
证明CPU指令是乱序执行的原创
承接上文CPU缓存一致性原理
双击QQ.exe从磁盘加载到内存里面,内存里面就会有了一个进程,进程产生的时候会产生一个主线程,就是main方法所在的线程,cpu会找到main开始的地方,把它的指令读取过来放到程序计数器,把数据放到寄存器,然后ALU开始做计算,一步一步来执行整个程序,这就是普通程序执行的过程。
cpu速度要比内存的速度快100倍,中间有各种各样的缓存,最常见的是三级缓存,由于它的速度非常快,在执行指令的时候也会有一些优化,比如现在有2条指令,一个是mov指令即从内存中读取一个数据到某一个寄存器中,第二个指令是把寄存器中的指令数值加1,如果严格按照前后写的效率执行,会发现它的效率比较低;第一条指令从内存中读数据出来,cpu等待99个时间周期,如果读完第一个指令之后,才可以执行第二个指令的话,cpu将会有99个空档期,所以现在的cpu设计是流水线式的设计(采用流水线式后,并没有加速单条指令的执行,每条指令的操作步骤一个也不能少,只是多条指令的不同操作步骤同时执行,因而从总体上看加快了指令流速度,缩短了程序执行时间),发送一条指令在等待内存数据返回的过程当中,会把后面这条指令执行了即后面的指令跑到前面先执行了,简单称为cpu的乱序执行,主要是为了提高效率,在等待费时的指令执行的时候,优先执行后面的指令。
证明cpu乱序执行是存在的
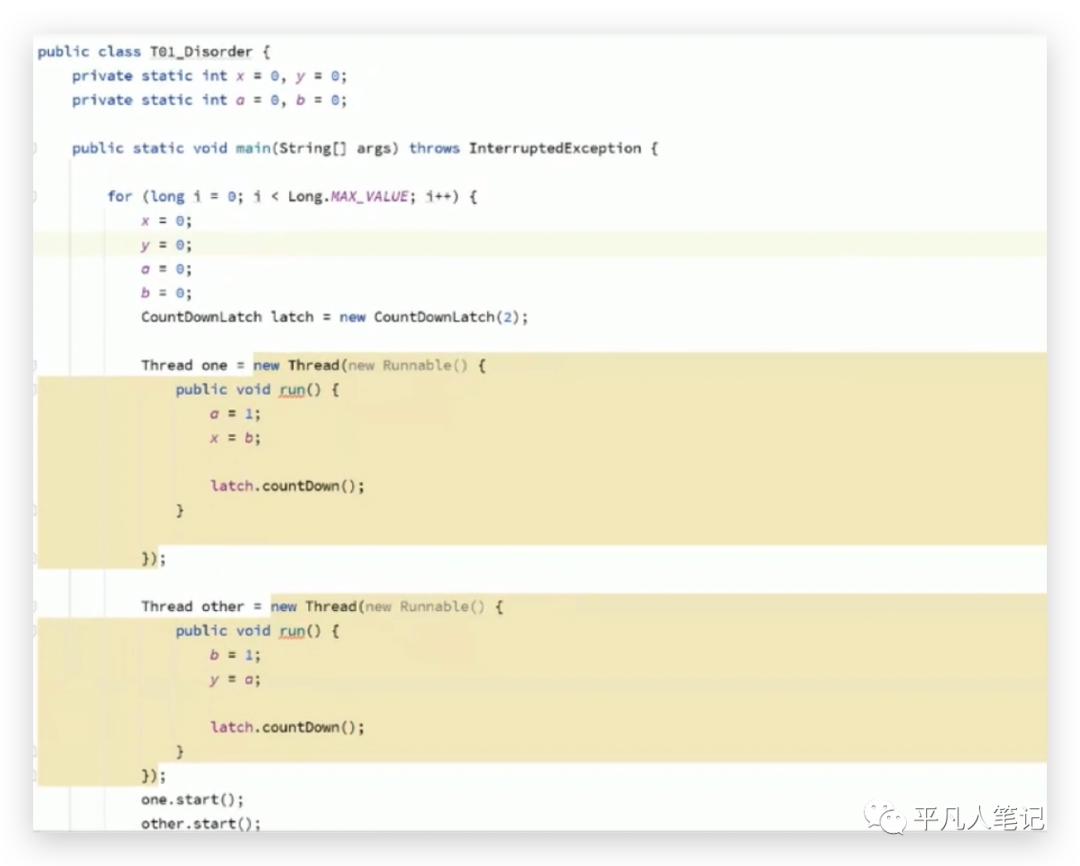
这里有个死循环,每一次循环都会把这4个值(x、y、a、b)设置为0,每一次循环都会起2个线程,第一个线程会执行a=1、x=b,第二个线程会执行b=1、y=a;假设所有的语句都是按照顺序执行的,从多线程微观的角度进行时间顺序上的排列组合,你会发现会有各种各样的组合场景:

比如第一种组合,

第一种组合先执行a=1、x=b,后执行b=1、y=a,得到的结果是x=0、y=1。
这6种排列组合的结果无论如何都不可能得到x=0、y=0的情况即只要按照顺序执行,绝对不会出现x=0、y=0。
这是数学上的排列组合,但cpu执行指令的时候未必是按照顺序执行的。
出现x=0、y=0的情况比较少见,为什么这么难出现?什么样的组合下才会出现?

跑了270多万次才出现了一次x=0、y=0的情况,
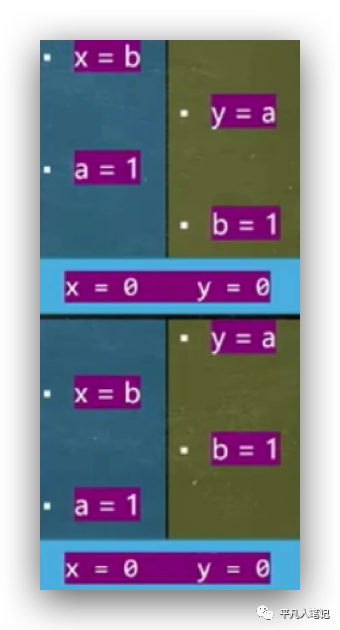
这两种是乱序执行的排列组合,比如第一个场景是线程1先执行x=b、线程2执行y=a,切换到线程1执行a=1,切换到线程2执行b=1,结果是x=0、y=0。
只有这2种场景,2个线程的这2个指令都得颠倒顺序才会出现,这种很难出现,不管怎样,得出一个结论:cpu内部是乱序执行的。
单线程的情况下,2个指令乱了顺序执行没有关系,反正最终的结果是一样的,但是在多线程的情况下,非常有可能出现你不想看到的情形,比如x=0、y=0的情况,比如在预知中没有这种情况,但是多线程的情况下,会出现,所以一定会影响整个多线程程序的运行,单线程的程序不会影响。
有了as-if-serial(看上去像序列化的)指令就可以随便变换顺序,只要维持最终一致性即可;单线程的重排序只需要保证最终的一致性,比如a=b、y=1,随便重排序,只要能保证单线程的最终一致性。

