
【全网首发】一次RocketMQ ons SDK Bug导致消息不断堆积到重试队列的案例分析原创
背景介绍
系统运行在专有云,应用运行时环境是EDAS Container( EDAS Container是EDAS 平台 HSF 应用运行的基础容器,EDAS Container 包含 Ali-Tomcat 和 Pandora),消息处理使用的是【ons SDK】,消息消费者使用【PUSH】方式【批量】消费【普通消息】,MessageModel是【CLUSTERING】。
为了解决RocketMQ Producer某个性能问题,对Pandora进行了升级(主要是升级RocketMQ版本)。
下面从技术角度对升级中遇到的问题及分析过程进行总结,积累经验以避免类似问题的发生。
问题描述
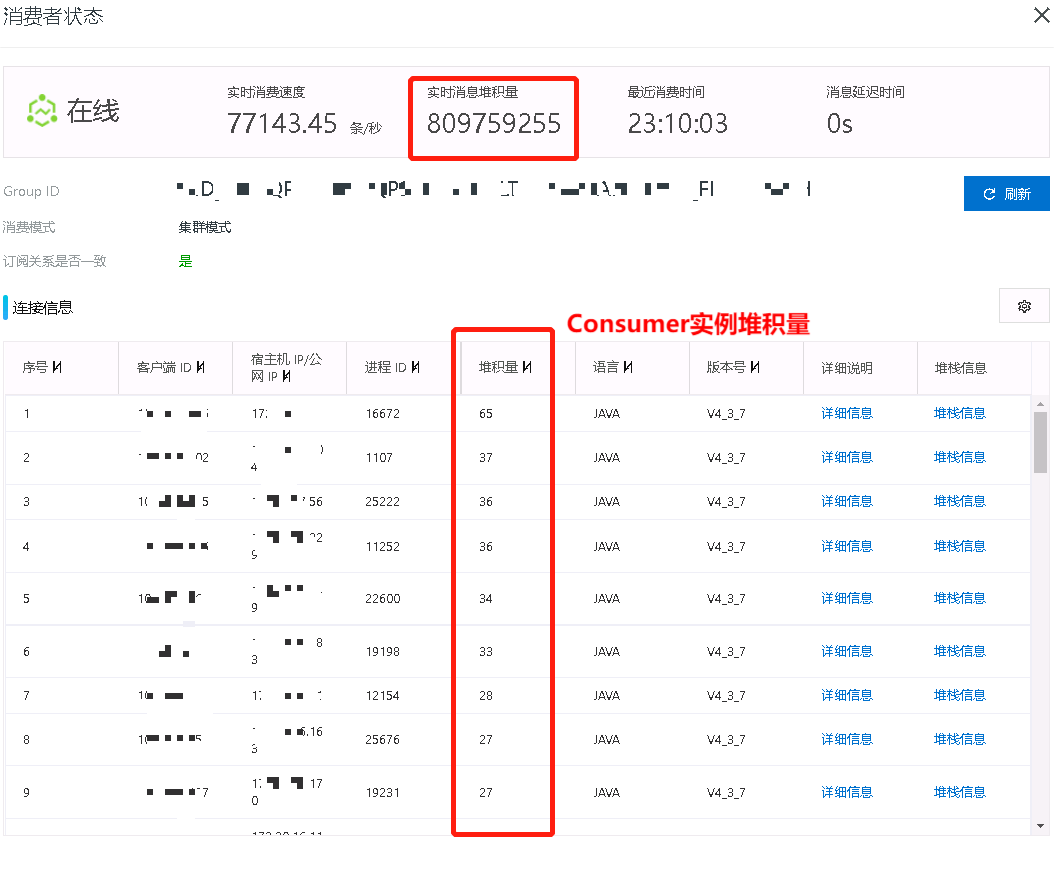
Pandora升级完成后,我们在RocketMQ控制台看到【消费者状态】->【实时消息堆积量】有8亿条,而每个Consumer实例堆积量是几十条,如图1:
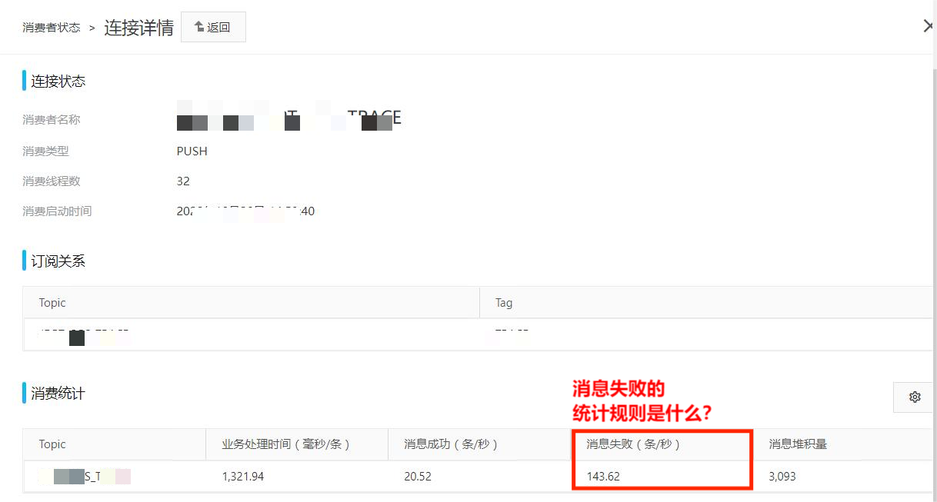
在【消费者状态】->【连接详情】有消息消费失败的情况,如图2:
在应用服务器ons.log也可以实时查看消息消费的指标信息,如图3:
这部分的统计指标的实现可以查看:org.apache.rocketmq.client.stat.ConsumerStatsManager

分析过程
根据我们前面几篇关于MQ消息堆积的文章,可以知道:
- 消息堆积总量与Consumer实例消息堆积量相符的情况下,通常是Consumer消费能力弱导致堆积
