
CPU缓存一致性原理原创
承接上文线程的执行
cpu速度和内存速度比值,目前比值是100:1的关系,一个做计算的,一个做存储,相互之间怎么比速度?
这个速度是指:cpu内部的ALU计算单元访问内部的寄存器,如果耗时是1个纳秒,计算单元通过数据总线去访问内存需要100纳秒,这个速度是指访问某个寄存器的速度并不是计算的速度,ALU访问寄存器的速度比访问内存的速度快100倍。
为什么ALU访问寄存器的速度快,因为ALU和寄存器离的近。
内存中有一个数组,访问数组中第一个元素数据需要100纳秒,访问第二个数据100纳秒,所以cpu至少有99个时间单元都得等着从内存中返回数据给ALU使用。
为了充分利用cpu的速度,一般往往在中间设计缓存的存在,cpu访问缓存的速度比访问内存的速度要快。
访问数组中第一个数据的时候,把整个数组放到缓存中来,下次cpu访问的时候从缓存中访问。
不要内存完全可以,但工业上需要考虑一个性价比,数据都放在寄存器中太贵了,8个G的内存400块钱,8个G的寄存器40万,寄存器稍微贵一点点的、容量稍微小一点的还可以承受,比如8个G的内存,1个G的寄存器。
不是所有的数据都放在寄存器中,在这里有专门的算法LRU(Least Recently Used 淘汰最近未使用的)或LFU(least frequently used淘汰不经常使用的),这个算法决定着什么样的数据挪过来,什么样的数据挪出去。
