JVM专家聊字符串常量池(一)原创
哈喽,我是子牙。十余年技术生涯,一路披荆斩棘从技术小白到技术总监到JVM专家到创业。技术栈如汇编、C语言、C++、Windows内核、Linux内核。特别喜欢研究虚拟机底层实现,对JVM有深入研究。分享的文章偏硬核,很硬的那种。
手撸过JVM、内存池、垃圾回收算法、synchronized、线程池、NIO、三色标记算法…
今天准备跟大家聊啥呢?字符串常量池,即Java代码中的字符串在JVM中到底是如何存储的。

分析问题的时候,我们需要把一道高度抽象的问题提炼成一道追寻本质的问题。讲道理的时候,一招制敌的秘诀是:以不变应万变。
这两段代码就是你玩透Java字符串的根本,围棋术语叫“棋眼”,就是说Java世界字符串圈,一切一切的变化,都是从这两段代码衍生出来的。
01
问题分析
研究事物,有两个角度:研究者角度、设计者角度。研究者角度就是说我们从学习的角度出发,去追寻事物的轨迹,沿着轨迹往下深挖,讲人话就是读源码去理解设计者的想法。设计者角度就是说我们假想我们要做一件事情,我们会怎么去做,前面有哪些选择,对每种选择进行利弊分析,最终做取舍。
相信大家很多时候都是从研究者的角度去研究问题,今天咱们换个思维,从设计者的角度去研究这个问题。
浓缩成一个本质的问题就是:如果我们来写一个JVM,我们如何处理字符串。这个问题很简单了,使用散列表,即hashtable。
这里需要注意一下,Java世界存在两个hashtable类型结构:Java的HashTable及HashMap,纯Java实现的;Hotspot的hashtable,纯C++实现的。我们今天探讨的是Hotspot源码中的hashtable。