- 消息堆积总量大,而Consumer实例消息堆积量很小的情况下,通常是消息堆积在了重试队列中
从【问题描述】看,更像是发生了第二种情况导致的消息堆积。
总体思路
消息在重试队列中堆积,说明Consumer实例消费消息的时候出现了某些异常,导致Consumer实例将消息发送到了Broker重试队列中,所以我们分析【哪些地方】调用了【发送消息到Broker重试队列的接口】就基本抓住了这个问题的关键。
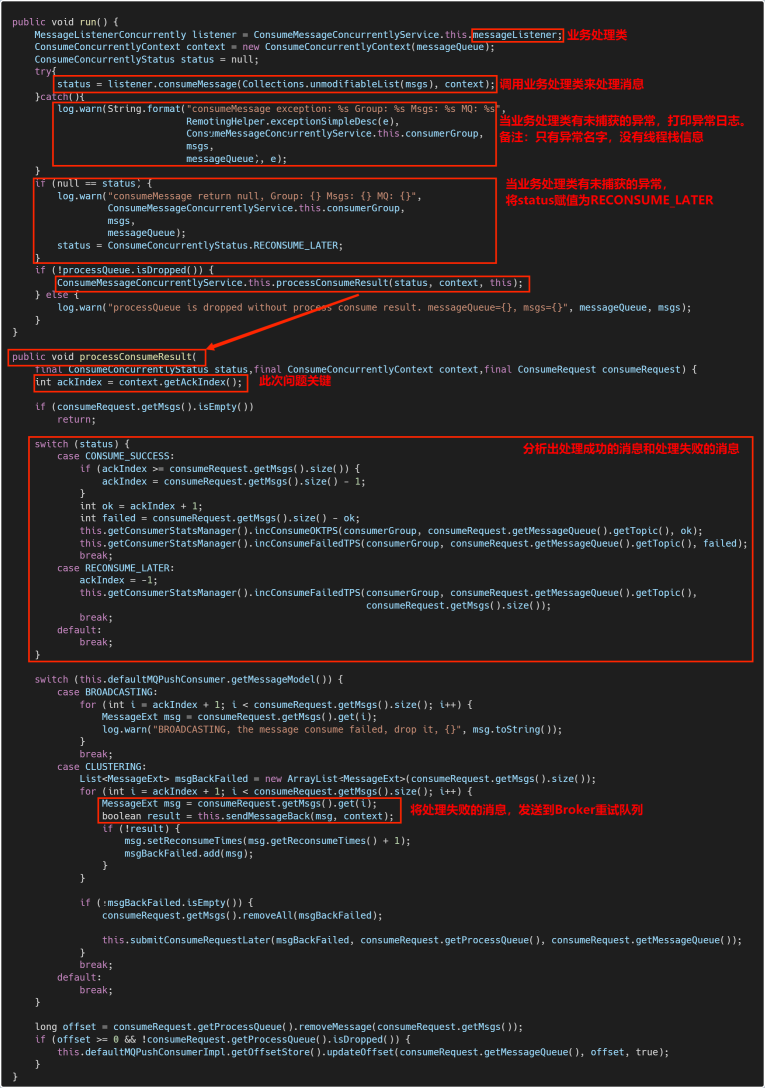
通过分析RocketMQ源码,发现主要有两个地方调用了【发送消息到Broker重试队列的接口】:
- 一个是org.apache.rocketmq.client.impl.consumer.ConsumeMessageConcurrentlyService的内部类ConsumeRequest
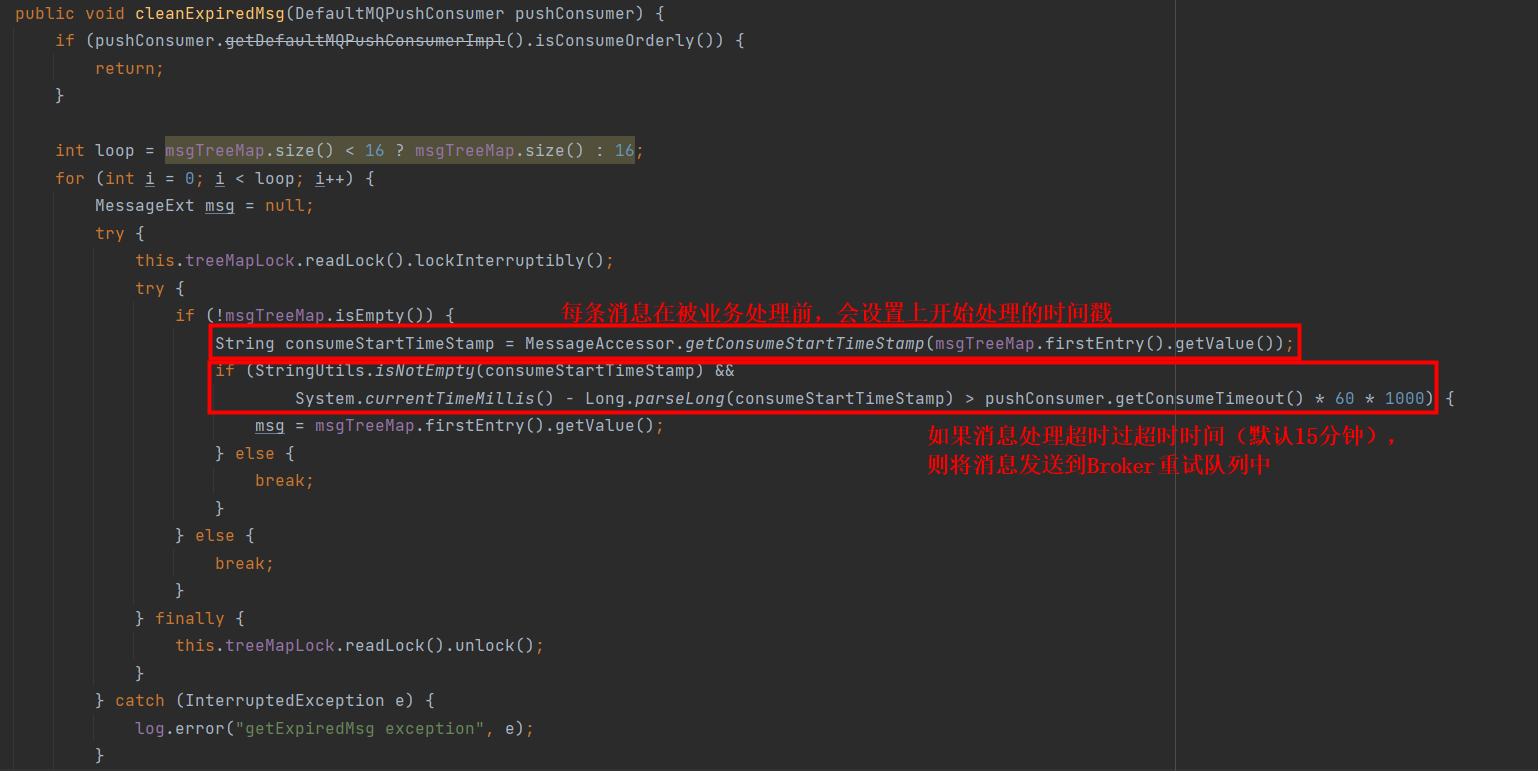
- 另一个是org.apache.rocketmq.client.impl.consumer.ConsumeMessageConcurrentlyService中清理过期Message的定时任务(最终是交给每个ProcessQueue来清理各自的Message)
ConsumeRequest
下面贴一下主要的代码,与该问题不相关的代码省略掉了;如果不想看代码,可以跳过此处,查看后面的流程图。
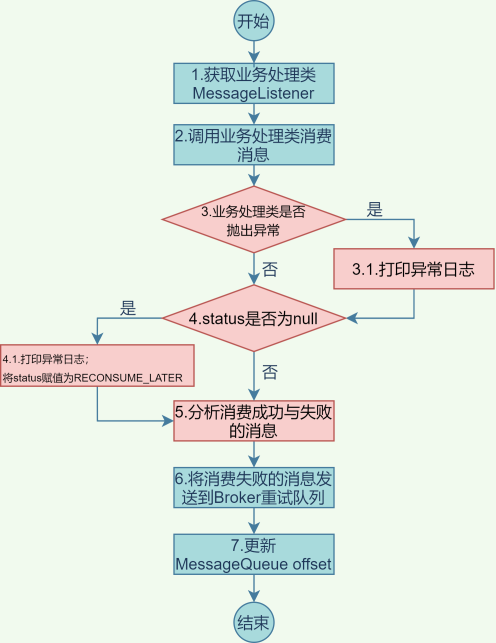
为了便于理解,我们使用流程图来表达下图4中代码主要逻辑,见图5:
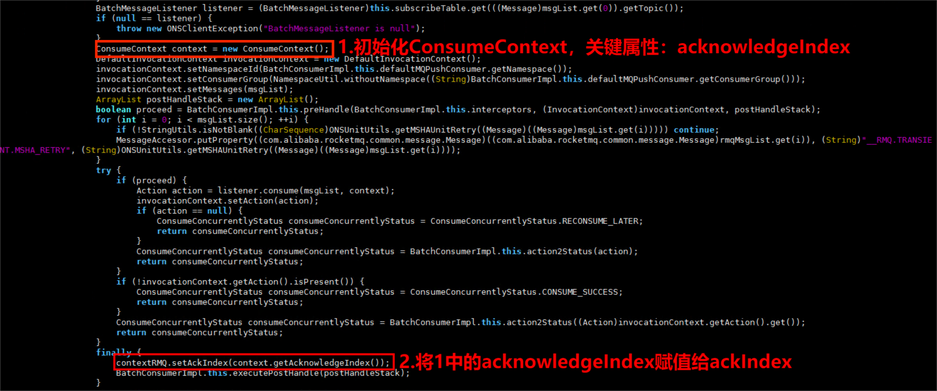