缓存是均衡的设计,在省钱和读取、写入的效率之间均衡。加了一层缓存之后,发现cpu到这个缓存之间的速度还是慢很多,再加一层,
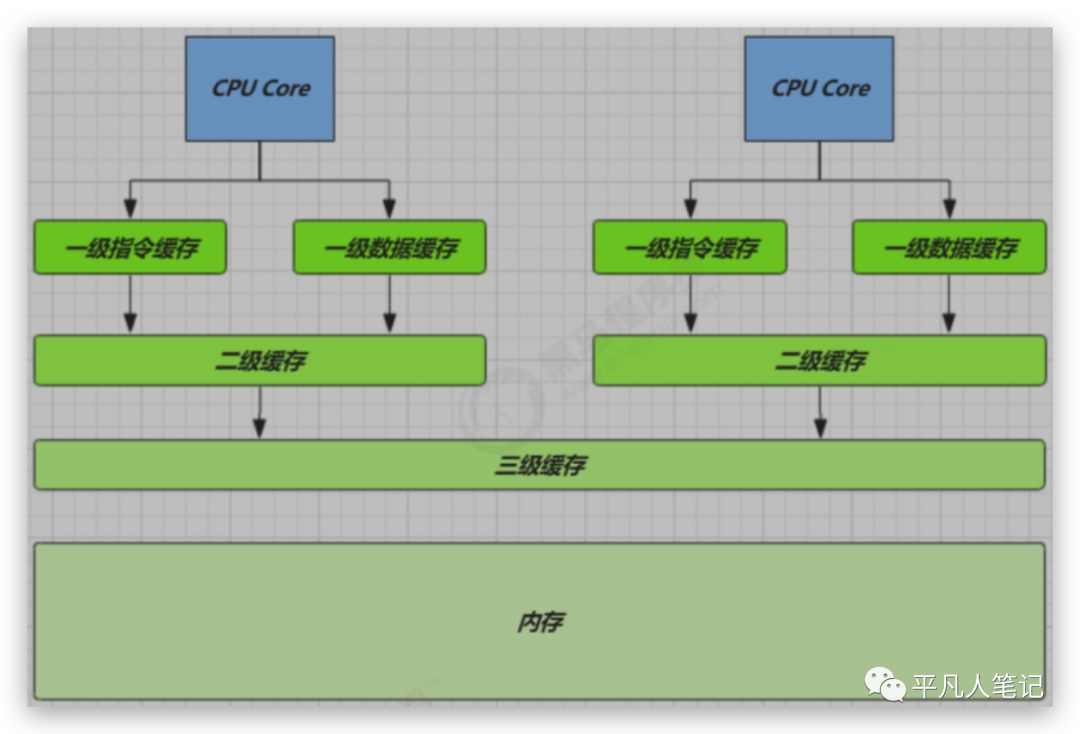
三级缓存是工业实现中的一个妥协,也许不久的将来,cpu的速度超级快,可能需要四层缓存或内存的速度快很多,也许就一层缓存,目前的工业实践,多采用三级缓存的结构。
线程和cpu之间的关系密不可分,一颗cpu在同一个时间只能执行一个线程,cpu的计算也代表着线程的计算。
多核CPU
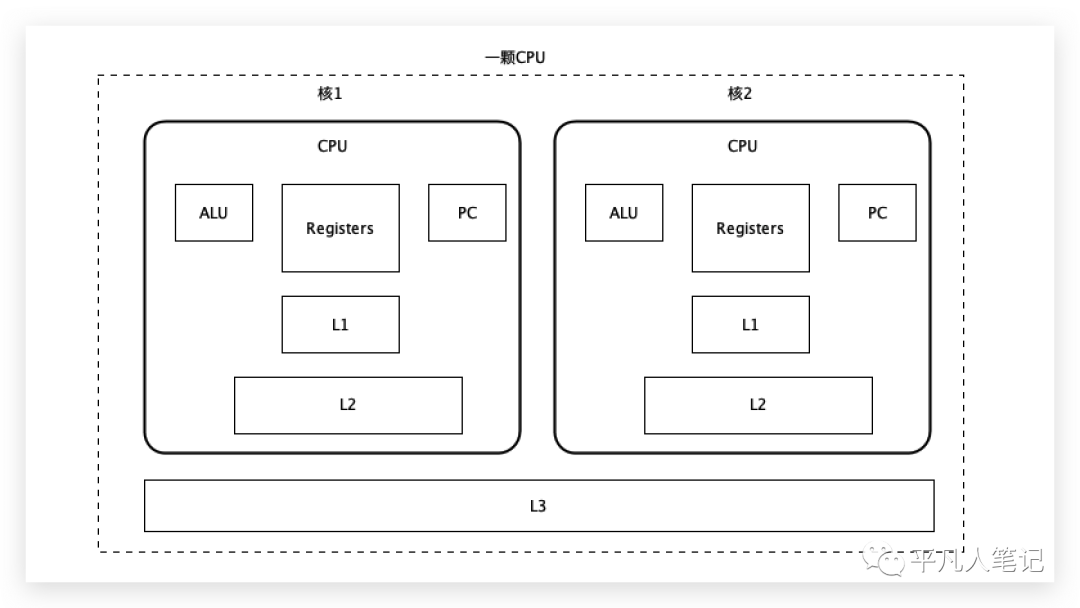
这是一颗cpu,在cpu内部往往有多个核存在,每一个核都有自己的ALU、寄存器、程序计数器,一级缓存和二级缓存都在这个核里,三级缓存是多个核共享。
ALU的计算单元需要把读到的数据放到寄存器,寄存器会去寻找想要的数据,首先去一级缓存找,没有的话,再去二级缓存找,还没有的话,再去三级缓存找,三级缓存把数据传给二级缓存,二级缓存把数据传给一级缓存,一级缓存把数据传给寄存器,下一次再访问数据的时候直接去一级缓存中拿。
超线程
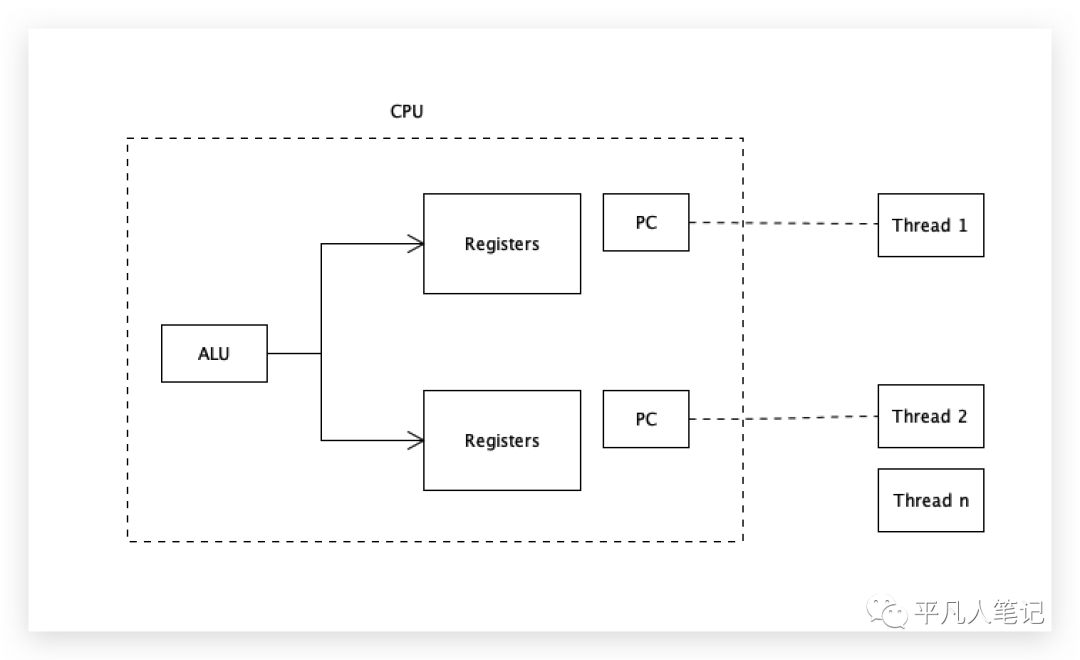
虽然只有一个计算单元ALU,但是有2套存储单元、2套寄存器、2套程序计数器,一个核可以装2个线程的数据进来,计算单元轮着计算,2个线程就不需要来回切换了,即一个核2个线程,2个核4个线程,4个核8个线程。
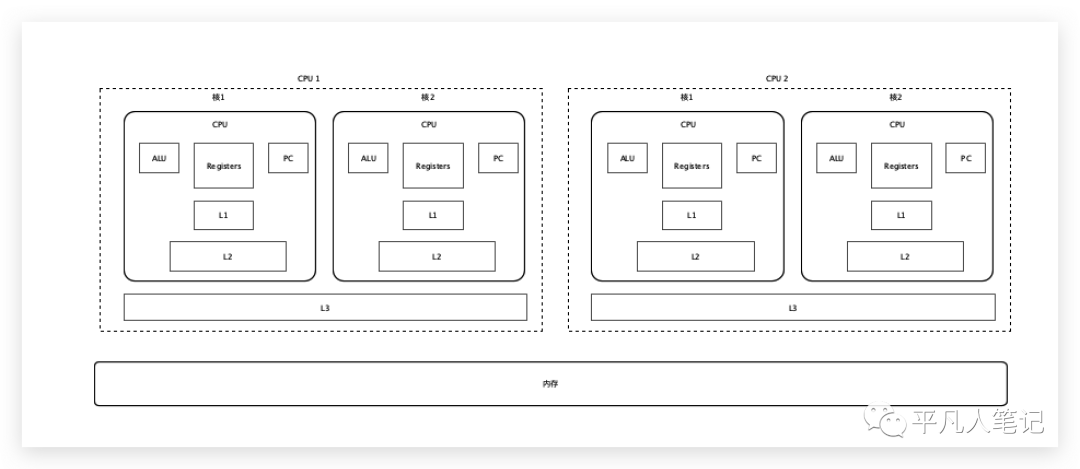
需要访问内存中某个数组中的第一个元素数据,先在一级缓存找,再找二级、三级,都没有的话,去内存中找,内存中找到之后,返回给三级缓存、二级缓存、一级缓存,最后再给到寄存器, ALU做计算的时候就可以直接访问寄存器获取数据了。
站在计算单元的角度,访问数组中第一个元素数据很可能会访问第二个元素数据,如果第二个元素数据也没有,同样的方式又得来一遍,那这样的话还不如直接从内存读呢!
缓存行
当要访问一个数据的时候,干脆每一次缓存一小块的数据,这一小块数据里面包含了整个数组的数据,当访问数组中的任意元素数据的时候,就可以直接从缓存中读取到了,这一块的数据被称为缓存行。
这个理论被称为程序的局部性原理,而局部性原理分为空间局部性和时间局部性。
根据大多数工业证明,在访问局部数据的时候,会很快的访问相邻的数据,这就是空间局部性。
时间局部性是执行完这条指令之后,很可能执行和它挨着的下一条指令,如果指令也看做是一份二进制0101数据的话,也可以一次性的把很多指令读取过来。
缓存行数据是大了好还是小了好?
如果这一行数据特别大,一次性可以放好多数据过来,好处就是访问的时候命中率会更高,但是每读一块数据过来效率会很低;数据小的话,读起来速度会很快但命中率会较低。
目前计算机多采用64个字节(64*8bit)为一缓存行数据。
缓存行对齐,伪共享
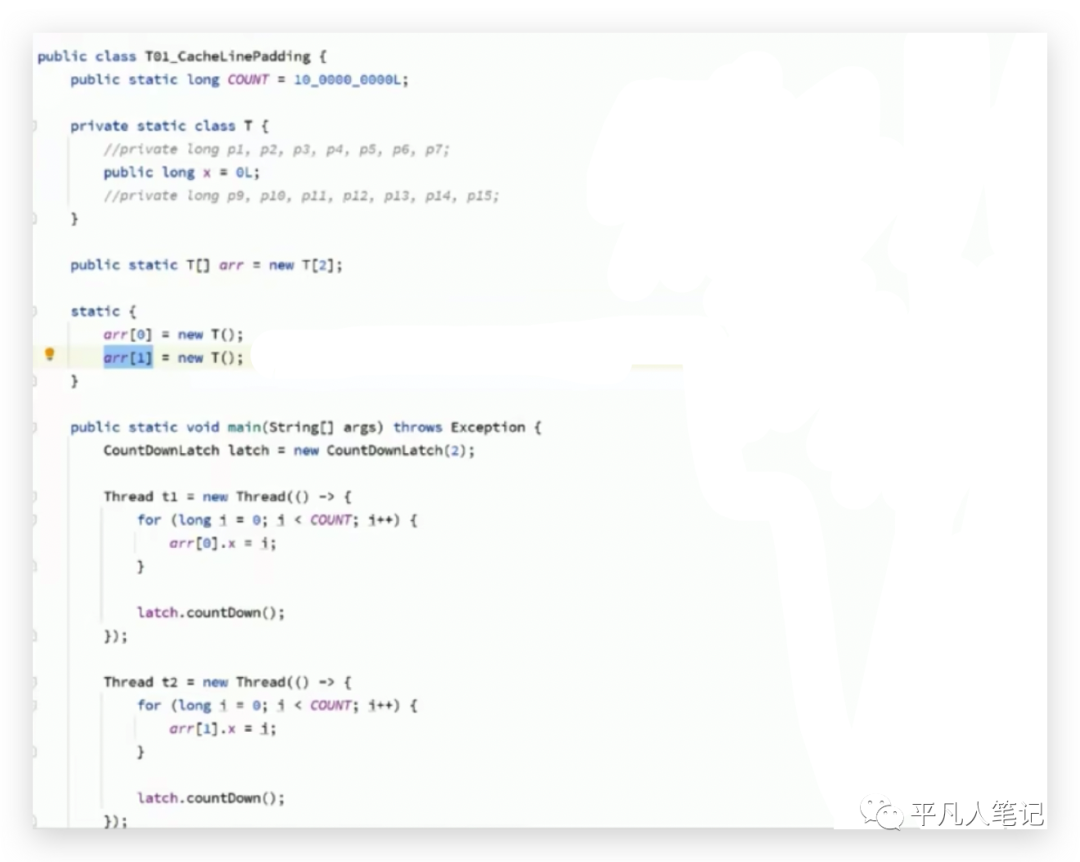
创建一个数组,里面存放了2个T类对象元素,T类中有一个long类型的x字段,long类型长度是8个bytes。
2个线程,意味着有2颗cpu在同时运行,第一个线程玩命的修改数组中的第一个元素t1,改了10亿次,第二个线程玩命的修改数组中的第二个元素t2,也改了10亿次,总共耗时700多毫秒。
对T类做了修改,

因为一个缓存行大小为64字节,所以在属性x前面加了7个属性(7*8字节=56个字节),加上x共64个字节,x后面也加了56个字节,正好将一个x值,放在一个缓存行里,计算结果耗时240多毫秒,数据越多执行效率反而越高了。在介绍原理之前,先介绍下缓存一致性协议,
缓存一致性协议
