
本篇文章主要介绍了
- Java 中的异常
- 如何处理函数抛出的异常
- 处理异常的原则
- 异常处理时,性能开销大的地方
Java 语言在设计之初就提供了相对完善的异常处理机制。
我们首先介绍一下 Java 中的异常。
介绍 Java 中的异常
异常是程序在运行过程中出现的程序异常事件,异常会中断正在执行的正常指令流 。
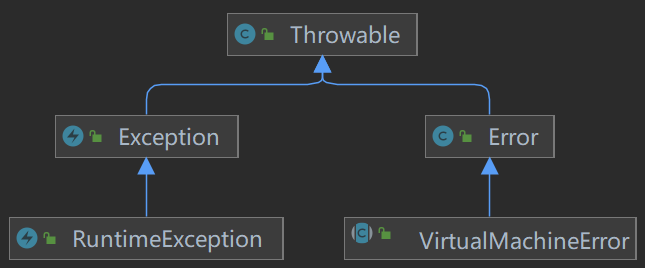
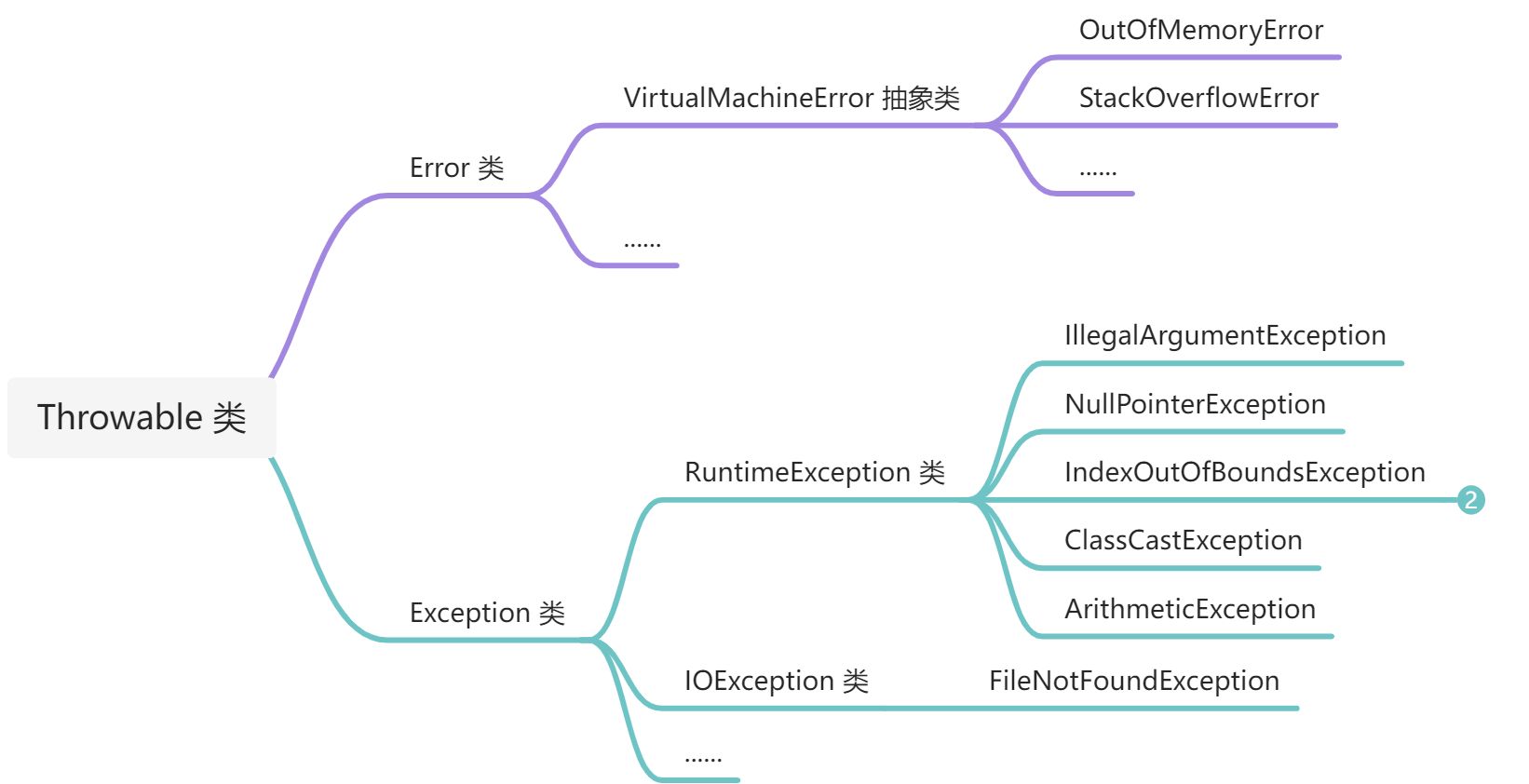
Java 中的异常分为两大类:Exception 和 Error。
下面是 Exception 和 Error 的类定义
public class Exception extends Throwable {}
public class Error extends Throwable {}
Exception 和 Error 都继承了 Throwable 类,在 Java 中只有 Throwable 类型的实例才可以被抛出(throw)或者被捕获(catch)。
Exception 和 Error 体现了 Java 平台设计者对不同异常情况的分类。
下面我们逐一介绍 Error 和 Exception。
介绍 Error
Error 类对象一般是由虚拟机生成并抛出,绝大部分的 Error 都会导致虚拟机自身处于不可恢复的状态,是程序无法控制和处理的。当出现 Error 时,一般会选择终止线程。
Error 中最常见的是虚拟机运行错误(VirtualMachineError 抽象类)。
虚拟机运行错误中最常见的有:
- 内存溢出(OutOfMemoryError):由于内存不足,虚拟机没有可分配的内存了,垃圾回收器也不能释放更多的内存,那么虚拟机抛出 OutOfMemoryError
- 栈溢出(StackOverflowError):如果一个线程已用的栈大小 超过 配置的允许最大的栈大小,那么虚拟机抛出 StackOverflowError
介绍 Exception
Exception 有两种类型「编译时异常」和「运行时异常」
- 「编译时异常」对应 Java 的 Exception 类
- 「运行时异常」对应 Java 的 RuntimeException 类(RuntimeException 类继承 Exception 类 )
下面是 Exception、RuntimeException 类的定义
public class Exception extends Throwable {}
public class RuntimeException extends Exception {}
对于「运行时异常」,我们在编写代码的时候,可以不用主动去 try-catch 捕获(不强制要求),编译器在编译代码的时候,并不会检查代码是否有对运行时异常做了处理。
相反,对于「编译时异常」,我们在编写代码的时候,必须主动去 try-catch 获取 或者 在函数定义中声明向上抛出异常(throws),否则编译就会报错。
所以:
- 「运行时异常」也叫作非受检异常(Unchecked Exception)
- 「编译时异常」也叫作受检异常(Checked Exception)
