
【云原生•监控】Categraf大一统的监控数据采集器原创
前言
「笔者已经在公有云上搭建了一套临时环境,可以先登录体验下:」
http://124.222.45.207:17000/login
账号:root/root.2020
简介
Categraf 是一个监控采集 Agent,类似 Telegraf、Grafana-Agent、Datadog-Agent,希望对所有常见监控对象提供监控数据采集能力,采用 All-in-one 的设计,不但支持指标采集,也希望支持日志和调用链路的数据采集。
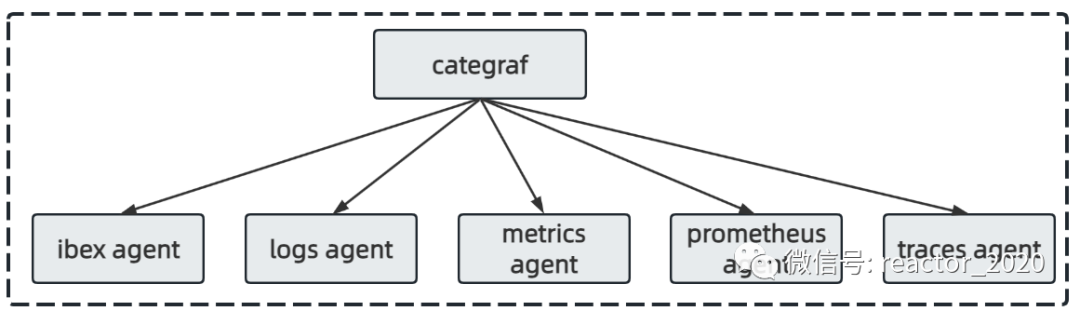
Categraf组件将5个常用agent进行整合,采用 all-in-one 的设计,主要解决如每台机器可能需要部署很多个prometheus exporter导致运维困难的问题,所有的采集工作用一个 agent 搞定,也可以把日志和 trace 的采集纳入 agent:
-
「ibex agent:」故障自愈 agent,主要用于执行自愈脚本; -
「logs agent:」日志采集 agent; -
「metrics agent:」指标采集 agent,采用插件模式设计; -
「prometheus agent:」嵌入 prometheus sdk,实现prometheus agent模式; -
「traces agent:」链路采集agent;
编译运行
categraf 的代码托管在 github:https://github.com/flashcatcloud/categraf。
1、下载并编译:
# export GO111MODULE=on
# export GOPROXY=https://goproxy.cn
go build
2、打包:
tar zcvf categraf.tar.gz categraf conf
❝conf 目录下还提供了 categraf.service 文件样例,便于大家使用 systemd 托管 categraf。
❞
3、运行
# test mode: just print metrics to stdout
./categraf --test
# test system and mem plugins
./categraf --test --inputs system:mem
