
【全网首发】稳定运行了多年的网关,偏偏让我掉进了坑原创
背景介绍
在服务刚启动的时候,服务的运行状态并没有达到最佳,如果一下子将流量提升到日常运行的状态,会存在大量的请求超时。
为什么服务刚启动的时候,服务不是最佳状态呢?
- Java应用类加载是按需加载的,在服务刚启动的时候,只会加载启动过程中需要的类;当服务接口被调用的时候,才会加载、初始化接口用到的类;对于热点代码,存在一个字节码解释执行到本地机器码执行的过程。
- Java应用需要与依赖的数据库创建连接,与数据库的连接不仅仅是建立一个TCP连接,还涉及用户认证、权限校验、数据库资源分配等,是一个比较耗时的操作。
- Java应用与依赖的Redis、HSF服务都要做初始化工作… …
为了服务达到最佳状态,我们通过调整服务权重慢慢增加流量,经过一段时间的小流量预热,让系统达到最佳运行状态。
某天我决定干这个事,我将权重由1调整到2,系统正常;由2调整到4,系统正常;将权重调整到9的时候,故障出现了。
故障描述
将权重调整到9,网关将流量都打到了30多台机器上(一共168台机器),接着应用不断发生CMS GC,接口成功率直线下降。
下游没流量的机器
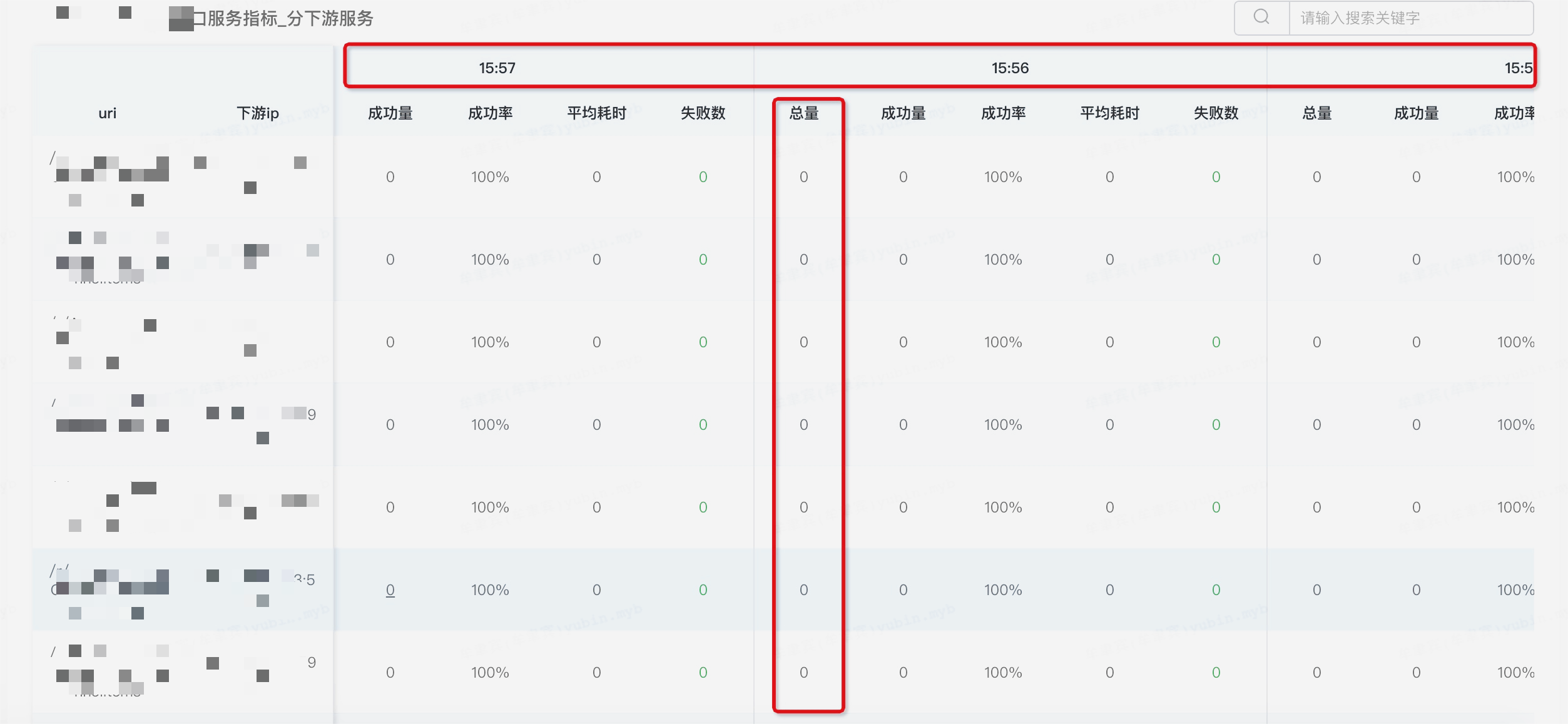
下游机器接口成功率
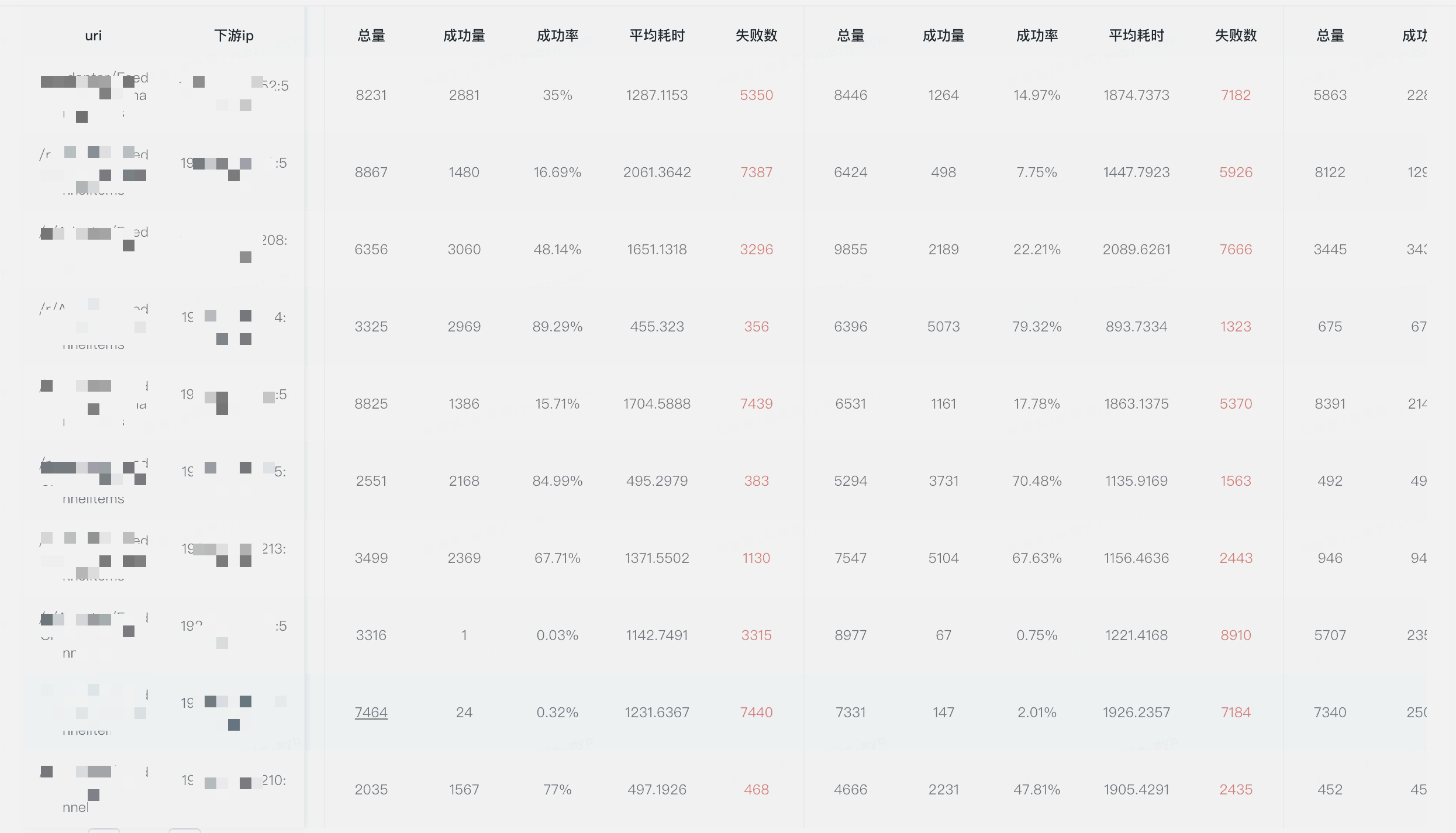
分析过程
因为提前完全没有想到发生这种情况,一点预案也没有。后来冷静下来,想明白:这不应该是应用侧的问题,调整个权重就被打挂似乎没有这种道理。
系统交互关系
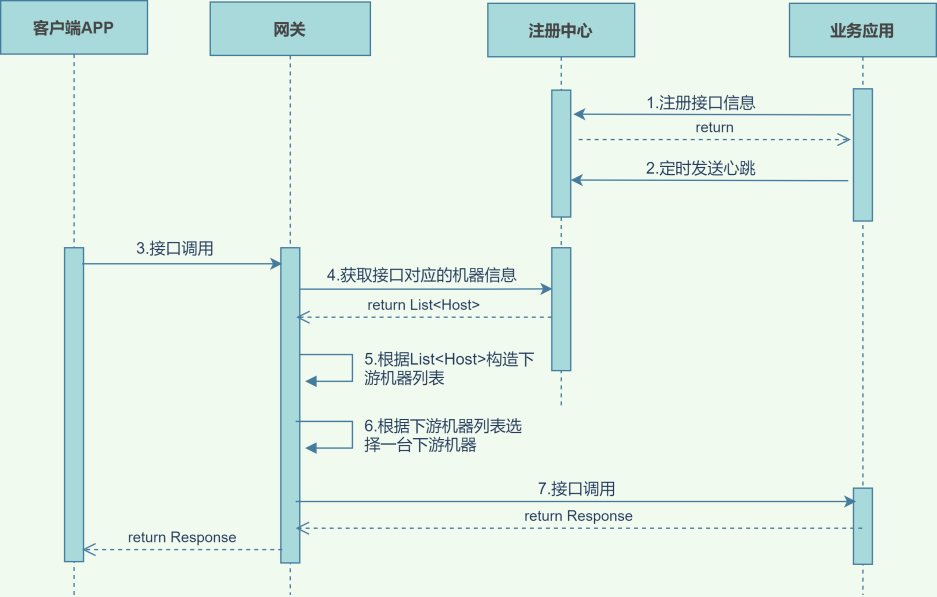
第4步-List<Host>
机器不健康的时候,注册中心会剔除掉问题机器;机器恢复健康后,注册中心会再次将机器加入到列表中,【机器列表的顺序不会改变】。
举例说明:
- A1、A2、A3、A4(权重都是1)已经注册到注册中心,状态健康;