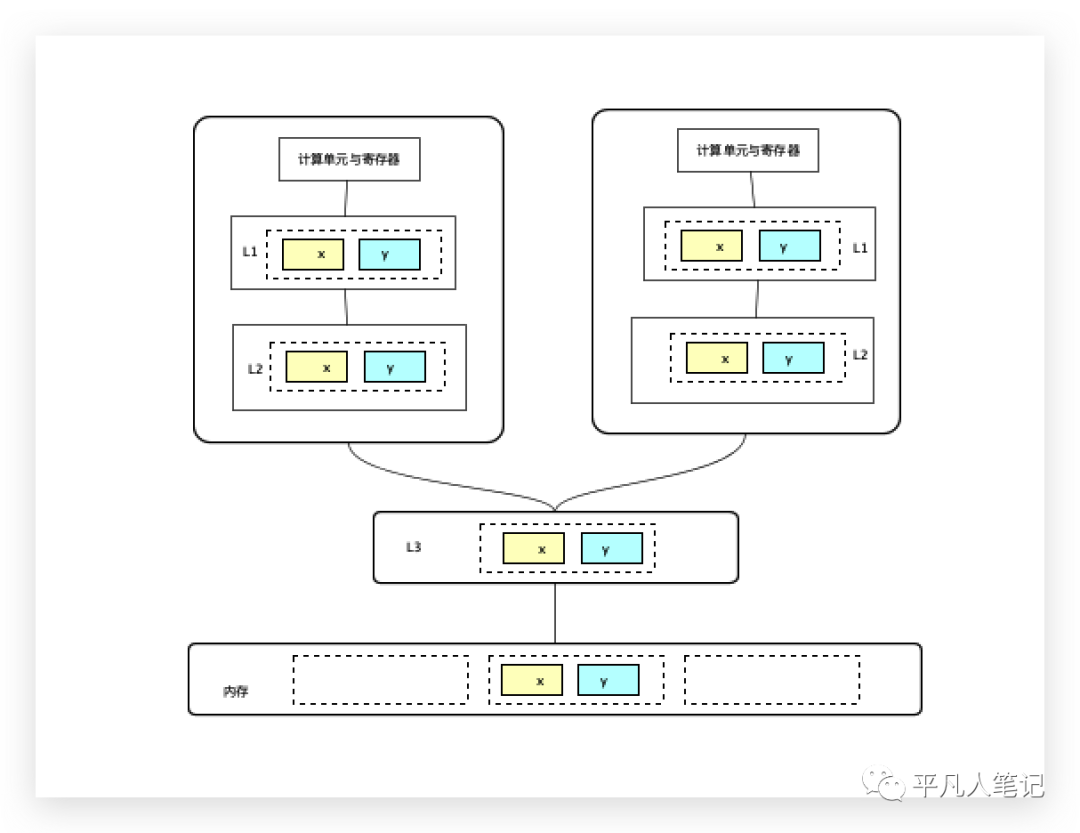
假设有2个数据x、y位于同一缓存行,在第一个计算单元(cpu或线程)里面只使用了x,第二个线程里面只使用了y,虽然在内存中是同一份数据,但是到缓存之后,是2份拷贝数据,每一个用到它的cpu都会有它的一份拷贝存在,一个cpu对这份数据做了修改之后,另外cpu也需要同步到最新的数据。
有了缓存的概念,必须要保证缓存的数据一致性即缓存一致性协议,每种cpu厂商都有自己完全不同的缓存一致性协议,常见的是MESI(因特尔的缓存一致性协议),这是缓存一致性协议的一种实现。
cpu每个缓存行标记有4种状态:Modified(被修改),Exclusive(独占)、Shared(共享)、Invalid(无效)。
一个cpu将一个缓存行中的数据修改了,需要一种机制:通知使用该缓存行的其他cpu数据已失效,需要重新再读取一遍,获取最新修改的数据。
有些无法被缓存的数据,比如一份的数据超过了64个字节,则需要使用总线锁。
再回到上面的那个问题,为什么数据越多执行效率反而越高了?