# print usage message
./categraf --help
# run
./categraf
# run with specified config directory
./categraf --configs /path/to/conf-directory
# only enable system and mem plugins
./categraf --inputs system:mem
# use nohup to start categraf
nohup ./categraf &> stdout.log &
「测试」
我们经常会需要测试某个采集器的行为,临时看一下这个采集器输出哪些监控指标,比如配置好了 conf/input.mem/mem.toml 想要看看采集了哪些Linux内存指标,可以执行命令:./categraf --test --inputs mem
[root@swarm-worker02 categraf-v0.3.3-linux-amd64]# ./categraf --test --inputs mem
2023/05/15 23:41:48 I! tracing disabled
2023/05/15 23:41:48 metrics_agent.go:269: I! input: local.mem started
2023/05/15 23:41:48 agent.go:47: I! [*agent.MetricsAgent] started
2023/05/15 23:41:48 agent.go:50: I! agent started
23:41:48 mem_free agent_hostname=swarm-worker02 1264836608
23:41:48 mem_high_free agent_hostname=swarm-worker02 0
23:41:48 mem_sreclaimable agent_hostname=swarm-worker02 279576576
23:41:48 mem_swap_cached agent_hostname=swarm-worker02 0
23:41:48 mem_available agent_hostname=swarm-worker02 5180682240
23:41:48 mem_used agent_hostname=swarm-worker02 520003584
23:41:48 mem_total agent_hostname=swarm-worker02 6017568768
23:41:48 mem_available_percent agent_hostname=swarm-worker02 86.09261380691878
23:41:48 mem_write_back agent_hostname=swarm-worker02 0
23:41:48 mem_used_percent agent_hostname=swarm-worker02 8.64142320674847
23:41:48 mem_high_total agent_hostname=swarm-worker02 0
23:41:48 mem_low_total agent_hostname=swarm-worker02 0
ibex agent
ibex agent主要用于告警自愈场景。故障自愈主要用于解决出现故障时,基于故障治理方案自动执行相关的操作,已达到故障自动修复能力。比如主机磁盘使用率高,可以执行脚本清理磁盘文件;还比如PaaS组件CPU、内存使用率居高不下,可以通过三方接口方式调用重启组件释放资源等等。
夜莺监控支持告警规则中关联回调地址方式,实现告警触发时通过调用三方接口方式实现告警自愈能力,见下图:
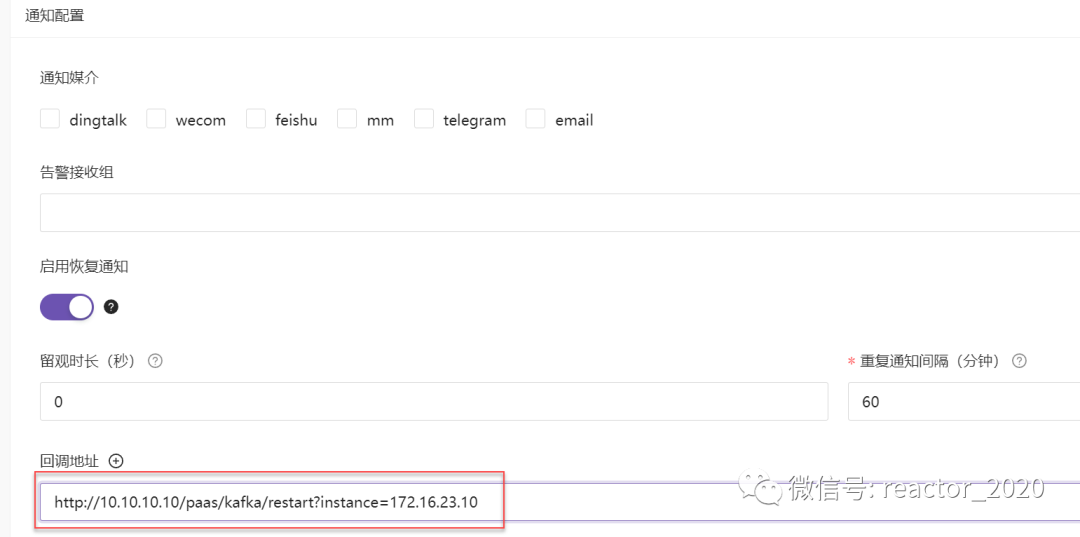
回调地址除了可以配置HTTP地址外,还支持基于ibex组件回调自愈脚本能力,见下图:

这里的1就是对应的自愈脚本ID,可以在【告警自愈】-【自愈脚本】页面查询对应ID信息:
自愈脚本通常有两种方式:基于ssh方式执行和客户端agent执行,夜莺采用基于后者方式,ibex-agent最新方式已经集成到categraf组件中:
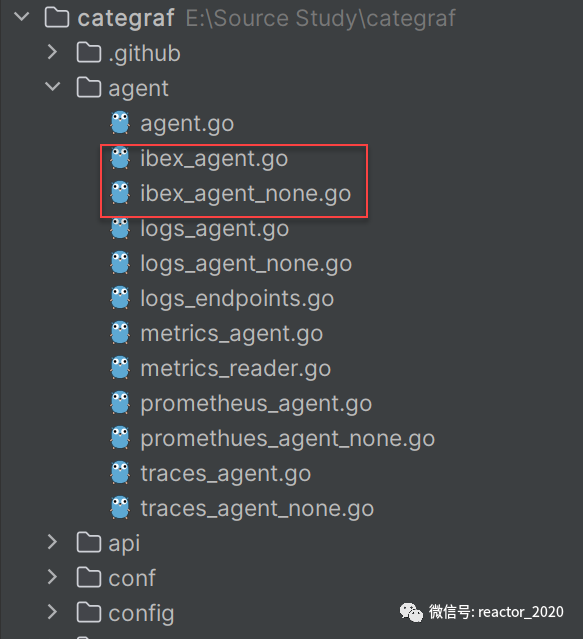
categraf组件ibex相关配置示例如下:
# 是否启用告警自愈agent
[ibex]
enable = false
## ibex flush interval
interval = "1000ms"
## n9e ibex server rpc address
servers = ["127.0.0.1:20090"]
## temp script dir
meta_dir = "./meta"
故障自愈核心组件数据流如下图:
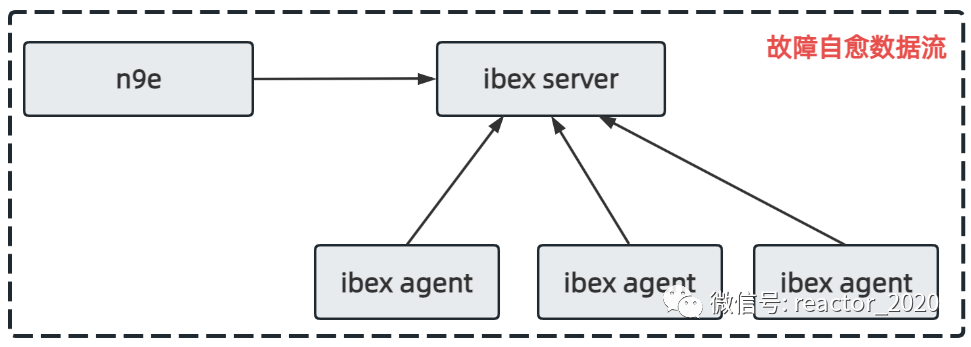
自愈脚本、告警配置都在n9e组件端,然后将其分发到ibex server组件,该组件单独管理故障自愈脚本执行分发,然后ibex agent组件定时周期性通过RPC接口方式拉取当前主机上执行的脚本任务执行,并同时将执行结果、执行输出等上报到ibex server组件,这样n9e管理端就可以从ibex server端查询到任务执行明细并进行展示。
❝ibex agent组件已经被集成到categraf组件中,所以,这里的ibex agent即为categraf。
❞
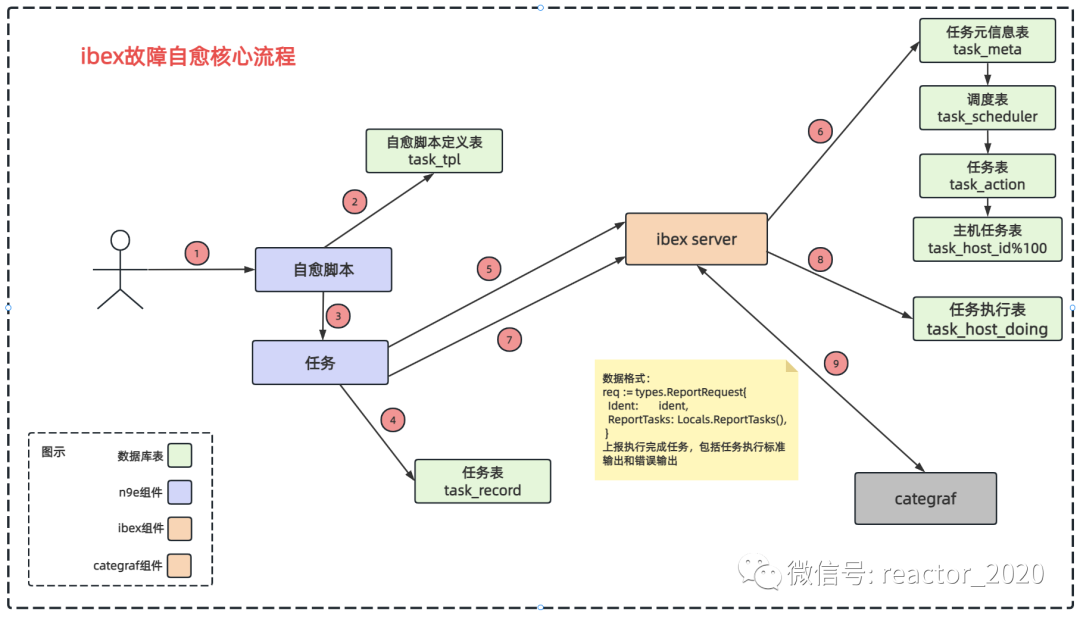
ibex故障自愈详细的核心流程见下图:
prometheus agent
Prometheus Agent 是自 Prometheus v2.32.0 版本推出的实验性功能,当启用此功能后,将不会在本地文件系统上生成块,并且无法在本地查询。如果网络出现异常状态无法连接至远程端点,数据将暂存在本地磁盘,但是仅限于两个小时的缓冲。
在prometheus开启agent模式时,prometheus.yml中必须配置"remote_write",不能配置alertmanager和rules,因为agent节点仅有采集指标功能,添加alertmanager和rules启动时会报错。
prometheus agent配置conf/prometheus.toml:
[prometheus]
# 是否启动prometheus agent
enable=false
# 原来prometheus的配置文件
# 或者新建一个prometheus格式的配置文件
scrape_config_file="/path/to/in_cluster_scrape.yaml"
## 日志级别,支持 debug | warn | info | error
log_level="info"
# 以下配置文件,保持默认就好了
## wal file storage path ,default ./data-agent
# wal_storage_path="/path/to/storage"
## wal reserve time duration, default value is 2 hour
# wal_min_duration=2
categraf组件中prometheus agent就是使用prometheus sdk实现了prometheus agent模式,这样就可以把prometheus采集配置直接拿来使用:
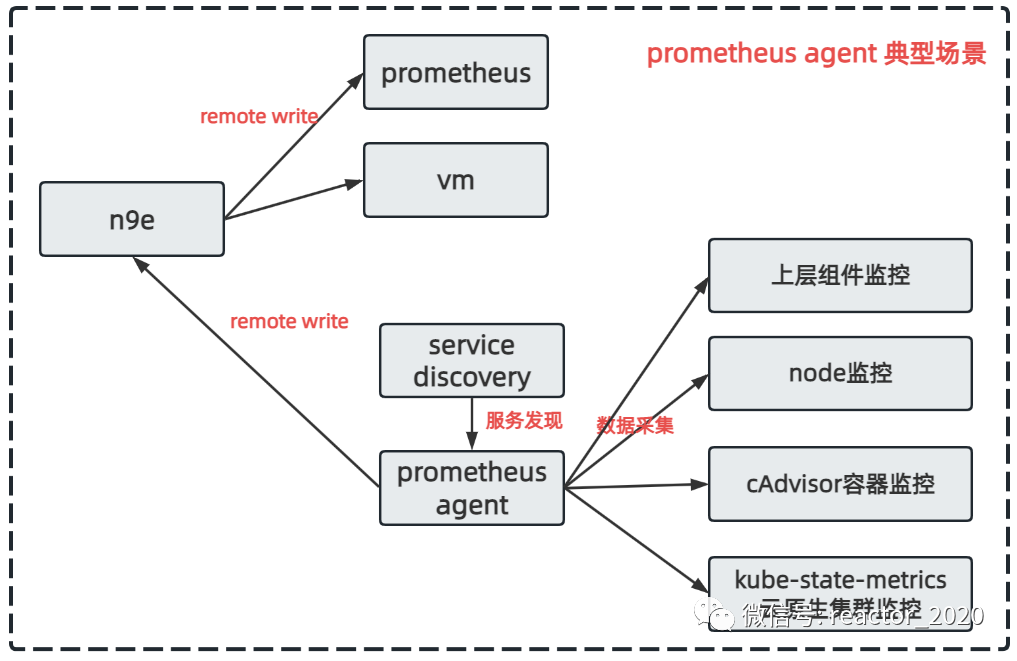
如上图,我理解的categraf的prometheus agent典型应用场景是借助prometheus强大的服务发现能力,对云原生集群node机器、cAdvisor容器、ksm集群和上层业务组件进行监控。
metrics agent
作为categraf组件的核心模块,metrics agent主要实现对各种组件的性能指标进行采集,类似于prometheus中的exporter,但是categraf组件采用All-in-one 的设计思想,并利用插件模式进行实现。
采集插件的代码,在代码的 inputs 目录,每个插件一个独立的目录,目录下是采集代码,以及相关的监控大盘JSON(如有)和告警规则JSON(如有),Linux相关的大盘和告警规则没有散在 cpu、mem、disk等采集器目录,而是一并放到了 system 目录下,方便使用。
插件的配置文件,放在conf目录,以input.打头,每个配置文件都有详尽的注释,如果整不明白,就直接去看 inputs 目录下的对应采集器的代码,Go 的代码非常易读,比如某个配置不知道是做什么的,去采集器代码里搜索相关配置项,很容易就可以找到答案。
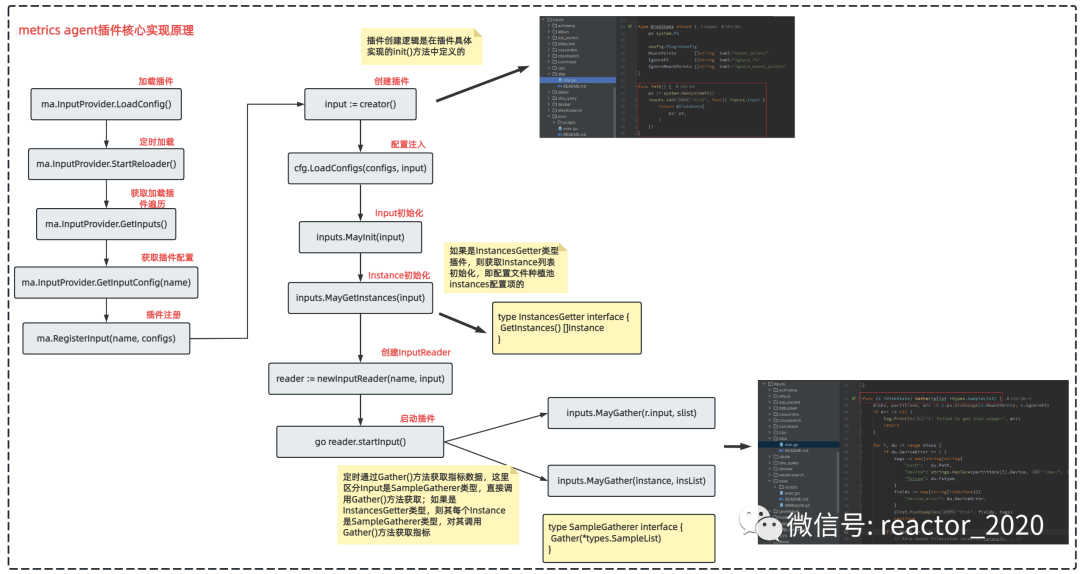
categraf大概实现了70+插件,每个插件怎么使用可以查看对应的插件的README文档,具体使用这里就不做过多介绍。下面主要来看下插件核心实现原理(见下图),方便我们进行二次开发:
heartbeat
categraf组件可以和n9e后端组件启用心跳功能,通过心跳模式上报集群节点的CPU、内存、OS等基础信息,配置如下:
# categraf心跳配置,启动心跳功能,categraf会定时周期将节点cpu、内存等信息通过心跳包发送给n9e后端服务
[heartbeat]
