
深度解析Seata AT 模式:性能优化与隔离保障的平衡之道原创
一、脏写和脏读
数据隔离性可从读和写两个维度来审视:
-
从写的视角来看,是不能有
脏写的,即不能让一个事务修改另外一个事务修改过但尚未提交的数据。 -
对于成熟的数据库产品来说,脏写这种情况是不允许发生的。所以在多个未提交事务相继对一条记录做改动时,需要让它们排队执行,这个排队的过程其实是通过锁来实现的。 -
从读的视角来看,通常数据库产品默认隔离级别为
读已提交(Read committed),比如Oracle、SQLServer;虽然 Mysql 的默认隔离级别为可重复读(Repeatable read),但通常来说隔离级别越高,性能损耗越大,而且读已提交能够满足业务绝大部分场景,所以有些公司的 MySQL 也采用了读已提交的隔离级别。 -
读已提交的隔离级别解决的是脏读的问题,脏读就是一个事务读取到了另外一个事务修改后尚未提交的数据 -
脏读会有什么问题呢?比如:A 事务读取 B 事务尚未提交的数据,此时如果 B 事务发生错误并执行回滚操作,那么很容易理解 A 事务获取、使用被回滚的数据肯定是会有问题的。
避免脏写和脏读是对数据库相关产品基本且必要的要求,所以 Seata 提供的分布式事务管理能力也要具备避免脏写和脏读的能力
二、锁的设计是引发脏读和脏写的关键
假定您已了解,数据库 XA 协议无论 Phase2 的决议是 commit 还是 rollback,事务性资源的锁都要保持到 Phase2 完成才释放,如下图所示:
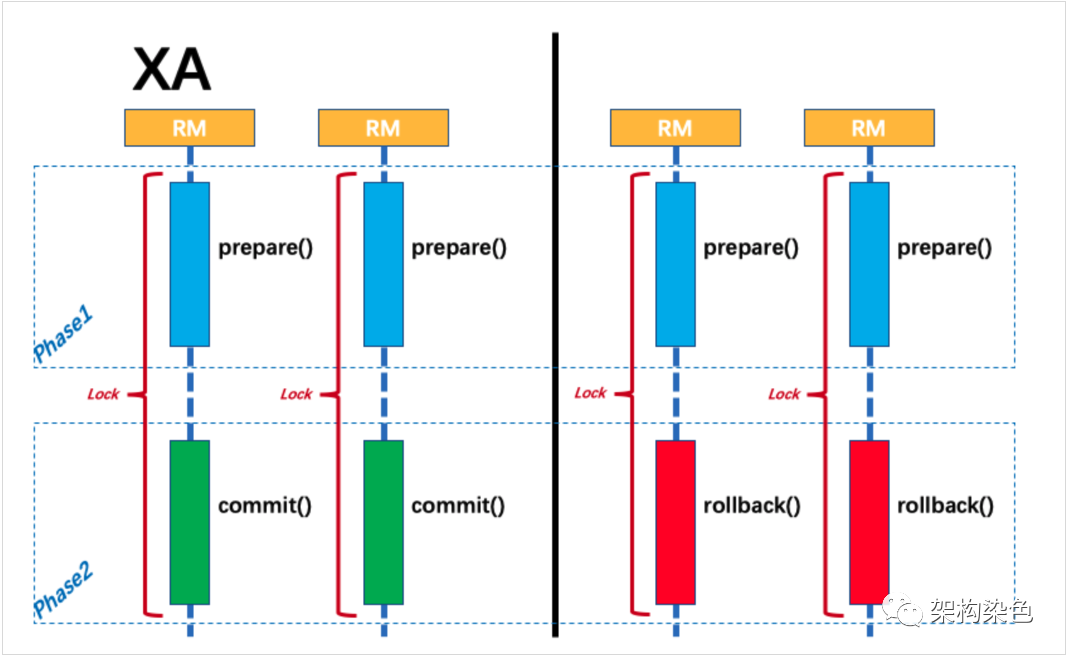
而绝大部分情况下全局事务是成功提交的,那么绝大部分情况下,可以省去 Phase2 的资源锁定(数据库锁和数据库连接),如下图所示:
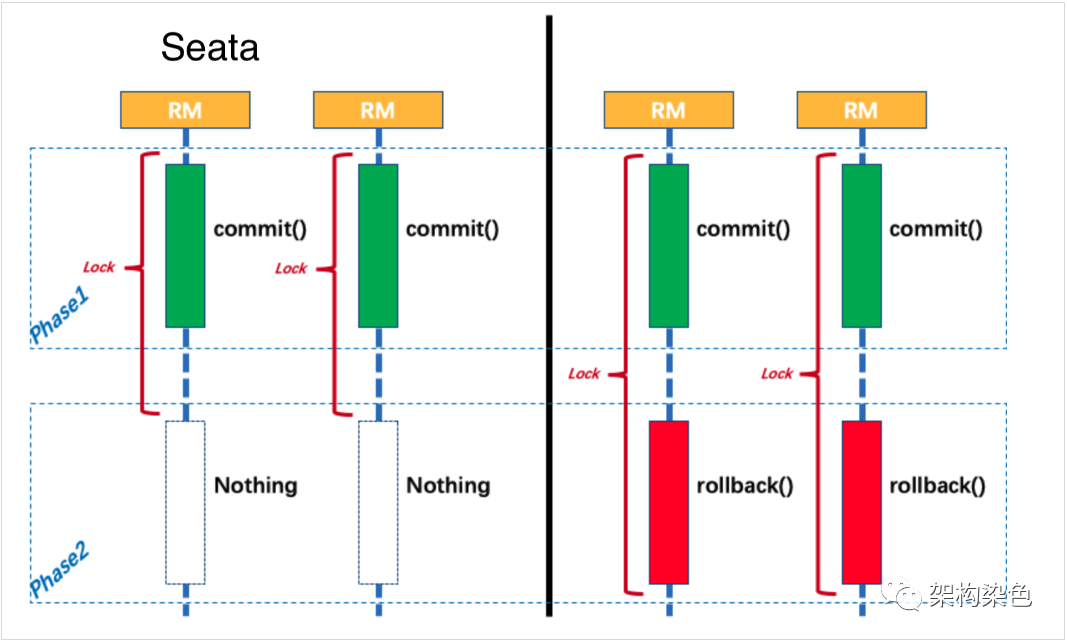
这个设计,给整体性能的提升提供了支撑,原因就在与他极大地减少了分支事务对资源(连接和锁)的锁定时间:
-
在分支事务 Phase1 结束时,本地 DB 连接也得以释放。 -
因分支事务中数据的本地 DB 锁由本地 DB 事务管理,在分支事务 Phase1 结束时释放,这时候其他本地 DB 事务就能读取到最新的数据。
