
微服务17:微服务治理之异常驱逐原创
★微服务系列
微服务1:微服务及其演进史
微服务2:微服务全景架构
微服务3:微服务拆分策略
微服务4:服务注册与发现
微服务5:服务注册与发现(实践篇)
微服务6:通信之网关
微服务7:通信之RPC
微服务8:通信之RPC实践篇(附源码)
微服务9:服务治理来保证高可用
微服务10:系统服务熔断、限流
微服务11:熔断、降级的Hystrix实现(附源码)
微服务12:流量策略
微服务13:云基础场景下流量策略实现原理
微服务14:微服务治理之重试
微服务15:微服务治理之超时
微服务16:微服务治理之熔断、限流
1 介绍
大家都知道,一个主机(或称为节点)可以部署多个Pod,Pod作为Kubernetes中的最小部署单元。是一组一个或多个紧密关联的容器的集合,它们共享相同的网络命名空间和存储卷。
一般来说,服务上云之后,我们的服务会配置 anti-affinity(反亲和调度),他有哪些利弊权衡呢:
- affinity 可以实现就近部署,增强网络能力实现通信上的就近路由,减少网络的损耗。如同一个BCC聚类多个实例Pod。
- anti-affinity 反亲和性主要是出于高可靠性考虑,尽量分散实例Pod,某个节点故障的时候,对应用的影响只是 N 分之一或者单实例。
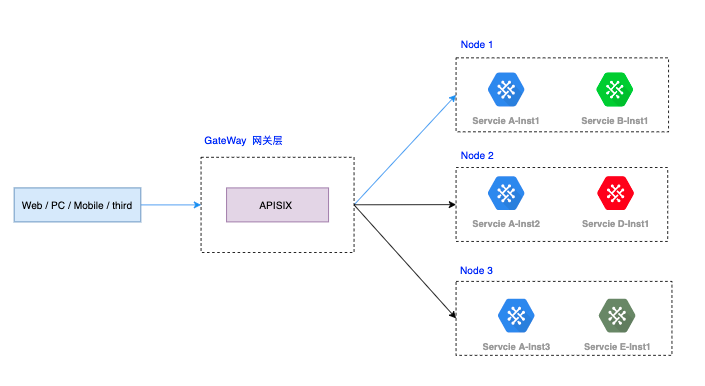
所以,最终的部署结构可能是:
同一个服务(如 Service A)的实例不会部署在同一个主机节点上(Node),即Node1上不会同时存在 Service-A-Ins1 和 Service-A-Ins2,这就好比如把鸡蛋分在不同的篮子里,不会因为一个主机节点故障导致全盘失败的风险。
但是依然不能解决一个问题,就是主机上可能部署了别的服务,如Service-A和B、C、D混部,虽然你们运行在不同的主机上,但是如果因为BCD服务导致的故障把整个主机节点都拖垮了,依然会影响你们的稳定性,至少是你们某个实例的稳定性。
所以需要强有力的解决方案来高保你们服务健壮存活着。
2 实例异常之后的解决方案
2.1 对集群的异常实例进行驱逐
下面以Istio为例子说明
服务混部模型下,经常会因为某一个或者某几个实例的故障而导致整个服务可用性降低。适当的把故障的实例短暂的驱逐出集群,可以保证整个集群的健康。
★ 这种手段在云基础上我们称之为离群检测(Outlier Detection):
当集群中的服务故障的时候,其实我们最优先的做法是先进行离群,然后再检查问题,处理问题并恢复故障。所以,能否快速的离群对系统的可用性很重要。
Outlier Detection 允许你对上游的服务进行扫描,然后根据你设置的参数来判断是否对服务进行离群。
下面的配置表示每秒钟扫描一次上游主机,连续失败 2 次返回 5xx 错误码的所有主机会被移出负载均衡连接池 3 分钟,上游被离群的主机在集群中占比不应该超过10%。
但无论比例多少,只要你集群下的服务实例>=2个,都将弹出至少1个主机。它有很详细的配置,参考。
注意:3分钟之后回群,如果再被离群,则为上次离群时间+本次离群时间,即 3+3;默认恐慌阈值为0,不启用,建议设置30%(可调整比例)被离群,进入恐慌模式,不再驱逐。

outlierDetection:
consecutiveErrors: 2
interval: 1s
baseEjectionTime: 3m
maxEjectionPercent: 10
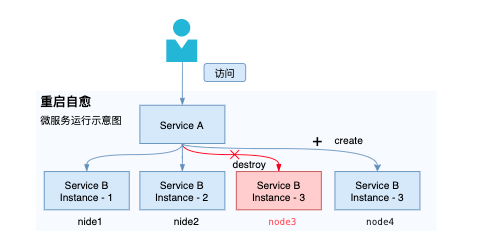
2.2 单(实例)节点的长时间故障不可用
当一个集群实例保持长时间的异常,或者说在指定时间驱逐回归之后依然是异常状态,则说明该实例的环境(或者该实例所属的主机环境)始终保持在一个不健康的状态。
比较好的自愈办法是:隔离并摘除流量,重启之后调度在另一台主机上去创建一个新实例,重新引入流量,达到故障恢复的目的。
实例容器重建能力一般是采用容器健康探针来进行摘流和重启。需要注意的是,极端异常会引发批量重启,这其实是个缺陷。
解决方案是PDB(Pod Disruption Budget),它负责中断预算,避免过度重启导致问题!PDB的作用就是通过控制 minAvailable(maxUnavailable)来控制存活的Pod实例,低于这个数,无论如何都不让重启了。
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: svc-a-pdb
spec:
minAvailable: 8 #svc-a至少要有8个实例是存活着得
selector:
matchLabels:
app: svc-a
3 总结
云基础场景下的多副本服务的单个副本出故障或者异常的现象在业内还是很常见的,这边讲解了初级版的异常驱逐和容器重启,
而且这种驱逐和重启是在平滑下执行的,对用户无感,让用户有一个更优良的使用体验。
在后续的章节我们在了解下大集群模式下的高可用架构怎么设计。