分析上面流程及代码,发现ConsumeConcurrentlyContext类的ackIndex变量是分析消息成功与失败的核心变量。
是否业务处理异常?
RocketMQ框架在业务处理类出现下面情况的时候,认为消息消费失败:
- 业务处理类返回ConsumeConcurrentlyStatus.RECONSUME_LATER
- 业务处理类返回null
- 业务处理类抛出异常
通过业务处理类日志可以确定业务没有返回ConsumeConcurrentlyStatus.RECONSUME_LATER的情况;
从代码可以看出,当出现2、3情况的时候,框架会将warn日志打印到ons.log中,通过过滤ons.log中“consumeMessage exception”和“consumeMessage return null”关键词,没有相应的日志记录,所以也不是这两种情况造成的。
备注:
当出现2、3情况的时候,ons.log日志中并没有打印出线程栈信息,如果想具体定位异常产生的位置,可以通过arthas stack命令进行分析。
arthas watch processConsumeResult
既然发送失败消息到Broker重试队列是在processConsumeResult方法调用的,那么我们可以分析下该方法的入参及返回值情况。
watch com.alibaba.rocketmq.client.impl.consumer.ConsumeMessageConcurrentlyService
processConsumeResult "{params,returnObj}" "target.consumeGroup=='GID_CID_XXX'" -x 3 -n3
watch正常机器