一个long类型的x是8个字节,这2个x位于同一个缓存行的概率极大(尤其这2个x位于同一个数组,在内存中是挨着的),2个cpu分别修改一个x,2个x在一方cpu都有缓存,修改了其中一个需要通知另外一个,每改一次通知一下,总之在修改的时候需要触发一种机制需要另外的cpu跟我保持一致,如果这样的话,耗时当然会比较长。
在x前后加56个字节,无论怎么刷新缓存,这个x都不会和另外一个x位于同一缓存行,这意味着这个cpu修改了第一个x的时候,是不需要通知任何其他cpu的,第二个cpu修改第二个x的时候,也是不需要通知第一个cpu的,速度一定会很快。
jdk 7写的LinkedBlockQueue也是这种写法或者获得杜克奖的开源软件Disruptor中的环形队列也是这种写法,
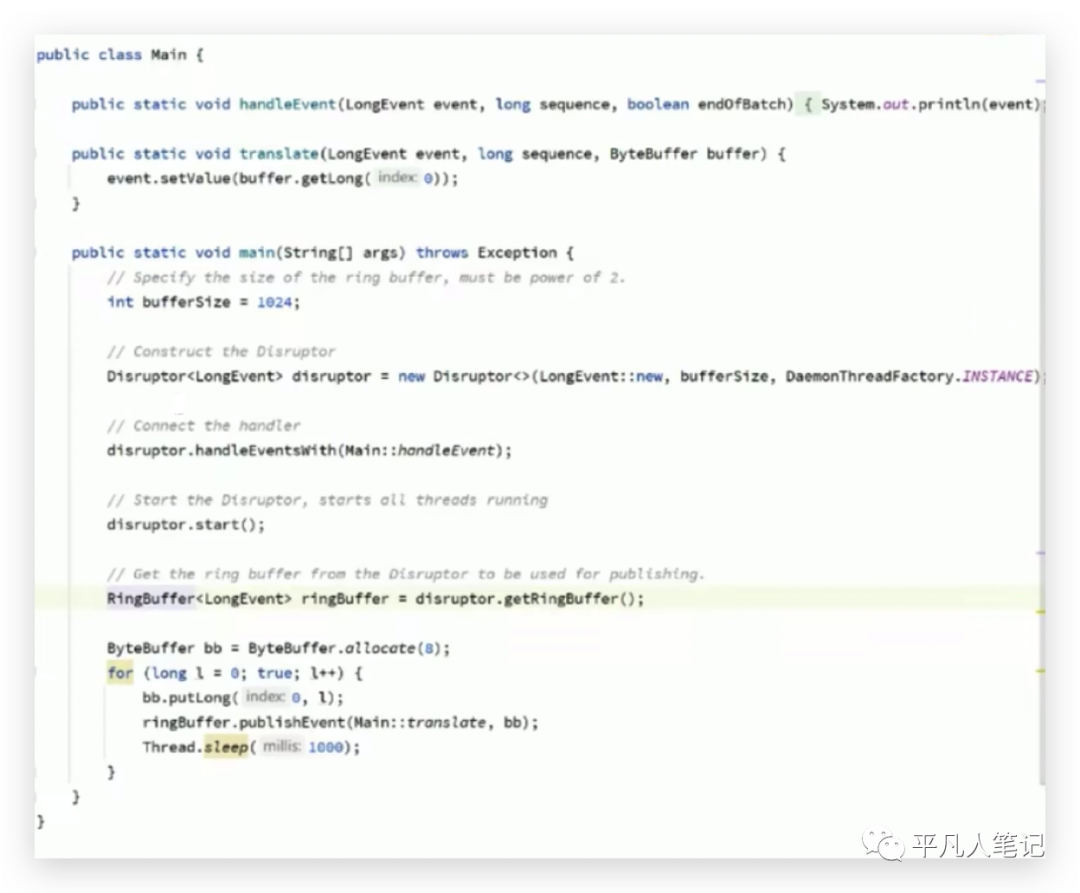
Disruptor(环形队列)号称是最快的单机mq;实现链表一般需要2个指针,一个是头指针,一个是尾指针,而这个环形队列,只要有一个指针就可以了,
