
【全网首发】微服务15:微服务治理之超时原创
2年前
550777
★微服务系列
微服务1:微服务及其演进史
微服务2:微服务全景架构
微服务3:微服务拆分策略
微服务4:服务注册与发现
微服务5:服务注册与发现(实践篇)
微服务6:通信之网关
微服务7:通信之RPC
微服务8:通信之RPC实践篇(附源码)
微服务9:服务治理来保证高可用
微服务10:系统服务熔断、限流
微服务11:熔断、降级的Hystrix实现(附源码)
微服务12:流量策略
微服务13:云基础场景下流量策略实现原理
微服务14:微服务治理之重试
1 介绍
在复杂的互联网场景中,不可避免的会因为一些内在或者外在的因素,导致出现请求超时的情况。
而典型的业务超时场景主要有如下:
- 网络延迟或者抖动或者丢包,从而导致响应时间变长。
- 容器甚至云主机资源瓶颈情况:如CPU使用率过高、内存使用是否正常、磁盘IO压力情况、网络时延情况等资源使用情况异常,也可能导致响应时间变长。
- 负载均衡性问题:多实例下分配的流量不均衡,目前看云基础场景,这个情况不多见。
- 突发洪峰请求:大部分对内的业务基本不存在非预期的流量,突发洪峰请求主要还是程序的调用不合理或者程序bug(内存泄露、循环调用、缓存击穿等)。
单个Pod实例,长耗时容易造成队列堆积,对资源损耗很大,快速的释放或者调度开是一个比较好的办法,是一种普遍可接受的降级方案,否则超时阻塞会导致服务长时间不可用。
而且这种影响是水平扩散的,同服务上的其他功能也会被争抢资源。

2 超时的常见治理手段
2.1 采用超时重试实现故障恢复
超时重试:对服务的核心接口进行细粒度配置,具体接口超时时间应该 ≥ TP999(即满足999‰的网络请求所需要的最低耗时)的耗时。
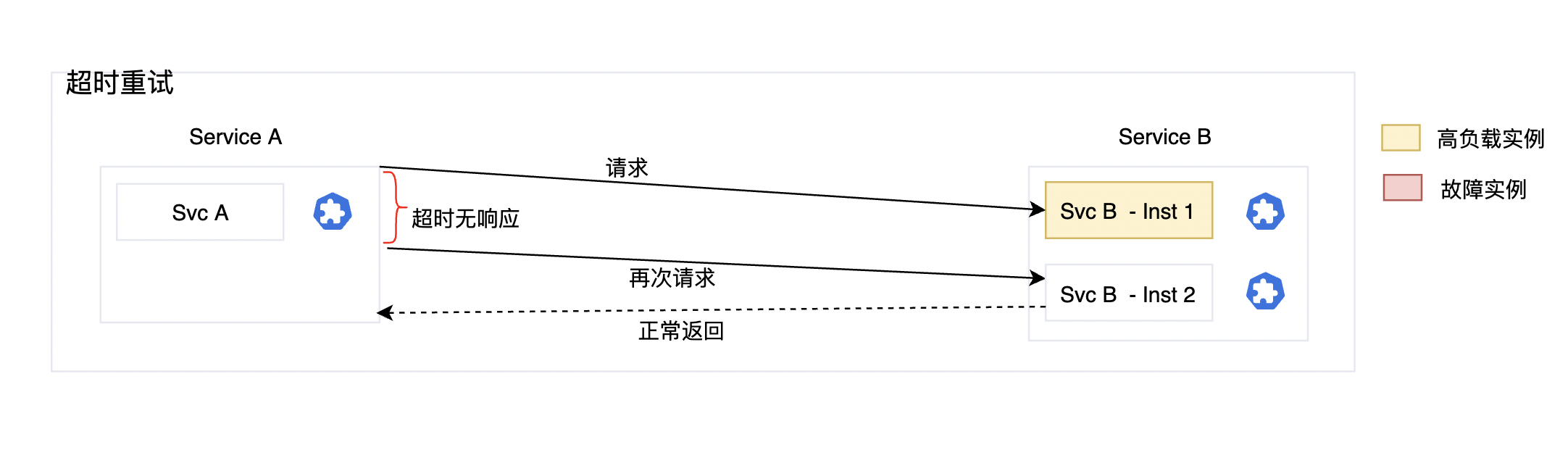
执行过程说明
- 这边以示例服务 Svc-A 向 Svc-B 发起访问为例子。
- 第1次执行,因为SvcB-Inst1高负载,所以在规定的时间内(比如2s)没有得到响应。
- 当请求方(Svc A)感知到超时无响应的时候,再次发起请求。
- 因为负载均衡策略,被请求方发生了变动,说明调度到新的实例(Svc-B-Instance1 到 Svc-B-Instance2)。
- 第二次请求返回正常的 200 。
2.1 采用超时断连实现系统保护
