
我试图给你分享一种自适应的负载均衡。有点打脑壳,但是确实也有点厉害。原创
你好呀,我是歪歪。
这篇文章带大家来盘一个有点意思的负载均衡算法:
https://cn.dubbo.apache.org/zh-cn/overview/core-features/load-balance/
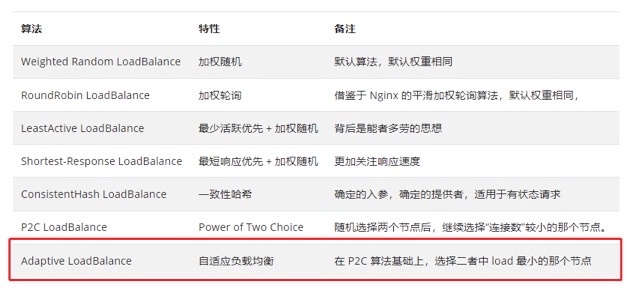
自适应负载均衡,虽然这个算法我是在 Dubbo 的源码里面看到的。但是这并不算是 Dubbo 的专属,而是一种算法思想,只不过你可以在 Dubbo 里面找到其对应的 Java 实现。
同样的,在 go-zero 里面,你也可以找到其对应的 Go 语言的实现。
关于这几种负载均衡策略,官方给了两个示意图。
https://cn.dubbo.apache.org/zh-cn/overview/reference/proposals/heuristic-flow-control
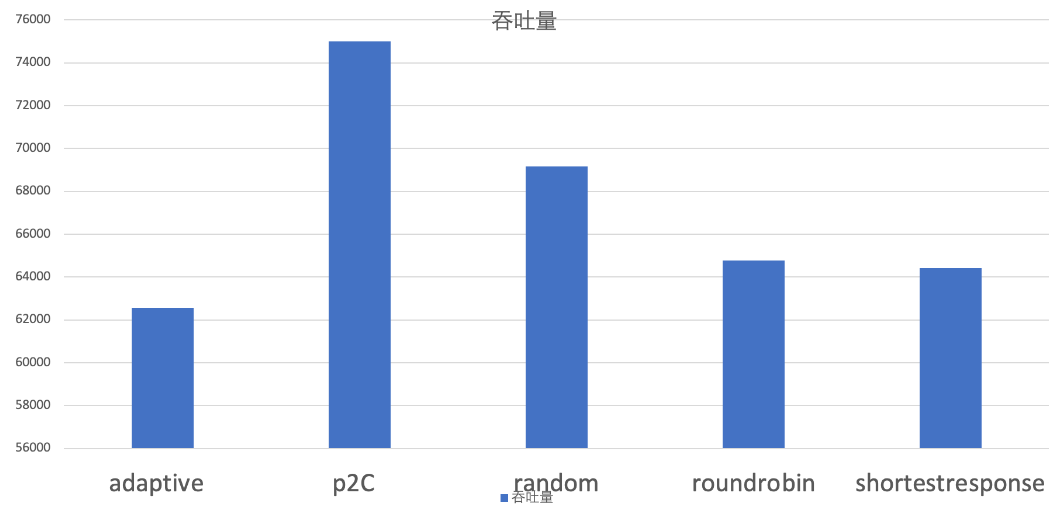
当服务提供端的机器配置比较均衡时,既每台机器的处理能力都差不多,甚至时一样的时候,可以看到 p2c 算法的吞吐量,遥遥领先:
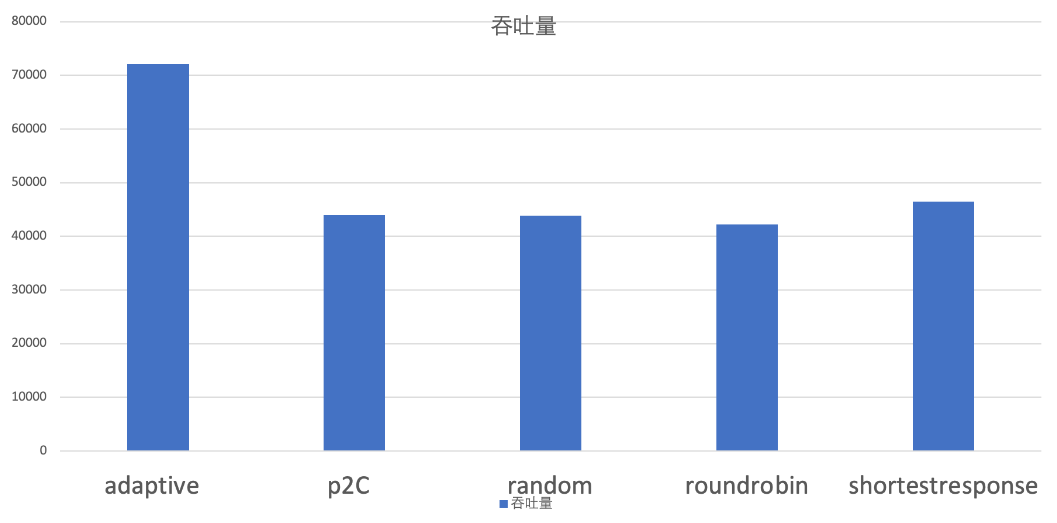
而当服务提供端的机器配置参差不齐的时候,也就是有的机器处理能力牛逼,有的又很拉跨的时候,adaptive 策略就比较出色了:
本文主要就带大家盘一下 adaptive 策略。
Demo
首先,还是不要偷懒,我们搞个 Demo 出来。
在 Dubbo 的官网上,不知道什么时候冒出来一个 Initializer 模块:

我体验了一下,利用这个搭建 Demo,和以前自己和 SpringBoot 搞融合的方式比起来,就一个字:非常的快!
