
集群节点宕机问题排查原创
问题反馈
朋友反馈k8s集群节点突然宕机了,怀疑是内存溢出。但是仔细检查了应用日志,节点日志之后,均没有发现out of memory记录
问题排查
思考深层次的原因,系统如果突然宕机,有可能是触发了内核的OOM-killer,最典型的就是swap空间满了,系统强杀进程。
于是让他检查了swap,发现压根没有开启
这里有一个奇怪的问题,377G的内存,cache就占了333G,并且这台机器刚刚重启。说明Cache可能回收不掉。
于是再次检查内核设备日志,终于在kubepod上发现了异常
dmesg | grep -i memory
内核日志:Memory cgroup out of memory kill process pid
问题已经清晰了,这是一个典型的cgroup memory导致的内存泄漏问题
cgroup memory内存泄漏。
k8s集群随着pod增多,运行久了之后就会出现不能创建pod的情况。执行kubectl describe pod命令可以发现 cannot allocate memory异常。重启对应的服务器之后异常提示才会消失。但继续随着运行时间推移,该问题依然会出现,最终内存会耗尽,系统会强杀节点释放内存。

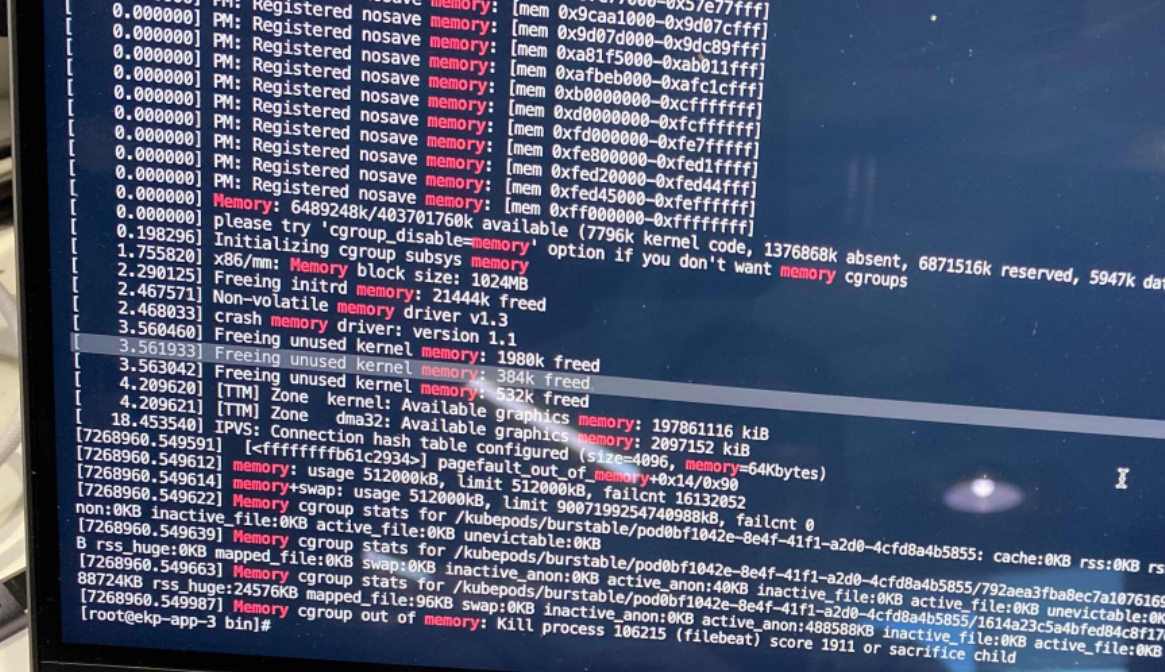
使用 cat /sys/fs/cgroup/memory/kubepods/memory.kmem.slabinfo 检查问题node,如下图则说明没有存在内存泄漏
如下图显示则说明存在内存泄漏
内核对每个cgroup 子系统的的内存地址页是有限制的,限制的大小定义在 kernel/cgroup.c #L139上。在 cgroup 创建一个内存地址之后,当开启了 kmem 功能,虽然 cgroup 的地址页删除了,但是内存不会回收。也就是说在3.1内核版本下,开启了 kmem 功能就会导致内存泄漏。该问题会导致可分配内存越来越少,直到无法创建新 pod 或节点宕机
注:该内存泄漏问题在3.10 的内核上存在,4.x的内核已经修复