在函数抛出异常的时候,,我们该怎么处理呢?是吞掉还是向上抛出?
如果选择向上抛出,我们应该选择抛出哪种类型的异常呢?是受检异常还是非受检异常?
我们下文会对此介绍。
常见的编译时异常有:
- FileNotFoundException:当尝试打开由指定路径表示的文件失败时抛出
- ClassNotFoundException:当应用程序尝试通过其字符串名称加载类失败时抛出,以下三种方法加载类:
- Class.forName(java.lang.String)
- ClassLoader.findSystemClass(java.lang.String)
- ClassLoader.loadClass(java.lang.String, boolean)
常见的运行时异常有:
- 非法参数异常(IllegalArgumentException):当传入了非法或不正确的参数时抛出
- 空指针异常(NullPointerException):当在需要对象的情况下使用了 null 时抛出。
- 下标访问越界异常(IndexOutOfBoundsException):当某种索引(例如数组,字符串或向量)的索引超出范围时抛出。
- 类型转换异常(ClassCastException):当尝试将对象转换为不是实例的子类时抛出。
- 运算异常(ArithmeticException):运算条件出现异常时抛出。例如,“除以零”的整数。
Java 异常类的结构
如何处理函数抛出的异常
在函数抛出异常的时候,我们该怎么处理呢?是吞掉还是向上抛出?
如果选择向上抛出,我们应该选择抛出哪种类型的异常呢?是受检异常还是非受检异常?
下面我们就对此介绍。
吞掉 or 抛出
在函数抛出异常的时候,我们该怎么处理?是吞掉还是向上抛出?
总结一下,在函数抛出异常的时候,一般有下面三种处理方法。
- 直接吞掉
- 原封不动地 re-throw
- 包装成新的异常 re-throw
直接吞掉。具体的代码示例如下所示:
public void func1() throws Exception1 {
// ...
}
public void func2() {
//...
try {
func1();
} catch (Exception1 e) {
//吐掉:try-catch打印日志
log.warn("...", e);
}
//...
}
原封不动地 re-throw。具体的代码示例如下所示:
public void func1() throws Exception1 {
// ...
}
//原封不动的re-throw Exception1
public void func2() throws Exception1 {
//...
func1();
//...
}
包装成新的异常 re-throw。具体的代码示例如下所示:
public void func1() throws Exception1 {
// ...
}
public void func2() throws Exception2 {
//...
try {
func1();
} catch (Exception1 e) {
// wrap成新的Exception2然后re-throw
throw new Exception2("...", e);
}
//...
