
【云原生•监控】夜莺可观测性之告警系统设计 - 2原创
前言
「笔者已经在公有云上搭建了一套临时环境,可以先登录体验下:」
http://124.222.45.207:17000/login
账号:root/root.2020
告警功能
内置规则
【内置规则】菜单主要提供系统中内置的一些告警规则,按照组件类型进行分类分组:
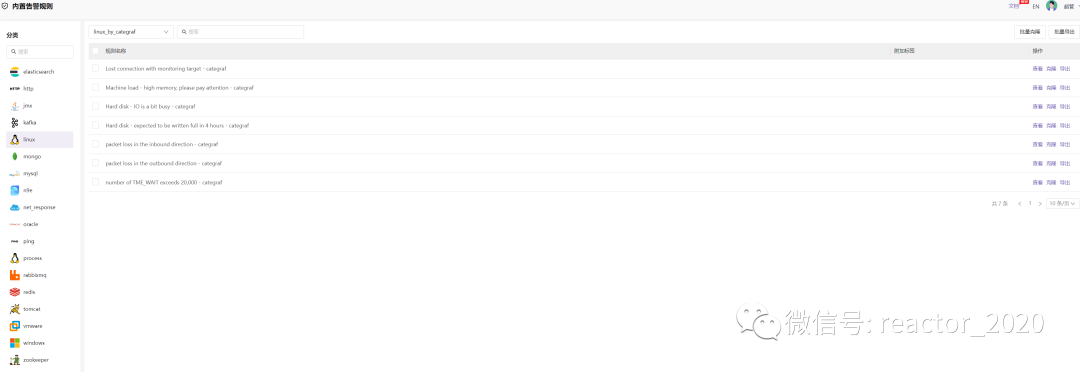
内置规则仅仅只是提供告警规则模板文件,是不会生效触发告警的,用户需要将使用的告警模板克隆到业务组下,才能使用这些告警模板。
告警规则
【告警规则】菜单用于管理每个业务组的告警规则,这些告警规则一方面是从【内置规则】克隆方式导入的,另一方面也可以【新增】方式创建:
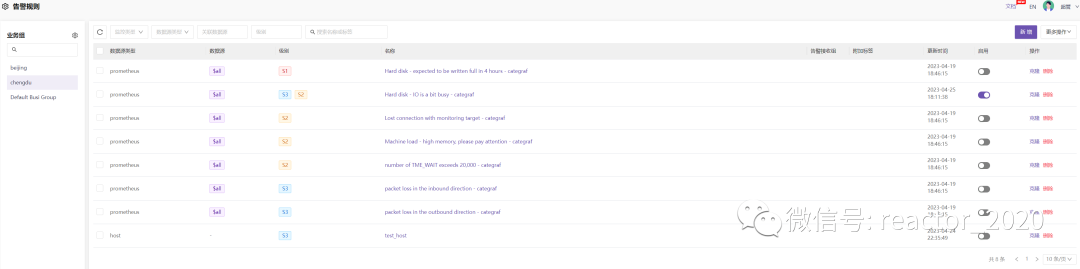
❝【启用】开关用于控制告警是否生效。
❞
下面我们来看下告警规则配置:
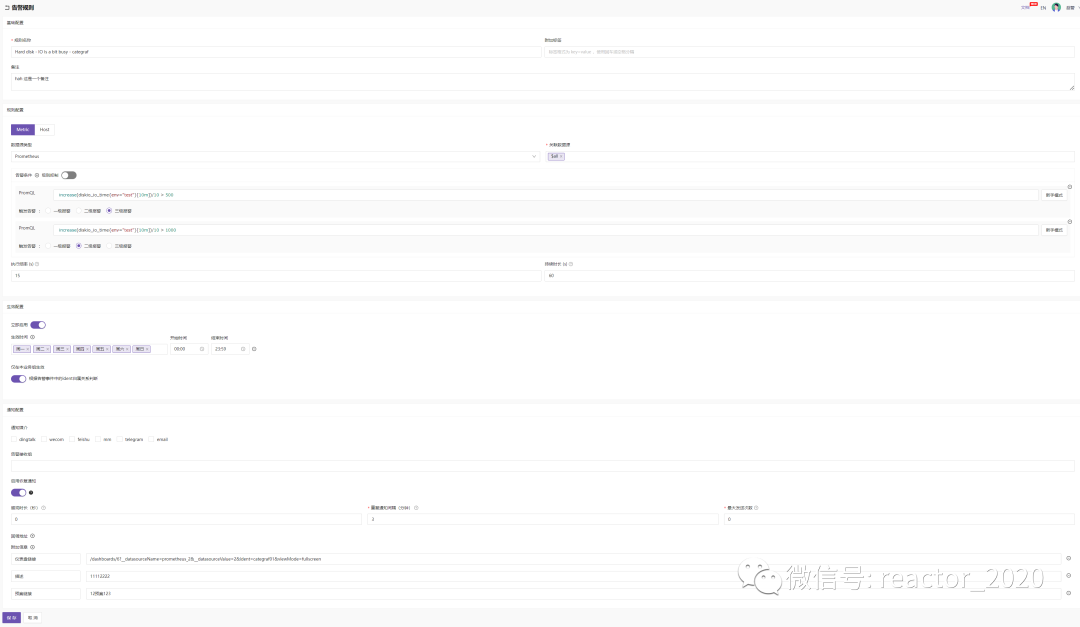
主要功能说明:
-
规则名称:简明扼要的说明当前告警内容,比如"磁盘IO高告警";
-
规则配置:
-
关联数据源: PromQL执行查询数据源。 -