超时断连:通过指定超时时间对请求进行断连,达到降级的目的。避免长时间队列阻塞,导致雪崩沿调用向上传递,造成整个链路崩溃。
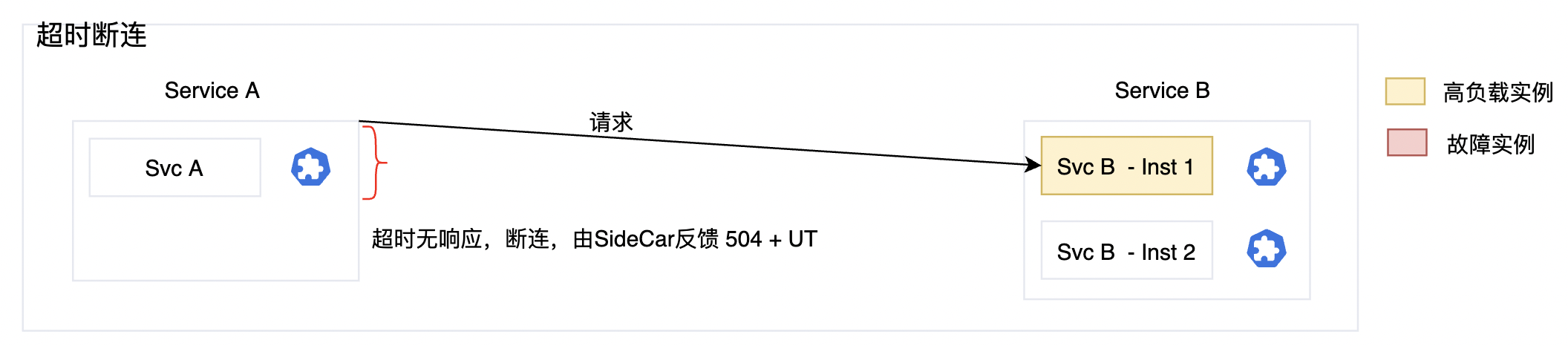
执行过程说明
- 这边以示例服务 Svc-A 向 Svc-B 发起访问为例子。
- 第1次执行,因为SvcB-Inst1高负载,所以在规定的时间内(比如2s)没有得到响应。
- 当请求方(Svc A)感知到超时无响应的时候,直接进行断连,不再发起请求。
- 如果使用Service Mesh 做微服务治理,则会由SideCar进行断连,并Response给请求方
- 504 代表 504 Gateway Time-out,flag = UT 代表 Upstream request timeout in addition to 504 response code。
3 策略实现(Service Mesh方案)
注释比较清晰了,这边就不解释了。
# VirtualService
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: xx-svc-b-vs
namespace: kube-ns-xx
spec:
hosts:
- svc_b.google.com # 治理发往 svc-b 服务的流量
http:
- match: # 匹配条件的流量进行治理
- uri:
prefix: /v1.0/userinfo # 匹配路由前缀为 /v1.0/userinfo 的,比如 /v1.0/userinfo/1305015
retries:
attempts: 1 # 重试一次
perTryTimeout: 1s # 首次调用和每次重试的超时时间
timeout: 2.5s # 请求整体超时时间为2.5s,无论重试多少次,超过该时间就断开。
route:
- destination:
host: svc_b.google.com
weight: 100
- route: # 其他未匹配的流量默认不治理,直接流转
- destination:
host: svc_c.google.com
weight: 100
4 总结
云基础场景下的治理手段各种各样,这边讲解了初级版的超时重试和超时熔断方案,让用户有一个更优良的使体验。
同时在系统大面积崩溃的时候,进行系统保护,不至于全面崩塌。
在后续的章节我们逐一了解下故障注入、熔断限流、异常驱逐等高级用法。
点赞收藏
分类:


