
【笔记】网络编程实战-上篇原创
一、概述
学习 JKSJ 《网络编程实战》的笔记
二、关键笔记
2.1、三次握手
为什么要三次握手,这个问题的本质是信道不可靠,但是通信双方需要就某个问题达成一致,而要解决这个问 题,无论你在消息中包含什么信息,三次通信是理论上的最小值。 所以三次握手不是 TCP 本身的要求,而是为了满足"在不可靠信道上可靠地传输信息"这一需求所导致的
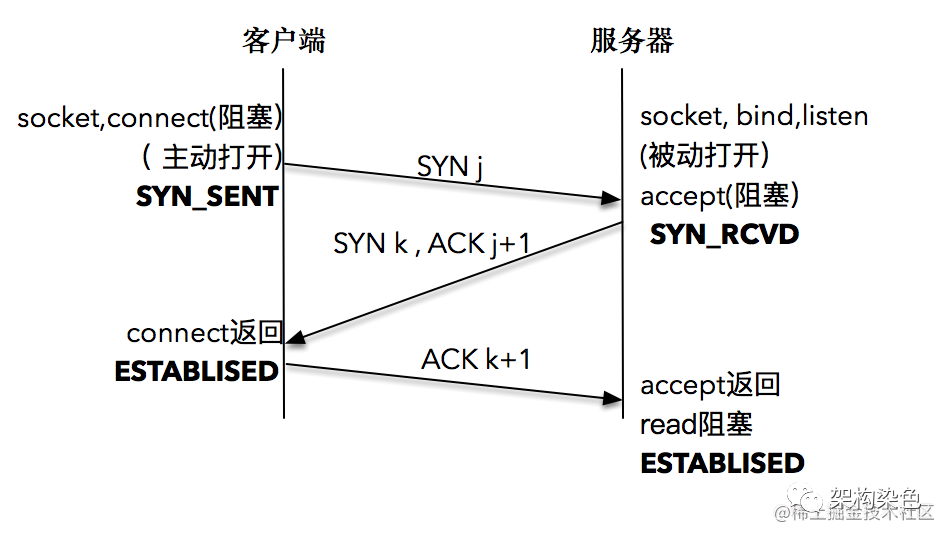
白话握手
-
【客户端】我要跟你建连 -
【服务端】收到,你确定嘛?(关键是要此时要跟客户端再核实一下,万一收到的消息是早些时候在网络中迷失的,实际已无效的消息) -
【客户端】嗯,我确定 -
【服务端】好的,我准备好了,咱们可以正式互发消息了
2.2、四次挥手
三次握手实际上也是四次,只是 SYN 和 ACK 二合一了,但是对于挥手来说,这两步不能合并,因为可能有善后工作未完成而不能立即回复 FIN
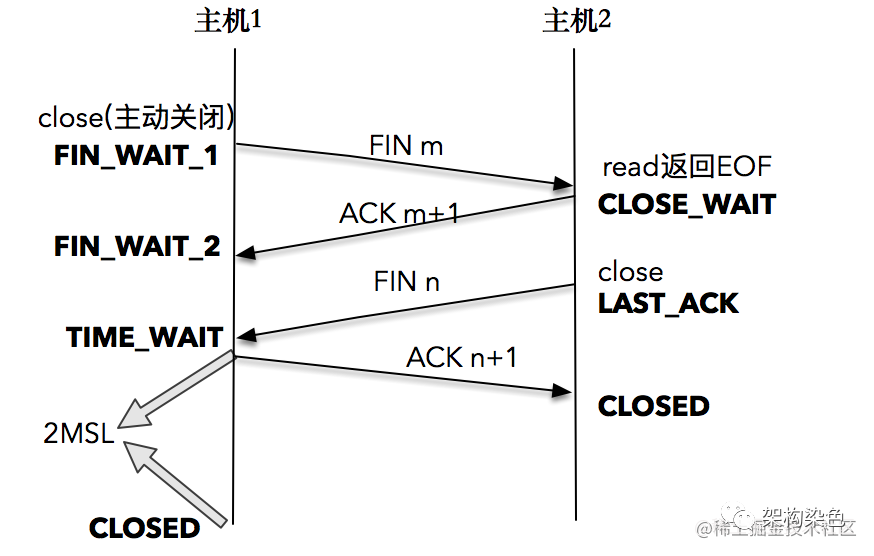
特别注意,主动关闭方接收到对方的 FIN 包,并确认这个 FIN 包后进入 TIME_WAIT 状态,而接收到 ACK 的被动关闭方则进入 CLOSED 状态。经过 2MSL 时间之后,主动关闭方也进入 CLOSED 状态。主动关闭方收到收到对方的一个 FIN 后回复 ACK,被动关闭方可能未收到 ACK,再一次发送 FIN。也就是说每次收到被关闭方的 FIN 后进入 TIME_WAIT 状态都会持续 2MSL 。MSL 是任何 IP 数据报能够在因特网中存活的最长时间,RFC793 中规定 MSL 的时间为 2 分钟,Linux 实际设置为 30 秒;也就是说,Linux 系统停留在 TIME_WAIT 的时间为固定的 60 秒。
白话挥手
-
【客户端】我想关闭连接,可以吗? -
【服务端】收到,你稍等我一下,有工作需要收尾,做完我通知你 -
【服务端】我这边完事了,你这边确定要关嘛?理论上 1MSL 分钟内你收到我的消息,2MSL 内我收到你的确认回复,要是我没收到我再问你 -
【客户端】收到 FIN 后,我确定关,可能 1MSL 你收不到我的回复,2MSL 内我会再收到你的关闭询问(FIN),所以我 2MSL 后我再关闭以确保你收到了。也确保你 2MSL 后才能收到新链接的数据,而 2MSL 内收到的都不是新连接的,而是老连接的,这样避免老连接迷失的数据对新链接产生干扰
-
TIME_WAIT 的引入是为了让 TCP 报文得以自然消失,同时为了让被动关闭方能够正常关闭; -
不要试图使用 SO_LINGER设置套接字选项,跳过 TIME_WAIT; -
现代 Linux 系统引入了更安全可控的方案(如 net.ipv4.tcp_tw_reuse),可以帮助我们尽可能地复用 TIME_WAIT 状态的连接。
2.3、net.ipv4.tcp_tw_reuse 优化 TIME_WAIT
tcp_tw_reuse 是内核选项,主要用在连接的发起方。TIME_WAIT 状态的连接创建时间超过 1 秒后,新的连接才可以被复用,注意,这里是连接的发起方,可以复用处于 TIME_WAIT 的套接字为新的连接所用,避免 TIME_WAIT 占用 2MSL 不得被用。