- A1发送心跳失败(网络超时/服务hang住等原因),client从注册中心获取的机器列表是:A2、A3、A4;
- A1发送心跳成功(恢复健康状态),client从注册中心获取的机器列表是:A1、A2、A3、A4。
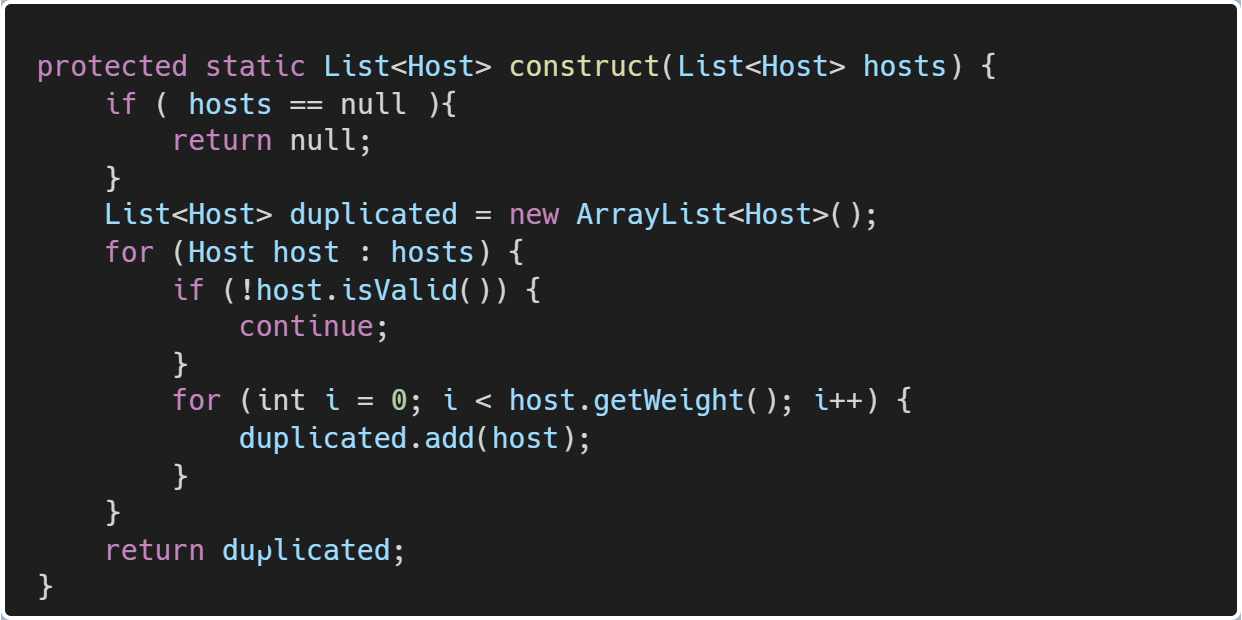
第5步-构造下游机器列表
网关从注册中心拿到List<Host>后,构造下游机器列表的逻辑:
举例说明:
List<Host>中共有A1、A2、A3、A4四台机器,每台机器权重是3,该方法构造出的下游机器列表是:
[A1,A1,A1,A2,A2,A2,A3,A3,A3,A4,A4,A4]
第6步-选择一台下游机器
当网关收到第一个请求的时候,选择下游机器列表的第一个机器;
当网关收到第二个请求的时候,选择下游机器列表的第二个机器;
依次轮询下游机器列表。
小结
每当某台机器向注册中心发送心跳超时的时候,该接口在注册中心对于的机器列表就会变化;
网关会获取该接口新的机器列表List<Host>,并根据List<Host>重新构造一个新的下游机器列表;
新的请求会按照下游机器列表的顺序轮询发送到后端业务机器上。
故障场景复盘
基本信息
业务应用有168台机器,定义为:A1,A2,A3… …A168;
网关有大概600台机器。
场景复盘
- 业务应用将权重调整为【9】;
- 网关机器列表(所有网关机器上都是这个列表)变更为:[A1,A1,A1…A1,A2,…A2,…A168,A168,A168…A168],列表中有9个A1,9个A2,9个A3,…,9个A168,计数设置为【0】;
- 单台网关机器QPM:300,【2】中数组每台机器对应9个元素,由于网关是轮询策略,所以一分钟的流量【整个集群的】打到了【300/9=33】台机器上;
- 由于流量打到了30多台机器上,机器负载迅速增大->发生了CMS GC,系统hang住,进而导致业务应用向注册中心发送心跳失败,注册中心通知网关机器列表变更,流程回到了第【2】步。