enable = true
# report os version cpu.util mem.util metadata
url = "http://127.0.0.1:17000/v1/n9e/heartbeat"
# interval, unit: s
interval = 10
# Basic auth username
basic_auth_user = ""
# Basic auth password
basic_auth_pass = ""
## Optional headers
# headers = ["X-From", "categraf", "X-Xyz", "abc"]
# timeout settings, unit: ms
timeout = 5000
dial_timeout = 2500
max_idle_conns_per_host = 100
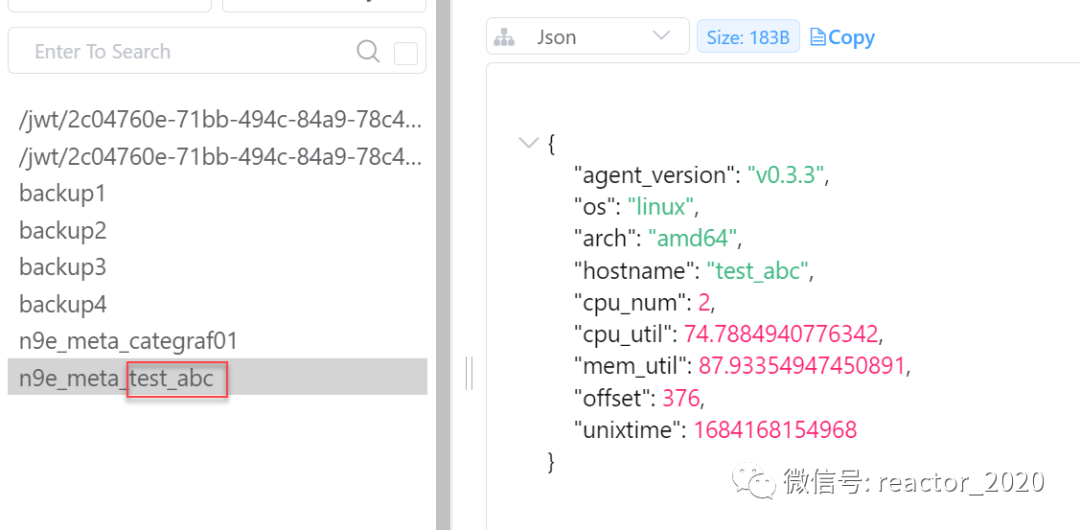
心跳包会将categraf组件服务器的基础信息发送到后端,具体信息如下:
data := map[string]interface{}{
"agent_version": version,//categraf版本
"os": runtime.GOOS,//系统
"arch": runtime.GOARCH,//架构
"hostname": hostname,//主机名
"cpu_num": runtime.NumCPU(),//CPU核数
"cpu_util": cpuUsagePercent,//cpu使用率
"mem_util": memUsagePercent,//内存使用率
"unixtime": time.Now().UnixMilli(), //后端可以用于计算客户端和后端时间偏移
}
服务端收到心跳包后,基于req.Offset = (time.Now().UnixMilli() - req.UnixTime)计算出后端和categraf采集端时间偏移量,然后并将这些信息一起写入到内存,并定时1秒间隔刷新到Redis缓存中,key是n9e_meta_$hostname格式,见下图:

[更多云原生监控运维,请关注微信公众号:Reactor2020]