但使用有一个前提,需要打开对 TCP 时间戳的支持,即net.ipv4.tcp_timestamps=1(默认即为 1)。
2.4、SO_REUSEADDR 优化"Address in use"
服务器端程序重启之后,若碰到“Address in use”的报错信,导致服务器程序不能很快地重启。是因为服务端程序绑定本地地址和一个端口,然后就监听在这个地址和端口上,等待客户端连接的到来。当服务端重启时,服务端就是 socket 的主动关闭方,按照 TCP 协议规范,该条连接的 TCP 状态会在真正断开之前进入 TIME-WAIT 态,至少 1 分钟后才能再次重启成功,这是无法接受的
SO_REUSEADDR 是用户态的选项,此选项用来告诉操作系统内核,如果端口已被占用,但是 TCP 连接状态位于 TIME_WAIT ,可以重用端口。如果端口忙,而 TCP 处于其他状态,重用端口时依旧得到“Address already in use”的错误信息。
为什么端口可以复用呢?原因是现代 Linux 操作系统对此进行了一些优化。
-
第一种优化是新连接 SYN 告知的初始序列号,一定比 TIME_WAIT 老连接的末序列号大,这样通过序列号就可以区别出新老连接。
-
第二种优化是开启了 tcp_timestamps,使得新连接的时间戳比老连接的时间戳大,这样通过时间戳也可以区别出新老连接。
在这样的优化之下,一个 TIME_WAIT 的 TCP 连接可以忽略掉旧连接,重新被新的连接所使用。
2.5、合理设置监听队列 backlog 的大小
backlog 对程序的连接数没影响,但是影响的是还没有被 Accept 取出的连接。
服务器 TCP 内核 内维护了两个队列,称为 A(未连接队列)和 B(已连接队列),如果 A+B 的长度大于 Backlog 时,新的连接就会被 TCP 内核拒绝掉。所以,如果 backlog 过小,就可能出现 Accept 的速度跟不上,A,B 队列满了,就会导致客户端无法建立连接。
在 netty 实现中,backlog 默认通过 NetUtil.SOMAXCONN 指定;也可以在服务器启动启动时,通过 option 方法自定义 backlog 的大小。
参考:https://blog.csdn.net/weixin_44730681/article/details/113728895
2.6 KeepAlive
TCP 有一个保持活跃的机制叫做 Keep-Alive。在 Linux 系统中以下几个 sysctl 变量控制:
-
保活时间: net.ipv4.tcp_keepalive_time,默认设置是 7200 秒(2 小时) -
保活时间间隔: net.ipv4.tcp_keepalive_intvl,默认设置是 75 秒 -
保活探测次数: net.ipv4.tcp_keepalve_probes,默认设置是 9 次探测
所以使用 TCP 自身的 keep-Alive 机制,在 Linux 系统中,最少需要经过 2 小时 11 分 15 秒才可以发现一个“死亡”连接。这个时间是是通过 2 小时,加上 75 秒乘以 9 的总和。实际上,对很多对时延要求敏感的系统中,这个时间间隔是不可接受的。业务侧可按需添加更为灵活、时效性更强的判活机制。
