
一个jsqlparse+git做的小工具帮我节省时间摸鱼原创
背景
前些时间做了个小工具解决了团队内数据库脚本检验&多测试环境自动执行的问题,感觉挺有意思,在这跟大家分享一下。
工具诞生之前的流程是这样:
1.开发人员先在开发环境编写脚本&执行;
2.执行没问题之后记录到代码目录下的upgrade目录;
3.提测时手动将upgrade目录下的脚本文件在测试库执行。
大概长这样
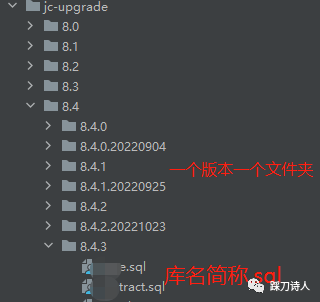
这套流程在我之前就有了,刚进来的时候感觉有点low,毕竟老东家解决这类问题是通过一款自研的数据库自动化运维平台-iDB,其诞生的目的是“解决绝大部分重复、复杂的数据库运维工作 ,满足业务对数据库信息查询和快速变更需求,借此提升研发效率,保证数据库操作符合审计要求,有可追溯的变更和审核日志”,内心一度排斥过一段时间,后来转念一想这套手工机制对于目前的团队规模来说是够用,况且没有配备dba,搞一套iDB上来谁审核谁呢?想到这,心里自然也就释怀了,不用过于追求太时尚的工具、技术,够用就可以了。
问题出现
伴随着近两年业务快速发展,团队也迎来了扩编,往往在这种时候就容易出一些低级故障,俗话说越忙越乱。
遇到过哪些问题呢?
0.代码提测了,但是脚本忘记执行了,测试走流程的时候发现有报错然后反馈给开发处理,耽误进度;
1.刷数据未加where条件,导致测试环境崩溃,有一次还波及了线上,幸好只是一张配置表,从其他私有化环境快速同步一份即可,但也是心惊肉跳,要是业务表可能团队要团灭了;
2.一些高危sql,比如drop table if exists,原意是想顺畅的建一张新表,但是谁能保证同样的语句不会再出现?
3.一些高级语法导致部分私有化环境不兼容,一般情况下开发执行一些数据库操作都是直接通过navicat等工具在开发库执行,然后再把工具生成的脚本记录下来,但是也有当时没整理,发版时再整理的情况,这时只能手写sql了,不排除会写一些高级的语法,导致发版时部分环境失败的情况,因为数据库版本有差异(有些客户分配的库,统一版本比较难);
人肉解决
最开始研发经理是专门安排了一个测试同学去处理这事,他需要定时做以下事项:
-
检查是否有新脚本提交,如果有就继续后续流程;
-
检查是否为高危脚本,如果高危就线下告知相关的开发整改,否则就继续后续流程;
-
在navicat等工具中执行,如果执行失败了就线下告知相关的开发处理。
起初几天确实是解决了前面提到的一些问题,但是人毕竟不是机器,会忘记、会疲倦、会烦躁、会走神,两周以后“人肉”方案又出现一些新问题:
-
忙的时候会忘;
-
频率不好把握,几小时一次太慢了,几分钟一次人会崩溃;
-
这个活太low了,临时干几天还行,长期没人愿意干;
机器解决
机器不知疲倦、一丝不苟、戒骄戒躁,最适合干这类重复性而且枯燥的活,鉴于此我利用半天时间构思&开发了一个小工具用来解决这一问题,解救了那个悲惨的测试同学。
这个工具需要具备以下特点:
-
定时拉取代码判断脚本文件是否有变化;
-
如果脚本文件变化了解析脚本看是否有语法错误,如果有语法错误发送邮件给提交人;
-
如果没有语法错误判断是否有高危语句,如果有高危发邮件给提交人和研发组长&经理们;
-
一切正常,开始执行sql语句,执行结果需要发邮件给相关人员,需要避免重复执行;
接下来一步步看如何解决上面的问题:
-
定时拉取代码
这个比较简单,因为是运行在我的开发机器上,定时使用Runtime执行git pull即可。
Process process = Runtime.getRuntime().exec("git pull ",null,new File(代码目录));
2.判断脚本文件是否发生变化
记录脚本文件的md5,拉取代码以后计算md5是否发生变化。
3.语法解析
利用jsqlparser工具将脚本文件内容解析为Statements对象,代表一组解析之后的sql语句对象,如果有语法错误jsqlparser会抛出异常,异常信息中包含具体的行号和错误信息,以下面这组sql语句为例:
String sql = "ALTER TABLE `wf_position` ADD COLUMN `c1` VARCHAR (10);" +
"ALTER TABLE `wf_position` ADD COLUNM `c2` VARCHAR (10)";
CCJSqlParserUtil.parseStatements(sql);
解析的时候会抛出如下异常,很明显是因为COLUNM写错了
net.sf.jsqlparser.JSQLParserException: Encountered unexpected token: "`c2`" <S_QUOTED_IDENTIFIER>
at line 1, column 93.
Was expecting:
"COMMENT"
at net.sf.jsqlparser.parser.CCJSqlParserUtil.parseStatements(CCJSqlParserUtil.java:188)至此我们已经做完了语法解析,但是怎么根据抛出的语法错误找到对应的提交人呢?这里分两步完成:
3.1正则匹配出异常堆栈中的line
Pattern pattern = Pattern.compile("line (\\d+), column (\\d+)");
try{
CCJSqlParserUtil.parseStatements(sql);
}catch(exception){
String message = exception.getMessage();
Matcher m = pattern.matcher(message);
int line = -1;
int column = -1;
while(m.find()){
int groupCount = m.groupCount();
if(groupCount > 0){
line = Integer.parseInt(m.group(1));
column = Integer.parseInt(m.group(2));
break;
}
}
}3.2前一步的line可以对应到脚本文件中的行,利用git blame命令可以获得对应行的提交记录,里面包含提交者的姓名和邮箱
String blameParams = scriptFile.getName()+" -L "+lineNum+","+lineNum;
Process process = Runtime.getRuntime().exec("git blame "+blameParams,null,new File(scriptFile所在目录));输出格式如下,红框所示区域就是提交者的邮箱(组内约定git user.name必须携带邮箱,所以这里能拿到)

接下来就各种的截取,最终提取邮箱,比较简单,这里就不啰嗦了。
4.高危判断
遍历所有的Statement对象,目前主要识别三类:
1.drop table
2.update不带where条件
3.delete不带where条件
Statements statements = CCJSqlParserUtil.parseStatements(sql);
List<RiskScript> riskScripts = new ArrayList<>()
for(Statement statement : statements.getStatements()){
RiskScript riskScript = new RiskScript();
//drop table
if(statement instanceof Drop
&& (((Drop) statement).getType().equals("table")
|| ((Drop) statement).getType().equals("TABLE"))){
riskScript.setErrorMsg("drop table高危,放弃自动执行,请确认,如有需要请手动执行");
riskScript.setSql(statement.toString());
this.riskScripts.add(riskScript);
continue;
}
//update不带where条件
if(statement instanceof Update
&& ((Update) statement).getWhere() == null){
riskScript.setErrorMsg("update 不带where条件,放弃自动执行,请确认,如有需要请手动执行");
riskScript.setSql(statement.toString());
this.riskScripts.add(riskScript);
continue;
}
//delete不带where条件
if(statement instanceof Delete &&
((Delete) statement).getWhere() == null){
riskScript.setErrorMsg("delete 不带where条件,放弃自动执行,请确认,如有需要请手动执行");
riskScript.setSql(statement.toString());
this.riskScripts.add(riskScript);
continue;
}
}5.避免重复执行
这个比较简单,每次执行完以后记录下每条sql的执行历史,执行前判断。
效果展示
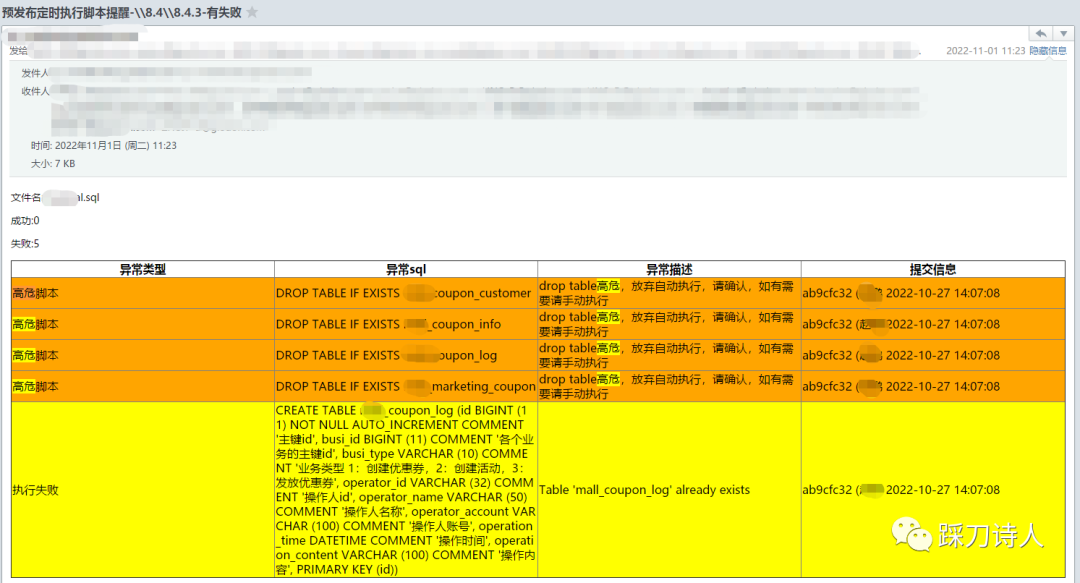
总结
是不是应该引入一个高大上的数据库自动化运维平台呢?我的判断是暂时不需要,究其原因我认为有以下几点:
1.虽说没有专人审核那么精细,但依赖工具把一些高危的sql已经排除在外,已然是够用了,想想老东家为什么需要dba严格审核是因为toC的数据量较大,字段类型、索引等对性能的影响不容小觑,而目前toB的业务,数据量不会特别大,字段类型、索引等因素对性能的影响姑且可以忽略,起码现阶段差别不大;
2.每个迭代产生的脚本变更较多,如果引入太繁琐的流程,对开发效率是一种制约,不求设计出精妙的表结构,只愿你不要写出“团灭”的脚本;
推荐阅读
https://jsqlparser.sourceforge.net/home.php
https://www.w3cschool.cn/doc_git/git-git-blame.html
https://www.cnblogs.com/zhengyun_ustc/p/idb.html

昨晚在楼下拍的一张夜

