
Java OOM 高级篇:线上Docker 上Springboot程序OOM问题的排查分享原创
Java OOM优化专题大纲目录
第四篇:Java OOM 基础篇:常见的OutOfMemoryError 场景三: PermGen space 永久空间问题详解
第五篇:Java OOM 基础篇:常见的OutOfMemoryError 场景四: Permgen size 元空间问题详解
第六篇:Java OOM 实战篇:应用故障之Java heap space 堆溢出实战
第七篇:Java OOM 高级篇:体验了一把线上CPU100%及应用OOM的排查和解决过程
第八篇:Java OOM 高级篇:线上Docker 上Springboot程序OOM问题的排查分享
导语
运维人员反馈一个容器化的java程序每跑一段时间就会出现OOM问题,重启后,间隔大概两天后复现。本篇就线上Docker上Springboot程序OOM问题来做一次详细的性能排查和性能优化,文章写的非常详细是一次非常优化的性能优化文章,希望能帮助到大家。
正文
问题调查
一、查日志
由于是容器化部署的程序,登上主机后使用docker logs ContainerId查看输出日志,并没有发现任何异常输出。使用docker stats查看容器使用的资源情况,分配了2G大小,目前使用率较低,也没有发现异常。

二、缺失的工具
打算进入容器内部一探究竟,先使用docker ps 找到java程序的ContainerId
,再执行docker exec -it ContainerId /bin/bash进入容器。进入后,本想着使用jmap、jstack 等JVM分析命令来诊断,结果发现命令都不存在,显示如下:
- bash: jstack: command not found
- bash: jmap: command not found
- bash: jps: command not found
- bash: jstat: command not found
突然意识到,可能打镜像的时候使用的是精简版的JDK,并没有这些jVM分析工具,但是这仍然不能阻止我们分析问题的脚步,此时docker cp命令就派上用场了,它的作用是:在容器和宿主机之间拷贝文件。这里使用的思路是:拷贝一个新的jdk到容器内部,目的是为了执行JVM分析命令,参照用法如下:
- Usage: docker cp [OPTIONS] CONTAINER:SRC_PATH DEST_PATH|-
- docker cp [OPTIONS] SRC_PATH|- CONTAINER:DEST_PATH [flags]
有了JVM工具,我们就可以开始分析咯。
三、查GC情况
通过jstat查看gc情况
- bin/jstat -gcutil 1 1s

看样子没有什么问题,full gc也少。再看一下对象的占用情况,由于是容器内部,进程号为1,执行如下命令:
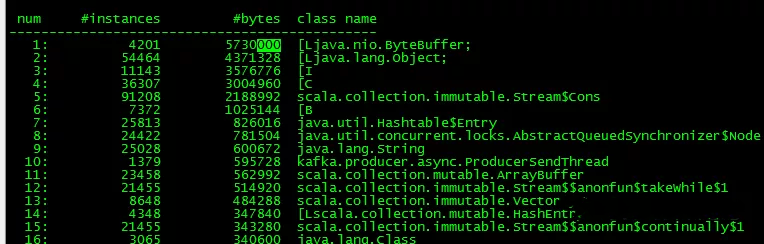
- bin/jmap -histo 1 |more
发现ByteBuffer对象占用最高,这是异常点一。
四、查线程快照情况
通过jstack查看线程快照情况。
- bin/jstack -l 1 > thread.txt
下载快照,这里推荐一个在线的线程快照分析网站。
- https://gceasy.io
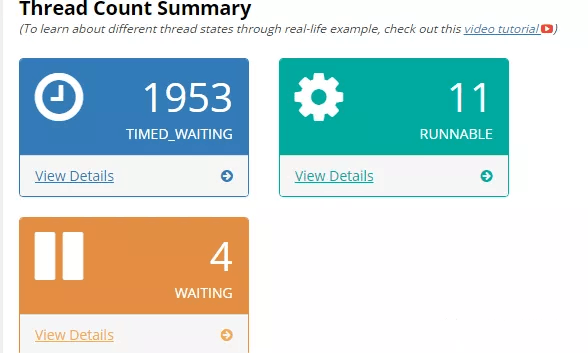
上传后,发现创建的线程近2000个,且大多是TIMED_WAITING状态。感觉逐渐接近真相了。点击详情发现有大量的kafka-producer-network-thread | producer-X 线程。如果是低版本则是大量的ProducerSendThread线程。(后续验证得知),可以看出这个是kafka生产者创建的线程,如下是生产者发送模型:
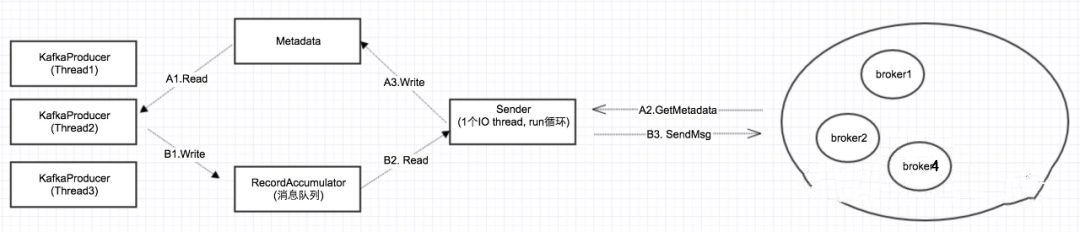
据生产者的发送模型,我们知道,这个sender线程主要做两个事,一是获取kafka集群的Metadata共享给多个生产者,二是把生产者送到本地消息队列中的数据,发送至远端集群。而本地消息队列底层的数据结构就是java NIO的ByteBuffer。
这里发现了异常点二:创建过多kafka生产者。
由于没有业务代码,决定写一个Demo程序来验证这个想法,定时2秒创建一个生产者对象,发送当前时间到kafka中,为了更好的观察,启动时指定jmx端口,使用jconsole来观察线程和内存情况,代码如下:
- nohup java -jar -Djava.rmi.server.hostname=ip
- -Dcom.sun.management.jmxremote.port=18099
- -Dcom.sun.management.jmxremote.rmi.port=18099
- -Dcom.sun.management.jmxremote.ssl=false
- -Dcom.sun.management.jmxremote.authenticate=false -jar
- com.hyq.kafkaMultipleProducer-1.0.0.jar 2>&1 &
连接jconsole后观察,发现线程数一直增长,使用内存也在逐渐增加,具体情况如下图:

故障原因回顾
分析到这里,基本确定了,应该是业务代码中循环创建Producer对象导致的。在kafka生产者发送模型中封装了 Java NIO中的 ByteBuffer 用来保存消息数据,ByteBuffer的创建是非常消耗资源的,尽管设计了BufferPool来复用,但也经不住每一条消息就创建一个buffer对象,这也就是为什么jmap显示ByteBuffer占用内存最多的原因。
总结
在日常的故障定位中,多多使用JDK自带的工具,来帮助我们辅助定位问题。一些其他的知识点:jmap -histo显示的对象含义:
[C 代表 char[]
[S 代表 short[]
[I 代表 int[]
[B 代表 byte[]
[[I 代表 int[][]
如果导出的dump文件过大,可以将MAT上传至服务器,分析完毕后,下载分析报告查看,命令为:
- ./mat/ParseHeapDump.sh active.dump org.eclipse.mat.api:suspects
- org.eclipse.mat.api:overview org.eclipse.mat.api:top_components
可能尽快触发Full GC的几种方式:
- System.gc();或者Runtime.getRuntime().gc();
- jmap -histo:live或者jmap -dump:live。
这个命令执行,JVM会先触发gc,然后再统计信息。 - 老生代内存不足的时候

