
并发之道:三大问题与JMM 何干?原创
笔者曾经历过数据规模(每天)在万亿级的监控系统、近百亿级的链路追踪系统、亿级的网关系统、千万级的短信系统、千万级的网络电话系统等诸多高并发系统的建设,在高并发系统的架构设计、开发实现、加固调优方面有少许经验积累~
一、背景
1.1 冯·诺依曼结构的局限性
现代计算机发展所遵循的基本结构形式始终是冯·诺依曼结构,这个结构存储程序的方式造成了系统对存储器的依赖,受制于存储元件的速度、存储器的性能和结构等诸多条件的约束,CPU + 存储器( 内存和硬盘) 这个三剑客组合已保持好多年未变,并且它们之间的速度相差很多,但 CPU 与存储器间信息交换的速度一直是影响系统性能的主要因素。
1.2 破局
若要提升信息交换的速度,就需要解决 CPU、内存、硬盘之间的速度差异问题。计算机体系结构、操作系统、编译程序等各自发力提供了解决方案:
-
操作系统通过增加进程、线程,分时复用 CPU,均衡 CPU 与 IO 设备之间的速度差异 -
CPU 通过增加多级缓存,均衡与内存之间的速度差异 -
编译程序和处理器通过优化指令顺序,使得运行效率更高
从发展史看,降低速度差异的改进其实很多,配合本篇并发问题探索的需求,仅关注这三味良药;有所得则必有所失,这三味良药也分别带来了副作用,也即今天要探讨的并发的三大问题。
二、并发的三大问题
2.1 原子性问题
原子即整体不可分割,原子性操作是由 CPU 指令来保证的,执行一个或一组指令完成原子操作的过程中,CPU 不能被中断;但在操作系统分时复用 CPU 的机制中,指令与指令之间可以发生中断,CPU 指令集中提供的不中断的原子操作特别少,根本无法满足应用层原子性逻辑操作的多样化诉求。
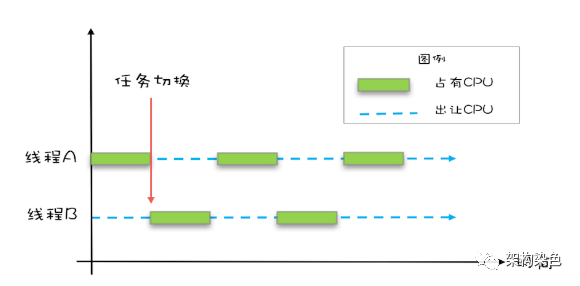
分时复用CPU(来自网络).png
2.2 可见性问题
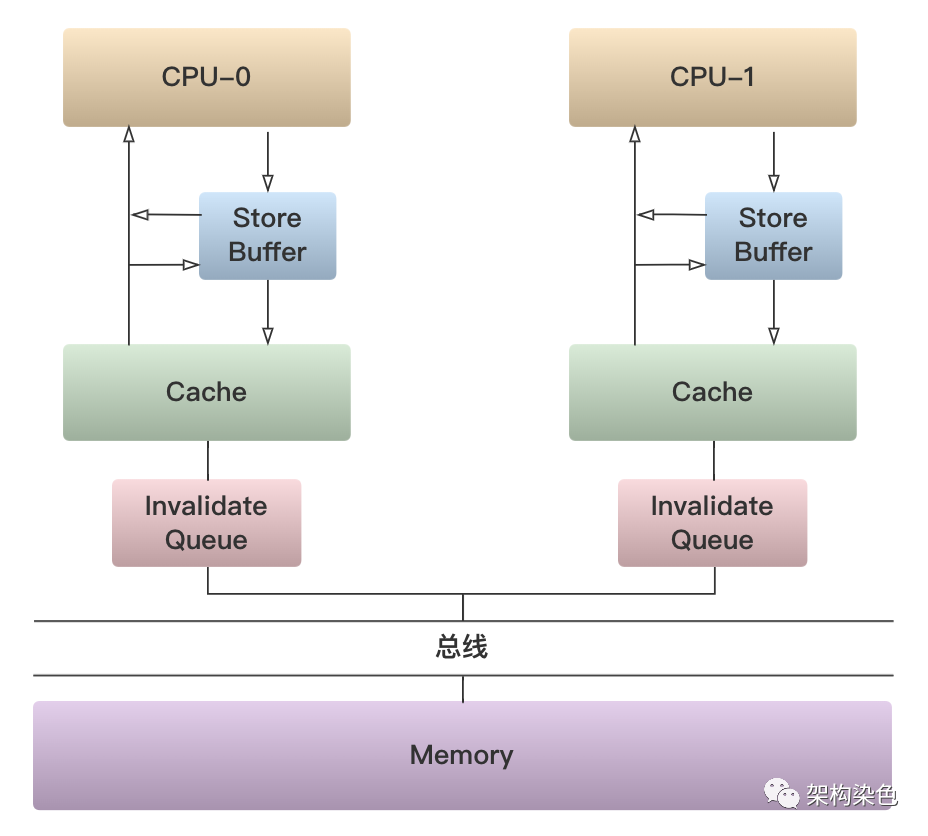
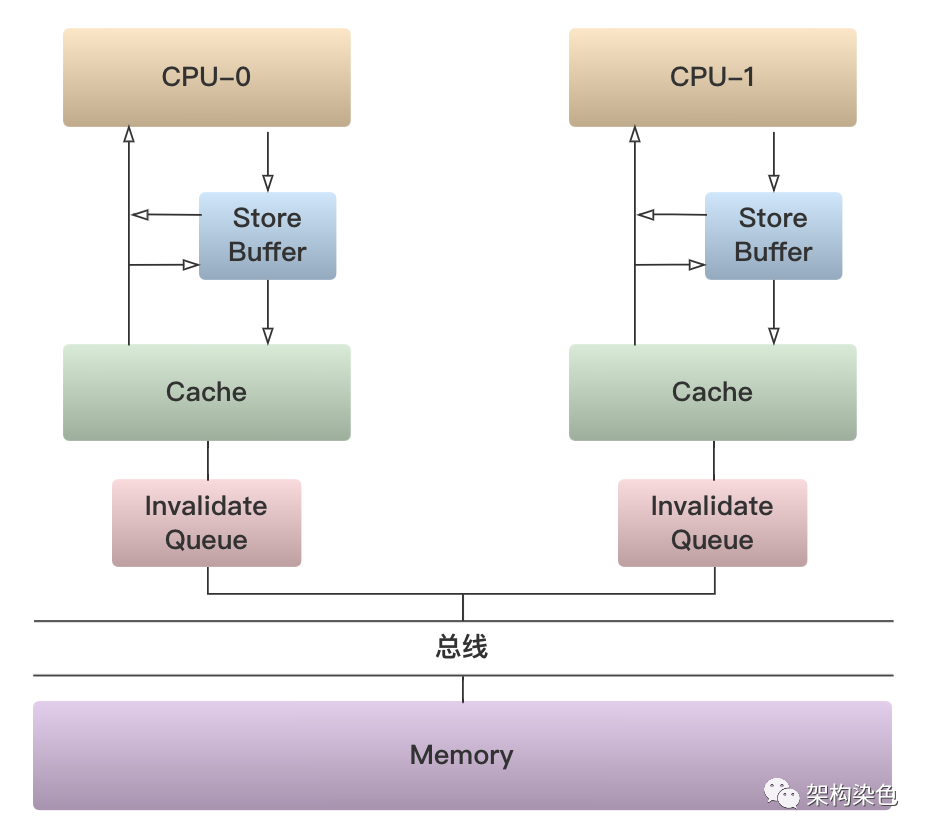
程序要运行,就会将数据从内存加载到 CPU 缓存,或者将数据从 CPU 缓存存储到内存;SMP 对称多处理器架构中,基于总线嗅探机制衍生了多种不同的 CPU 缓存一致性协议,其中最常用的就是 MESI 协议。