提示:在绝大部分应用在读已提交的隔离级别下工作是没有问题的,本地事务的锁这么早释放,2 阶段没有本地事务锁的保障,是否会出现读未提交的问题呢?实际上,有不少应用场景在读未提交的隔离级别下是没有问题的,而锁在 1 阶段释放掉带来的性能提升也是基于。
相较于 XA 模式 2 个阶段的本地 DB 资源锁定,AT 模式的初衷是减少非必要的 2 阶段本地 DB 资源的锁定,这其中为了保障隔离性,锁在两个阶段肯定是都不能少的(下文补充详情),基于复杂度不会减少只会迁移的的理论模型来推测,AT 模式一定是采用了其他锁方案来替代 2 阶段本地锁,即由 Seata TC 侧提供的全局锁,那么 Seata 就需协调本地锁和全局锁来保障隔离性,其协作机制如下::
-
一阶段本地事务提交前,需要确保先拿到 全局锁。 -
拿不到 全局锁,不能提交本地事务。 -
拿 全局锁有尝试上限(有限次数的重试),超出限制将放弃,并回滚本地事务,释放本地锁。
分支事务一_开始
|
V 获取 本地锁
|
V 获取 全局锁 分支事务二_开始
| |
V 释放 本地锁 V 获取 本地锁
| |
V 释放 全局锁 V 获取 全局锁
|
V 释放 本地锁
|
V 释放 全局锁
如上所示,一个分布式事务的锁获取流程是这样的
-
先获取到本地锁即可修改本地数据,但不能直接提交本地事务
-
为何不能直接提交本地事务呢?因为还未获取全局锁
-
本地锁和全局锁都获得了,才具有全局事务写隔离的保障,本地事务才可以提交,之后释放本地锁
-
当分布式事务执行 2 阶段提交后释放全局锁;这样就可以让其它事务获取全局锁,并提交它们对本地数据的修改了。
至此已明确 Seata AT模式通过将传统 XA 方案的 2 个阶段的本地 DB 锁,拆分成了 1 阶段的本地锁(DB 锁),和 2 阶段的全局锁,且设计的初衷是第 2 阶段的全局锁在绝大部分情况下非必要,也就是说若不利用 Seata 所提供的一些机制,就不会使用到 2 阶段的全局锁,那么对大部分隔离性要求不高的场景来说,这样就提升了性能;但若对隔离性有要求,又没有基于 Seata 的规则使用全局锁就可能会出现脏写和脏读的问题。
三、AT 模式下脏写问题