通过内存分析。发现存在太多的 cgroup memory申请,slab占用过高,无法回收掉。
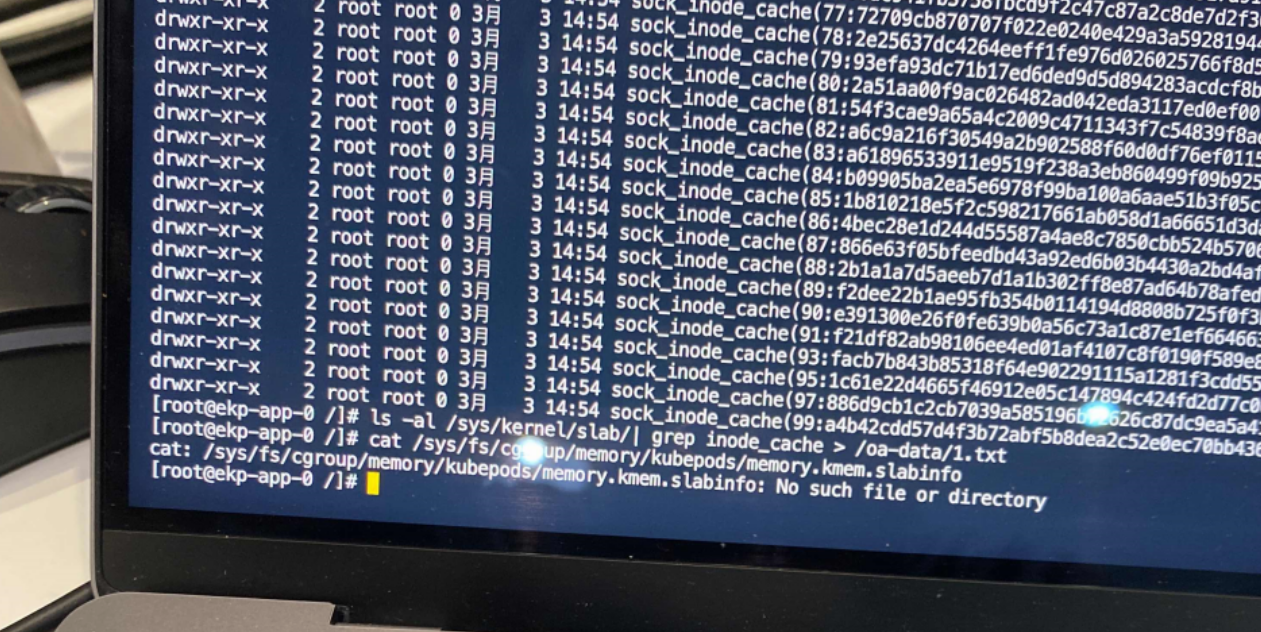
ls -al /sys/kernel/slab/| grep inode_cache |more
节点创建时通过 cgroup memory申请了slab,但是节点关闭时,这些slab却释放不掉。导致越积越多,最终将内存耗尽
内存速度比较快,所以缓存了一部分磁盘数据,称之为高速缓存。这部分缓存数据被调用之后会打上标记,称之为内存脏页,或者slab。
脏页达到一定比例之后,系统会调用sync函数进行回收,保证数据不会丢失。但是k8s节点在内核3.1下面是有bug的,这部分slab永远不会被回收掉,直到进程触发oomkiller
值得思考的是,为什么会申请这么多内存?根本原因是什么呢?还需要进一步去检索日志。
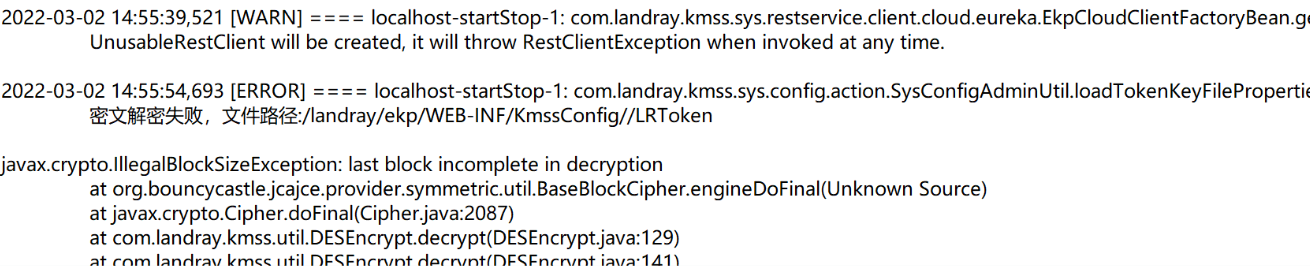
从应用日志可以看到,在宕机前一段时间,系统返回了大量的error,如下图
系统在高峰期不停的对token做解密操作,先是密文解密,后是明文解密。解密的过程中不停的通过CacheManager去申请缓存。接着又拿这些解密失败的token去鉴权,结果肯定也是失败的。于是形成了一个死循环。重复下面的流程
解密-申请内存-解密失败-重复鉴权-记录日志
代码死循环,再加上内存无法回收的内核bug,最终造成了频繁的宕机
备注:





解决方案
1:内核参数文件 /boot/grub2/grub.cfg中添加 cgroup.memory=nokmem 让系统禁用 cgroup的 kmem
2:内核参数文件 /boog/grub2/grub.cfg 中添加 cgroup_disable=memory 关掉整个cgroup memory
3:升级内核版本到4.x
4:改bug
问题复盘
遇到这种突然宕机的现象不要慌,先捞日志。应用日志,server日志,堆栈日志,内核设备日志,总能找到蛛丝马迹,然后再顺藤摸瓜探索问题产生的根源