PromQL:填写告警规则的PromQL语句,这里可以填写多条,主要场景比如"CPU% > 80%"触发三级告警,"CPU% > 90%"触发二级告警,基于不同阈值触发不同告警等级的告警,这里有个【级别抑制】开关,打开级别抑制,则高等级告警抑制低等级告警,比如"当前CPU% > 95%",上面配置的二级告警和三级告警都会触发,但是用户肯定希望收到更高等级的二级告警,就可以打开【级别抑制】开关,避免过多告警干扰。 -
执行频率: PromQL执行周期间隔,单位:秒。 -
持续时长:告警持续多久才会触发该告警,比如"CPU% > 80%"告警,执行频率15秒,持续时长60s,则连续抓取4个点CPU使用率都高于80%才会触发告警,如果对灵敏度要求比较高,可以设置持续时长=0,则只要检测到CPU使用率>80%,会立即触发告警。 -
告警分为: Metric和Host,Metric当前只支持Prometheus,即基于指标使用PromQL表达式进行告警;Host告警是内置实现对Categraf采集点相关的告警。 -
Host告警主要基于Categraf采集点告警,可定制能力比较弱,主要使用内置实现的:机器失联、机器机器失联和机器时间偏移,这块告警主要依赖Categraf的heartbeat功能,同时该告警只能中心服务器,对于边缘部署的n9e-alert组件没法使用。 -
可定制强的主要使用的 Metric告警: -
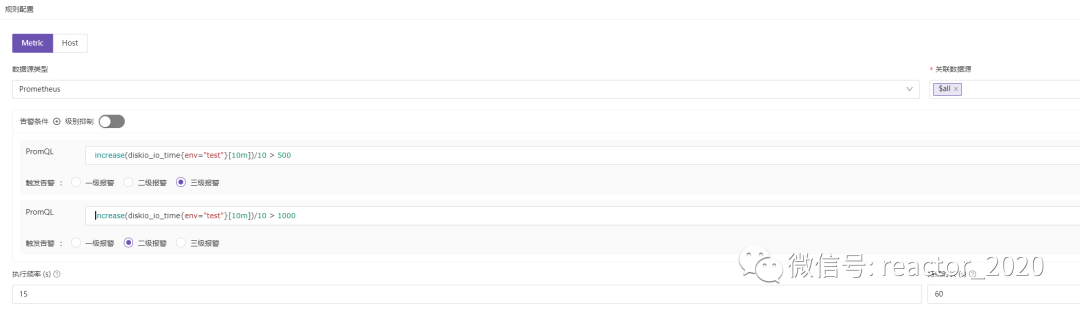