Seata 的全局事务,是由若干个分支本地事务组成,在 AT 模式下全局事务执行过程中,某个本地事务提交了不代表全局事务提交了(因为全局事务还没执行完),本地事务读已提交的隔离级别能保障避免本地事务中出现脏读,但当某个本地事务提交后,仅通过本地事务读已提交的隔离级别保障,则会导致已提交的本地事务被读取,但就全局事务而言仍处于未提交的状态,如此便造成了脏读。同样若出现本地事务修改后-全局事务提交前的数据又被其他本地事物修改,则会造成脏写。
3.1、脏写的产生
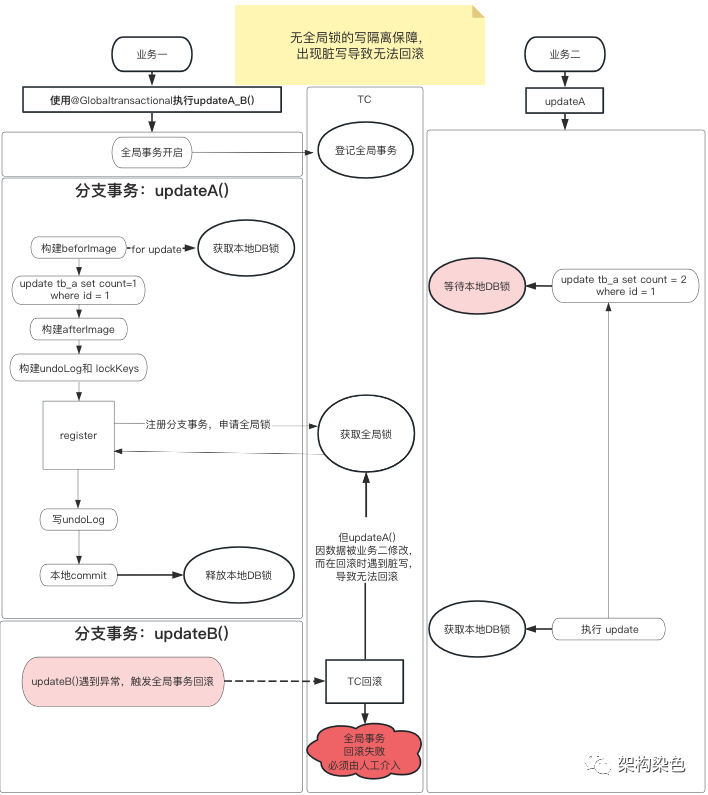
如下图示例,有业务一和业务二,业务一使用@Globaltransactional开启事务调用updateA()和 updateB()方法,业务二没有全局事务,直接调用 updateA()方法,updateA()方法是修改表tb_a中 id 值为 1 的记录中 count 字段的值:
-
业务一开启全局事务 -
业务一中分支事务 updateA()将count的值修改为 1,提交了本地事务 -
之后业务二中 updateA()获取到锁,将count的值修改为 2,提交了本地事务 -
业务一中分支事务 updateB()出现了错误,导致业务一全局事务的回滚,在回滚updateA()分支事务时,发现当前 count 字段的值并不是自己所修改的 1,程序逻辑就无法明确该回滚成什么值,导致无法进行自动回滚,需由人工介入排查矫正。
3.2、脏写的应对之法
从前文所介绍内容可知,在 AT 模式下避免脏写的原理也很清晰,就是仅依靠本地锁无法避免,还要依赖 Seata TC 侧的全局锁,在需要全局写隔离的场景下,加入全局锁的判断逻辑即可避免脏写。这里补充全局锁和本地锁协作的两个关键逻辑:
-
本地锁获取之前,不会去争抢全局锁 -
全局锁获取之前(除非超时),不会释放本地锁
全局锁才可以保障分布式事务修改中的读、写隔离,这是理顺隔离性的关键,而这样的协作设计才让全局锁和本地锁相得益彰,即保障数据修改操作是互斥的,不会造成写入脏数据;又尽量避免造成互等死锁。Seata AT 模式下,有两种方法来启用全局锁
-
通过 @GlobalTransactional启用全局锁,是很自然能想到的 -
另外一种是通过 @GlobalLock启用全局锁
下文会分别对其进行介绍。
3.3、通过@GlobalTransactional保障写隔离
