
堆内存OOM泄露-mat工具分析实践原创
一、背景
线上程序在运行几天后,服务无法访问。查看日志,发现程序出现OutOfMemory 异常。重启程序后,执行 ps -ef | grep java 命令,查找当前Linux系统中的java进程程序。
- ps -ef | grep java 命令含义
- ps命令将某个进程显示出来,grep是正则查找命令,中间的|是管道命令,是指ps命令与grep同时执行
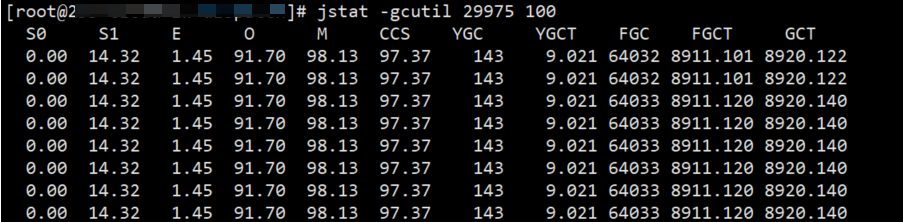
找出对应的Java进程后,执行 jstat -gcutil {pid} 100,查看jvm运行时的内存信息、垃圾回收情况。
- jstat -gcutil {pid} 100 命令含义
- jstat是JDK自带的一个轻量级资源性能监控小工具,-gcutil表示的是各个区间的容量使用百分比,也可以用-gc表示实际的值,pid就是进程id
1.1 分析
S0 survivor0使用百分比-幸存区0,用于保证新对象能始终在eden区出生,倒腾GC后的Eden区的数据;