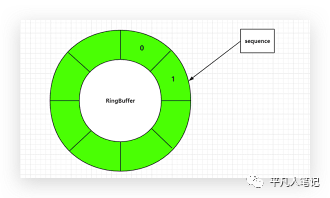
指针指向这个位置就往这存,指向下个位置就往下一个位置存,什么时候存满了,就等着最开始存的那个被消费走,消费走了继续往这里存,一个指针来回转,速度非常快。
由于有多个生产者和多个消费者,在多线程的情况下这个环形的指针就会被多个线程读到自己的缓存里,
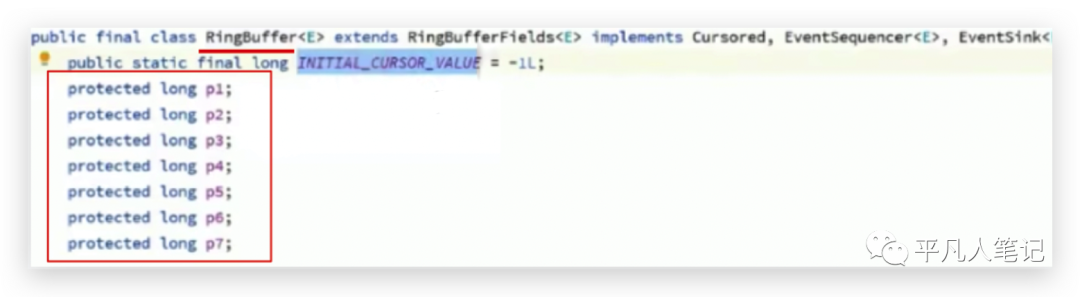
第一个属性是起始值,后面是7个无业务含义的数据,其存在的目的是可以保证p1属性往后组合的时候不会和别的p1属性位于同一个缓存行。
但是说不准会往前面组合呢即为什么没有前面的7个呢?也是有的,在父类的父类中定义的,
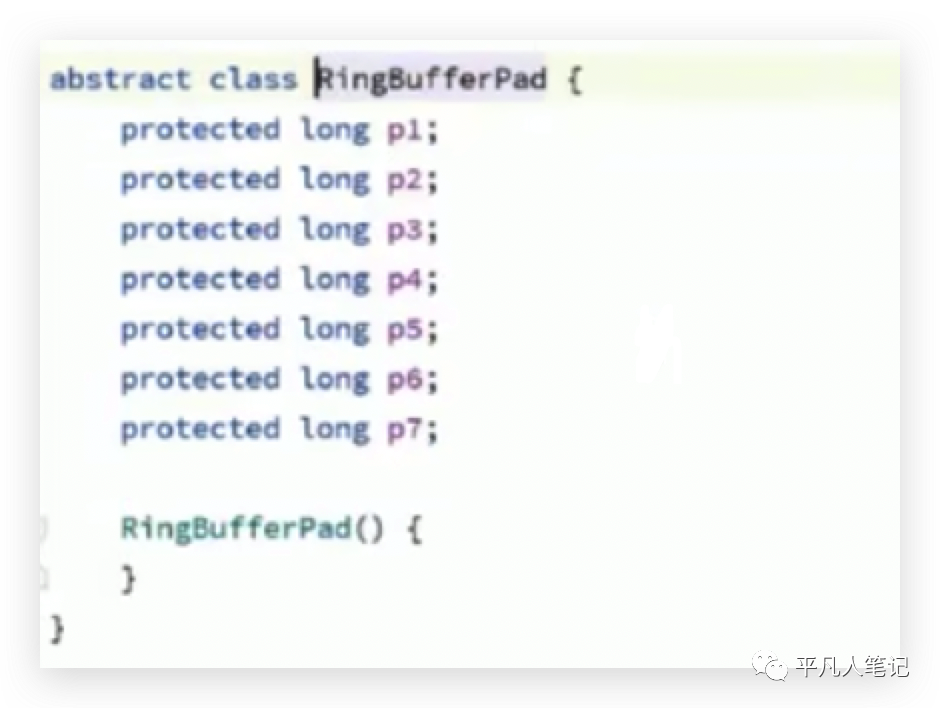

数组中前连续的2个元素是2个RingBuffer对象,一个对象所占用的字节57+8+56,所以可以确保一个缓存行中只有一个元素,那么在多线程的情况下对不同元素的修改不会互相通知,互相影响。
以上便是cpu级别的并发控制之缓存一致性的描述。