https://start.dubbo.apache.org/bootstrap.html
关于这个 Initializer 模块的详细介绍,如果感兴趣可以自己去玩玩,我这里就不扩展了。
注意 Dubbo 版本选择 3.2.0 就行,因为我们要研究的自适应负载均衡策略是在这个版本中才开始支持的。
我创建的是一个 Single Module 项目,代码下载下来之后,结构是这样的:
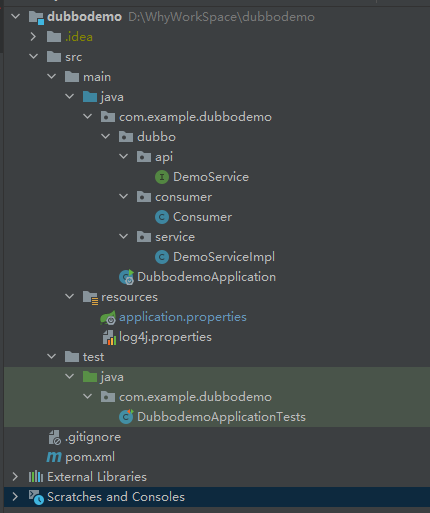
一个提供者,一个消费者。消费者继承了 CommandLineRunner 接口,在服务启动完成之后会自动去触发一次服务调用:
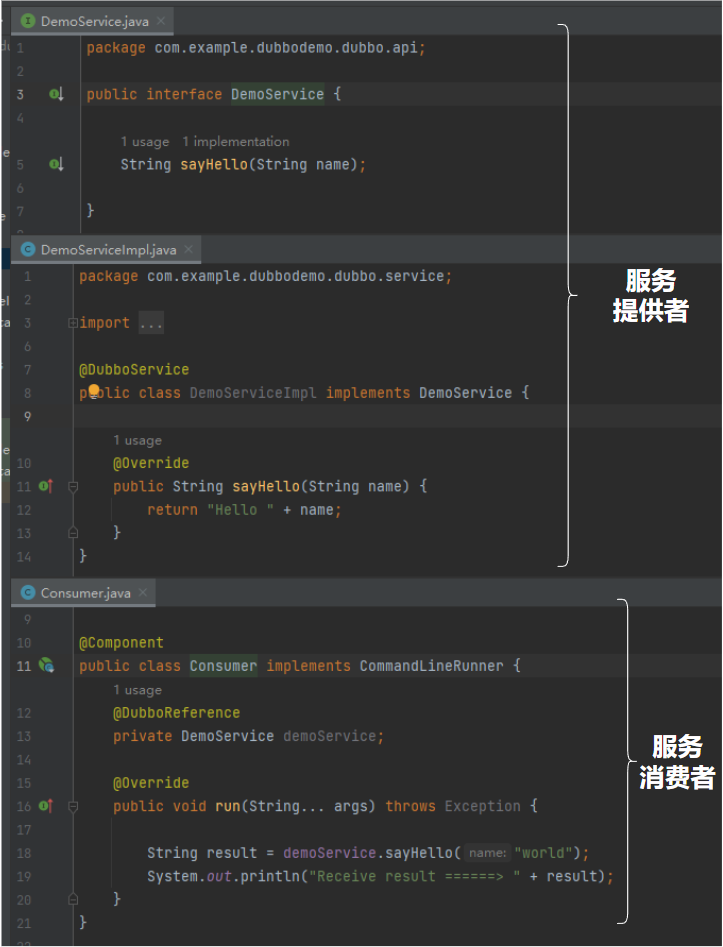
所以在项目打开,依赖拉取完毕之后,啥也不用管,我们先把项目启动起来,看看啥情况:
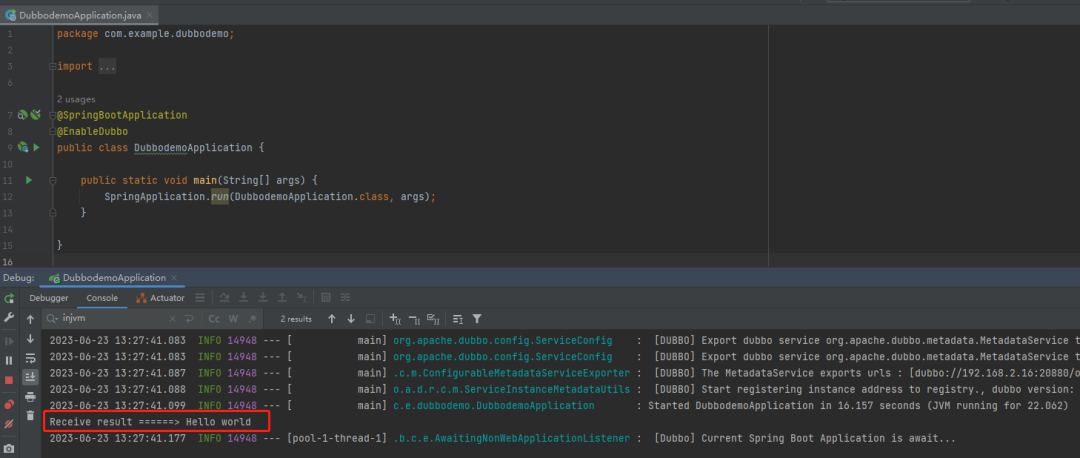
控制台输出了 Consumer 类中的内容,这样就算是完成了一次 Dubbo 调用,就这么简单。
如果你想要了解 Dubbo 服务的调用过程,那么你基本上就可以用这个 Demo 去进行调试了。
在服务提供者的实现类中打上断点,拿到调用栈,玩去吧:
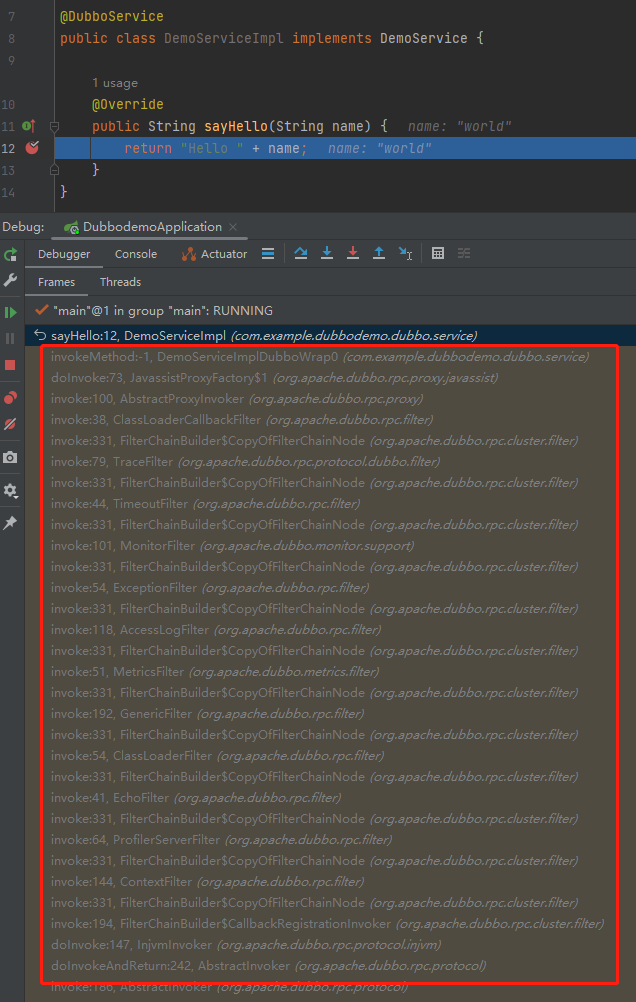
但是,你有没有感觉到一丝丝奇怪?
我们甚至都没有启动一个注册中心,就完成了一次 Dubbo 调用?
