
看完intern源码,和面试官battle,巨自信原创
哈喽,我是子牙。十余年技术生涯,一路披荆斩棘从技术小白到技术总监到JVM专家到创业。技术栈如汇编、C语言、C++、Windows内核、Linux内核。特别喜欢研究虚拟机底层实现,对JVM有深入研究。分享的文章偏硬核,很硬的那种。
手撸过JVM、内存池、垃圾回收算法、synchronized、线程池、NIO、三色标记算法…
这篇文章是专栏字符串常量池的第三篇。如果前两篇你还没看,墙裂都建议你回去看一下,再来看本篇 传送门
本篇文章就从上篇文章留的问题切入,分享:
-
什么情况字符串会写入常量池
-
什么情况字符串不会写入常量池
-
intern底层是如何实现的
-
字符串过多导致OOM如何解决
上篇留的问题是这段代码为什么是这个结果

简单分析一下
一、s2与s3不是同一个对象,说明在创建s3这个对象时,字符串常量池StringTable中是没有[子牙真帅]这个字符串的。引出的问题就是什么情况字符串会写入?什么情况不会?
二、执行s3.intern,如果接收返回结果,则s3与s4指向的是同一个对象,如果不接收,还是不相等,这又是为什么呢?
1、写不写常量池
一般我们用Java代码创建字符串,常用方式有三
String s1 = "ziya";
String s2 = new String("ziya");
String s3 = "zi" + new String("ya");
那不常用的呢?反射方式创建、字节码增强包创建。但是我想,正常写代码,没人这么不正常吧。
如果你的Java代码编译生成的字节码指令中有【ldc】,就会写入常量池,否则就不会。细节上篇文章已经讲了,不赘述。
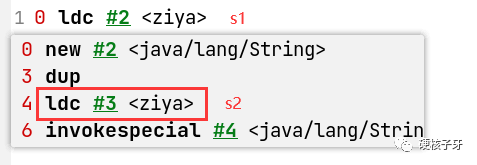
经过前面的简单分析我们知道:字符串拼接是不会写入常量池的,我们来细究一下
首先我们来看下字符串拼接,经编译器编译后生成的字节码长啥样子
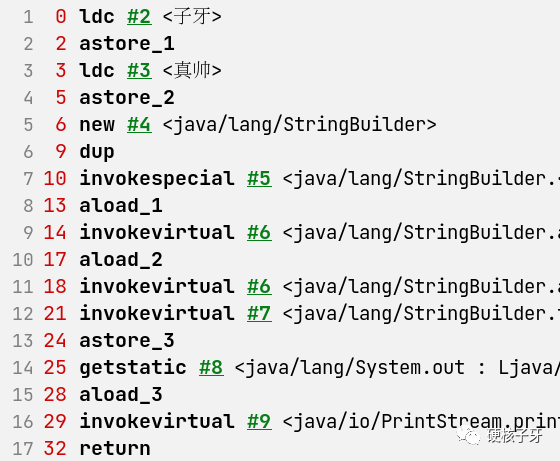
是不是没想到,字符串拼接的底层竟然是通过StringBuild类实现的,通过append进行拼接,调用toString转成字符串。那毫无疑问,字符串拼接不写入常量池的秘密,不是在append中,就是在toString中。
追踪append的调用链,你最终会找到这句代码
public void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin) {
……
System.arraycopy(this.value, srcBegin, dst, dstBegin, srcEnd - srcBegin);
……
}
StringBuild中维护着一个能够自动扩容的char数组,append传入的字符串,都会被蜕去外壳,拿到真正的字符串内容,写入这个char数组。
arraycopy是个native方法,继续跟踪到Hotspot源码,发现也没有操作StringTable的代码。Hotspot源码我就不贴了,敢兴趣的可以自己去看。不会看吗?可以看我之前写的一篇文章《教你如何找到native方法对应的Hotspot源码》 传送门
再看看toString调用链,代码很简单,创建一个String对象,将StingBuild中char数组中的内容原封不动的copy过来
public String(char[] value, int offset, int count) {
……
this.value = Arrays.copyOfRange(value, offset, offset + count);
……
}
copyOfRange最终调用的也是arraycopy这个native方法
综上:你写的Java代码经编译器编译后生成的字节码指令中有【ldc】,就会写入常量池,字符串拼接不会写入常量池。
2、intern做了什么
JVM执行到指令【ldc】就会将字符串写入常量池,本质原因是这条调用链上会调用intern,那intern底层是如何实现的呢?我把相关代码贴出来,然后挨个剖析
先上第一段代码
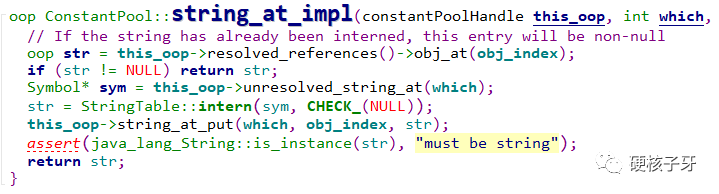
解释这个代码之前,先给大家看个图,不然讲了大家也听不懂。什么图呢?字符串到底是怎么存储的?与运行时常量池之间的关系是怎样的?
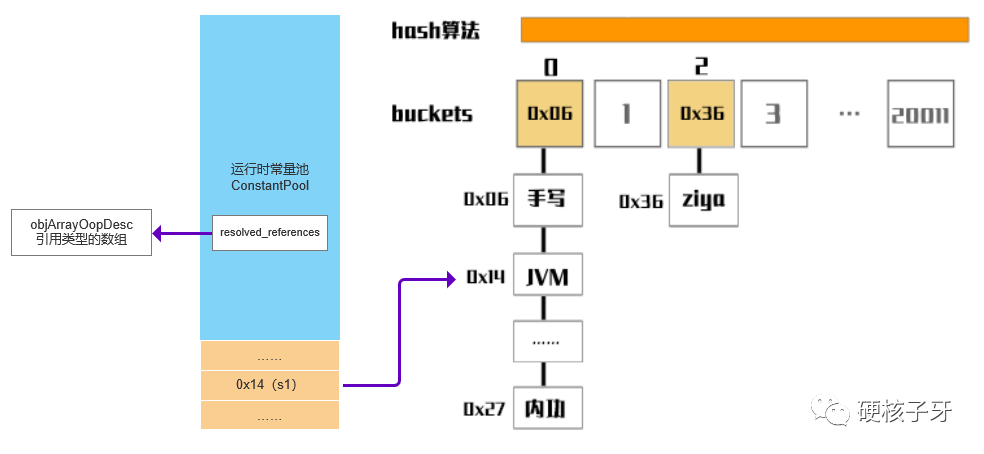
前面讲过,在link阶段,字符串会被封装成Symbol对象,存储到SymbolTable中,然后还要存储到运行时常量池中
运行时常量池是一个C++对象,如图所示:蓝色部分表示这个C++对象本身占用的内存,接在对象后面的部分是常量池项。比如index=1的位置是一个字符串,那这个位置存储的就是一个Symbol对象的内存地址
运行时常量池这个C++对象中有一个属性resolved_references,是一个数组结构。看这个属性的名字也能看得出来:解析过的引用类型。即如果这个字符串已经执行过了intern,由Symbol对象转成了String对象,就直接返回。如果还没有转成String对象,就调用intern,调用完intern还有件重要的事情,就是写入resolved_references。
这三段内容看到,上面那段代码应该不用我解释了吧。
接下来第二段代码

