
【云原生•监控】基于Prometheus的云原生集群监控(理论+实践)-03原创
【云原生•监控】基于Prometheus的云原生集群监控(理论+实践)-03
k8s服务组件指标
kubernetes云原生集群作为大规模多节点容器调度平台,在交付和部署上的巨大优势逐渐让其称为一种技术趋势,如基于工作负载快速进行扩/缩容、故障自愈、资源弹性等。
但是,另一方面kubernetes云原生集群「复杂性较高」,集群自身存在非常多的组件,如master节点上运行着:api-server组件、etcd组件、kube-scheduler组件、kube-controller-manager组件、coredns组件等,node节点上有kubelet组件、kube-proxy组件等。这里还隐含着另一个问题就是:一旦云原生集群出现问题,云原生集群上部署的应用组件可能都会受到影响,「影响面比较大」。
所以,作为云原生集群的运维人员,关注云原生集群组件的整体运行情况,特别是一些核心组件的运行状况,避免某些组件出现性能瓶颈、异常奔溃等导致整个云原生集群性能低下甚至不可用风险的发生,这一节我们就来重点关注下云原生集群核心组件的监控。
kubernetes架构
在对kubernetes服务组件进行监控之前,我们要先来了解下kubernetes的架构(见下图):
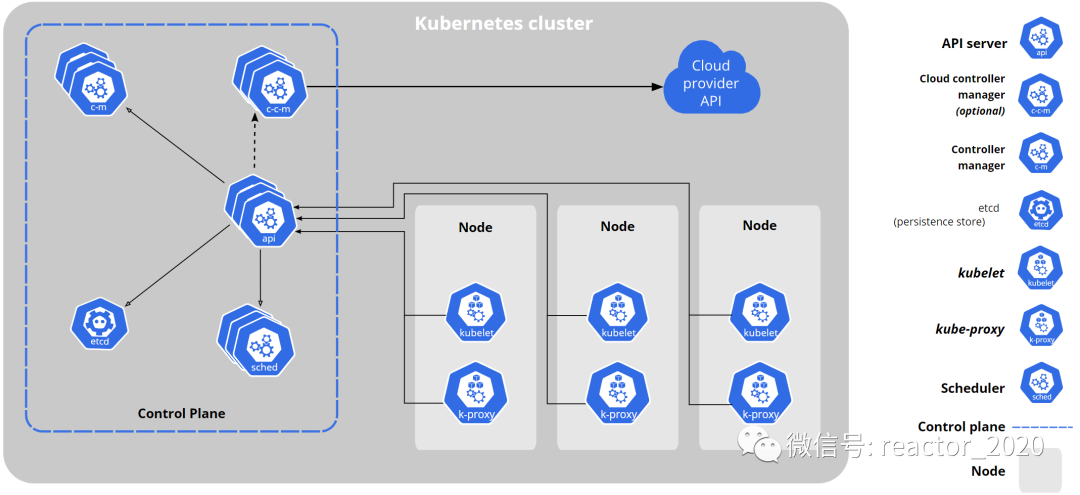
kubernetes集群节点大致分为两类:控制节点和工作节点。
左边蓝色框框中就是控制节点上运行的核心组件:
-
API Server组件:API Server可以看着的整个集群的大脑,从图上可以看出基本所有组件都要和API Server组件进行交互,同时,内外部接口请求也都要经过API Server组件,如kubectl指令、client-go获取监听集群资源等。 -
ETCD组件:API Server组件作为集群的对外接口层,会接收大量外部请求,肯定需要持久化数据库存储这些元数据信息,ETCD组件就是kubernetes元数据存储的数据库。 -
Scheduler组件:kubernetes作为大规模多节点容器调度平台,可灵活的基于多种策略实现容器的调度,这就是Scheduler组件的职责。 -
Controller Manager组件:kubernetes中核心的设计理念是声明式,kubernetes集群中所有的操作都可以通过声明式的yaml文件将需求描述清楚,具体底层如何实现用户是无需太多关注的,这其中背后实现的逻辑就是kubernetes集群中存在的大量控制器的功劳,kubernetes二次开发主要也是自定义各种控制器,而Controller Manager组件就是管理这些控制器的管理器。
右边框框就是工作节点,控制节点相当于集群管理层,驱动着整个集群的运行,而工作节点是真正运行业务容器的节点,即将控制节点调度分配过来的任务干好即可。其核心组件:
-
kubelet组件:工作节点上最重要的一个组件就是kubelet组件,主要负责底层容器创建、管理、运行等,kubelet基于CRI(Container Runtime Interface)与容器运行时(Docker、containerd等)进行通信,这种标准化的接口使得kubernetes能够与不同的容器运行时进行交互,提高了系统的灵活性和可扩展性。 -
kube-proxy组件:kube-proxy是kubernetes集群中负责网络代理和负载均衡的重要组件,它通过转发请求、负载均衡和会话绑定等功能,确保服务的可访问性和高可用性,为应用程序提供稳定和可靠的网络服务。
API Server组件监控
1、API Server作为kubernetes最核心的组件,当然他的监控也是非常有必要的。API Server组件部署在kube-system命名空间下:
[root@k8s-01 manifests]# kubectl get pod -n kube-system -owide -l component=kube-apiserver
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-apiserver-k8s-01 1/1 Running 2 21d 192.168.31.160 k8s-01 <none> <none>
并在default命名空间下创建service,并通过手工配置endpoint:
[root@k8s-01 manifests]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 519d
[root@k8s-01 manifests]# kubectl get ep kubernetes
NAME ENDPOINTS AGE
kubernetes 192.168.31.160:6443 519d
2、因此,我们可以基于service的endpoints服务发现:
- job_name: 'kube-apiserver'
metrics_path: metrics
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_name]
regex: kubernetes
action: keep
- source_labels: [__meta_kubernetes_endpoint_port_name]