因为在 Demo 里面使用的是 injvm 协议,也就是本地调用:
https://cn.dubbo.apache.org/zh-cn/overview/mannual/java-sdk/advanced-features-and-usage/service/local-call/

所以,我们还需要对这个 Demo 进行一点改造,本次要调试的部分是负载均衡策略,需要使用远程调用才行。
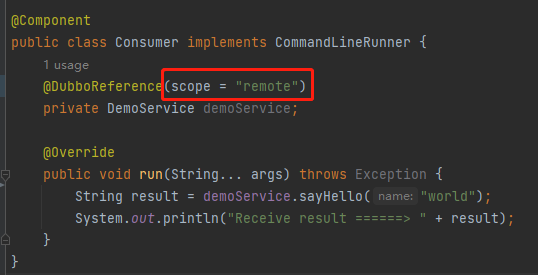
因此需要在服务引用的地方,加上 scope="remote" 配置:
然后在配置文件中配置注册中心:
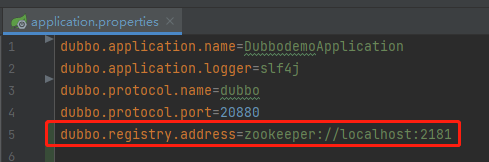
同时在自己本地启动一个 zookeeper。
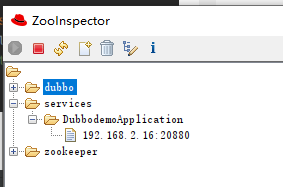
通过 ZooInspector 工具,可以看到在 20880 端口有一个服务提供者了:
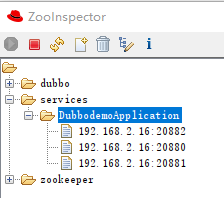
类似的,我们在 20881 和 20882 再搞一个服务提供者,一共三个。
有同学可能就要问了:为什么至少要三个呢?
如果只有一个服务提供者,也不需要进行负载均衡。
如果只有两个服务提供者,也用不上自适应负载均衡。
为什么?
我们再看一下关于它的描述。
自适应负载均衡:在 P2C 算法基础上,选择二者中 load 最小的那个节点
P2C 算法,是要随机选择两个节点。
如果你只有两个节点,还选个啥啊。
所以,如果我们要盘一下自适应负载均衡,服务提供方节点当然是越多越好,但是至少也需要 3 个节点。
源码
如果要启用自适应负载均衡算法,需要在服务引用的地方进行指定:
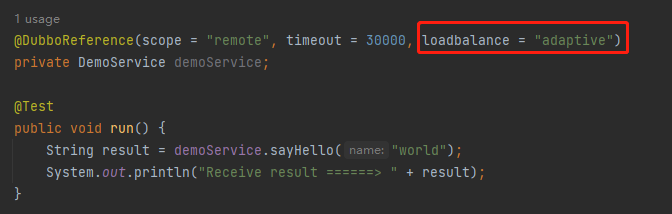
然后在对应的位置打上断点:
org.apache.dubbo.rpc.cluster.loadbalance.AdaptiveLoadBalance#doSelect
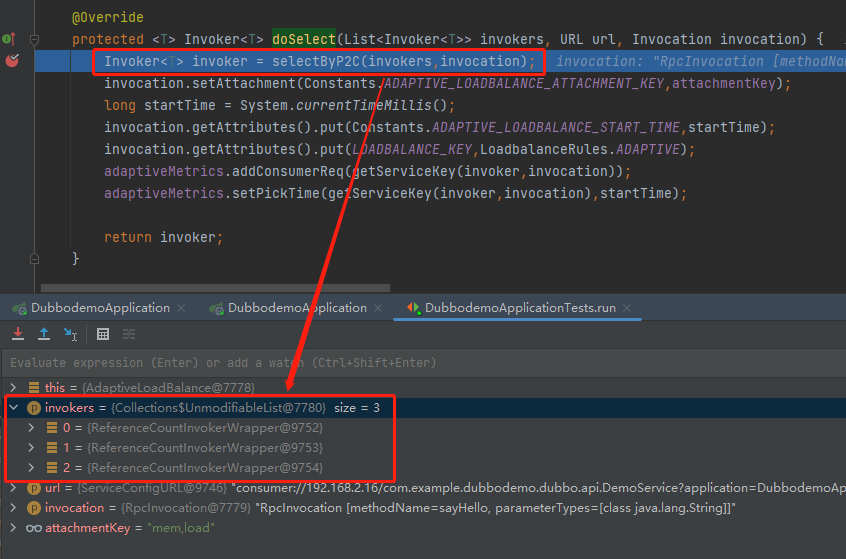
进入断点处,既 doSelect 方法的第一行的方法,就是叫做 selectByP2C,主打的就是一个开门见山。
可以看到这个方法的入参 invokers 的大小就是 3,它就是代表我们在 20880、20881、20882 端口启动的三个服务提供方。
进入 doSelect 方法,核心逻辑就两部分:
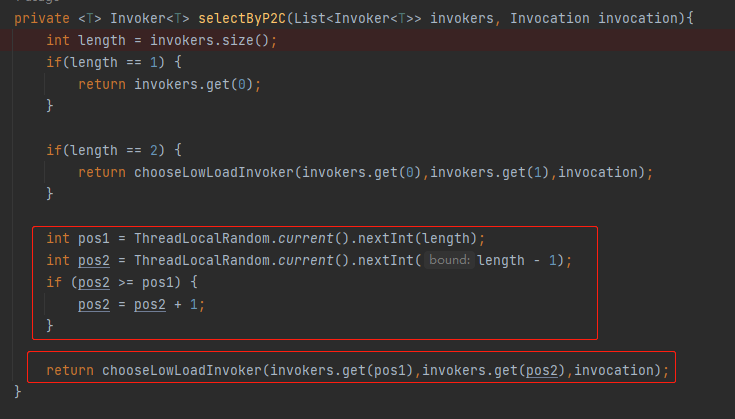
第一部分是这样的:
int pos1 = ThreadLocalRandom.current().nextInt(length);
int pos2 = ThreadLocalRandom.current().nextInt(length - 1);
if (pos2 >= pos1) {
pos2 = pos2 + 1;
}
你说这是在干啥?
虽然只有简单的四行代码,但是我还是给你缕一缕,因为我总感觉这个地方有 BUG。
首先,在我们的 Demo 中 length 就是 invokers 的大小,既为 3。
然后 pos1、pos2 代表的是 invokers 这个 List 的下标。
所以,
第一次随机,pos1 就是从 [0,3) 之间的正数。
第二次随机,pos2 就是从 [0,2) 之间的正数。
没问题对吧?