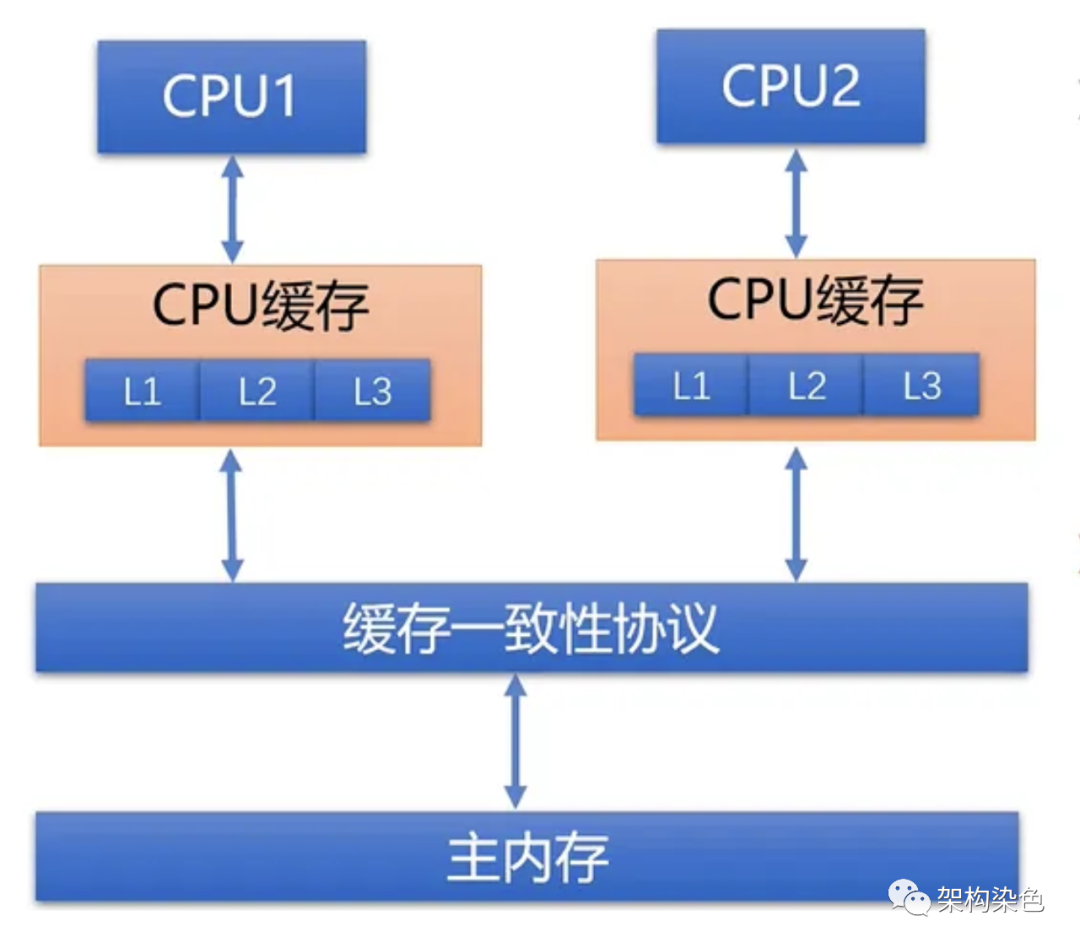
多级缓存架构的缓存一致性机制(来自网络).png
虽然看起来 MESI 提供了缓存一致的能力,但需注意 MESI 在实现缓存一致性时加入 Store buffer 和 Invalidate message Queue,通过异步处理来提升性能。所以从效果看缓存之间并非同步变更,这种最终一致的机制还是会导致缓存可见性问题。而有些场景下,应用程序需要的是立即一致或者说是按需一致。
2.3 有序性问题
为了提高性能、效率,编译器、处理器等常会对指令进行重排序。一般重排序可以分为如下三种:

-
编译器优化的重排序:编译器在不改变单线程的程序语义的前提下,可以重新安排语句的执行顺序
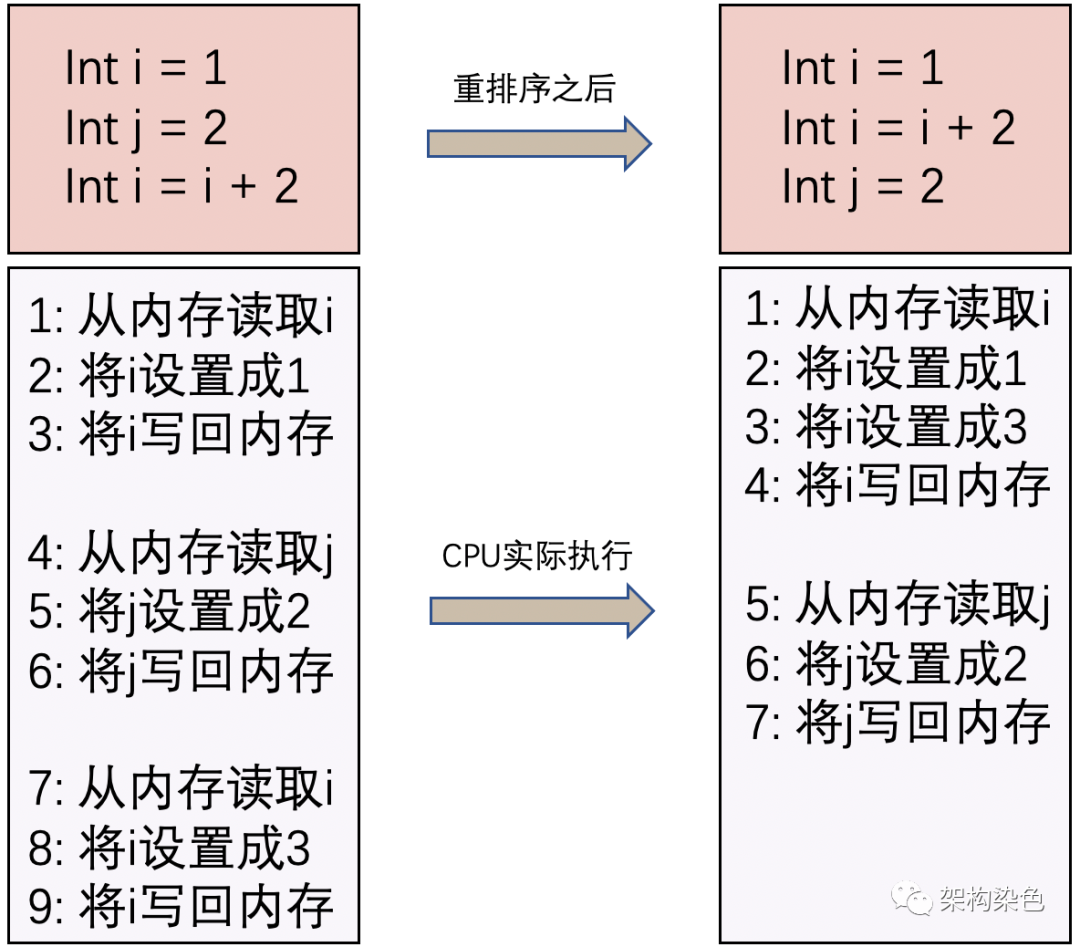
编译优化重排序(来自网络).png
-
指令级并行的重排序:现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序