regex: https
action: keep
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
3、通过prometheus target界面查看采集点接入正常:

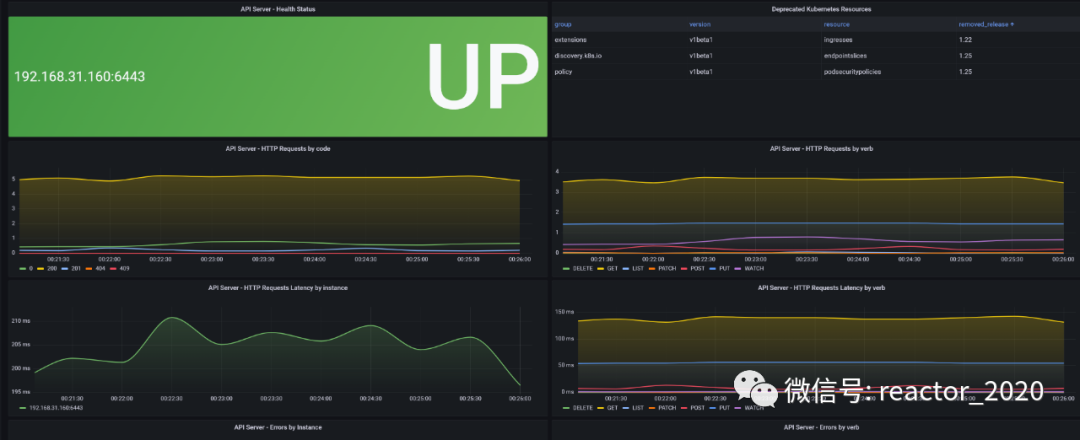
4、导入15761 dashboard,API Server组件监控指标就展示到模板上。
比如可以看到API Server组件健康检查状态,API Server组件作为kubernetes集群大脑,主要对外提供API接口,所以,这里重点监控API Server组件的请求量、请求响应延迟大小、错误请求量等:
ETCD组件监控
kubernetes集群的ETCD默认是开启暴露metrics数据的。
1、获取Etcd Pod名称:
[root@k8s-01 manifests]# kubectl edit pod etcd-k8s-01 -n kube-system
spec:
containers:
- command:
- etcd
- --advertise-client-urls=https://192.168.31.160:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt
- --client-cert-auth=true
- --data-dir=/var/lib/etcd
- --initial-advertise-peer-urls=https://192.168.31.160:2380
- --initial-cluster=k8s-01=https://192.168.31.160:2380
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --listen-client-urls=https://127.0.0.1:2379,https://192.168.31.160:2379
- --listen-metrics-urls=http://127.0.0.1:2381
- --listen-peer-urls=https://192.168.31.160:2380
- --name=k8s-01
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --snapshot-count=10000
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_imag
我们可以看到启动参数里面有一个 --listen-metrics-urls=http://127.0.0.1:2381 的配置,该参数就是来指定 Metrics 接口运行在 2381 端口下面的,而且是http的协议,所以也不需要什么证书配置,这就比以前的版本要简单许多了,以前的版本需要用 https 协议访问,所以要配置对应的证书。
注意:这里监听的是127.0.0.1,需要修改/etc/kubernetes/manifests/etcd.yaml,将--listen-metrics-urls=http://127.0.0.1:2381修改成--listen-metrics-urls=http://0.0.0.0:2381,编辑后会自动更新Pod(静态Pod)。
2、创建etcd组件service服务:
apiVersion: v1
kind: Service
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
spec:
type: ClusterIP
clusterIP: None #设置为None,不分配Service IP
ports:
- name: port
port: 2381
---
apiVersion: v1
kind: Endpoints
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
subsets:
- addresses:
- ip: 192.168.31.160 # 指定etcd节点地址,如果是集群则继续向下添加
nodeName: k8s-01
ports:
- name: port
port: 2381 # Etcd 端口号
3、prometheus监控接入:
- job_name: 'kube-etcd'
metrics_path: metrics
scheme: http
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_name]
regex: etcd-k8s
action: keep
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
4、通过prometheus target界面查看采集点接入正常:

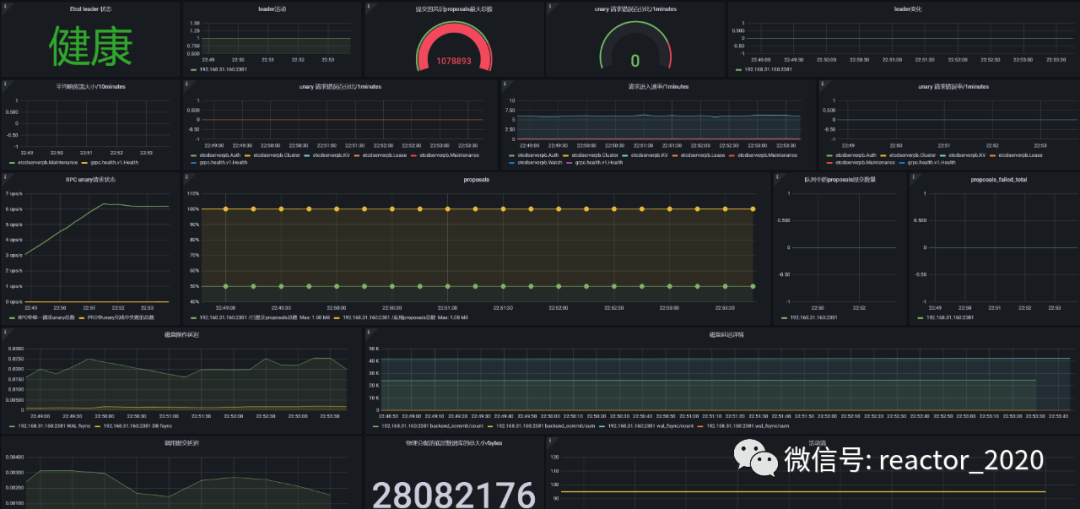
5、导入3973 或者 3070 dashboard,ETCD组件监控指标就展示到模板上。
Scheduler组件监控
1、创建kube-scheduler组件service:kube-scheduler.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