很多小伙伴一看到C++,就心生恐惧…或者心想:这是我不花钱就能看的吗?这是这个水平的我能看的吗?我真的是太懂了…
额,别怕,今天木有任何源码!只有子牙学了许久AE绘制的独领**小动图,帮你准确快速精准拿捏。额,想看源码的也别灰心,下篇纯源码,满足你。只要你想看,我故意翻个车也不是不可以,留言回复:想看翻车
02
hashtable
为了保证文章的完整性,我准备把hashtable细讲下。如果你觉得这块你非常熟悉,同样建议看一遍,一定有收获
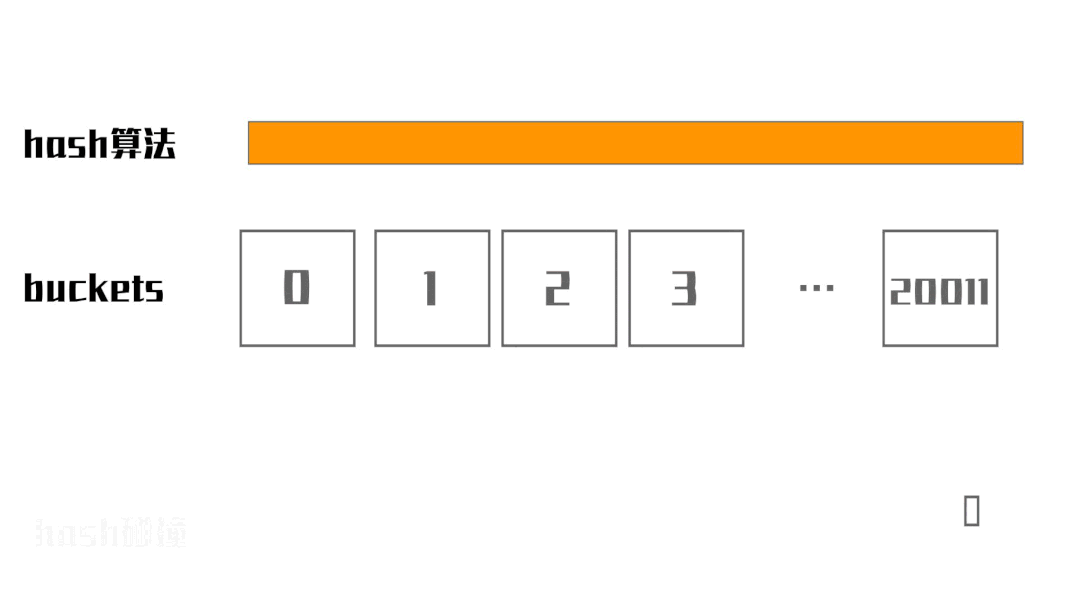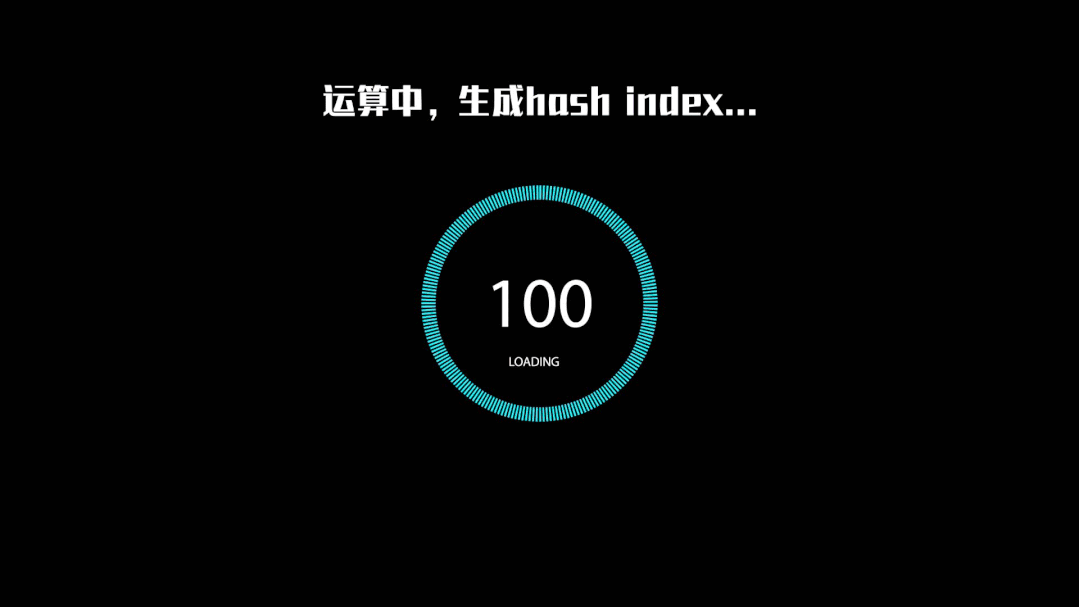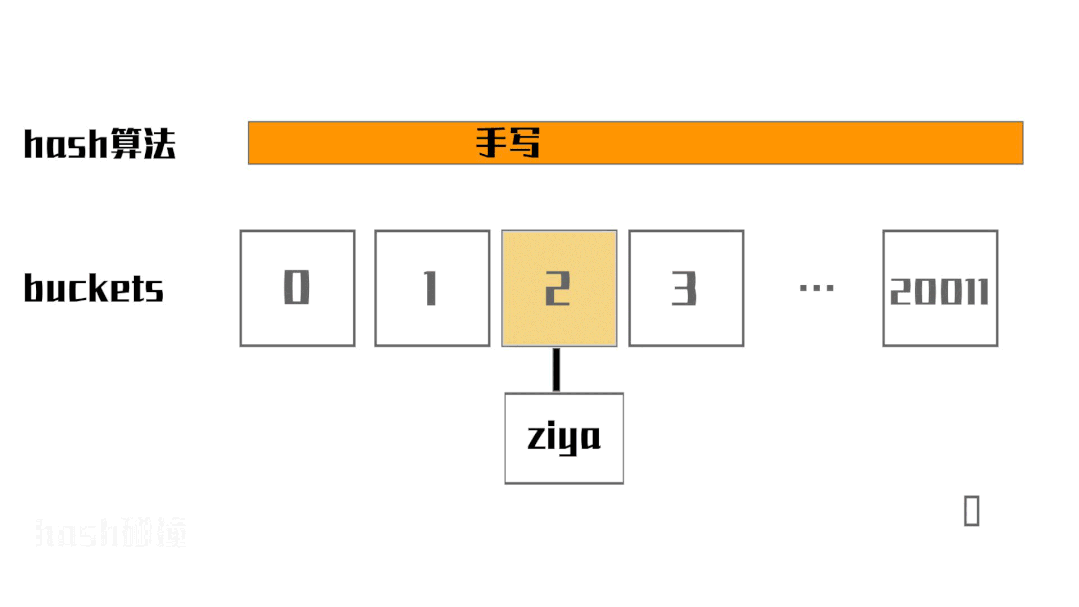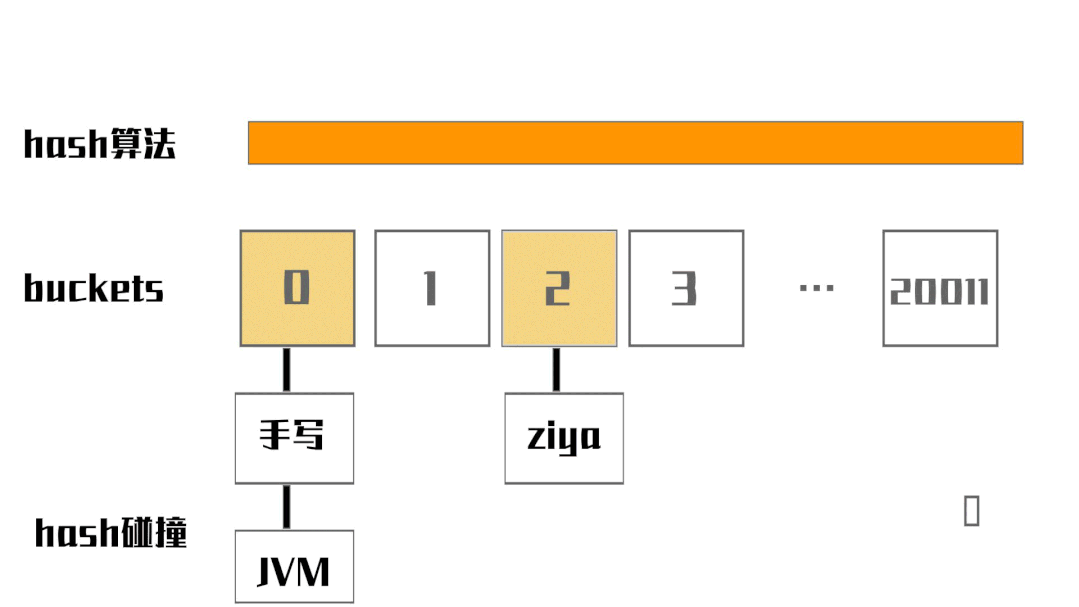
首先上个图,看hashtable是如何工作的,涉及到的名词、现象,等下细讲
说下hashtable的底层实现,主流两种方式:数组+单链表、数组+红黑树。你硬要说有第三种也行:数组+单链表+红黑树。你可能一下子很多问题冒出来了:为什么要这样实现?不同实现方法有什么区别?别急,都会说到。
先了解下数组+单链表是怎么玩的。我们这个图画的就是数组+单链表。