1)串行化获取全局锁实现写隔离并正常提交
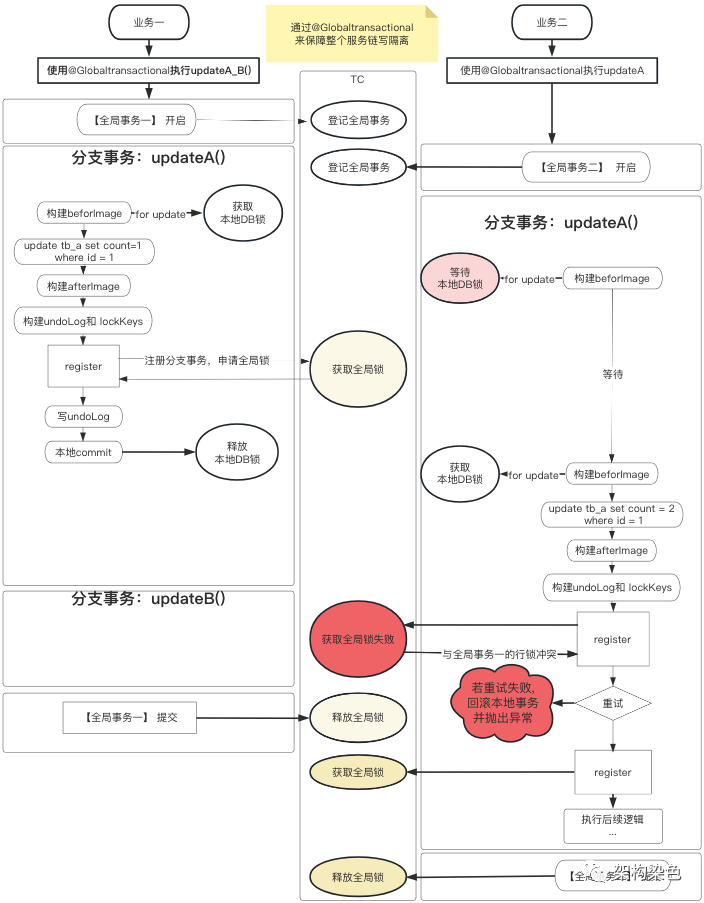
以下图示例来描述一下前后串行获取全局锁实现写隔离并正常提交,有业务一和业务二,业务一使用@Globaltransactional开启事务调用updateA()和 updateB()方法,业务二也使用@Globaltransactional开启事务,单只调用 updateA()方法,updateA()方法是修改表tb_a中 id 值为 1 的记录中 count 字段的值:
-
业务一开启全局事务 -
业务一中分支事务 updateA()将count的值修改为 1,register注册分支事务并获取到了全局锁后提交了本地事务 -
之后业务二中 updateA()获取到本地锁,将count的值修改为 2,但由于是开启了全局事务,所以提交本地事务之前也是需先获取到全局锁,但由于业务一中的全局事务尚未提交,表tb_a的id为 1 的的全局锁还存在,所以在注册分支事务时就发现了锁已存在,并且不是业务二这个全局事务的,于是就需要通过循环重试的方式来多次尝试获取全局锁。 -
业务一中分支事务 updateB()执行完毕后,业务一的全局事务发起提交,之后会释放掉表tb_a的id为 1 的的全局锁。 -
之后若业务二若还在获取全局锁的重试中,则 register注册分支事务并获取到了全局锁(表tb_a的id为 1 的的全局锁),之后便能提交本地事务
注意:业务二提交本地事务后,从其处理上下文来看,已经具备了写隔离性,但是不能就此打住,因为业务二所获取的全局锁还没释放,所以接下来还要再做全局事务的提交,通过提交全局事务将其所添加的全局锁释放掉。释放全局锁似乎略显得多余,可试试推理全局锁的添加是否有必要;注意看,业务二整个事务中只有一个分支事务updateA(),从上下文来看,保障其写隔离,只需要在获取本地锁后判断一下全局锁是否存在,若存在就等其他全局事务结束后再处理,若全局锁不存即表明没有其他全局事务存在,可放心提交本地事务;这块内容是为了下文@GlobalLock做铺垫, @GlobalLock恰是应对不必引入整个全局事务的这种场景,此处先探讨至此。
2)2 阶段回滚会不会出现脏写?