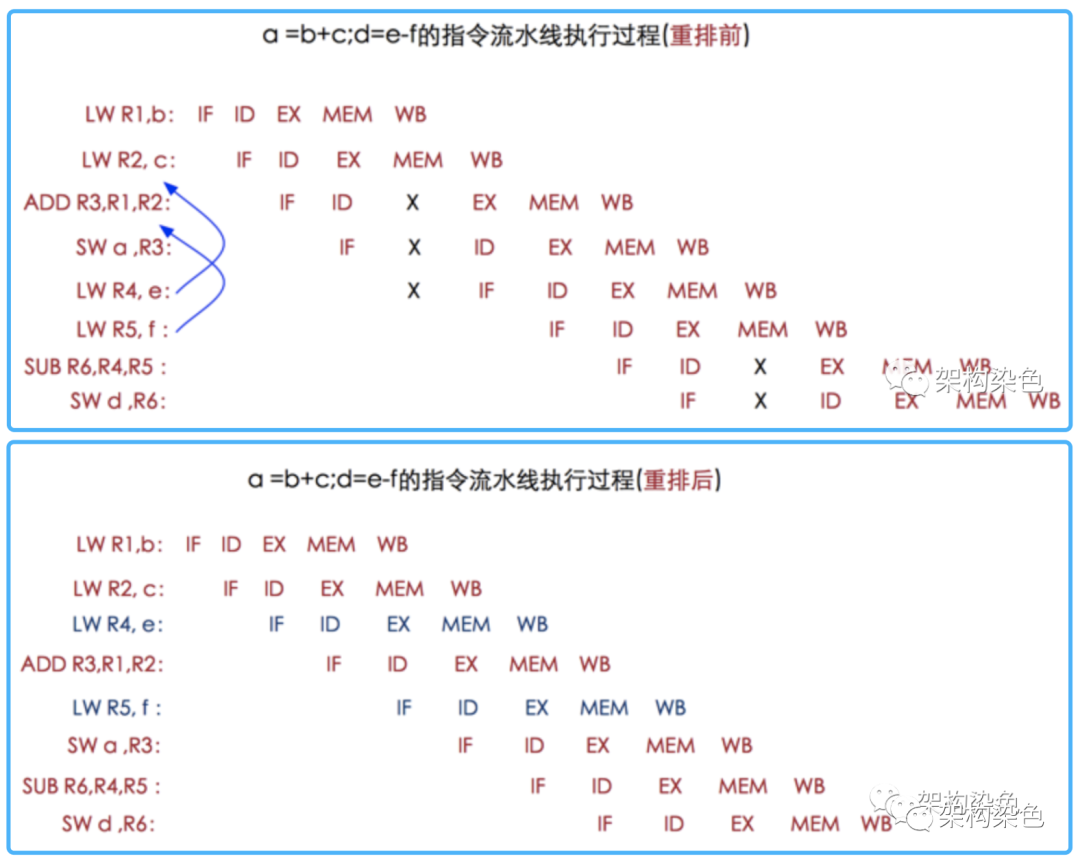
-
内存系统的重排序:由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行的
三、编程语言如何解决并发问题
3.1 提供多线程操控的能力
编程语言面对并发的三大问题,它所做的是对多线程的通信、同步机制进行包装,为开发者提供使用轻便、功能丰富的多线程编程 API。
3.2 选择合适的多线程通信、同步机制
-
线程间通信:线程间交换信息的机制 -
线程间同步:控制不同线程之间操作发生相对顺序的机制
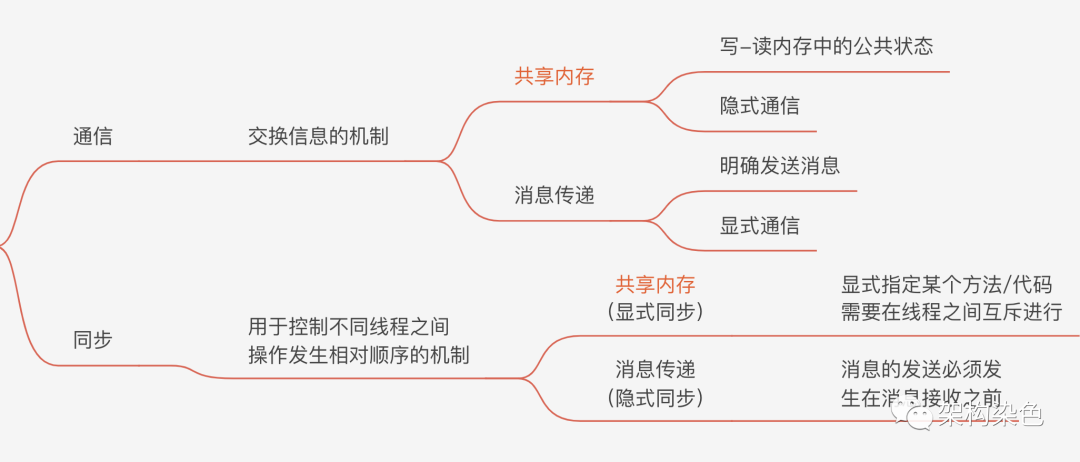
从上图可知,通过消息传递或者共享内存都可以实现线程间的通信、同步,不同的语言采用的方式可能不同,而 JAVA 采用的是共享内存的方式,似乎共享内存的方式开发者更容易理解。
三、Java如何解决并发问题
Java 是采用共享内存的方式来进行线程间的通信、同步,为了屏蔽各个硬件平台和操作系统对内存访问机制的差异化,内存模型(Memory Model)诞生了,而 JAVA 的内存模型就叫 JMM。
4.1 JMM-共享内存的抽象
JMM 以抽象方式约定了,共享变量会先放在主存中,每个线程都有属于自己的工作内存,并且会把位于主存中的共享变量拷贝到自己的工作内存,之后的读写操作均使用位于工作内存的变量副本,并在某个时刻将工作内存的变量副本写回到主存中去。
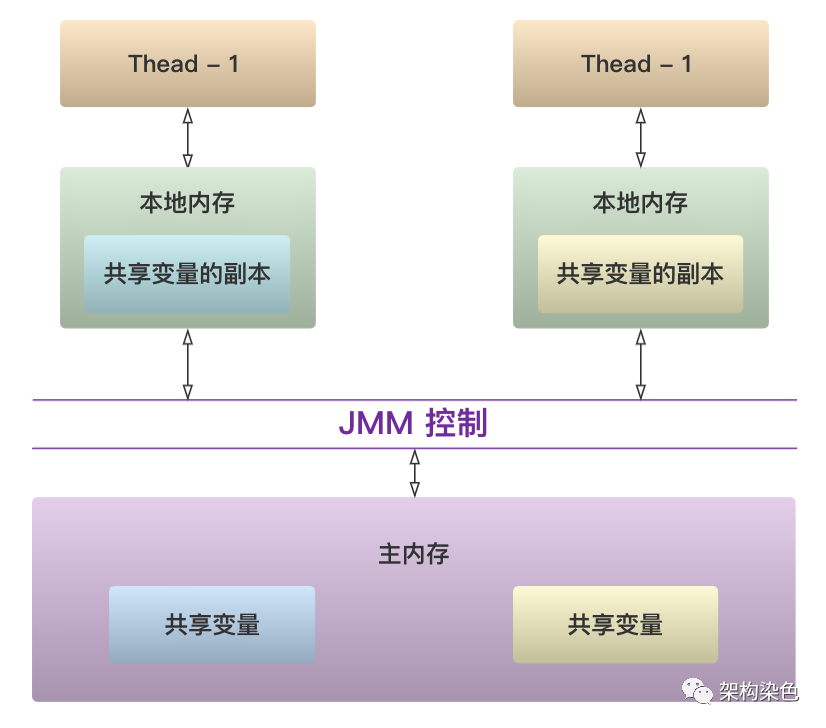
JMM内存模型的抽象结构示意图(来自网络).png
我曾疑惑许久 JMM 中的本地内存到底是啥?查阅的一些资料表明:本地内存是 JMM 中的一个抽象概念,并不真实存在;它涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化,这正是以抽象的概念来屏蔽底层实现的证明。
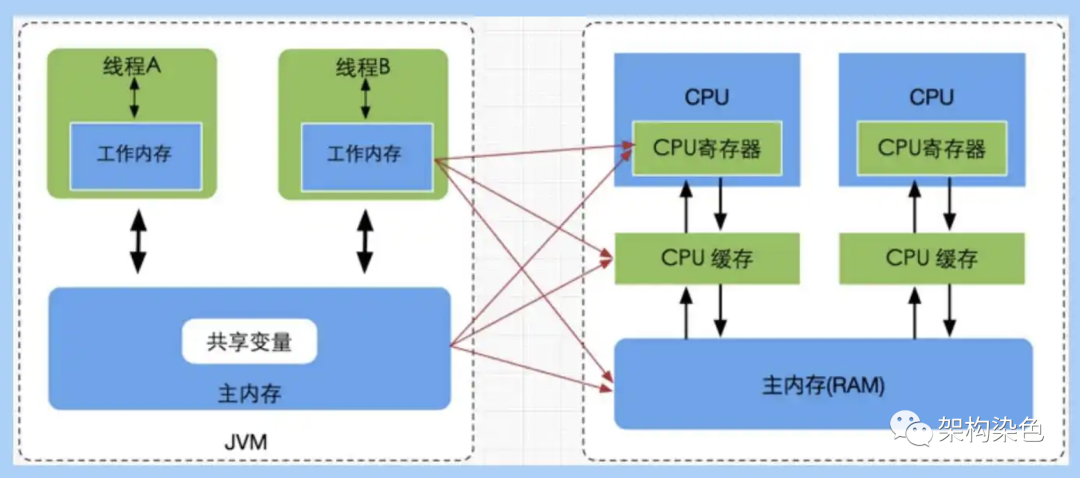
Java内存模型和操作系统内存模型的关系(来自网络).png
4.2 JMM 如何解决并发三大问题
这里需要特别注意,内存模型(MM)的工作目标是保证 内存一致性(Memory Consistency),而有了内存一致性的保证,自然就解决了可见性、重排序、原子性这些问题。了解一下 JMM 如何规范读写,就能明白这个因果关系:
-
有序的读写:不同地址上的读写操作在其他处理器看来不乱序(通过内存屏障来保障 ) -
写操作的原子性: 一个写操作是否同时被其他处理器观察到
这样的描述似乎不易理解,下边转换为面向编程的话术就是 JMM 规范了:
-
一个线程如何以及何时,可以看到由其他线程修改过后的共享变量的值 -
在必要时,如何以同步串行的效果访问共享变量
有序的读写还有这样经典的描述:
-
如果在本线程内观察,所有的操作都是有序的 -
这个描述是指,线程内表现为串行的语义(Within Thread As-If-Serial Semantics)) -
如果在一个线程中观察另一个线程,所有的操作都是无序的。 -
这个描述是指,指令重排序现象以及工作内存与主内存同步延迟的现象;指令重排序在任何时候都有可能发生,与是否为多线程无关,之所以在单线程下感觉没有发生重排序,是因为线程内表现为串行的语义的存在
四、总结
并发场景要解决好原子性问题、可见性问题、重排序问题。JAVA 很友好,多线程间通信、同步机制采用共享内存的方式,并且站在开发者的立场考虑问题,通过 JMM 屏蔽了复杂多样又难以理解的底层技术知识,以更亲民的方式提供给我们解决这些问题的规范和工具,让开发者只关注如何操作,而忽视底层的复杂实现。
要客观应对高并发场景,许多系统并非设计出来时便具备高并发的能力,而是在上线后根据实际请求、数据的分布情况,通过针对性的加固、调优反复打磨而成,比如全链路追踪系统 SkyWalking 的建设与实践,详情查看:《Skywalking on the way-千亿级的数据储能、毫秒级的查询耗时》。
后续笔者会不断将自己沉淀多年的高并发相关的知识整理输出,还望读者老师不吝指教。
如果这篇文章对您有帮助,或者有所启发的话,欢迎关注公众号【 架构染色 】进行交流和学习。您的支持是我坚持写作最大的动力。
参考:
Java 并发编程的艺术、Java 并发编程实战


