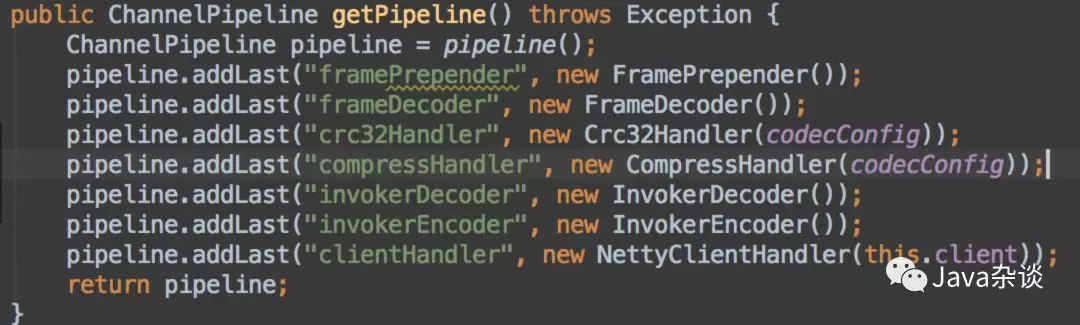
于是还是应该把着重点放在反序列化上,在反序列化方法上加上监控,准备上线时,却发现线上tomcat日志有以下错误:
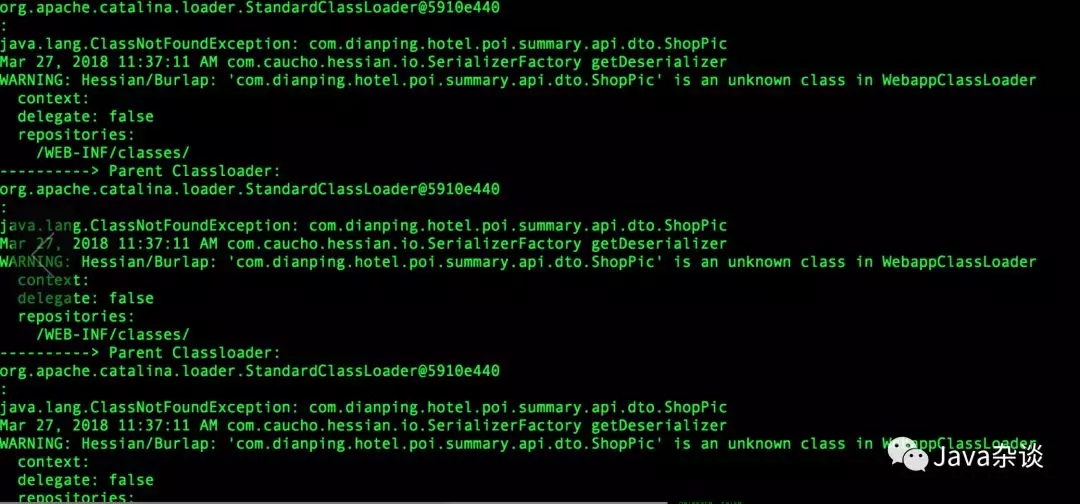
很明显在序列化查找类的时候,找不到该类。再次联系下游服务是不是添加了ShopPic这个对象,他们再次查看代码确实在返回对象中添加了List<ShopPic> 对象类型。
让他们提供新的jar版本,服务升级后问题解决。
原理分析
因为pigeon服务在从下游拿到数据之后,需要进行反序列化,使用的反序列化方式是hession。hession在反序列化时,需要加载class,若class加载到了会缓存下来,加载不到会每次都会尝试再次加载。而添加的对象刚好又是list,里面的每个对象都会走“加载类,未找到,输出log”模式。而这一过程本身是比较耗cpu和时间的,并且生成不少临时变量。消耗时间会导致pigeon的I/O线程阻塞,进而导致其他pigeon服务延迟也升高。
总结
通常我们在做问题排查的时候,一般要先把所有的异常现象都给列举出来。然后查看这些现象本身是否有因果关系。确定某些现象有因果关系,那么就要把查看重点放在因。列举出独立的异常现象之后,可以先从比较容易着手的异常现象排查,有时候一个异常现象被找到解决,可能其他所有异常现象都会解决。
比如本例有3个异常表现:cpu升高、young gc次数增多、服务超时增多。cpu升高可能会导致服务超时增多,但是进程内所有的服务都应该受影响,不只是pigeon服务,所以排除这两者之间的因果关系。young gc次数增多会导致cpu略微升高,但是本例中不能就因此确定cpu升高就是young gc导致的。在本例中的3个异常表现中,cpu升高最好排查、服务超时增多次之、young gc次数增多最难排查。所以问题排查就应该按照先排查cpu问题、再排查服务超时问题、最后再是young gc次数增多。