第一步:当字符串ziya到来,迎接它的是hash算法。hash算法又叫散列算法,实现思路有很多,这里不展开讲,感兴趣的小伙伴自行百度。达到的效果就是生成buckets index。假如字符串ziya经过hash算法运算得出buckets index等于2。
第二步:buckets的数据结构是数组。第一步生成的就是该数组的下标。这时候会将字符串ziya封装成一个链表节点Node,这里字符串ziya是index=2的第一个元素,就将字符串ziya封装成的链表节点Node作为链表头,将Node的内存地址存入index=2的位置。
这时候我们要思考一个问题:buckets是数组,写过C++代码的都知道,不指定数组长度是无法创建数组的。那指定多大呢?Hotspot源码是20011。为什么是20011?我也有这个疑问,但是我试图找了下答案,没找着,但是我确定这个数字应该是有特殊意义的。了解的小伙伴可以留言告知下。当然我也不会放弃追求真理!
接下来我们用发展的眼光看问题:如果存储的字符串经过hash算法得到的buckets index不重复,最多可以存储20011个字符串。如果超过20011个字符串呢?这时候肯定会出现一种情况:不同的字符串经过hash算法运算得到的buckets index是相同的,这种情况叫hash碰撞。
比如图中的字符串[手写]与字符串[JVM],它们经hash算法运算得到的buckets index都是0,这时候怎么存储呢?先把字符串[手写]封装成链表节点Node,因为是index=0的第一个节点,将该Node的内存地址写入index=0的位置。然后把字符串[JVM]封装成链表节点Node,插入链表尾部。
注意:链表的节点在内存中不是连续的!