S1 survivor1使用百分比-幸存区1;
E Eden区使用百分比,满了会触发younggc;
O 老年代使用百分比,满了会触发oldgc;
M 元数据区使用百分比,注意一个jvm参数,MaxMetaspaceSize,会导致元空间溢出;
CCS 压缩使用百分比;
YGC 年轻代垃圾回收次数,younggc回收的是整个Eden区域的内存;
YGCT 年轻代垃圾回收消耗时间;
FGC Full GC垃圾回收次数,清理整个heap区,包括Yong区和old区;
FGCT Full GC垃圾回收消耗时间;
GCT 垃圾回收消耗总时间;
分析生产环境jvm运行时数据区发现M元空间占比98.13%,但程序未配置MaxMetaspaceSize去限制元空间的大小,所以重点是FGC次数过多,导致系统卡顿,甚至引发OOM。
1.2 OOM种类
- 堆内存溢出:OutofMemoryError:Java heap space
- 元空间溢出:OutofMemoryError:Metaspace
- 栈溢出:StackOverflowError
本次 Full GC 的情况是堆内存的溢出。堆内存溢出由以下几种情况导致:一、堆内存配置不足导致;二、程序中存在死循环;三、程序中出现大对象,其出生就在老年代,比如大List、大Set、Map等集合对象。
二、分析步骤
2.1 准备分析工具
| 工具 | 描述 |
|---|---|
| mat | Memory Analyzer Tool |
| jmap命令 | 获取生产上的dump文件 |
2.2 jmap命令
生产环境,获取demp文件命令:
jmap -dump:format=b,file=/home/admin/logs/{fileName}.hprof {pid}
jmap能够打印给定Java进程、核心文件或远程DEBUG服务器的共享对象内存映射或堆内存的详细信息,导出 pid 进程的java程序的整个JVM信息,放在服务器 /home/admin/logs/ 目录下,文件名字可以随意取,文件后缀.hprof。
三、MAT工具使用
3.0 安装