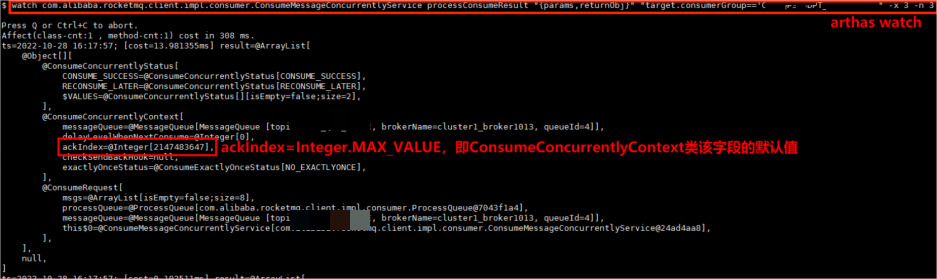
watch异常机器
通过上面的watch,我们找到了问题最关键的地方,我们用下面的场景来分析下ackIndex不同值的影响。
场景一
- 业务处理类批量消费了【8】条数据,消费成功返回:CONSUME_SUCCESS
- ackIndex=Integer.MAX_VALUE
- RocketMQ框架分析消费成功了【8】条,失败【0】条
- 因为都消费成功了,不会将消息发送到Broker重试队列中
场景二
- 业务处理类批量消费了【8】条数据,消费成功返回:CONSUME_SUCCESS
- ackIndex=0
- RocketMQ框架分析消费成功了【1】条,失败【7】条
- 因为有【7】条消费失败,所以会将【7】条消费失败的消息发送到Broker重试队列中
arthas watch setAckIndex
既然有地方在修改ackIndex,先验证下我们的判断是否正确。
watch com.alibaba.rocketmq.client.consumer.listener.ConsumeConcurrentlyContext setAckIndex "{params,returnObj}" "params[0]==0"
通过观察,确实有地方在不断将ackIndex的值修改为0。
arthas stack setAckIndex
我们继续定位是什么地方将ackIndex修改为0的。
stack com.alibaba.rocketmq.client.consumer.listener.ConsumeConcurrentlyContext setAckIndex "params[0]==0" -n 2