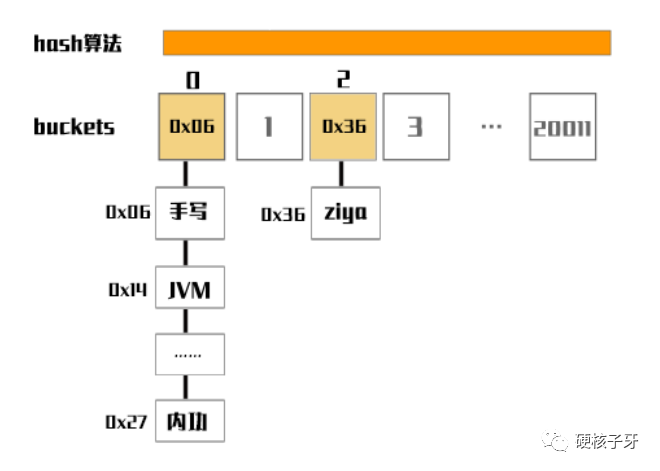
后面有字符串写入,就是重复这个动作了:字符串到来,经过hash算法运算得到buckets index,然后将字符串封装成链表节点Node。如果到来的字符串是该index的第一个元素,将节点的内存地址写入该index位置,如果不是第一个元素,插入到链表尾部。
03
一种特殊情况
先看图,再说话
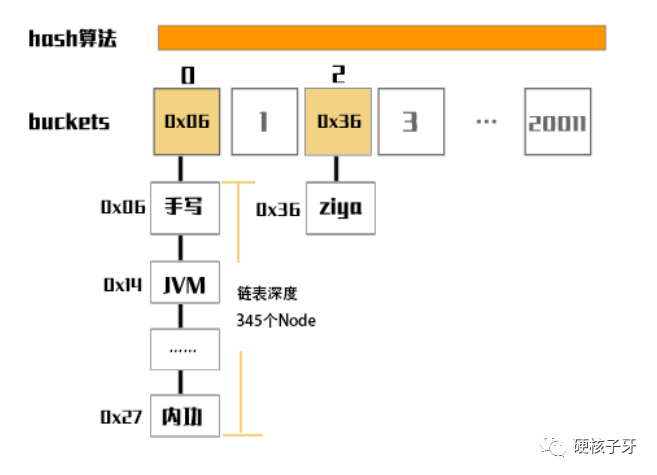
该图想表达的现象是buckets index=0对应的链表深度过深,达到了345,这样如果我们查找的字符串恰好是[内功],抛开其他运算,就光遍历链表都要345次。对于现在的高性能计算机来说,345次好像也不慢,但是性能随数据增长而出现性能下降,意味着总有一天会达到性能瓶颈,需要优化。
于是就出现了数组+红黑树结构,后面又发展出了数组+链表+红黑树结构。我解释下原因:大量数据的情况下,红黑树的查找性能比链表高。那为什么后面又会出现数组+链表+红黑树结构呢?注意看前提:大量数据的情况。当数据量比较少的时候,比如拿HashMap底层实现来说,这个阈值是8,即hash碰撞严重情况下,数据少于8,两者性能上差异不大,但是链表相对实现起来更容易、占用空间更少…
hash碰撞严重的情况,改变底层存储容器是一种思路,还有没有其他思路呢?有!改变hash算法,Hotspot源码就是这样干的。默认算法是java_lang_String::hash_code,触发rehash后使用的算法是AltHashing::murmur3_32。
Hotspot触发rehash的条件是:查找一个字符串超过100次。
04
串一串
JVM中与字符串相关的有两个表,一个是SymbolTable,一个是StringTable。我们通常说的字符串常量池是指StringTable。但是StringTable的运行与SymbolTable紧密相连。这篇文章讲到的内容,全部都是SymbolTable的底层原理。关于它俩之间的联系,本文篇幅已经够长了,放下篇文章讲。
SymbolTable底层是基于hashtable实现的,结构是数组+链表,当存储的数据足够多,遇到hash碰撞严重时,是通过切换hash算法实现的。默认算法是java_lang_String::hash_code,触发rehash后使用的算法是AltHashing::murmur3_32。
留个问题吧:切换hash算法不会马上生效,需要等到安全点,你觉得是为什么?欢迎留言讨论

题外话

你好,我是子牙。十余年技术生涯,一路披荆斩棘从小白到技术总监到大厂中间件到创业。技术栈如汇编、C语言、C++、Windows内核、Linux内核及特别喜欢研究虚拟机底层实现,对JVM有深入研究。分享的文章偏硬核,很硬的那种。不考虑交个朋友吗?关注硬核子牙: