
可观测性之链路追踪门面Micrometer Tracing原创
简介
使用微服务框架的同学不知道有没有遇到过这样的问题,有业务同学投诉说未收到消息或者系统提示500状态码错误,然后App服务端同学开始根据业务反馈过来的用户信息查询日志,发现当前系统没有问题,然后将下游系统的负责人拉进群里协助排查问题,下游系统的同学又排查发现自己的系统也没问题又会将他的下游系统的同学拉进群,大家重复着这样的循环,群里面的人也越来越多,排查的链路也越来越长,业务同学也很着急催了一次又一次,直到达到循环的终止条件:链路中有一个同学发现系统日志里面抛出了一个异常,终于定位到了问题。
可以看到我们的服务拆分的越细排查问题的时候就会有越多的同学参与进来,耗费的时间就越长,业务对技术的评价变的更差,日益复杂的软件架构导致系统在出现问题的时候,发现问题和排查问题的效率极低。那这个问题如何解决呢?就需要引入一个称为链路追踪的系统。
说起链路追踪系统,最为著名理论还是谷歌的一篇论文:
《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》
论文中详细的介绍了Dapper链路追踪系统的基本原理和关键技术点。如果对论文原文比较感兴趣可以访问地址:
https://research.google/pubs/pub36356/
或者关注微信公众号 《中间件源码》 发送dapper关键词获取原文和译文的PDF。
链路追踪系统不仅仅可以帮助排查问题还可以用于分析系统请求链路中的性能问题,这里就不详细拆解枯燥的论文了,为了简单起见通过Micrometer提供的Tracing门面来引入全链路追踪系统的一些概念和说明,为什么需要链路追踪系统和对于可观测性的一些知识也可以参考前面的文章 《可观测性神器之Micrometer》 这一章节。那下面就进入正文看一看Micrometer提供的Tracing门面是如何定义链路追踪系统的。
架构说明
定位
Micrometer Tracing为最流行的链路追踪系统库提供了一个简单的外观。
Micrometer Tracing具有如下特性:
- 基于JVM: 基于 JVM 的应用程序代码,厂商无关的API。
- 低开销: 收集数据增加很少甚至没有开销,同时最大限度地提高跟踪工作的可移植性。
- 可扩展: Micrometer Tracing 内部包含一个带有仪器SPI的核心模块、一组包含各种示踪剂桥接的模块、一组包含专用跨度报告机制的模块和一个测试套件。
- 简单易用: 为了方便使用它还提供了对 Micrometer 的Tracing扩展
ObservationHandler。每当使用 一个Observation时,都会创建、启动、停止和报告相应的跨度。
架构
请求响应链路传递模型
下面可以通过一个官方的图来了解下一次请求到响应的过程中完整链路,借助这个链路来引入链路追踪系统的一些常见名词与概念。

先来描述下这个请求过程(可以只看下前面4个场景即可):
- 外部请求到SERVICE1
- 外部请求没有链路追踪数据,SERVICE1在链路追踪系统中是第一个系统要产生跨越整个链路的Id又称为Trace Id,在服务A内部的业务处理中会额外有一个跨度Id 称为SpanId。
- SERVICE1 发起请求到SERVICE2
- 请求时仅仅需要将链路Id TraceId传递到SERVICE2 SERVICE2会再内部重新产生新的跨度Id。
- SERVICE2 发起请求到SERVICE3
- SERVICE2在内部处理业务时可能会产生新的线程这个时候可以产生新的跨度Id, 不过请求时仅仅需要将链路Id TraceId传递到SERVICE3 SERVICE3会再内部重新产生新的跨度Id。
- SERVICE3 响应请求到SERVICE2
- 响应的时候同样只传递TraceId, 不过在SERVICE2中发起请求到SERVICE3和从接收来自SERVICE3的线程是同一个可以使用当前线程中已经存在的SpanId
- SERVICE2 发起请求到SERVICE4
- 参考SERVICE2 发起请求到SERVICE3
- SERVICE4 响应请求到SERVICE2
- 参考SERVICE3 响应请求到SERVICE2
- SERVICE2 响应请求到SERVICE1
- 参考参考SERVICE3 响应请求到SERVICE2
可以看到SERVICE1是起始链路产生了TraceId,内部业务处理的时候产生了SpanId,在SERVICE2中会将请求发送给多个下游服务TraceId依旧使用的是同一个,但是内部业务处理的时候多个线程可以使用多个SpanId。
父子关系处理
上面的方式虽然可有有效的通过Trace和Span来检测到请求所处的位置,但是当处于某个系统的时候无法知道上下游关系,这就需要在上图的Custom Span中创建自定义跨度信息了,一个有前后关系的链路中需要在当前的Span跨度中增加父SpanId 来形成上下游关系如下图所示:

常见术语
Micrometer Tracing 借用了 Dapper中的一些术语。让我们看下在Micrometer中将要出现的一些常见的名词含义,方便我们接下来要熟悉的入门例子。
Trace(追踪): 一组形成树状结构的跨度。代表一个潜在的,分布式的,存在并行数据或并行执行轨迹(潜在的分布式、并行)的系统。
Span(跨度): 基本工作单元。代表系统中具有开始时间和执行时长的逻辑运行单元。Span之间通过嵌套或者顺序排列建立逻辑因果关系。例如,发送 RPC 是一个新的 Span,发送对 RPC 的响应也是如此。跨度还有其他数据,例如描述、带时间戳的事件、键值注释(标签)、导致它们的跨度的 ID 和进程 ID(通常是 IP 地址)。
Baggage(行李): Baggage存储在SpanContext中的一个键值对(SpanContext)集合。它会在一条追踪链路上的所有Span内全局传输,包含这些span对应的SpanContexts。在这种情况下,”Baggage”会随着Trace一同传播,Baggage拥有强大功能,也会有很大的消耗。由于Baggage的全局传输,如果包含的数量量太大,或者元素太多,它将降低系统的吞吐量或增加RPC的延迟。
Annotation/Event(注解/事件): 用于及时记录一个事件的存在。
Tracer(追踪器): 处理跨度(Span)生命周期的库。它可以创建、启动、停止和通过reporters / exporters来上报跨度到外部系统。
有了Trace和Span这样的数据,再排查一个链路上请求异常的时候就可以通过TraceId来快速定位请求落到了哪个系统上终止了,然后在对应系统中搜索Traceid相关日志来分析原因,但是一个TraceId的请求可能在这个系统中以多线程的方式执行时,开启了多个Span,这个时候就要通过SpanId来精确这个请求在内部的处理逻辑了。有了这些理论知识做铺垫那接下来就尝试使用Micrometer Tracing来开发一个简单的链路追踪功能吧。
有了Trace和Span这样的数据,在排查一个链路上请求异常的时候可以通过TraceId来快速定位请求落到了哪个系统上终止了,然后在对应系统中搜索Traceid相关日志来分析原因,但是一个TraceId的请求可能在这个系统中以多线程的方式执行时,开启了多个Span,这个时候就要通过SpanId来精确这个请求在内部的处理逻辑了。有了这些理论知识做铺垫那接下来就尝试使用Micrometer Tracing来开发一个简单的链路追踪功能吧。
开发入门
依赖引入
Micrometer Tracing自带了一个物料清单(BOM),它是一个包含所有项目版本的项目的依赖接下来以Maven依赖引入为例:
Micrometer核心依赖
这里一共需要引入两个依赖:
- 一个是用来管理版本号的BOM
- 一个是micrometer-tracing依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing-bom</artifactId>
<version>${micrometer-tracing.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing</artifactId>
</dependency>
</dependencies>
桥接依赖
由于Micrometer Tracing是一个门面工具自身并没有实现完整的链路追踪系统,具体的链路追踪另外需要引入的是第三方链路追踪系统的依赖,下面就以Zipkin 链路追踪系统为例:
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing-bridge-brave</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-reporter-brave</artifactId>
<version>2.16.3</version>
</dependency>
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-sender-urlconnection</artifactId>
<version>2.16.3</version>
</dependency>
官方提示:只能依赖一个桥接的依赖。类路径上不应该有两个第三方桥接依赖同时出现。
Zipkin
前面我们引入的brave是Zipkin的一个Java依赖库。Zipkin是一个分布式跟踪系统。它有助于收集解决服务架构中的延迟问题所需的计时数据。功能包括收集和查找此数据。为了帮助理解我们可以看下Zipkin提供的UI管理端页面如下所示:
链路追踪图
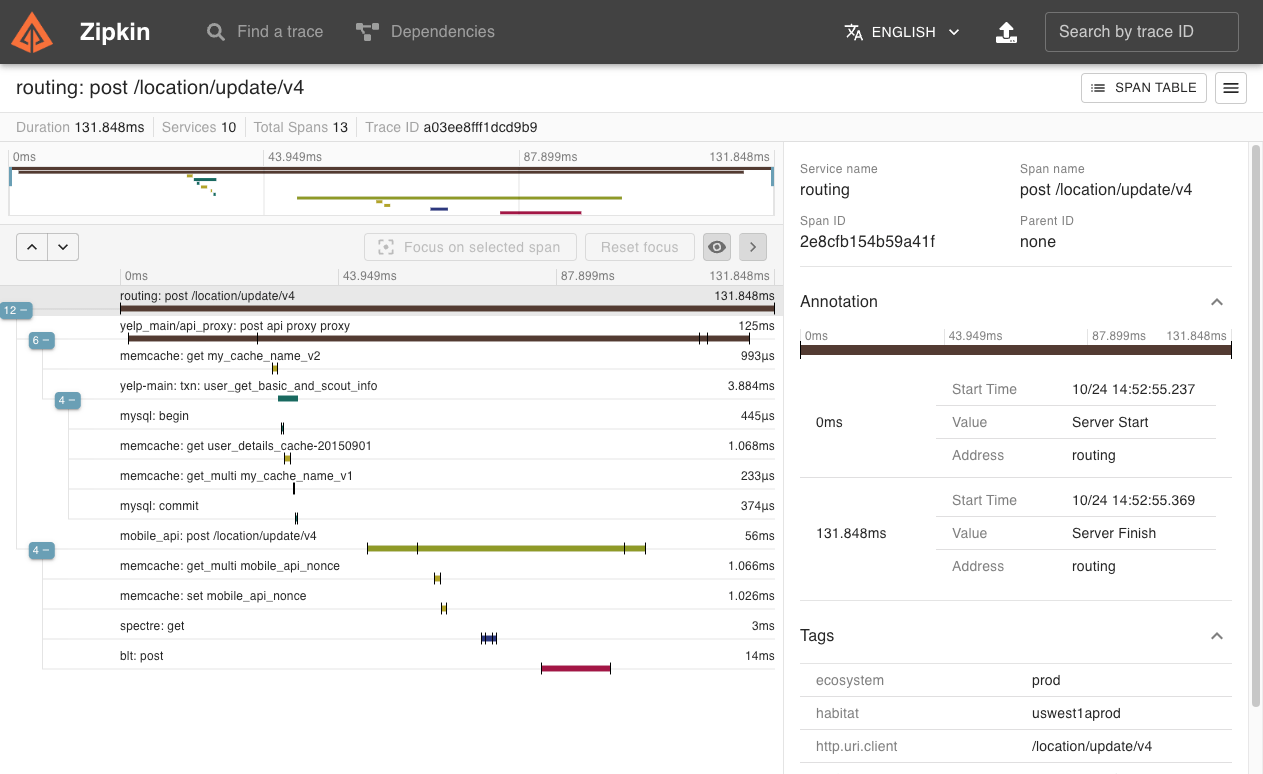
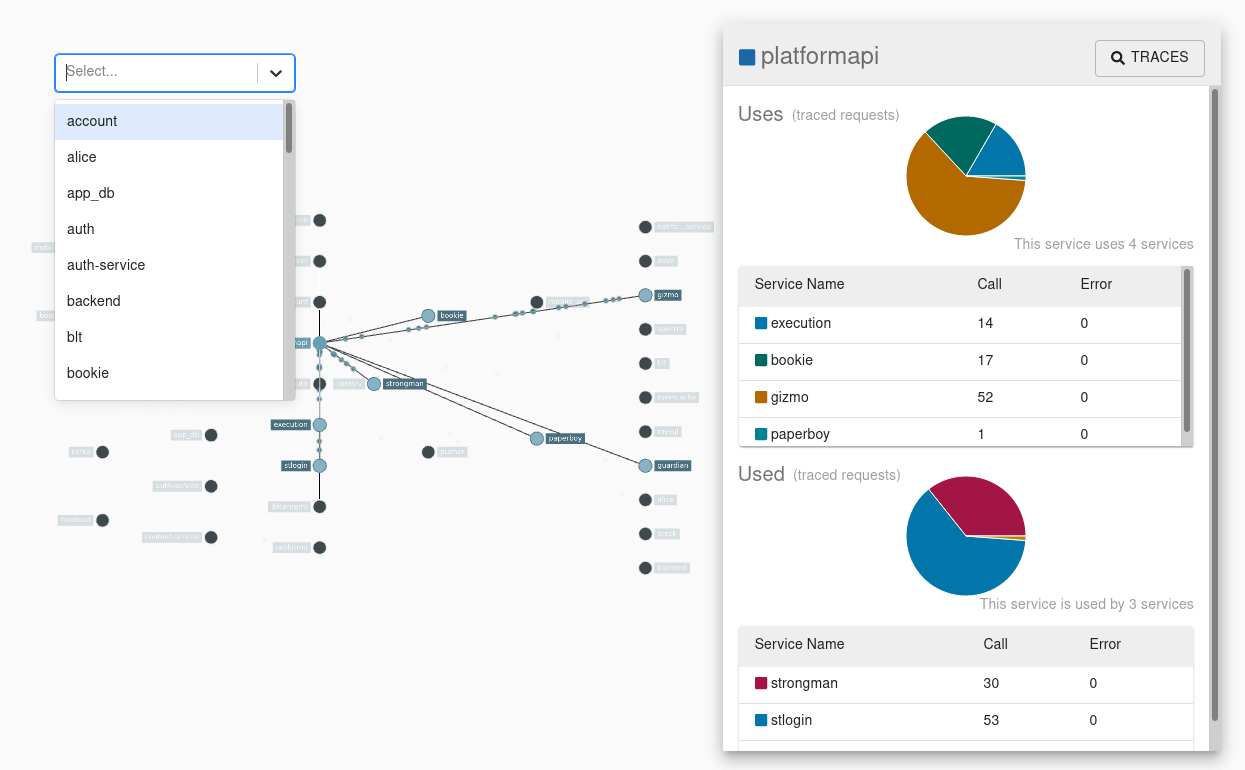
依赖关系图:
如果去搭建zipkin呢,可以参考官网的快速开始手册直接运行jar执行文件或者使用docker来启动容器,如下命令:
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar
更详细的zipkin内容,感兴趣可以打开官网来看:https://zipkin.io/pages/quickstart.html,
入门示例
前面介绍了如何安装zipkin,下面就直接来贴一下官方提供的Java示例了,通过示例来详细看下:
import brave.Tracing;
import brave.baggage.BaggageField;
import brave.baggage.BaggagePropagation;
import brave.baggage.BaggagePropagationConfig;
import brave.handler.SpanHandler;
import brave.propagation.B3Propagation;
import brave.propagation.StrictCurrentTraceContext;
import brave.sampler.Sampler;
import io.micrometer.tracing.CurrentTraceContext;
import io.micrometer.tracing.Span;
import io.micrometer.tracing.Tracer;
import io.micrometer.tracing.brave.bridge.BraveBaggageManager;
import io.micrometer.tracing.brave.bridge.BraveCurrentTraceContext;
import io.micrometer.tracing.brave.bridge.BraveTracer;
import zipkin2.reporter.AsyncReporter;
import zipkin2.reporter.brave.ZipkinSpanHandler;
import zipkin2.reporter.urlconnection.URLConnectionSender;
public class MicrometerTracingBrave {
public static void main(String[] args) {
//[Brave component]使用SpanHandler的示例。
// SpanHandler是一个在完成跨度时调用的组件。
// 这里我们有一个设置示例,通过UrlConnectionSender(通过<io.Zipkin.reporter2:Zipkin-sender-urlconnection>依赖项)
// 以Zipkin格式将跨度发送到所提供的位置。另一个选项可以是使用TestSpanHandler进行测试
SpanHandler spanHandler = ZipkinSpanHandler
.create(AsyncReporter.create(URLConnectionSender.create("http://localhost:9411/api/v2/spans")));
// 〔Brave组件〕CurrentTraceContext是一个Brave组件,它允许您检索当前TraceContext。
StrictCurrentTraceContext braveCurrentTraceContext = StrictCurrentTraceContext.create();
// [Micrometer Tracing 组件] Brave的CurrentTraceContext的Micrometer包装类型
CurrentTraceContext bridgeContext = new BraveCurrentTraceContext(braveCurrentTraceContext);
// [Brave组件]跟踪是根组件,允许配置跟踪程序、处理程序、上下文传播等。
Tracing tracing = Tracing.newBuilder().currentTraceContext(braveCurrentTraceContext).supportsJoin(false)
.traceId128Bit(true)
// 要使Baggage(行李)正常工作,您需要提供要传播的字段列表
.propagationFactory(BaggagePropagation.newFactoryBuilder(B3Propagation.FACTORY)
.add(BaggagePropagationConfig.SingleBaggageField
.remote(BaggageField.create("from_span_in_scope 1")))
.build()).sampler(Sampler.ALWAYS_SAMPLE).addSpanHandler(spanHandler).build();
// [Brave 组件] Tracer是用于处理跨度生命周期的组件
brave.Tracer braveTracer = tracing.tracer();
//--------上面主要是brave创建Tracer追踪器的逻辑,可以随时替换为其他链路追踪系统-------//
//--------下面是Micrometer Tracing门面做的操作---------------------------------//
// [Micrometer Tracing 组件] Micrometer Tracing包装类型,包装了Brave‘s Tracer的Tracer
Tracer tracer = new BraveTracer(braveTracer, bridgeContext, new BraveBaggageManager());
// 创建跨度。如果此线程中存在span,它将成为“newSpan”的父级。
Span newSpan = tracer.nextSpan().name("calculateTax");
// 开始一个跨度并将其放在范围内。放入范围意味着将范围放在本地线程中,如果已配置,则调整MDC以包含跟踪信息
try (Tracer.SpanInScope ws = tracer.withSpan(newSpan.start())) {
// 您可以标记一个span-在其上放置一个键值对,以便更好地调试
newSpan.tag("taxValue", "value");