}
当我们面对函数抛出异常的时候,应该选择上面的哪种处理方式呢?我总结了下面三个参考原则:
- 如果 func1() 抛出的异常是可以恢复,且 func2() 的调用方并不关心此异常,我们完全可以在 func2() 内将 func1() 抛出的异常吞掉;
- 如果 func1() 抛出的异常对 func2() 的调用方来说,也是可以理解的、关心的 ,并且在业务概念上有一定的相关性,我们可以选择直接将 func1 抛出的异常 re-throw;
- 如果 func1() 抛出的异常太底层,对 func2() 的调用方来说,缺乏背景去理解、且业务概念上无关,我们可以将它重新包装成调用方可以理解的新异常,然后 re-throw。
应该选择上面的哪种处理方式,总结来说就是从以下两个方面进行判断:
- 函数1 抛出的异常是否可以恢复
- 函数1 抛出的异常对于 函数2 的调用方来说是否可以理解、关心、业务概念相关
总之,是否往上继续抛出,要看上层代码是否关心这个异常。关心就将它抛出,否则就直接吞掉。
是否需要包装成新的异常抛出,看上层代码是否能理解这个异常、是否业务相关。如果能理解、业务相关就可以直接抛出,否则就封装成新的异常抛出。
对于处理函数抛出的异常,我们需要注意:
- 如果选择吞掉函数抛出的异常的话,我们必须把异常输出到日志系统,方便后续诊断。
- 如果把异常输出到日志系统时,我们在保证诊断信息足够的同时,也要考虑避免包含敏感信息,因为那样可能导致潜在的安全问题。
如果我们看 Java 的标准类库,你可能注意到类似 java.net.ConnectException,出错信息是类似“ Connection refused (Connection refused)”,而不包含具体的机器名、IP、端口等,一个重要考量就是信息安全。
类似的情况在日志中也有,比如,用户数据一般是不可以输出到日志里面的。
受检异常 or 非受检异常
在函数抛出异常的时候,如果选择向上抛出,我们应该选择抛出哪种类型的异常呢?是受检异常还是非受检异常?
对于代码 bug(比如下标访问越界、空指针)以及不可恢复的异常(比如数据库连接失败),即便我们捕获了,也做不了太多事情,我们希望程序能 fail-fast,所以,我们倾向于使用非受检异常,将程序终止掉。
对于可恢复异常、业务异常,比如提现金额大于余额的异常,我们更倾向于使用受检异常,明确告知调用者需要捕获处理。
处理异常的原则
尽量不要捕获通用异常
尽量不要捕获类似 Exception 这样的通用异常,而应该捕获特定异常(尽量缩小捕获的异常范围)。
下面举例说明,实例代码如下:
try {
// 业务代码
// …
Thread.sleep(1000L);
} catch (Exception e) {
// Ignore it
}
对于 Thread.sleep() 函数抛出的 InterruptedException,我们不应该捕获 Exception 通用异常,而应该捕获 InterruptedException 这样的特定异常。
这是因为我们要保证程序不会捕获到我们不希望捕获的异常。比如,我们更希望 RuntimeException 导致线程终止,而不是被捕获。
不要生吞异常
不要生吞(swallow)异常,尽量把异常信息记录到日志系统中。
这是异常处理中要特别注意的事情,因为生吞异常很可能会导致难以诊断的诡异情况。
如果我们没有把异常抛出,也没有把异常记录到日志系统,程序可能会在后续出现难以排查的 bug。没人能够轻易判断究竟是哪里抛出了异常,以及是什么原因产生了异常。
再来看一段代码
try {
// 业务代码
// …
} catch (IOException e) {
e.printStackTrace();
}
这段代码作为一段实验代码,是没有任何问题的,但是在产品代码中,通常都不允许这样处理。
你先思考一下这是为什么呢?
我们先来看看 printStackTrace() 的文档,开头就是“Prints this throwable and its backtrace to the standard error stream”。问题就在这里,在稍微复杂一点的生产系统中,标准出错(STERR)不是个合适的输出选项,因为你很难判到底输出到哪里去了。尤其是对于分布式系统,如果发生异常,但是无法找到堆栈轨迹(stacktrace),这纯属是为诊断设置障碍。
所以,最好使用产品日志,详细地将异常记录到日志系统里。
异常处理时,性能开销大的地方
我们从性能角度来审视一下 Java 的异常处理机制,这里有两个性能开销相对大的地方:
- try-catch 代码段会产生额外的性能开销,或者换个角度说,它往往会影响 JVM 对代码进行优化,所以建议仅捕获有必要的代码段,尽量不要一个大的 try 包住整段的代码;
- Java 每实例化一个 Exception,都会对当时的栈进行快照,这是一个相对比较重的操作。如果实例化 Exception 发生的非常频繁,这个开销可就不能被忽略了。
当我们的服务出现反应变慢、吞吐量下降的时候,检查发生最频繁的 Exception 也是一种思路。