在介绍这个内容时,先将前文的几个关键内容回顾以作为下文的铺垫:
-
本地锁获取之前,不会去争抢全局锁 -
全局锁获取之前(除非超时),不会释放本地锁 -
2 阶段回滚需再获取 本地锁,在回滚(有重试)完成之前,不会释放全局锁 -
以上 3 个逻辑会导致死锁,避免死锁的关键点在给获取 全局锁设定等待超时,若超时则将回滚本地事务,释放本地锁
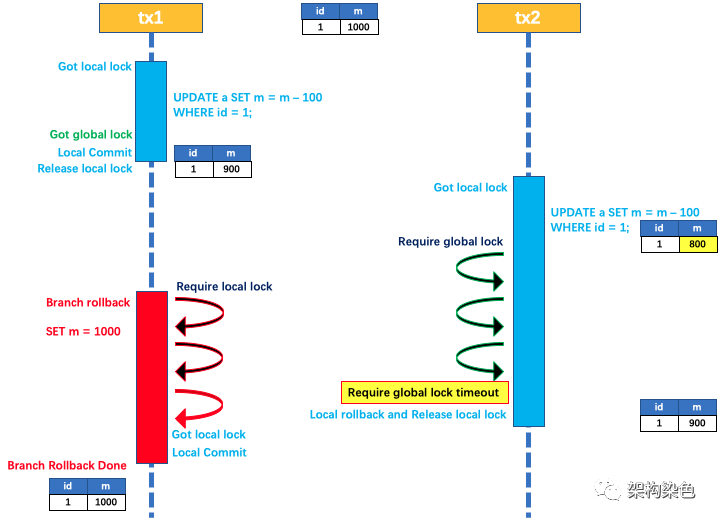
基于以上 4 点逻辑,很容易理解以下摘自《Seata 官网中的 AT 模式回滚时写隔离》的示例描述
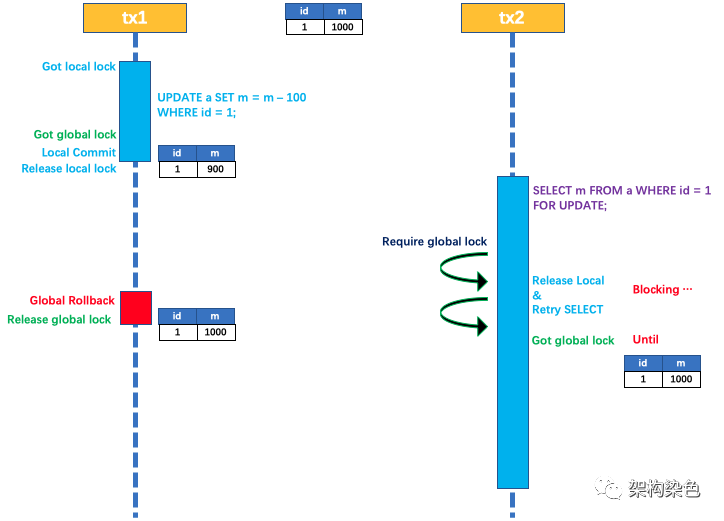
如果 tx1 在二阶段全局回滚,则 tx1 需要重新获取该数据的本地锁,进行反向补偿的更新操作,实现分支的回滚。
此时,如果 tx2 仍在等待该数据的 全局锁,同时持有本地锁,则 tx1 的分支回滚会失败。分支的回滚会一直重试,直到 tx2 的 全局锁 等锁超时,放弃 全局锁 并回滚本地事务释放本地锁,tx1 的分支回滚最终成功。
因为整个过程 全局锁 在 tx1 结束前一直是被 tx1 持有的,所以不会发生 脏写 的问题。
3.4、通过 @GlobalLock保障写隔离
正如上文 @Globaltransactional所介绍的情况,业务二只有一个分支事务updateA(),从上下文来看保障其写隔离,只需要在获取本地锁后判断一下全局锁是否存在,若存在就先等其他全局事务结束后再处理,若全局锁不存即表明没有其他全局事务存在,可放心提交本地事务,这种情况下@Globaltransactional中的逻辑和交互有点多余;而@GlobalLock 恰好是应对这种只在更新前检索全局锁是否存在的场景,如下图所示:
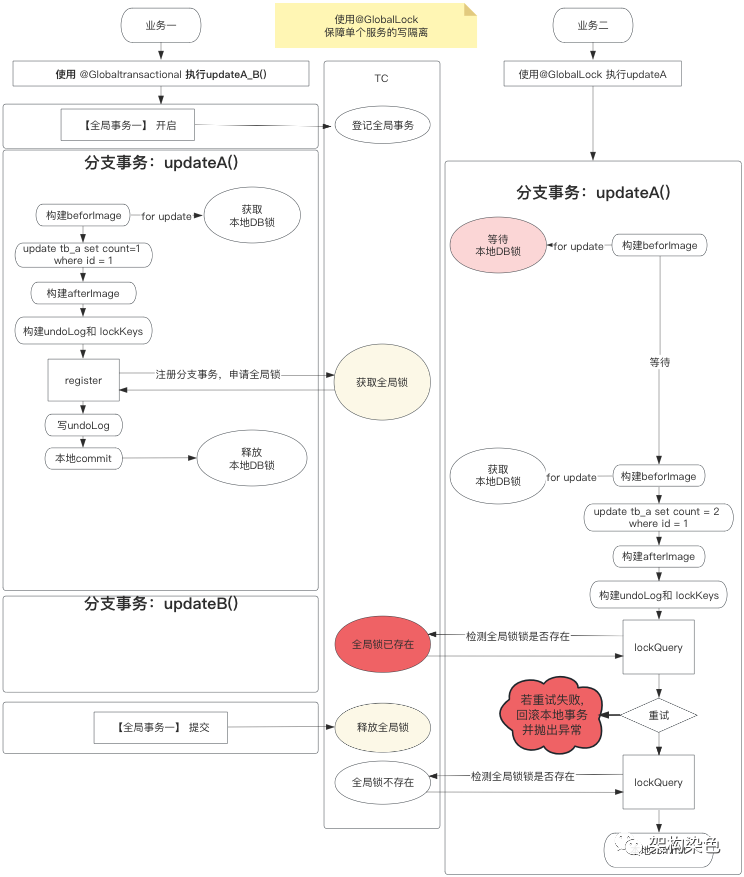
注意:@GlobalLock中为何也有前后镜像的构建过程呢,关键在于要通过lockQuery查询全局锁,而查询全局锁的参数 lockKeys,需要通过前后镜像记录的主键等信息构建(比如insert类的 sql,主键通过后镜像获取主键,delete类的操作要通过前镜像获得,update类的操作理论上前后镜像都可以),这部分的详情可查看《【Seata 源码领读】揭秘 @GlobalTransactional 背后 RM 的黑盒操作》
四、AT 模式下脏读问题
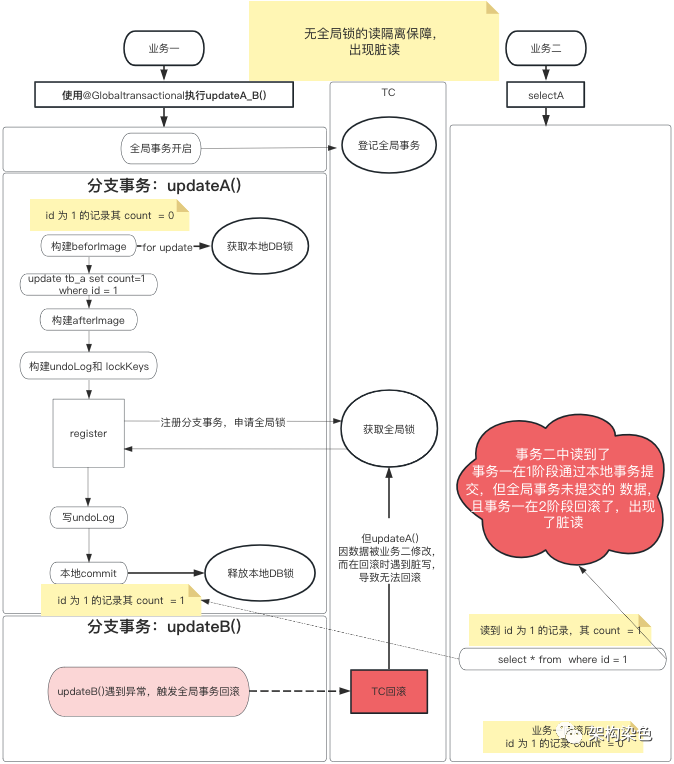
4.1、脏读的产生
和脏写的情况类似,如下图示例,有业务一和业务二,业务一使用@Globaltransactional开启事务调用updateA()和 updateB()方法,业务二没有全局事务,直接调用 selectA()方法,updateA()方法是修改表tb_a中 id 值为 1 的记录中 count 字段的值,selectA()是读取表tb_a中 id 值为 1 的记录:
-
业务一开启全局事务 -
业务一中分支事务 updateA()将count的值修改为 1,提交了本地事务 -
之后业务二中 selectA(),读取到count的值为 1 -
业务一中分支事务 updateB()出现了错误,导致业务一全局事务的回滚,就要撤销那么count为1的修改,那么业务二中读取到的count值为 1 的情况就是读未提交了。
4.2、脏读的应对之法
