
善用算法和数据结构-如何写出高性能代码(一)原创
同一份逻辑,不同人的实现的代码性能会出现数量级的差异; 同一份代码,你可能微调几个字符或者某行代码的顺序,就会有数倍的性能提升;同一份代码,也可能在不同处理器上运行也会有几倍的性能差异;十倍程序员不是只存在于传说中,可能在我们的周围也比比皆是。十倍体现在程序员的方法面面,而代码性能却是其中最直观的一面。
“如何写出高性能代码”系列源自我在组内做的一次分享,本系列将以我个人之前的经验为基础,尝试帮助大家写出更高性能的代码 。原ppt分享的面有宽也比较浅薄,所以这里将原ppt拆分成5个独立的部分,分别成文,也作为对原ppt的扩展和补充,本文是第一篇——善用算法和数据结构。
荀子-劝学中说道:君子生非异也,善假于物也。其大意是君子的资质跟一般人没什么不同,只是善于借助外物罢了。 对于程序猿而已,我们在日常编码过程中,可能最常用的就是数据结构。现代各语言的开发库里基本上都封装好了各类的数据结构,我们基本不需要自己去实现。但错误地使用数据结构可能导致代码性能出现大幅的下降。
这里我举三个Java中因未考虑到底层实现导致性能损耗的示例。
上面这段代码本身功能上没有任何问题,但Java中ArrayList在添加过程中在容量不足时会触发扩容,扩容的过程会额外消耗CPU资源。但我在上述代码中指定了ArrayList的初始化容量为100后,用JMH压测发现有了33%的性能提升。
在Java中,很多容器都有动态扩容的特性,而扩容的过程涉及到内存的拷贝,很消耗性能。 所以建议如果能预知到数据量大小,在容器初始化的时候给定一个初始容量。这点在现在很多公司的编码规范中也明确提出了,如下图来自阿里巴巴Java开发手册。
再来看一个错误使用LinkedList导致的性能问题。
// jdk LinkedList中的get(int index)
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
// 这里会从前到后遍历链表
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
LinkedList并不受动态扩容的影响,但是它的底层实现是用的链表,而链表最大的问题在于不支持随机遍历,所以LinkedList中get(int index)的底层实现是用了遍历,时间复杂度是O(n),而ArrayList的底层实现是数组,它的get时间复杂度是O(1)。在上述代码中我将LinkedList改成ArrayList后压测确实也得到了十倍以上的性能提升。
在Java中,Set和List都提供了contains()方法,其作用就是校验某个在是否存在于这个集合中,但其contains实现方法完全不一样。在HashSet中,contains直接是从hash表中查找,其时间复杂度只有O(1)。而在ArrayList和LinkedList中,都是需要遍历一次全量数据才能得出结果,时间复杂度是O(n),代码这里就不再赘述,具体可以自行查阅。
在我实际测试是,Set和List的contains性能差异确实也非常明显。我用JMH测试发现,当有100个元素时,HashSet.contains的性能是ArrayList的10倍,是LinkedList的20倍,当数据量更大时,这个差异会更明显。
以上3个错误的示例其实在我们日常代码中经常会遇到,或许你现在去翻阅下项目代码,很容易就能找到List和Set使用不当之处。 也许你会反驳,JDK中这些Api的性能都极高,而且这部分也只是业务逻辑中非常非常小的一部分,错误得使用可能只会导致整体百分之一甚至千分之一的差异,但是不积跬步无以至千里,不积小流无以成江河。
下图是各种常用数据结构各种操作的时间、空间复杂度供大家查阅: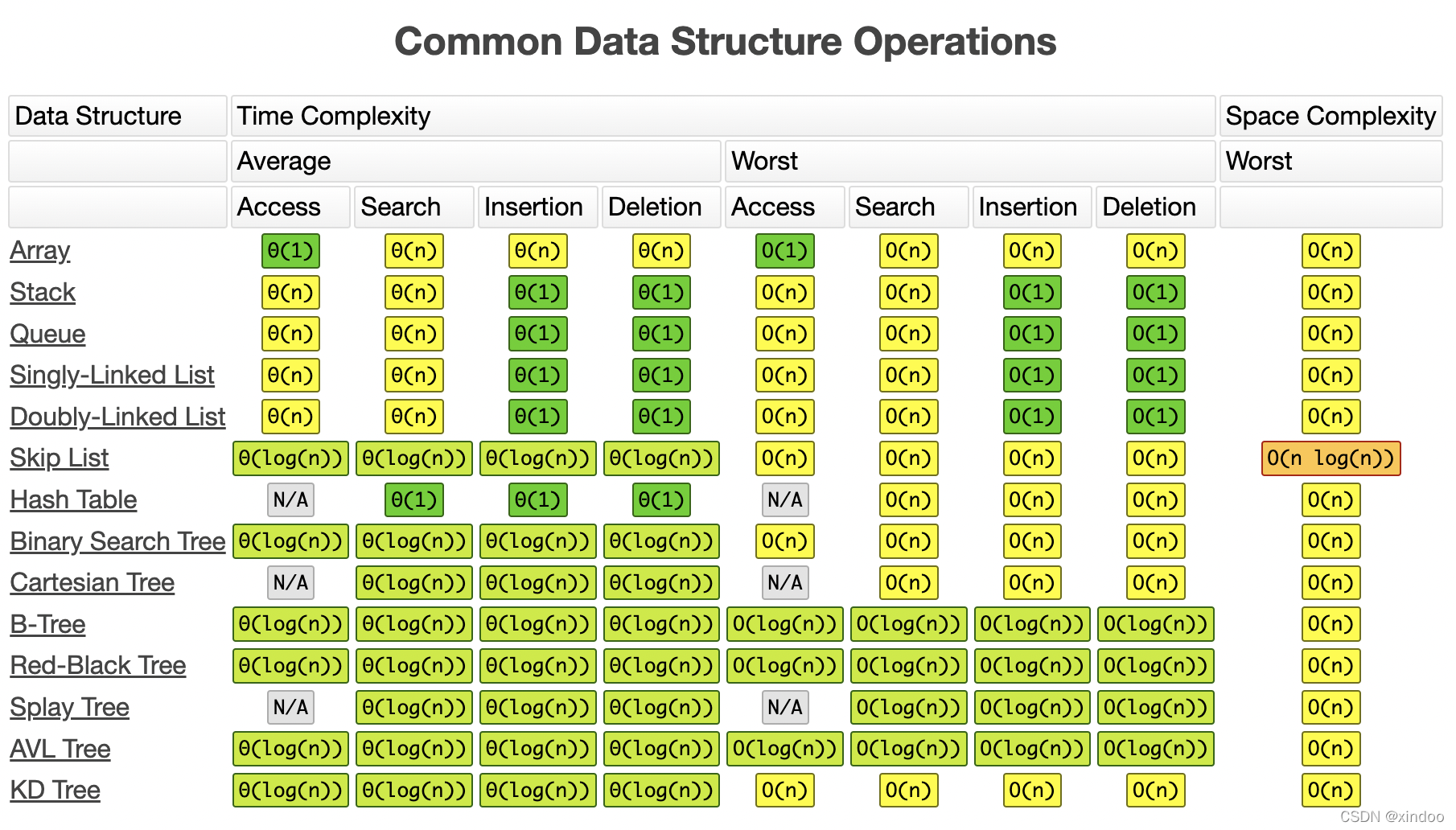
算法和数据结构是一个程序员的根基,虽然日常我们很少自己去实现某种具体的算法或数据结构,但我们却无时无刻不在使用各种已被封装好的算法或数据结构,我们应当做到对各种算法和数据结构烂熟于心,包括其时间复杂度、空间复杂度、适用范围。
如何写出高性能代码系列文章
作者简介:10年技术博主(博客简介:xindoo),曾就职于阿里 小米,目前任贝壳资深工程师。拥有运维、搜索广告、后端业务相关工作经验,擅长Java、Lniux、Redis……


