
【全网首发】定位频繁创建对象导致内存溢出风险的思路原创
背景介绍
近来一段时间排查了几例由于应用程序频繁创建对象导致FGC的问题,问题产生的场景包括:
- 同一条SQL语句,平时返回预期内的数据条数,出问题的时候返回了几十万条数据,短时间内创建了大量对象进而导致非预期的GC。
- 应用程序在处理Excel文件的时候,短时间内创建了大量对象进而导致非预期GC。
- 接口的入参是List<Object>,未对入参参数个数做控制,导致后续逻辑创建了大量对象进而导致非预期GC。
- … …
综上,无论是何种具体场景,最终的结果是短时间内创建了大量对象,导致GC频次升高,GC频次升高到一定程度会导致CPU飙高(频繁GC是导致CPU飙高的一个原因,所以在遇到CPU飙高的现象,可以迅速看下是否GC频繁导致,而不是首先dump热点线程/方法)。
如何发现此类问题呢?通常的做法是监控GC频次及GC耗时;发现了此类问题如何定位呢?网上此类问题的文章比较多,总结分析下来就是要定位出两个事情:
- 哪些非预期的对象大量占用了内存
- 这些非预期的对象是在什么地方构造出来的,即定位出哪块代码出的问题(当然有的时候通过第1步的对象就可以确定对象是由哪块代码初始化的)
进一步思考,是否可以在发现此类问题的时候,就能够将非预期的对象和分配该对象的线程栈展示出来,即将事后的定位分析前移到事中,变成一种常规的运维方式,以提高问题发现和定位的效率,节约研发人员的时间。
下面内容从此类问题发现和定位两个方面进行思路的总结。
发现(事中)
需要一种低开销的可编程的实时分析对象分配的方式,几种实时分析对象分配的方式如下。
字节码增强方式
HeapTracker
JDK提供的DEMO,总体思路:
- HOOK JVMTI_EVENT_CLASS_FILE_LOAD_HOOK事件,插入调用HeapTracker的字节码;
- 在创建对象的时候,通过插入的HeapTracker字节码完成对象分配的监控逻辑。
详情可参考:https://heapdump.cn/article/5484283
google allocation-instrumenter
Allocation Instrumenter是一个使用Java .lang.instrument API和ASM编写的Java代理。Java程序中的每个分配都是工具化的;在每个分配上调用用户定义的回调。
纯JAVA开发的agent,支持指定类对象分配的监控,应用启动时候需要指定-javaagent:path/to/java-allocation-instrumenter-3.3.1.jar,不支持attach方式。
使用方法:
<dependency>
<groupId>com.google.code.java-allocation-instrumenter</groupId>
<artifactId>java-allocation-instrumenter</artifactId>
<version>3.3.1</version>
</dependency>
import com.google.monitoring.runtime.instrumentation.AllocationRecorder;
import com.google.monitoring.runtime.instrumentation.Sampler;
public class Test {
public static void main(String [] args) throws Exception {
AllocationRecorder.addSampler(new Sampler() {
public void sampleAllocation(int count, String desc, Object newObj, long size) {
System.out.println("I just allocated the object " + newObj
+ " of type " + desc + " whose size is " + size);
if (count != -1) { System.out.println("It's an array of size " + count); }
}
});