那么问题就来了:如果第一次没有随机出 2,即最后一个下标。那么第二次随机的时候由于执行了减一操作,所以最后一个下标根本就不可能被随机到。
所以,我认为这个随机算法对于 invokers 集合中的最后一个元素是不公平的,因为它少了一次参与随机的机会。
然后,它还有这样的两行代码:
if (pos2 >= pos1) {
pos2 = pos2 + 1;
}
目的是为了解决当 pos2 和 pos1 随机出一样的值的时候,把 pos2 进行加一处理。
首先, pos2 和 pos1 随机出一样的值,这个是完全有可能的。
其次,为什么不是 pos1 + 1 呢?或者说能不能是 pos1 + 1 呢?
不能。
因为,假设 pos1 是最后一个下标,再加一的话那么就越界了呀。
只能是 pos2 进行加一,因为 pos2 的最大值也只能是倒数第二个元素。
整个算法从逻辑上来说,完全是没有问题的,可以实现随机选择两个元素出来的逻辑。
但是,我总感觉对于最后一个元素,即 List 中最后一个服务提供者来说,确实是不太友好。它被选中的概率比其他的元素少了一半。
万一最后一个服务提供者,又恰好是一个性能牛逼的服务器呢?
这个地方不知道是不是我想错了,反正我之前写 P2C 的时候,是这样写的:
Object invoker1 = invokerList.remove(invokerList.size()-1);
Object invoker2 = invokerList.remove(invokerList.size()-1);
关于 Dubbo 源码这里为什么是这样的写法,我也不太明白。我看了 go-zero 对应部分的源码,也是和 Dubbo 一样的写法。不知道是不是我把自己给绕进去了。
算了,问题不大:

前面讲的代码,就是 P2C 思想的实现,是不是非常简单?
在我们的 Demo 中,选出来的就是 2,1 这两个 invokers:
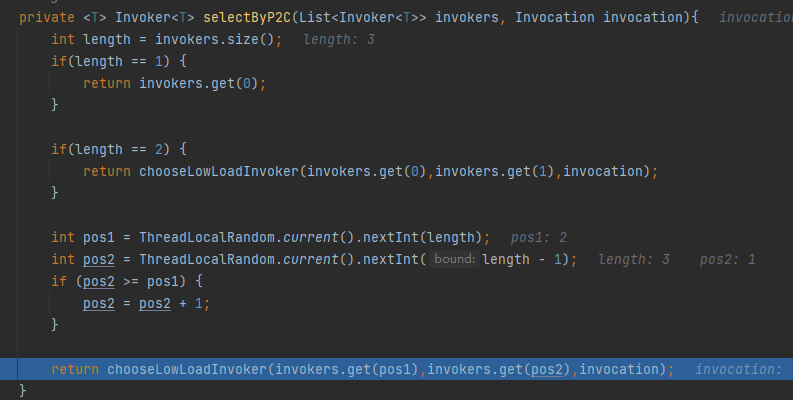
现在我们已经随机选择出了两个 invoker 了,那么应该由哪个 invoker 来执行这次的请求呢?
逻辑就来到了 chooseLowLoadInvoker 方法里面。从方法名可以知道,是要选择负载比较低的那个。
在这个方法里面,有两个关键变量,load1 和 load2:
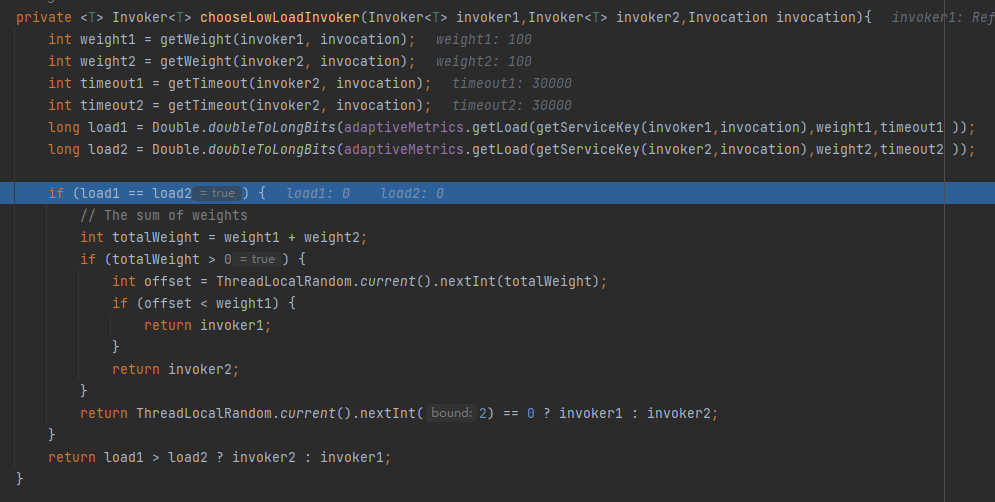
它们是经过某个公式计算出来的。
我们先看简单的情况,当 load1 和 load2 一样的时候,也就是说这两个 invoker 都可以使用,则按照权重选择一个。
当 load1 和 load2 不一样的时候,则选 load 值比较小的。
所以接下来的问题就变成了:如何计算 load 的值?
源码都在这个方法里面:
org.apache.dubbo.rpc.AdaptiveMetrics#getLoad
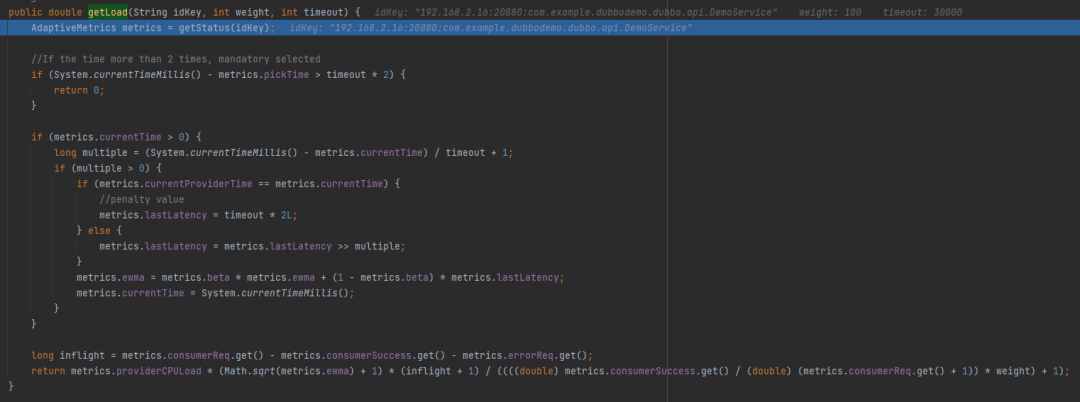
首先 getStatus 方法是获取一个 AdaptiveMetrics 对象。这个对象里面有一个 ConcurrentHashMap,内容是这样的:

以“ip:端口:方法”为 key, value 里面放了很多计算负载相关的字段:
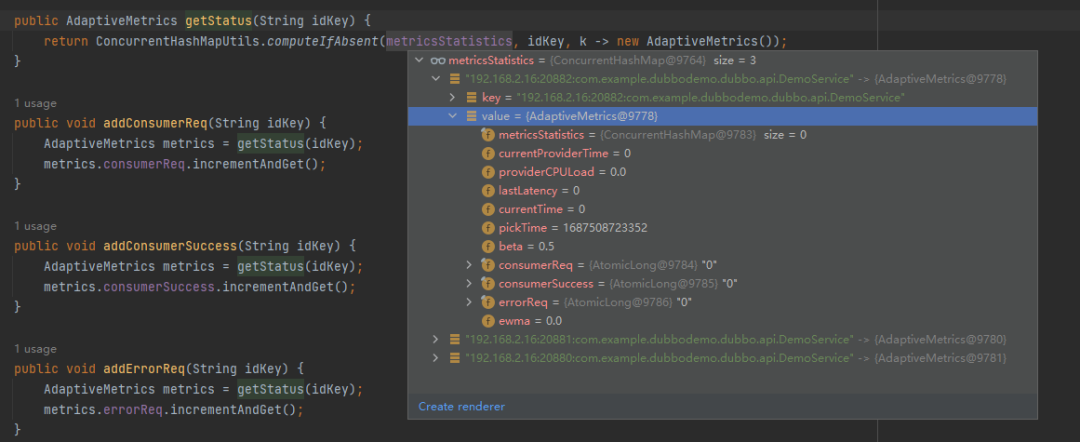
比如其中的 pickTime 字段,在计算负载的时候,第一个用到的就是它:
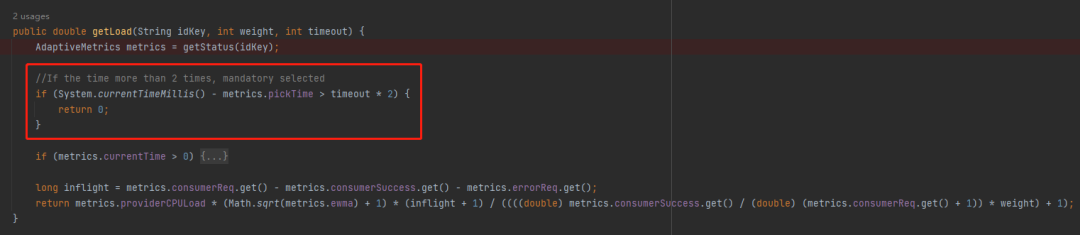
当前时间减去 pickTime 时间,如果差值超过超时时间的两倍,则直接选中它。
假设超时时间是 5s,那么当这个服务端距离上次被选中的时间超过 10s,则返回 0,既表示无负载。
那么这个 pickTime 是什么时候设置的呢?
就是在 doSelect 方法里面经过 selectByP2C 方法选择出一个服务端之后,在前面提到的 ConcurrentHashMap 中维护了 pickTime:
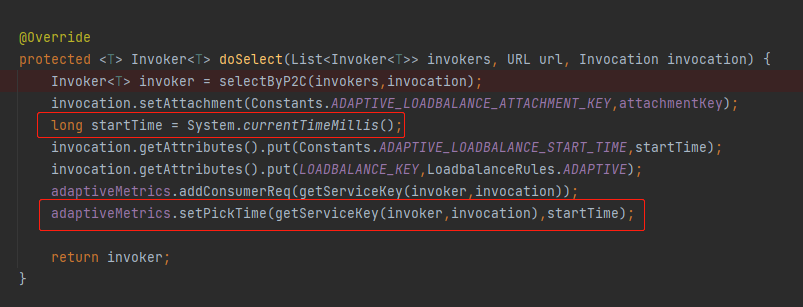
同时,在这里还在上下文中维护了一个 startTime,表示这个请求开始执行的时间:
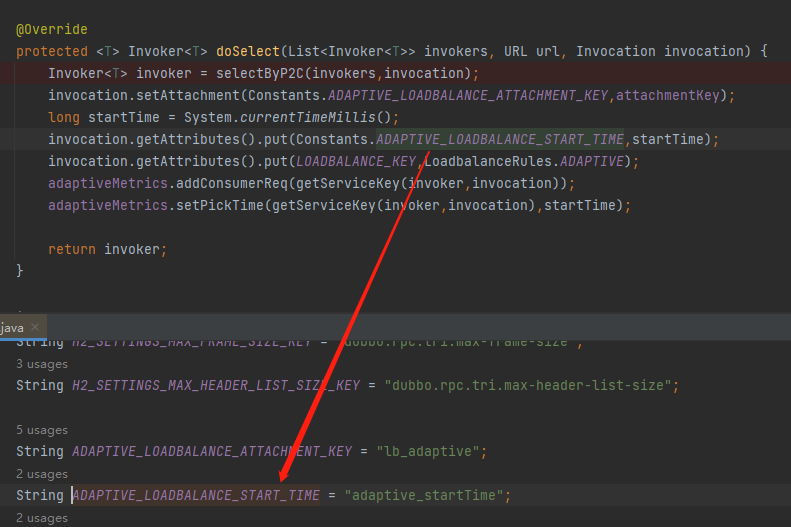
它是在什么时候用的呢?
这个时候就要把目光放到 AdaptiveLoadBalanceFilter 这个类上了:
org.apache.dubbo.rpc.filter.AdaptiveLoadBalanceFilter#onResponse
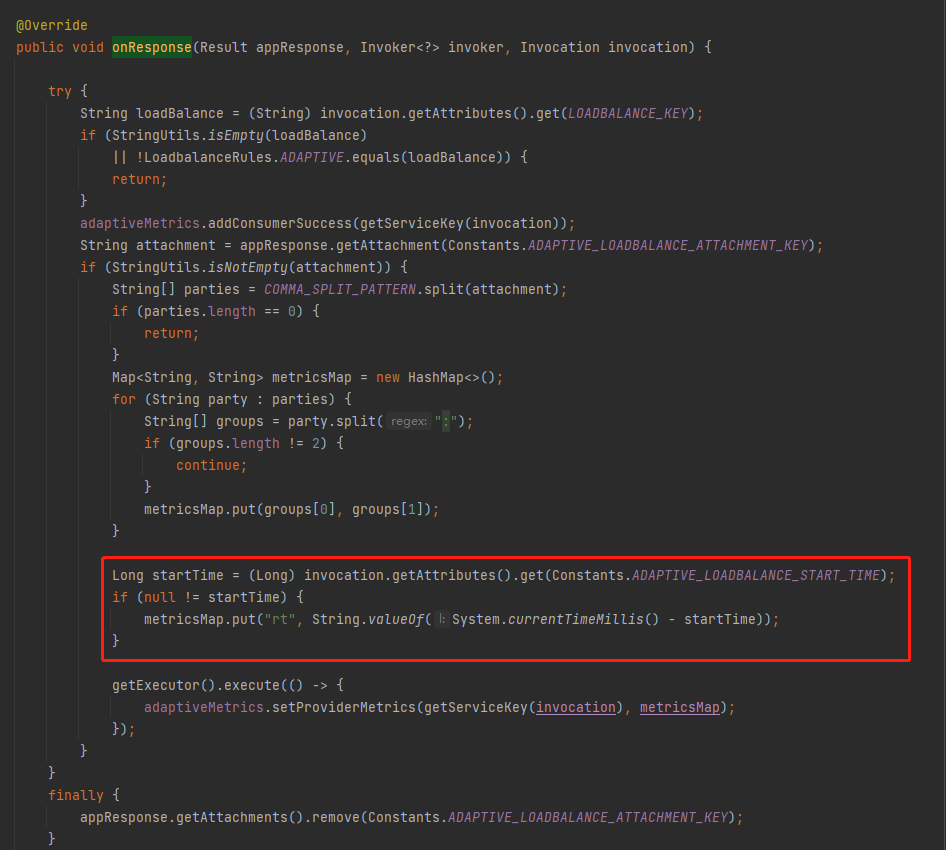
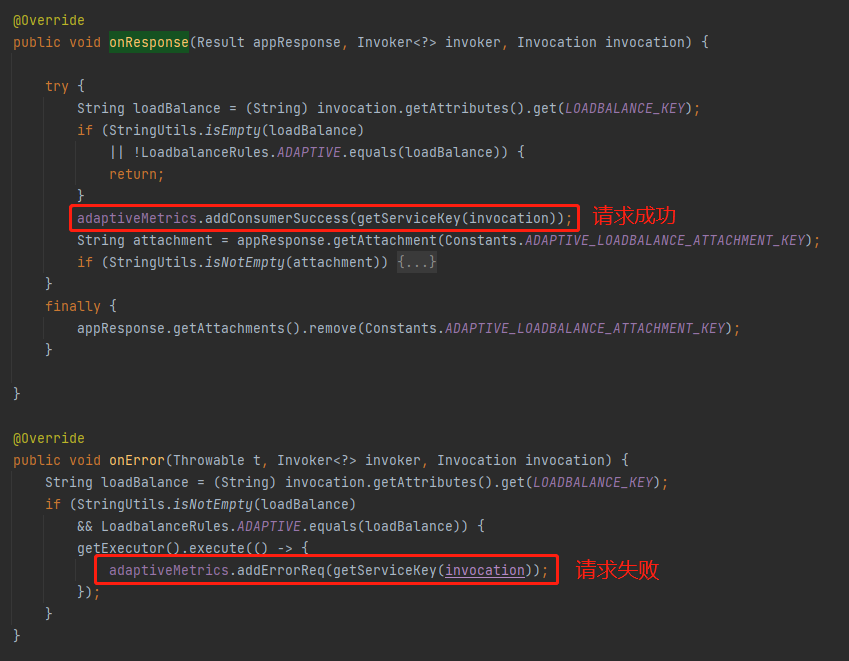
在 AdaptiveLoadBalanceFilter 里面的 onResponse 方法里面,当收到服务端的响应之后,在这里取出了 startTime 用来计算 rt 值。
同时在这里还维护了 AdaptiveMetrics 的 consumerSuccess(请求成功)、errorReq(请求失败)这两个属性:
然后,我们还可以看到有这样的一部分代码:
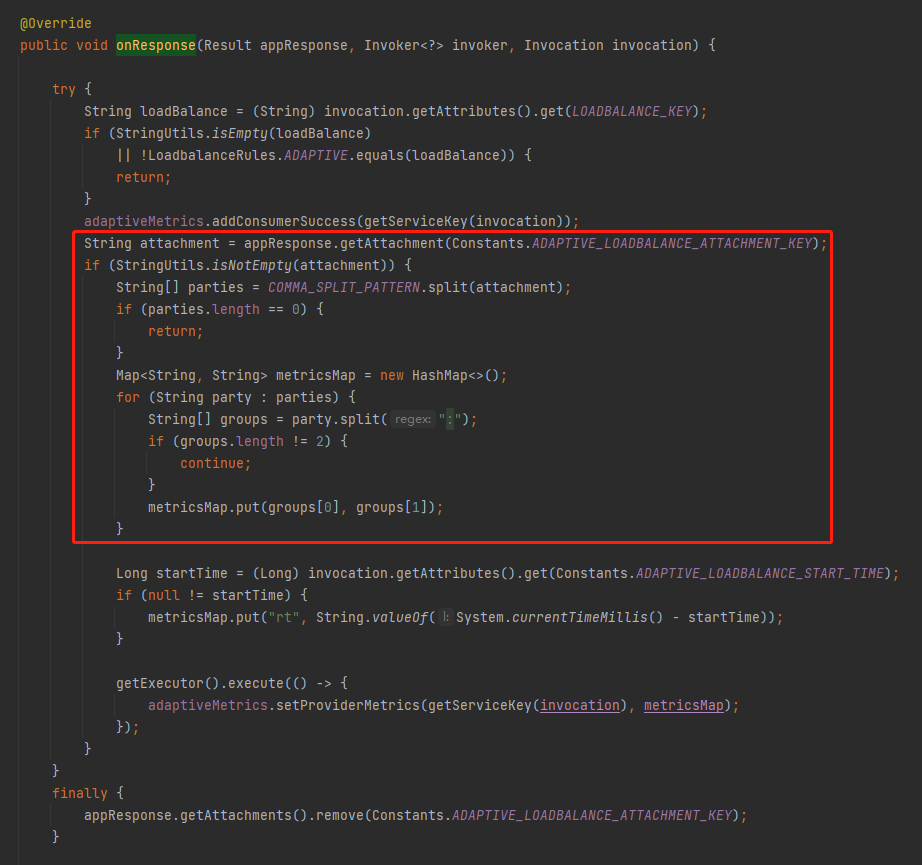
这部分代码是在对 ADAPTIVE_LOADBALANCE_ATTACHMENT_KEY 这个字段进行处理。
那么这是个啥玩意呢?