从前文所介绍内容可知,在 AT 模式下避免脏读的关键是要避免读取到完成了 1 阶段本地提交,但 2 阶段未提交的数据;即本地提交后,全局事务提交前的数据都不可被读到,我们一起通过自省的方式来寻找答案
-
【问题】:若全局锁不存在时,就读 DB 数据是否安全呢?
-
如果判断出全局锁不存在之后读 DB 数据,那么判断全局锁 和 读 DB 数据这期间,就可能有其他事务插入了数据,而这个数据也可能会被回滚掉;所以读 DB 和判断全局锁之间不能留下让其他事务插入数据的机会
-
【问题】:本地锁和全局锁之间的协作关系是怎样呢?
-
全局事务提交数据是先拿本地锁,修改数据,再获取全局锁,本地提交后释放本地锁,全局提交后释放全局锁。 -
全局锁获取之前(除非超时),不会释放本地锁 -
所以本地锁和全局锁都不存在的情况下,才能避免脏读
-
【问题】:本地锁是否存在怎么判断?全局锁是否存在怎么判断?
-
本地锁是否存在可以通过 select... for update nowait,全局锁可通过 TC 侧的lockQuery接口查询获知
-
【问题】:判断本地锁和判断全局锁这两个操作不是原子的,期间仍然是有空隙,如何避免空隙?
-
按照问题 2 中本地锁和全局锁的协作关系来看,需先抢占本地锁避免其他事务将数据写入,然后再判断全局锁是否存在,所以要求 select 还具备加锁的能力
-
【问题】:什么 select 具备加锁的能力呢?
-
select * for update具备这个能力,从其字面意思可知,该查询语句不是简单的查询,而在查询时会持有本地锁,避免其他事务变更数据操作,造成数据的不一致性。所以select * for update持有本地锁后,再判断全局锁即可。
-
【问题】:在获取到本地锁之后,接下来可能发现全局锁已存在,这时等待全局锁的的这个机制如何实现?