selector:
component: kube-scheduler
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10251
targetPort: 10251
protocol: TCP
2、修改/etc/kubernetes/manifests/kube-scheduler.yaml
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
- --port=0
image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/kube-scheduler:v1.21.0
imagePullPolicy: IfNotPresent
livenessProbe:
修改点主要有两处:
-
将 --bind-address=127.0.0.1修改成--bind-address=0.0.0.0,否则外部无法访问。 -
使用 --port标志为 HTTP 服务指定端口,你可能已经完全--port=0禁用HTTP服务,这里配置--port=10251。
修改完成后等待重启:
[root@k8s-01 kube-scheduler]# kubectl get pod -n kube-systemz -n kube-system -owide|grep kube-scheduler
kube-scheduler-k8s-01 1/1 Running 0 5m37s 192.168.31.160 k8s-01 <none> <none>
在kube-scheduler-k8s-01组件运行的master节点(k8s-01)上查看端口是否开启监听:
[root@k8s-01 prometheus]# netstat -antp|grep 10251
tcp6 0 0 :::10251 :::* LISTEN 68892/kube-schedule
tcp6 0 0 192.168.31.160:10251 192.168.31.161:57196 ESTABLISHED 68892/kube-schedule
[root@k8s-01 prometheus]# netstat -antp|grep 10259
tcp6 0 0 :::10259 :::* LISTEN 68892/kube-schedule
❝--port=0禁用时,只有10259 HTTPS监听端口开启,将--port=10251配置后,10251 HTTP监听端口也会开启。
❞
3、prometheus监控接入:
- job_name: 'kube-scheduler'
metrics_path: metrics
scheme: http
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: false
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_name]
regex: kube-scheduler
action: keep
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
4、通过prometheus target界面查看采集点接入正常:

Controller Manager组件
1、创建kube-scheduler组件service:kubeControllerManager.yaml
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
spec:
selector:
component: kube-controller-manager
type: ClusterIP
clusterIP: None
ports:
- name: https-metrics
port: 10252
targetPort: 10252
protocol: TCP
2、修改/etc/kubernetes/manifests/kube-controller-manager.yaml
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
- --port=0
image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/kube-scheduler:v1.21.0
imagePullPolicy: IfNotPresent
livenessProbe:
修改点主要有两处:
-
将 --bind-address=127.0.0.1修改成--bind-address=0.0.0.0,否则外部无法访问。 -
使用 --port标志为 HTTP 服务指定端口,你可能已经完全--port=0禁用HTTP服务,这里配置--port=10252。
修改完成后等待重启:
[root@k8s-01 manifests]# kubectl get pod -n kube-systemz -n kube-system -owide|grep kube-controller-manager
kube-controller-manager-k8s-01 1/1 Running 0 35s 192.168.31.160 k8s-01 <none> <none>