Memory Analyzer Tool 工具安装,在网上已有很多教程。且也有不少讲解如何使用的文章,但均讲解的过于深奥,不能直白的找到溢出问题点。
3.1 No.1 载入dump文件
依次点击 File -> Open File -> 找到下载的dump文件
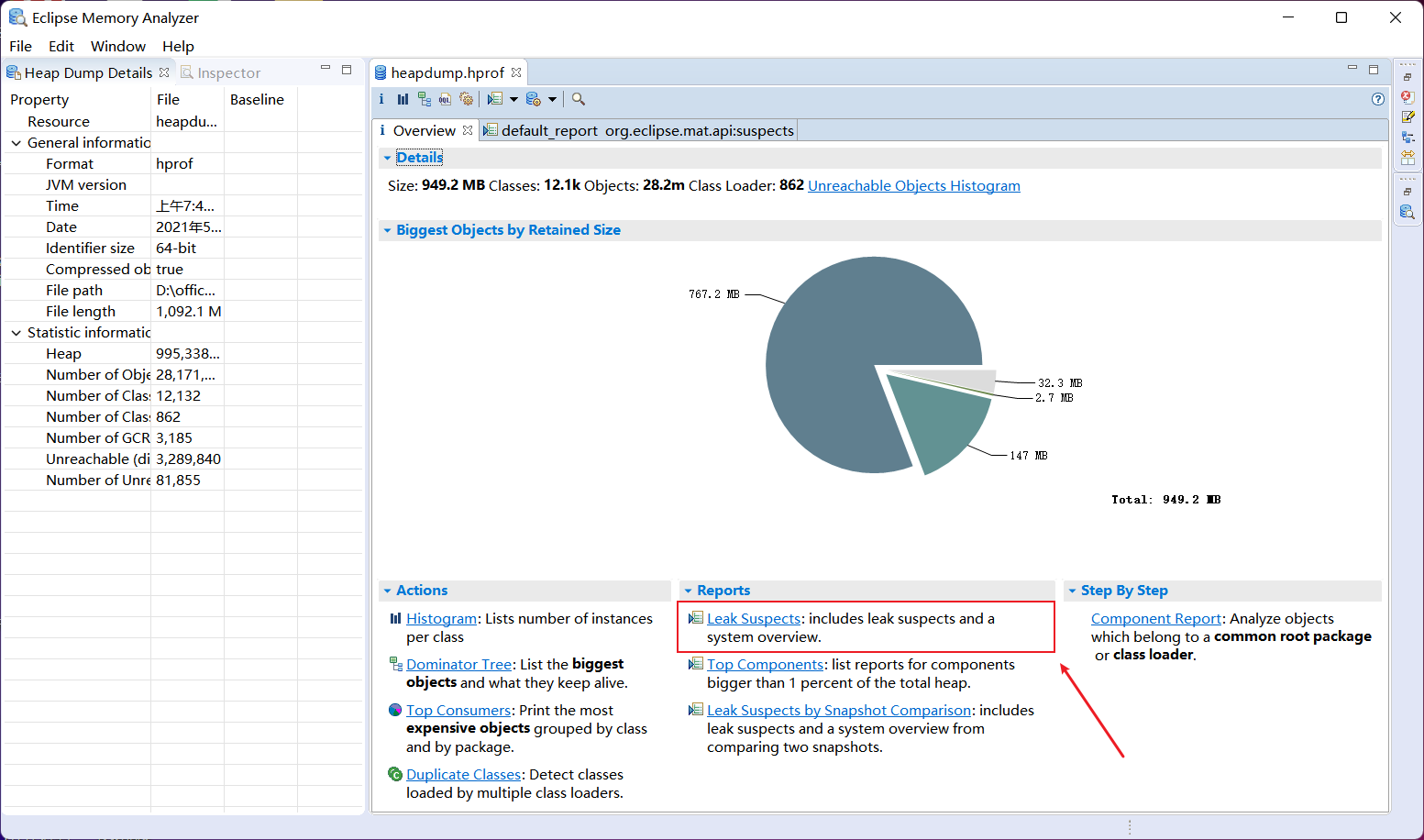
3.2 No.2 Leak Suspects
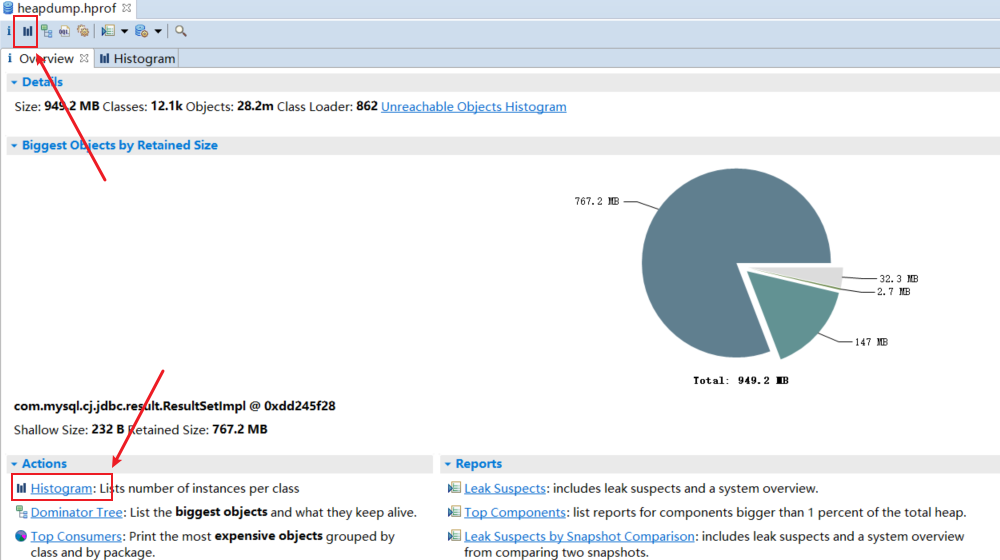
直接点击 Leak Suspects :泄漏疑点,包括泄漏嫌疑和系统概述。优先使用mat分析泄漏疑点。
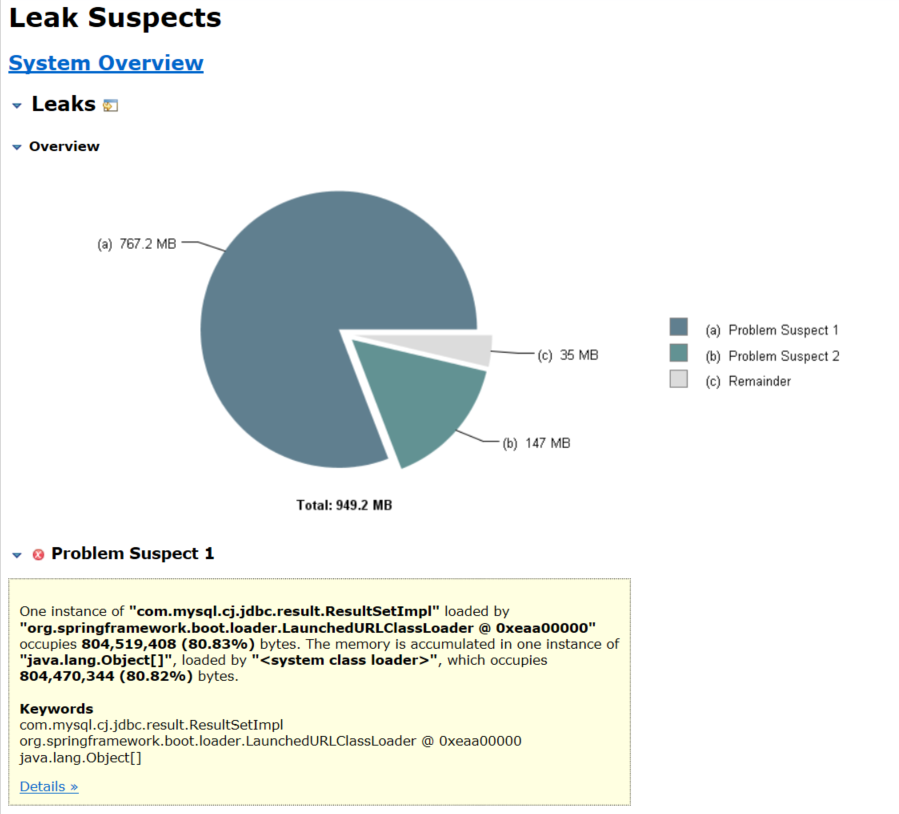
3.3 No.3 Leak Suspects
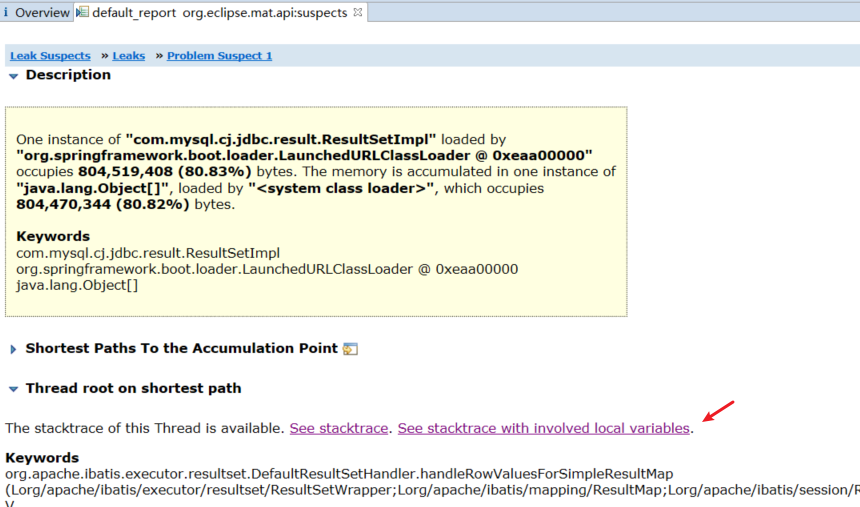
下图呈现出(a)问题怀疑1;(b)问题怀疑2;(c)剩余部分;可以看出问题怀疑1,占用767.2MB,占全部80%左右;同时下面文字上描述:com.mysql.cj.jdbc.result. ResultSetImpl 的实例,内存累计占用804,519,408(80.83%)字节。