我也不知道,但是我知道它也是在 AdaptiveLoadBalance 的 doSelect 方法里面进行了一次维护:
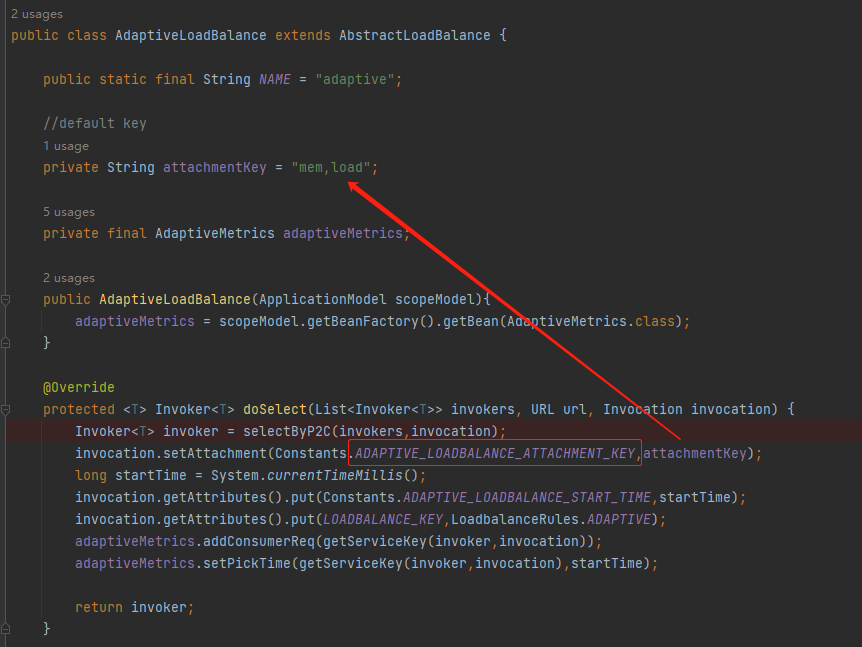
塞进去的值是:
private String attachmentKey = "mem,load";
看样子是要对内存和负载这两个维度进行统计。
首先,我问你,统计是站在谁的维度统计?
是不是要统计服务端的 mem 和 load?
所以,这里的含义是客户端告诉服务端:我这边需要 mem,load 这两个维度,你一会给我送回来。
那么服务端是怎么感知到的呢?
那我们就要把目光切换到 ProfilerServerFilter 这个 Filter 了:
org.apache.dubbo.rpc.filter.ProfilerServerFilter#onResponse
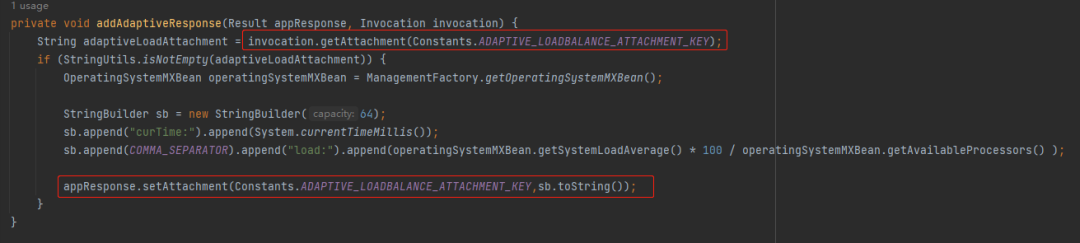
在这里我们可以看到,它从上下文中取出了 ADAPTIVE_LOADBALANCE_ATTACHMENT_KEY 变量,判断是否为空。
如果不为空则搞点事情,然后再重新给这个变量赋值。
那么问题就来了:这个地方并没有对所谓的 mem,load 进行任何处理,只是进行了非空判断,然后就自己 new 了一个 StringBuilder,拼接了 curTime 和 load 属性。
和 mem 没有任何关系?
是的,没有任何关系。
甚至和 load 都没有任何关系,只要 ADAPTIVE_LOADBALANCE_ATTACHMENT_KEY 不是空就行。
但是你不能说这是 BUG,这算是个 features 吧。
好,经过前面的分析,我们回到这个地方:
org.apache.dubbo.rpc.filter.AdaptiveLoadBalanceFilter#onResponse
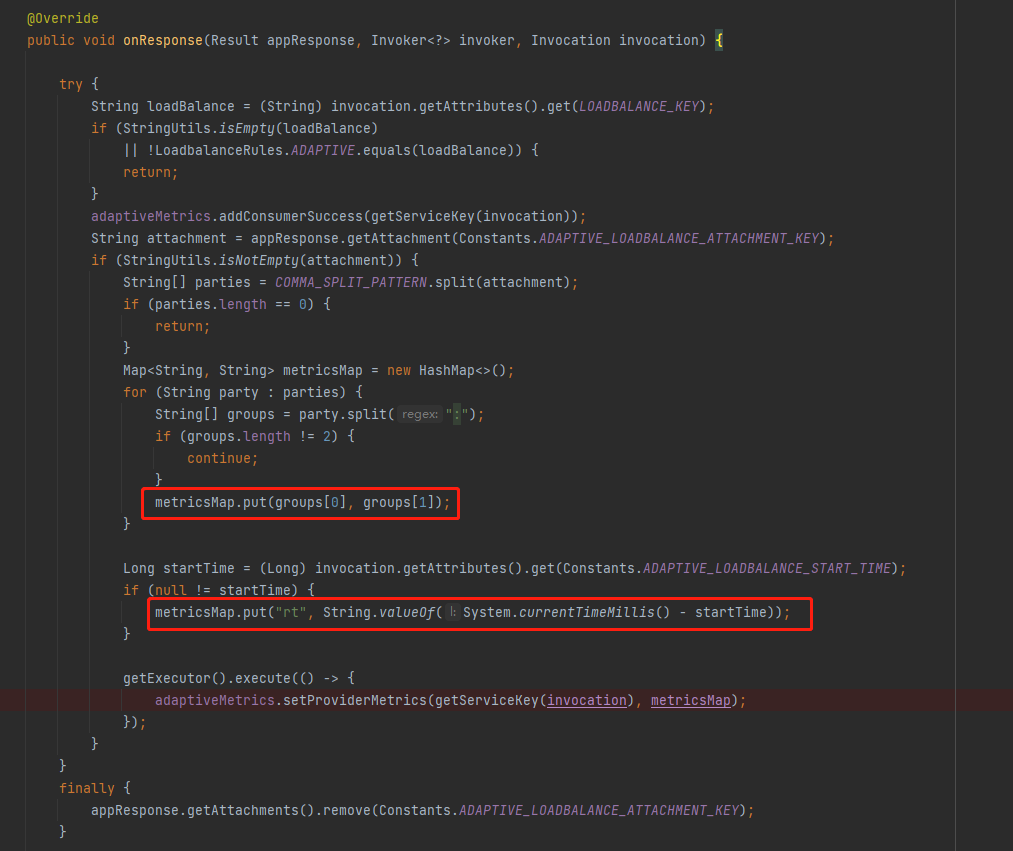
来,你告诉我,这个 metricsMap 里面装得是什么?