在kube-controller-manager-k8s-01组件运行的master节点(k8s-01)上查看端口是否开启监听:
[root@k8s-01 manifests]# netstat -antp|grep 10252
tcp6 0 0 :::10252 :::* LISTEN 125547/kube-control
[root@k8s-01 manifests]# netstat -antp|grep 10257
tcp6 0 0 :::10257 :::* LISTEN 125547/kube-control
❝--port=0禁用时,只有10257 HTTPS监听端口开启,将--port=10251配置后,10252 HTTP监听端口也会开启。
❞
3、prometheus监控接入:
- job_name: 'kube-controller-manager'
metrics_path: metrics
scheme: http
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: false
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_name]
regex: kube-controller-manager
action: keep
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
4、通过prometheus target界面查看采集点接入正常:

kubelet组件
kubelet组件集成cAdvisor,通过/metrics/cadvisor端点暴露容器性能指标,kubelet组件还通过/metrics端点暴露自身组件指标。
1、prometheus监控接入:
- job_name: "kubelet"
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
- replacement: /metrics
target_label: __metrics_path__
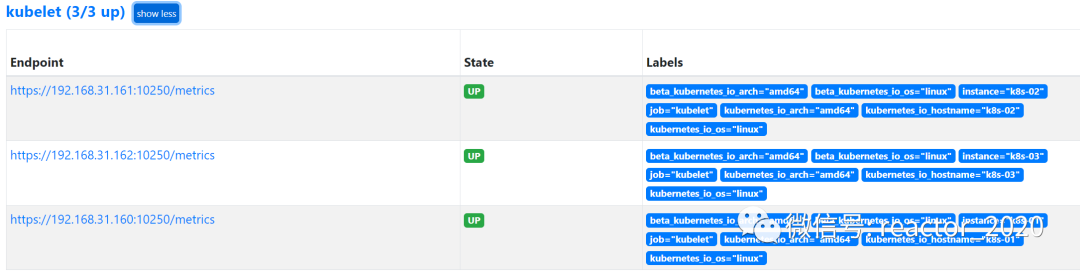
2、通过prometheus target界面查看采集点接入正常:
kube-proxy组件
kube-proxy默认暴露两个端口,一个是10249,在/metrics端点暴露监控指标,另一个是10256。可以使用netstat命令检查这两个端口是否监听:
[root@k8s-01 prometheus]# netstat -antp|grep 10256
tcp6 0 0 :::10256 :::* LISTEN 101021/kube-proxy
[root@k8s-01 prometheus]# netstat -antp|grep 10249
tcp 0 0 127.0.0.1:10249 0.0.0.0:* LISTEN 101021/kube-proxy
如果需要修改监听端口,修改kubectl edit configmap kube-proxy -n kube-system,将metricsBindAddress这段修改成metricsBindAddress: 0.0.0.0:10249即可。默认监听127.0.0.1,修改:
metricsBindAddress: 0.0.0.0:10249
然后重新启动kube-proxy这个pod:
[root@k8s-01 prometheus]# kubectl get pods -n kube-system | grep kube-proxy |awk '{print $1}' | xargs kubectl delete pods -n kube-system
pod "kube-proxy-75h6q" deleted
pod "kube-proxy-jhnbg" deleted
pod "kube-proxy-s8jmc" deleted
[root@k8s-01 prometheus]# kubectl get pod -n kube-system|grep kube-proxy
kube-proxy-s8nhd 1/1 Running 0 42s
kube-proxy-wx6vg 1/1 Running 0 44s
kube-proxy-xcq4t 1/1 Running 0 44s
再次使用netstat检测10249监听到0.0.0.0上:
[root@k8s-01 prometheus]# netstat -antp|grep 10249
tcp6 0 0 :::10249 :::* LISTEN 109228/kube-proxy
tcp6 0 0 192.168.31.160:10249 192.168.31.161:57096 ESTABLISHED 109228/kube-proxy
1、创建service:
# vi kube-proxy-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: kube-proxy
name: kube-proxy
namespace: kube-system
spec:
selector:
k8s-app: kube-proxy
type: ClusterIP
clusterIP: None