选择Details,进入详情。
PS:这里凭借经验,jdbc的result实例占用大量内存,出现了数据库查询集合对象过大。
四、多种分析方法
4.1 方法1.线程栈
进入 Problem Suspect 1 的 Details 后,首先看线程栈信息,Thread Stack ,这个就和java程序日志报错类似,通过打印线程栈报错信息,往往能直接命中泄露点。在 Thread Details 栏目展开就能看到。
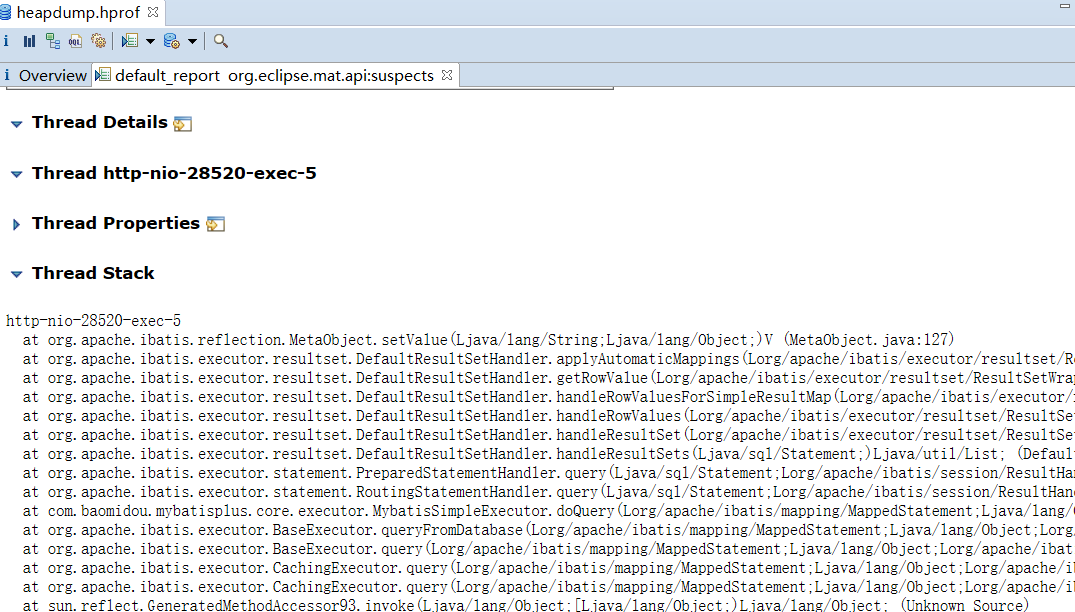
Thread Stack 大多数是apache容器、servlet、spring框架的报错信息(实际上是线程的调用链顺序),要找到项目的关键字和关键方法。如下图,直接定位到:
com.station.openapi.domain.repository.SellTicketRepository.queryTblZwSellTicket