是不是只有 curTime、load、rt 这三个属性。
巧了,在 AdaptiveMetrics 的 setProviderMetrics 方法中,也只是用(写)到(死)了这三个值,用于给其他字段赋值:
org.apache.dubbo.rpc.AdaptiveMetrics#setProviderMetrics
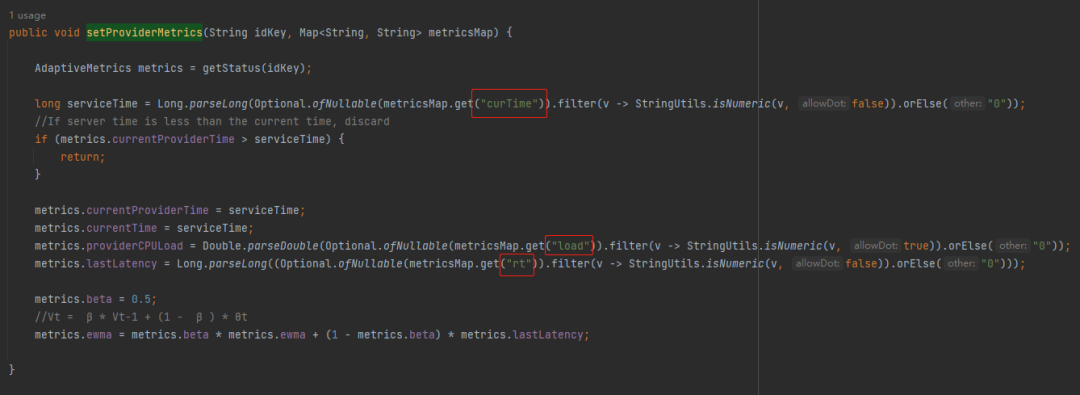
然后你注意看最后两行:
Vt = β * Vt-1 + (1 - β ) * θt
这是什么东西?
公式?我当然知道这是一个公式了。
我是问你这是一个什么公式?
第一次看到的时候我也是懵的,我也不知道,所以我查了一下,这是指数加权平均(exponentially weighted moving average),简称 EWMA,可以用来估计变量的局部均值,使得变量的更新与一段时间内的历史取值有关。

我试图去理解它,我也大概知道它是什么东西,但是你让我给你说出来,抱歉,超纲了。

好,最后回到计算 load 值的这个地方:
org.apache.dubbo.rpc.AdaptiveMetrics#getLoad
最后一行代码是这样的:
return metrics.providerCPULoad * (Math.sqrt(metrics.ewma) + 1) * (inflight + 1) / ((((double) metrics.consumerSuccess.get() / (double) (metrics.consumerReq.get() + 1)) * weight) + 1);
虽然一眼望去眼睛疼,但是我还是给你解释一下每个变量的含义:
-
providerCPULoad:是在 ProfilerServerFilter 的 onResponse 方法中经过计算得到的 cpu load。 -
ewma:是在 setProviderMetrics 方法里面维护的,其中 lastLatency 是在 ProfilerServerFilter 的 onResponse 方法中经过计算得到的 rt 值。 -
inflight:是当前服务提供方正在处理中的请求个数。 -
consumerSuccess:是在每次调用成功后在 AdaptiveLoadBalanceFilter 的 onResponse 方法中维护的值。 -
consumerReq:是总的调用次数。 -
weight:是服务提供方配置的权重。
以上这些变量带入到上面的公式中,就能获取到一个 load 值。
每个服务提供方经过上面的计算都会得到一个 load 值,其值越低代表越其负载越低。请求就应该发到负载低的机器上去。
因为这个 load 值,是实时计算出来的,反应的是当前服务器的处理能力。
而负载均衡策略在选择的时候,通过 load 值来决策是否应该选中这个服务提供方。
所以,这就是自适应负载均衡。
有的同学就会问了:既然可以实时计算 load 值,那么为什么不把所有的服务提供者的 load 都计算出来,然后选择最小的呢?
很简单,因为随机选择两个出来比较对应的时间是可控的,在常数时间内。但是如果你要把所有的服务提供者都计算一遍,那么耗时就和服务提供者的数量成正比了。
P2C,稳当的,放心。
自适应限流
前面聊了自适应负载均衡,但是还在站在服务调用方的角度来说的。
服务调用方来决定本次由哪个服务提供方来执行这次请求。
那么问题就来了:你服务调用方凭什么说啥就是啥?我服务提供方不服气。
假设现在所有的服务提供方的 load 值都很高了。我 P2C 出来两个,一个负载是 100,一个负载是 99。
按理来说,这个时候不应该把请求再给到服务方了。但是调用方可不管这些事情,一个劲的给就行了,边给边说:成长,一定是伴随着痛苦的...

所以,出于保护自己的原则,服务端应该有权在自己快 hold 不住的时候,拒绝调用端发来的请求。
但是到底应该在什么时候去拒绝请求呢?
这个不好说,应该是一个随着服务能力变化而变化的一个东西。
基于此,Dubbo 也提出了自适应限流的措施:
https://cn.dubbo.apache.org/zh-cn/overview/reference/proposals/heuristic-flow-control/#%E8%87%AA%E9%80%82%E5%BA%94%E9%99%90%E6%B5%81
从理论上讲,服务端机器的处理能力是存在上限的,对于一台服务端机器,当短时间内出现大量的请求调用时,会导致处理不及时的请求积压,使机器过载。在这种情况下可能导致两个问题:
-
由于请求积压,最终所有的请求都必须等待较长时间才能被处理,从而使整个服务瘫痪。 -
服务端机器长时间的过载可能有宕机的风险。


这玩意就更复杂了,我看了一下对应的 pr,目前还处于 open 状态:
https://github.com/apache/dubbo/pull/10642
看得我脑壳疼,在这里指个路,有兴趣的可以自己去研究一下。
另外,可以结合着这个赛题看。
https://tianchi.aliyun.com/competition/entrance/531923/introduction

能看明白更好,看不明白的话,学到一个看起来很牛逼的词也不错的:柔性集群调度。
荒腔走板

前几天不是发了《啥,你问我程序员的悲哀是什么?》这篇文章,说电脑扯拐了嘛,老是蓝屏。
刚好赶上 618 我也搞了一个固态硬盘,升级一下配置。不得不说,买之前我知道现在固态硬盘应该比较便宜,没想到这么便宜。1T 的内存,只要 300 多元,确实香。
原计划是拿到固态硬盘之后,趁着端午这几天顺便重装一下系统,彻底解决一下蓝屏这个问题。
但是固态硬盘在端午前一天就到了,我就先给装上了。
装的过程中,我想着,反正也已经把机箱拆开了,那就随便清个灰吧。
清灰的过程中,我想着,反正都在清灰了,那就把内存条也拔下来,用橡皮擦一擦吧。
结果...
蓝屏的问题就解决了。
我本来已经做好重装系统,然后重新安装各个软件的心理准备了。
这玩意,你找谁说理去。
我只能说计算机的尽头,是清灰。