// 记录一个事件
newSpan.event("taxCalculated");
}
finally {
// 一旦完成,记得结束跨度。这将允许收集跨度并将其发送到分布式跟踪系统,例如Zipkin
newSpan.end();
}
}
}
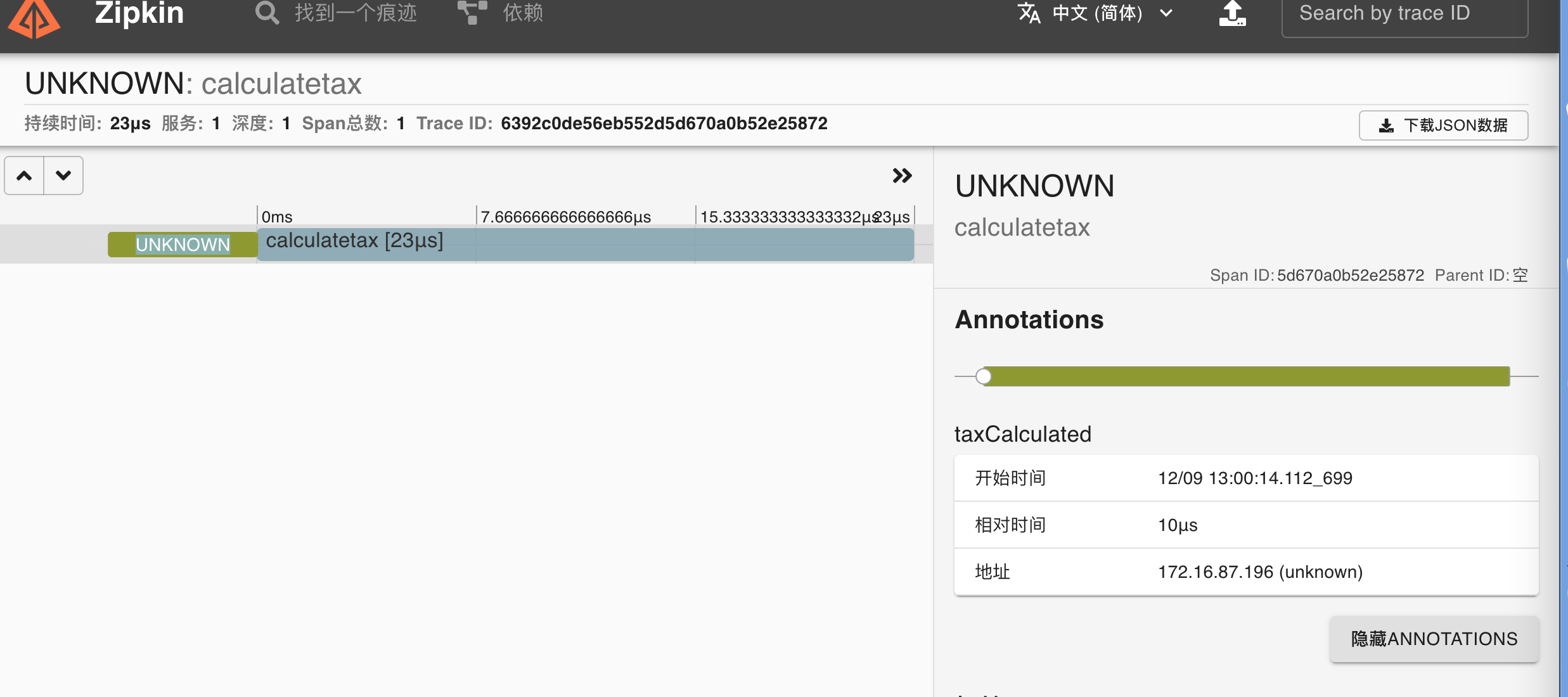
示例中每行代码都标记了注释,可以通过注释来了解下Trace和Span的创建过程,通过运行代码进行埋点。
使用Zipkin分析链路
运行Zipkin
前面简单说了下搭建Zipkin的方式:
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar
如果windows下无法使用curl命令和bash可以直接下载zipkin的jar进行运行,
Zipkin可执行文件下载链接为:https://search.maven.org/remote_content?g=io.zipkin&a=zipkin-server&v=LATEST&c=exec
运行应用程序
直接运行前面示例代码的MicrometerTracingBrave的main方法即可。可以多运行几次。
使用Zipkin分析链路
浏览器打开地址:http://127.0.0.1:9411/
列表页
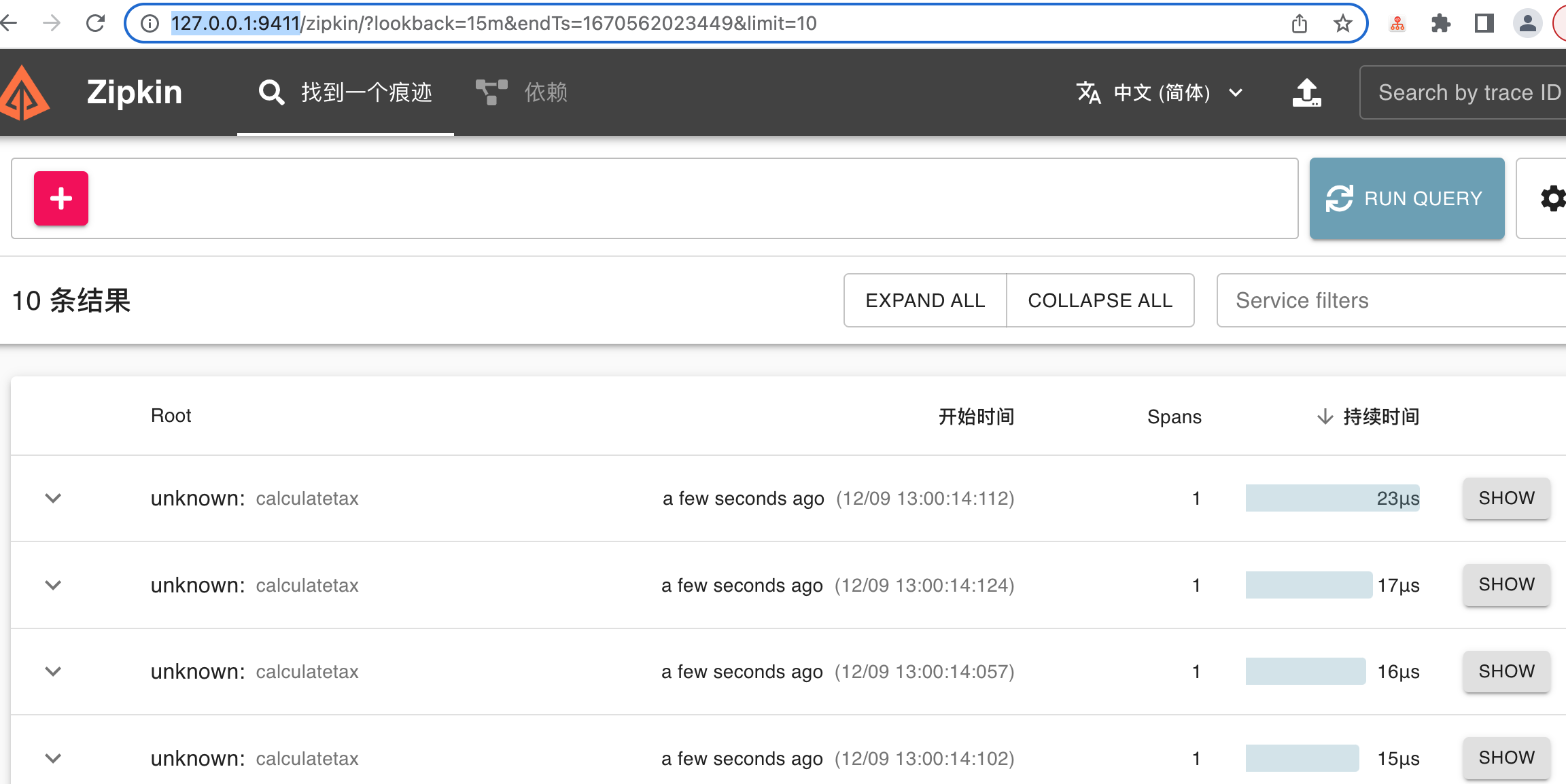
详情页
总结
Micrometer Tracing为最流行的链路追踪系统库提供了一个简单的外观,对于框架层的服务来说引入这样的门面是非常实用的,对于第三方链路追踪系统只需要根据内部规范实现桥接的代码即可,无需让框架层耦合。
不过相比于OpenTracing这样的老牌链路追踪门面,Micrometer Tracing并不是最成熟的,不过OpenTracing已经归档不再维护,OpenTracing和OpenCensus合并为OpenTelemetry之后统一了可观测性门面,从 Dapper 到 OpenTracing,解决了厂商无关和统一链路 API 的问题,从 OpenTracing 到 OpenTelemetry,解决统一可观测性 API 的问题,不过有意思的是SpringBoot3 在 Spring Boot Actuator 中为 Micrometer Tracing 的依赖性管理和自动配置。Micrometer Tracing 充当了类似日志领域内 slf4j 门面的角色。
可以看到在未来Micrometer必定会在Java的可观测性领域越来越火,从成熟的Meter埋点到 Tracing 链路追踪。
对Micrometer Tracing感兴趣可以关注微信公众号 《中间件源码》 订阅交流吧。