SellTicketRepository 类的 queryTblZwSellTicket 方法 81行。
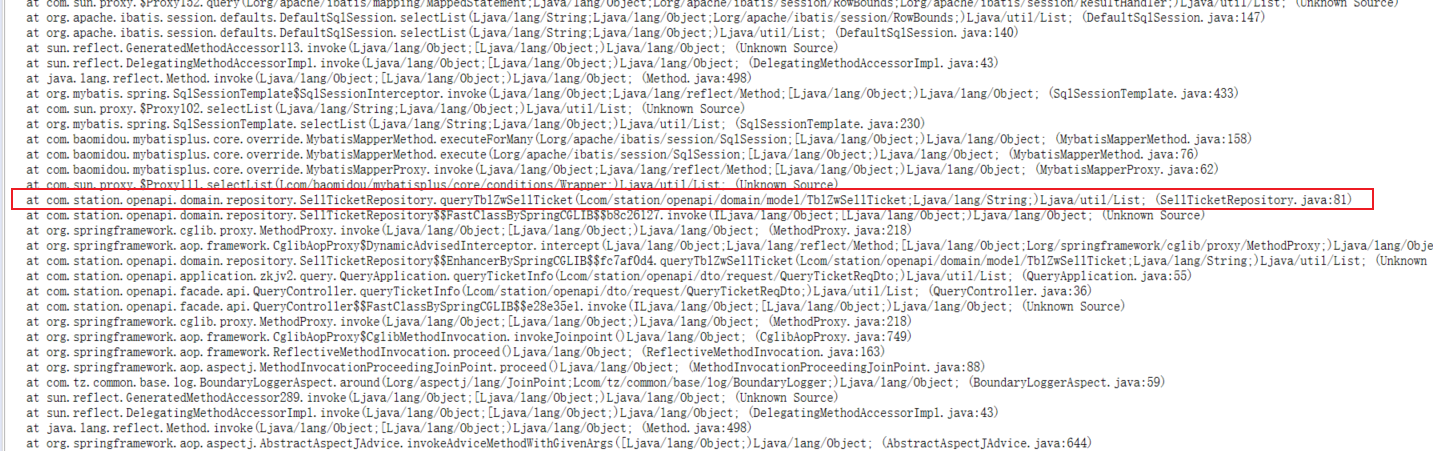
4.2 方法2.包含局部变量的堆栈跟踪
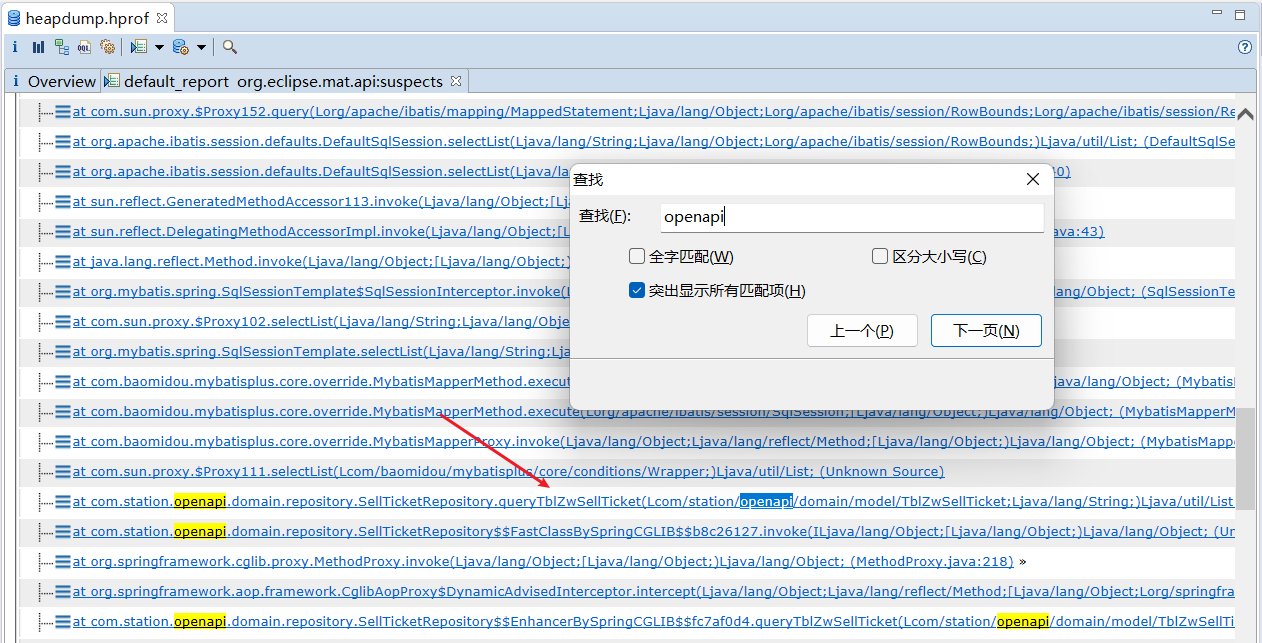
同样在 Problem Suspect 1 的 Details 里面,还有 See stacktrace with involved local variables (查看包含局部变量的堆栈跟踪),点击进去之后直接搜索项目的关键字,避免apache容器、servlet、spring框架的影响。
PS:项目关键字 openapi 立刻找到 SellTicketRepository 类的 queryTblZwSellTicket 方法。
4.3 方法3.histogram