这段代码做的事情:从Symbol对象中拿出字符串内容,调用intern。这个方法代码有点长,保留核心逻辑

1、先去字符串常量池StringTable中去找有没有这个字符串,如果有,直接返回,如果没有,往下走
2、第16行代码,基于字符串内容创建Java的String对象。这个方法等下展开讲,讲完第二篇的内容你就恍然大悟了
3、将创建的String对象写入StringTable。这个做的好处:一、下次通用的字符串不需要再次执行创建,提升了程序执行效率;二、由于不需要重复创建,节省了内存,有点缓存的感觉
接下来看下16行代码的细节

189行:创建一个Java的String对象,这里是Hotspot源码,所以创建的是一个oop对象,转成Handle。Hotspot源码中,操作一个对象,有时候是直接操作oop,有时候会转成Handle对象。其实因为做了C++级别的操作符重载,两种对象的写代码风格风格基本差不多
190行:拿到String对象中存储字符串的容器char数组,对应的Hotspot中的C++对象就是typeArrayOop
后面的for循环就是一个字节一个字节的赋值。这块为啥不调用类似memcopy直接整块内存拷贝呢?想不通!
到这里就把intern底层细节讲明白了
3、字符串导致OOM
这个问题也是小伙伴问我问的比较多的。看到这里你应该清楚这背后的原因及如何解决了吧
背后的原因是大概率你的代码中的字符串都是拼接生成的,不会写入常量池,所以每次都是不断的创建,消耗内存空间
解决办法就是在拼接字符串的代码后面手动调用intern触发写入常量池StringTable。后面出现的G1的字符串去重,本质就是干这事,就是你不用手动调用intern,在GC的时候,G1给你做了。
但是就算存在字符串去重,因为拼接底层实现是通过copy实现的,不会写入常量池,所以字符串去重只是缓解了这个问题,并没有根本解决这个问题。如果从根本上解决,拼接的底层实现需要改!jdk8这块还是之前的代码,后面的不晓得改了没,抽空看下
你好,我是子牙。十余年技术生涯,一路披荆斩棘从小白到技术总监到大厂中间件到创业。技术栈如汇编、C语言、C++、Windows内核、Linux内核及特别喜欢研究虚拟机底层实现,对JVM有深入研究。关注《硬核子牙》。