2.7、Nagle 算法和延时 ACK 的组合。
1)Nagle 算法是发送端的优化算法
本质是限制大批量的小数据包同时发送,为此,它提出在任何一个时刻,未被确认的小数据包不能超过一个。这样,发送端就可以把接下来连续的几个小数据包存储起来,等待接收到前一个小数据包的 ACK 分组之后,再将数据一次性发送出去。
2)延时 ACK 算法是接收端的优化算法
接收端需要对每个接收到的 TCP 分组发送 ACK 报文,但是 ACK 报文本身是不带数据的,如果一直这样发送大量的 ACK 报文,就会消耗大量的带宽。延时 ACK 算法在收到数据后并不马上回复,而是累计需要发送的 ACK 报文,等到有数据需要发送给对端时,将累计的 ACK捎带一并发送出去。当然,延时 ACK 机制,不能无限地延时下去,否则发送端误认为数据包没有发送成功,引起重传,反而会占用额外的网络带宽。
3)Nagle 算法和延时 ACK 的组合。
Nagle 算法和延时确认组合在一起,增大了处理时延,实际上,两个优化彼此在阻止对方。
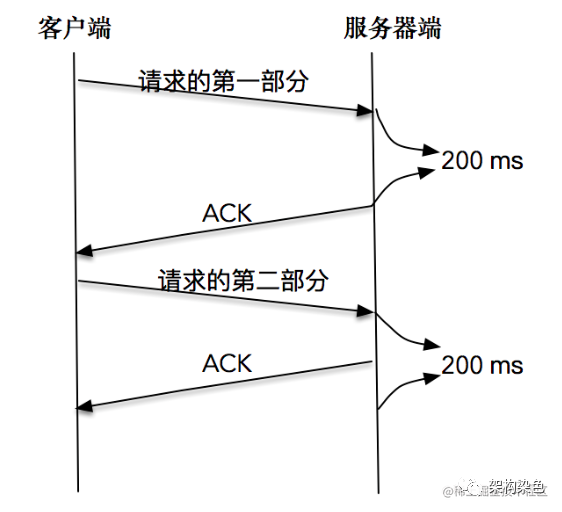
如客户端分两次将一个请求发送出去
-
由于请求的第一部分的报文未被确认,Nagle 算法开始起作用; -
同时延时 ACK 在服务器端起作用,假设延时时间为 200ms,服务器等待 200ms 后,对请求的第一部分进行确认; -
接下来客户端收到了确认后,Nagle 算法解除请求第二部分的阻止,让第二部分得以发送出去 -
服务器端在收到之后,进行处理应答,同时将第二部分的确认捎带发送出去。
-
可使用 TCP_NODELAY 禁用 Nagle 算法
2.8 select、poll、epoll
1)select
select 是常见的 I/O 多路复用技术,它通过描述符集合来表示检测的 I/O 对象,通过三个不同的描述符集合来描述 I/O 事件 :可读、可写和异常。但是 select 有一个缺点,那就是所支持的文件描述符的个数是有限的。在 Linux 系统中,select 的默认最大值为 1024。
2)poll
poll 突破文件描述符个数(1024)限制;和 select 另一个非常不同的地方在于,poll 每次检测之后的结果不会修改原来的传入值,而是将结果保留在 revents 字段中,这样就不需要每次检测完都得重置待检测的描述字和感兴趣的事件。我们可以把 revents 理解成“returned events”。
-
epoll
任一时间只有部分的 socket 是“活跃”的,但是 select/poll 每次调用都会[线性扫描]全部的集合,导致效率呈现线性下降。但是 epoll 不存在这个问题,它只会对“活跃”的 socket 进行操作---这是因为在内核实现中 epoll 是根据每个 fd 上面的 callback 函数实现的。那么,只有“活跃”的 socket 才会主动的
最后
我是石页兄,如果这篇文章对您有帮助,或者有所启发的话,欢迎关注笔者的微信公众号【 架构染色 】进行交流和学习。您的支持是我坚持写作最大的动力。