-
如果持有本地锁不释放一直干巴巴的等全局锁,有可能造成死锁,比如另一个事务已持有全局锁回滚时却无法拿到本地锁。这种死锁问题可以规避,即持有本地锁后,发现全局锁已存在,就立即放弃本地锁(这个间隙就给了其他需要本地锁的事务抢锁的机会),再重新先抢占本地锁、查询全局锁。
所以 Seata AT 模式是通过对select... for update语句代理提供的全局的读已提交的能力,基于了select... for update的原始能力抢占本地锁,又通过增强的方式加入了查询全局锁以及重试的机制。需要留意增强的前提是select... for update要处于@GlobalTransactional 或 @GlobalLock的上下文中。
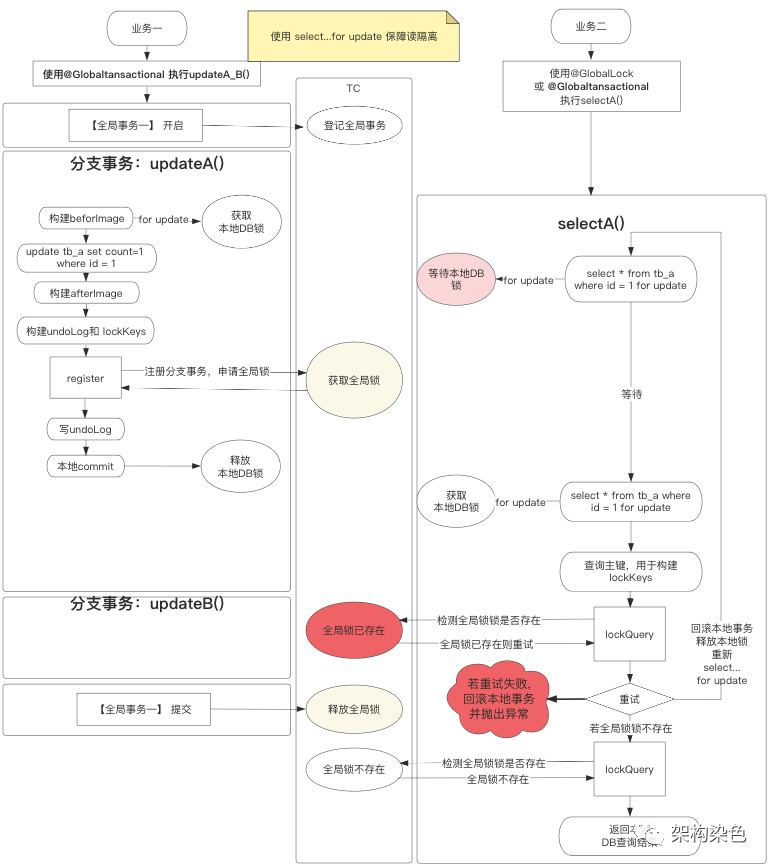
1)当读隔离遇到 2 阶段提交
有业务一和业务二,业务一使用@Globaltransactional开启事务调用updateA()和 updateB()方法,业务二要使用@GlobalTransactional 或 @GlobalLock来包裹对 selectA()方法的调用, updateA()方法是修改表tb_a中 id 值为 1 的记录中 count 字段的值,selectA()是读取表tb_a中 id 值为 1 的记录,而且有for update子句:
-
业务一开启全局事务 -
业务一中分支事务 updateA()将count的值修改为 1,提交了本地事务 -
之后业务二中 selectA(),读取时因for update的机制会等待业务一释放本地锁 -
业务一获取了全局锁后,执行本地提交,释放了本地锁 -
之后业务二中 selectA(),获取了本地锁,读到了数据;接下来读取全局锁,发现业务一的全局锁还在后,就会回滚本地事务,释放本地锁,进入重试逻辑(有上限次数)从第 3 步重新开始执行。 -
业务一中分支事务 updateB()执行完毕,接下来业务一全局事务的提交 -
业务二重试时,发现全局锁不存在了,则直接返回本地查询的结果,即读到业务一提交 count的值为 1 ,实现了读已提交
2)当读隔离遇到 2 阶段回滚
基于以上自省和图解的过程,很容易理解以下摘自《Seata 官网中的 AT 模式回滚时读隔离》的示例,过程就不再过多描述了
通过本章节内容可知,Seata AT 模式默认全局隔离级别是读未提交;如果需要全局的读已提交,可以通过select... for update语句的代理。但相信大家已看到 Seata 实现 AT 模式下读已提交的成本很高,传统的读已提交不需要本地锁,但这里却需要对查询语句加上for update,查询多出了加锁和竞争的开销,另外还要持锁调用 TC 的lockQuery接口以判断全局锁情况。对于非必要场景还是要尽量避免使用。
最后
我是石页兄,如果这篇文章对您有帮助,或者有所启发的话,欢迎关注笔者的微信公众号【 架构染色 】进行交流和学习。您的支持是我坚持写作最大的动力。
参考并感谢
-
详解 Seata AT 模式事务隔离级别与全局锁设计
-
阿里开源分布式事务解决方案 Fescar 全解析
-
Seata AT 模式分布式事务源码分析
-
Seata AT 模式的全局锁 GlobalLock
-
带你读透 SEATA 的 AT 模式