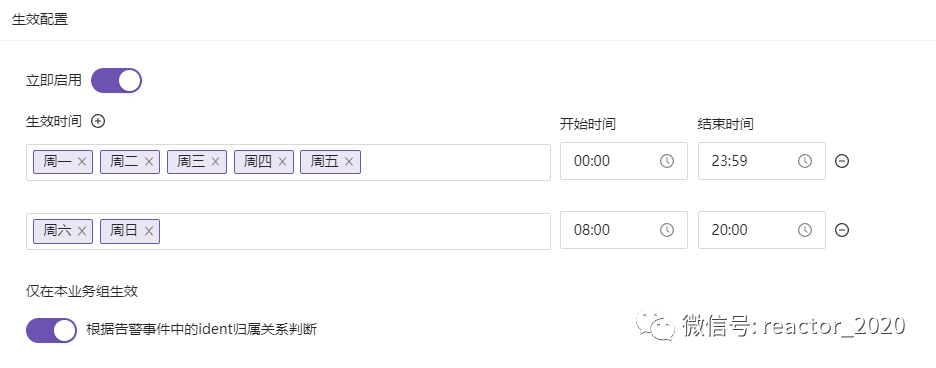
生效规则:用于配置告警规则生效时间
-
系统提供的生效时间还是比较灵活,比如可以细化到星期几的哪个时间区间告警; -
尽在本业务组生效:依赖告警事件中必须存在"ident"标签,查询告警"ident"标识机器所属的业务组和告警规则所属的业务组是否匹配,不匹配则过滤掉,这个主要用来实现告警隔离,比如业务A组配置的告警规则更可能作用于业务组A管理下的机器告警,对业务组B机器告警也没用,告警出来没法处理,注意:该告警依赖"ident"标签识别是代码写死不能调整。
-
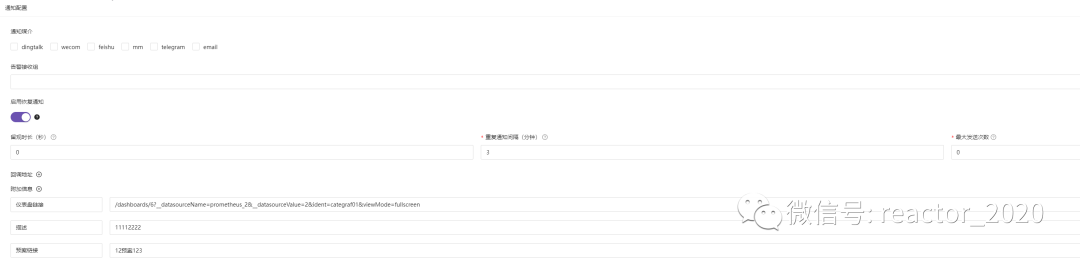
通知配置:该部分主要配置告警触发后通过不同媒介通知到相关人员。 -
留观时长:该参数主要预防告警波动,比如告警恢复后几十后又触发, -
重复通知间隔:避免告警风暴,告警触发通知后,后面还在源源不断的触发告警,也必须等到"重复通知间隔"时间后才能再次触发告警通知,如果"重复通知间隔=0"则同一告警事件在一个触发周期内只会发送一次告警。 -
最大发送次数:同一告警事件最多发送几次告警。 -
三个核心参数:
活跃告警
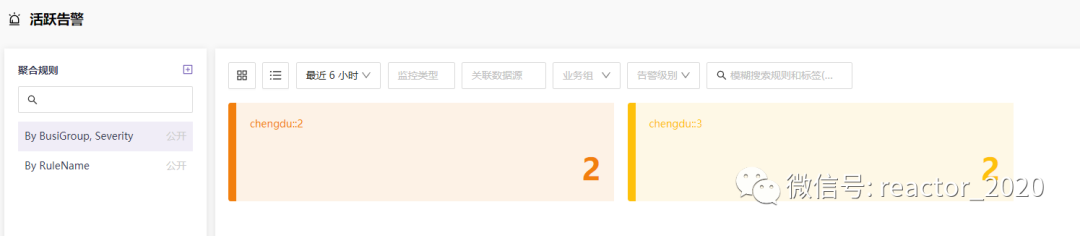
【活跃告警】菜单展示当前触发中的告警,可以从业务组和告警等级维度展示:
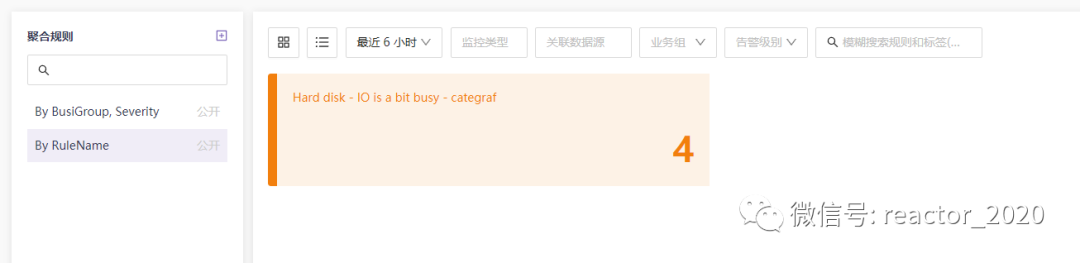
还可以基于告警规则维度展示:
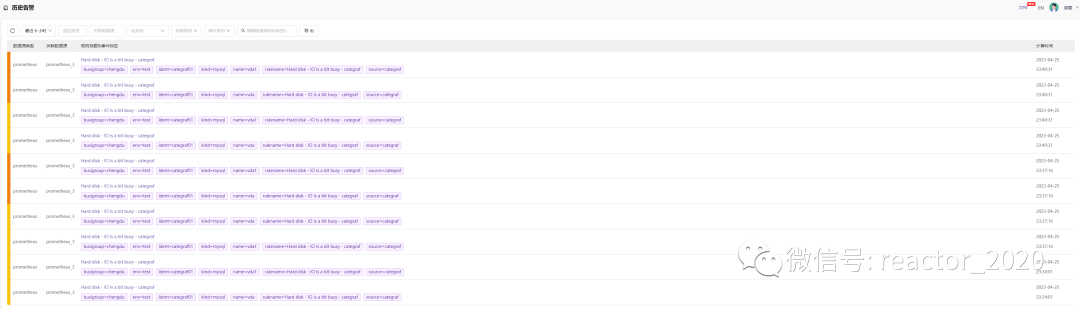
历史告警
【历史告警】菜单展示全量告警信息,包括所有历史触发过的告警:
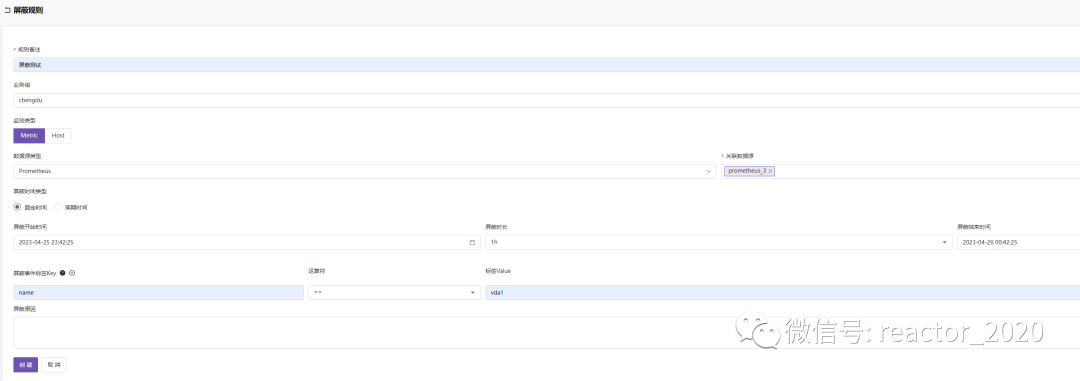
告警屏蔽
【告警屏蔽】菜单实现告警屏蔽规则或者说告警静默规则,支持固定时间和周期时间,比较灵活,可以根据事件源屏蔽,也可以根据事件标签屏蔽:
告警系统如何设计实现
夜莺监控系统在告警引擎的建设上,提供了诸多灵活配置能力,而且具备多样的告警策略,下面我们来看一下告警系统是如何设计实现的。
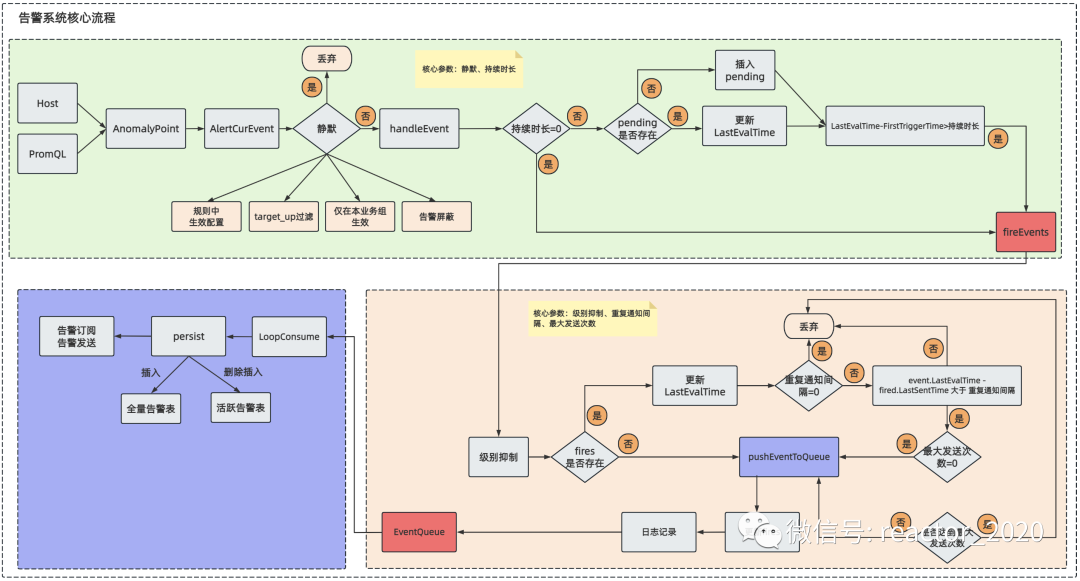
「核心流程解读:」
1、对告警系统整个核心流程梳理,可以分为三个主要阶段(「注意图中红色方块重要节点」):第一个阶段完成基于异常点构建告警事件;第二个阶段基于告警事件计算告警是否触发;第三个阶段则是告警触发后置处理,包括持久化、告警发送等处理。
2、基于异常点构建告警事件阶段:异常点检索主要分为两种PromQL和Host。
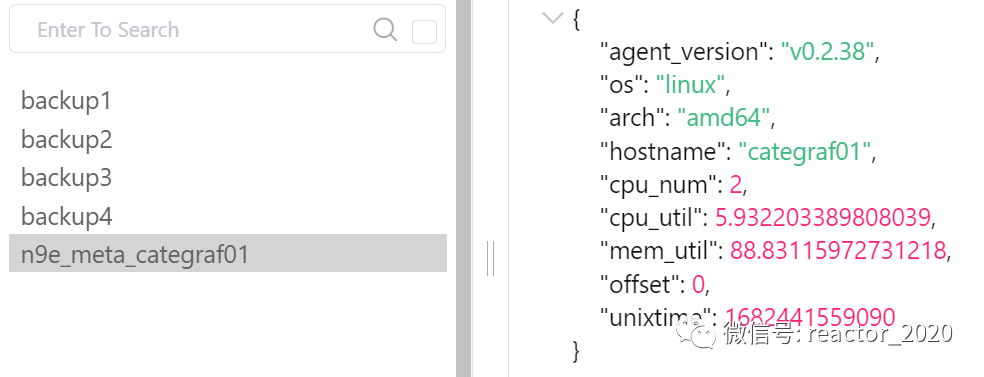