如果 Leak Suspects 无法查到项目溢出信息,则直接使用 histogram 柱状图,查看每个类型的实例的数量。其默认是按照浅堆从大到小顺序排列的,shallow heap 浅堆、Retained heap 深堆。
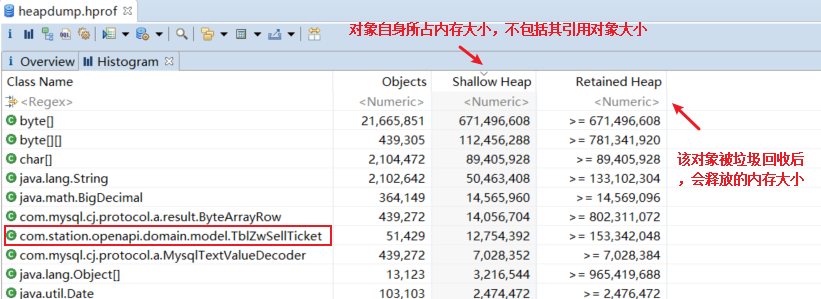
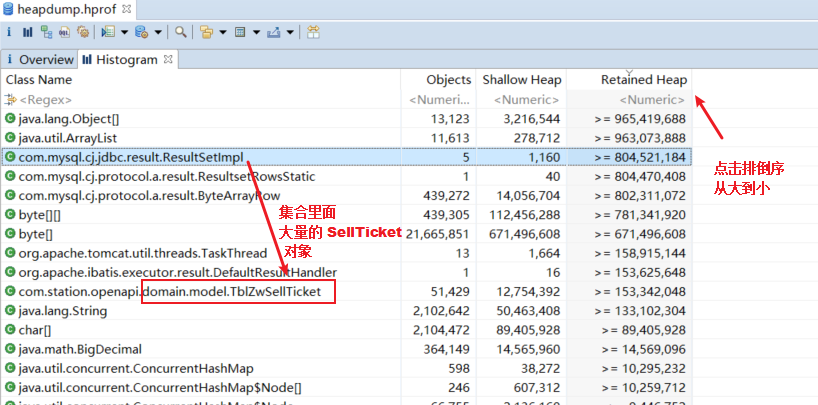
对 Retained heap 深堆 进行倒序,从大到小的排列。前面的 Object[] 和 ArrayList 是表示内存中的集合对象个数,那么集合里面是什么对象非常多且大呢,如图正是项目中的 TblZwSellTicket 对象。
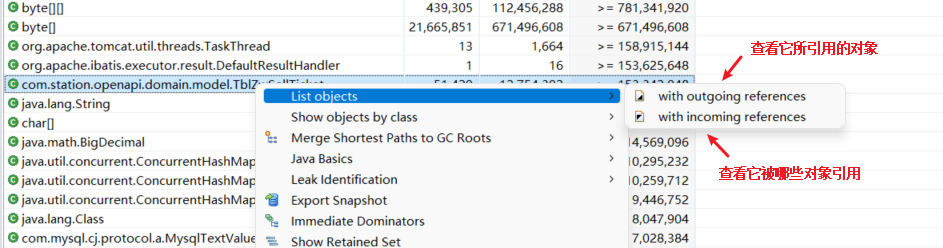
4.4 对象引用与去除弱连接、软连接
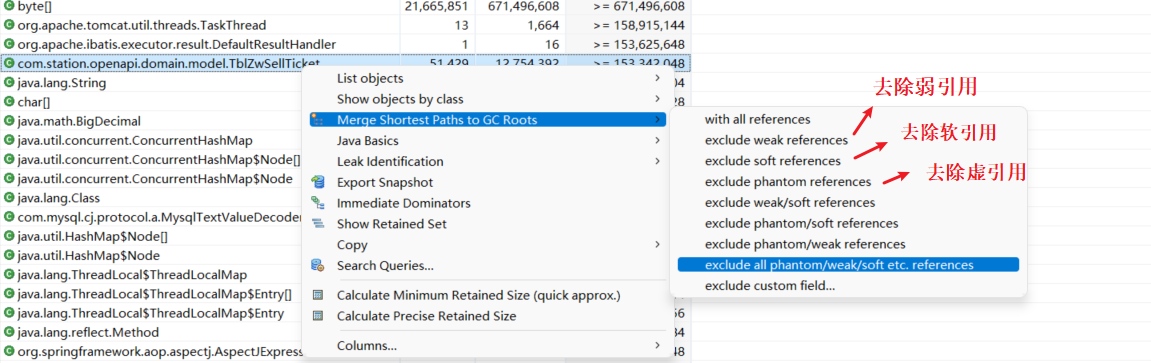
五、代码问题定位
( at com.station.openapi.domain.repository.SellTicketRepository.queryTblZwSellTicket(Lcom/station