通过线程栈可知BatchConsumerImpl类调用了ConsumeConcurrentlyContext.setAckIndex方法。

arthas jad BatchConsumerImpl
没有源码的情况下,我们可以使用arthas jad对类进行反编译。
jad com.aliyun.openservices.ons.api.impl.rocketmq.BatchConsumerImpl
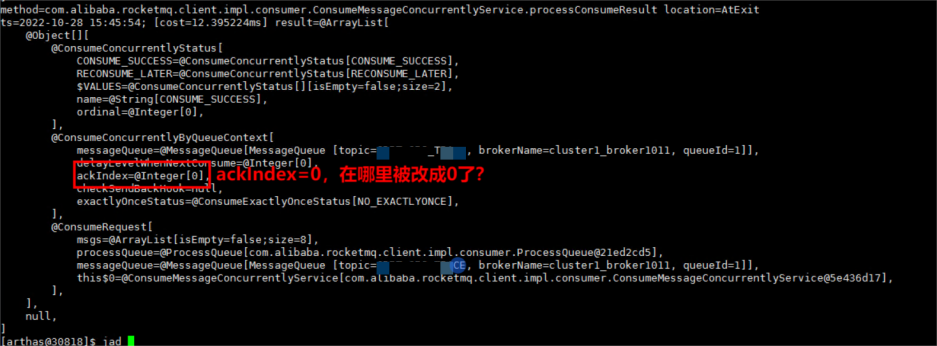
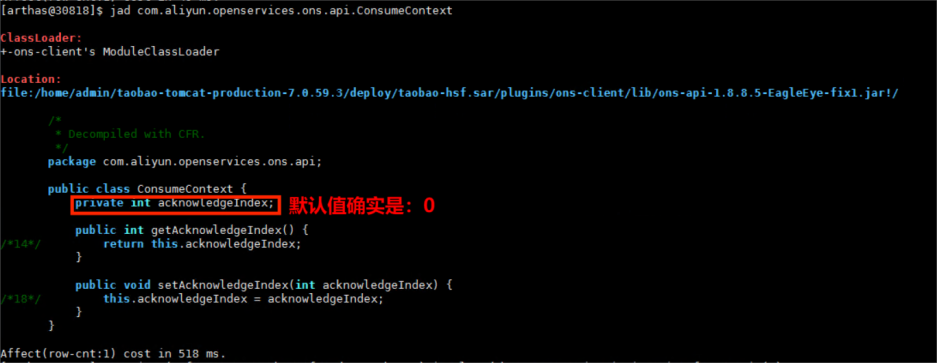
ConsumeContext类实例字段acknowledgeIndex默认值是多少呢?如果是0,问题的原因就找到了。
athas jad ConsumeContext
没有源码的情况下,我们可以使用arthas jad对类进行反编译。
jad com.aliyun.openservices.ons.api.ConsumeContext
通过上面代码可以看出,ConsumeContext类实例字段acknowledgeIndex的默认值是0。
ProcessQueue
通过上面的分析,我们已经定位到了问题,ProcessQueue做下简单描述,不做具体分析了。
解决办法
由上面的分析,这个问题属于RocketMQ ons SDK的一个Bug,修复就交给相应的产研团队来fix吧。
经验总结
1-5-10,1分钟发现,5分钟定位,10分钟恢复。
当故障发生的时候,需要【1】最短时间内发现(监控报警是否做好),需要【10】最快的速度恢复(变更管理和预案是否做好),【5】似乎不是最主要的。