a、Host告警主要基于target表中heartbeat数据计算,比如"机器失联"则判断target表中update_at最后更新时间距当前时间差超过配置阈值,则触发机器失联告警,heartbeat完整数据是存储到Redis中,见下图:
b、检索出来的异常点构建成AleretCurEvent,然后通过静默筛选,不通过的会被丢弃,千万注意下这里对丢弃的数据是没有任何记录的,没有涉及屏蔽告警表。
c、然后依据告警规则中配置的持续时长参数,筛选满足要求的告警事件,进入到fireEvents集合中,即该集合中告警满足触发前置条件。
3、基于告警事件计算告警是否触发阶段:fireEvents集合中告警是否可以真正告警触发还要看这一阶段处理。
a、经过级别抑制筛选掉低级别告警事件;
b、然后根据重复通知间隔和最大发送次数又会筛选掉一部分告警事件;
c、将最后满足条件的告警事件更新到fires集合中,并进行日志记录这些告警事件,然后发送到EventQueue队列中,表示当前这些告警事件是满足触发条件的。
4、告警触发后置处理阶段:满足触发条件的告警事件进入到EventQueue,这里采用生产者/消费者模式实现,对应的存在一个消费者LoopConsume循环从EventQueue中提取告警事件进行后续处理。这里的后续处理主要包括:
a、持久化:将告警事件写入到数据库的全量告警表和活跃告警表中;
b、依据配置进行告警订阅和告警发送处理。

[更多云原生监控运维,请关注微信公众号:Reactor2020]