for (int i = 0 ; i < 10; i++) {
new String("foo");
}
}
}
详情:https://github.com/google/allocation-instrumenter
JVMTI SampledObjectAlloc
SampledObjectAlloc是在JDK11引入的,在功能和性能上是一个比较好的选择,可惜的是JDK8不支持,而JDK8 JVMTI VMObjectAlloc并不能完全覆盖对象分配的场景。
详情:https://heapdump.cn/article/5494193
定位(事后)
【发现(事中)】的字节码增强方式对系统性能影响较大,如果不能实现【发现(事中)】阶段的问题定位,那么需要总结下【定位(事后)】的一些套路,目的是以便捷、低代价的方式定位出问题。
下面代码示例模拟的是应用程序每隔一段时间创建大量对象:
package allocate;
import java.lang.management.ManagementFactory;
import java.util.LinkedList;
import java.util.List;
public class StackTest {
private byte[] test;
public StackTest(){
this.test = new byte[1024];
}
public static void main(String[] args) throws Exception{
System.out.println(ManagementFactory.getRuntimeMXBean().getName());
while (true){
Thread.sleep(1000L);
a();
}
}
public static void a(){
b();
}
public static void b(){
c();
}
private static void c(){
List<StackTest> list = new LinkedList<>();
for (int i = 0;i<100000;i++){
list.add(new StackTest());
}
}
}
定位内存占用高的对象
当出现此类问题的时候,直接dump整个JVM代价比较高,某些场景下并不是一种高效的处理方式。
遇到此类问题的时候可以先使用jmap -histo看看哪些对象占据内存比较多,有些时候通过这些对象就可以定位是在什么逻辑的地方分配了这些对象:
如果不熟悉业务逻辑,或者一些对象并不属于业务对象则可以借助一些工具进行业务逻辑相关代码定位。
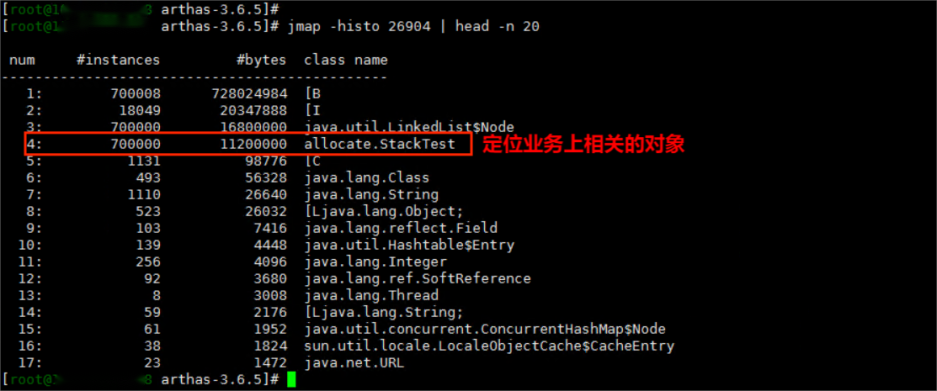
定位分配对象的逻辑
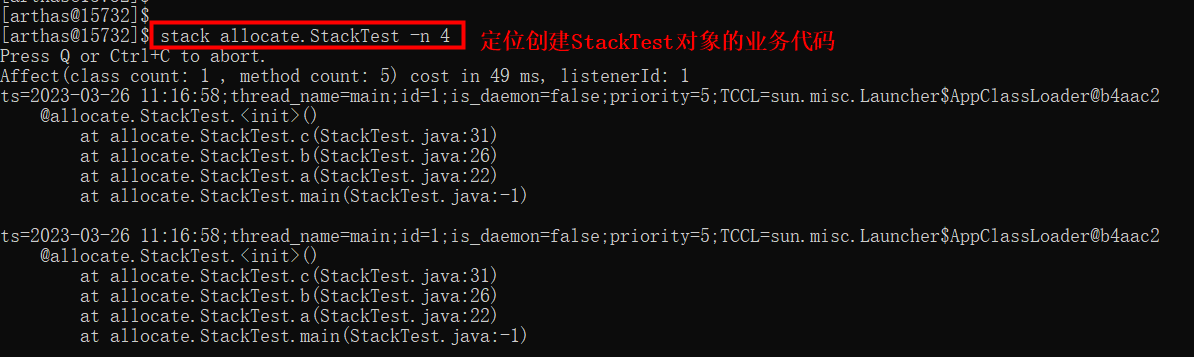
当我们通过jmap -histo发现有大量StackTest对象创建,如何定位创建StackTest的业务代码呢?可以通过两种方式:
arthas stack
通过arthas stack定位创建StackTest对象的业务代码。
arthas profiler
有的时候通过arthas stack并不好定位,比如分配了大量byte[]等对象类型的逻辑,此时可以使用arthas profiler进行分析。
profiler start --event alloc:
查看生成的profiler文件:
此处profiler主要用来进行故障排查,当然也可以用在性能分析优化的场景。


heapdump memory
如果以上轻量级的排查方式还是不能定位问题,可以考虑使用jmap -dump:format=b,file=heapDump <pid>的方式将内存dump下来,然后使用MAT等工具进行分析的方式。
分析dump内存文件的文档比较多,这里就不再做介绍了。
总结
- 期望能够在发现问题的时候就能够给出产生问题的原因,以提高故障排查效率
- HeapTracker、google allocation-instrumenter、JVMTI SampledObjectAlloc提供了监控对象分配的方式,需要根据具体场景来应用
- 事后分析的套路是:定位异常对象->定位异常对象分配线程,实在不习则需要分析内存dump文件来进行定位。