ports:
- name: https-metrics
port: 10249
targetPort: 10249
protocol: TCP
2、prometheus监控接入:
- job_name: 'kube-proxy'
metrics_path: metrics
scheme: http
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: false
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_name]
regex: kube-proxy
action: keep
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
3、通过prometheus target界面查看采集点接入正常:

CoreDNS
kubernetes集群中非常重要的CoreDNS插件,一般默认情况下就开启了 /metrics 接口:
kubectl get cm coredns -n kube-system -o yaml
上面ConfigMap中 prometheus :9153 就是开启prometheus的插件:
[root@k8s-01 ~]# kubectl get pods -n kube-system -l k8s-app=kube-dns -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-b98666c6d-cdhwp 1/1 Running 2 80d 192.165.61.208 k8s-01 <none> <none>
coredns-b98666c6d-zmg8t 1/1 Running 2 80d 192.165.61.206 k8s-01 <none> <none>
我们可以先尝试手动访问下 /metrics 接口,如果能够手动访问到那证明接口是没有任何问题的:
[root@k8s-01 ~]# curl http://192.165.61.208:9153/metrics|more
# TYPE coredns_build_info gauge
coredns_build_info{goversion="go1.15.3",revision="054c9ae",version="1.8.0"} 1
# HELP coredns_cache_entries The number of elements in the cache.
# TYPE coredns_cache_entries gauge
coredns_cache_entries{server="dns://:53",type="denial"} 31
coredns_cache_entries{server="dns://:53",type="success"} 7
# HELP coredns_cache_hits_total The count of cache hits.
# TYPE coredns_cache_hits_total counter
coredns_cache_hits_total{server="dns://:53",type="denial"} 23
coredns_cache_hits_total{server="dns://:53",type="success"} 6
# HELP coredns_cache_misses_total The count of cache misses.
# TYPE coredns_cache_misses_total counter
coredns_cache_misses_total{server="dns://:53"} 468
我们可以看到可以正常访问到,从这里可以看到CoreDNS的监控数据接口是正常的了,然后我们就可以将这个 /metrics 接口配置到 prometheus.yml 中去。
默认,以在kube-system命名空间下创建了CoreDNS组件的service:
[root@k8s-01 kube-dns]# kubectl get svc -n kube-system|grep dns
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 520d
CoreDNS组件监控接入配置:
- job_name: 'kube-dns'
metrics_path: metrics
scheme: http
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: false
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_name]
regex: kube-dns
action: keep
- source_labels: [__meta_kubernetes_endpoint_port_name]
regex: metrics
action: keep
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
通过prometheus target界面查看采集点接入正常:


[更多云原生监控运维,请关注微信公众号:云原生生态实验室]