/openapi/domain/model/TblZwSellTicket;Ljava/lang/String;)Ljava/util/List; (SellTicketRepository.java:81)
)
代码存在明显问题,其持久层使用的是 mybatis plus,当所有的 if 条件都没有进入时,则会进行全表扫描,放入 List<TblZwSellTicket> 集合内,该表数据量接近百万级,且调用频次较高。这样的对象会直接进入 old space 老年代,很快触发 full gc。
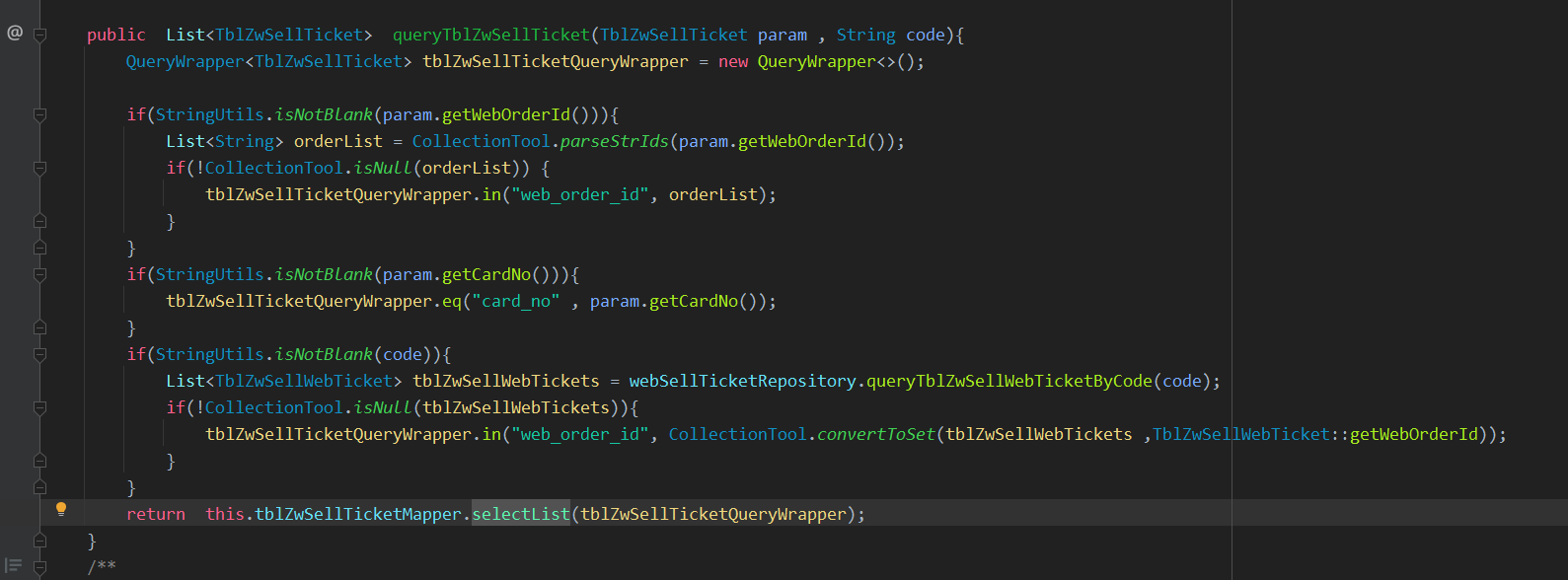
5.1 部分代码优化思路
-
- 大容量数据表的查询,要做好条件过滤。(尽量不出现全表查询)
-
- 增加缓存机制,对入参相同的查询直接从缓存内返回,这样不会频繁在堆中生成重复对象。使入参相同可以采用md5值。
-
- 对list转换、set转换要进行容量限制。
-
- 对临时私有变量使用完成后,在finally中设置为null。


