
设计和实现的对比:4种常见堆分析器进行内存泄漏故障排除转载
系统运行时间较长后,可用内存可能会减少,部分服务可能会出现故障。这是一个典型的内存泄漏问题,通常难以预测和识别。堆分析器(Heap profilers)是解决此类问题的有用工具。它们跟踪内存分配并帮助您找出程序堆中的信息并定位内存泄漏。
本文介绍如何使用堆分析器(Heap profilers),以及如何设计和实现广泛使用的堆分析器,如 Go heap profiler、gperftools、jemalloc 和 Bytehound。我希望这篇文章可以帮助您更好地理解堆分析器并将其用于您自己的项目。
在深入了解每个堆分析器的详细信息之前,我将在下表中向您展示它们的性能和指标准确性,以便您决定是否需要阅读整篇文章。
| 分析器 | 性能开销 | 指标质量 |
| go | 低 | 中等 |
| TCMalloc (gperftools) | 低 | 中等 |
| jemalloc | 低 | 中等 |
| Bytehound | 高 | 高 |
这些工具具有相似的技术设计。我将在 Go Heap Profiler 部分介绍它们,我强烈建议您先阅读该部分,然后再跳到其他部分。
什么是堆分析?
堆分析意味着收集或采样程序的堆分配,以帮助用户确定程序堆中的信息。它可用于定位内存泄漏、分析分配模式或发现分配大量内存的位置。
堆分析的工作原理
在详细介绍堆分析之前,让我们看看CPU分析是如何工作的,它更简单,有助于您了解堆分析的工作原理。
当我们分析 CPU 使用率时,我们需要选择一个特定的时间窗口。在此窗口中,CPU 分析器注册一个钩子,该钩子在目标程序中定期执行。有很多方法,例如 SIGPROF 信号。该钩子实时获取业务线程的堆栈跟踪。
然后,我们指定挂钩的执行频率。例如,如果我们将频率设置为 100 Hz,则意味着每 10 ms 收集一次应用程序代码的调用堆栈样本。当时间窗口结束时,我们聚合收集到的样本并获取每个函数被收集的次数。我们将这些数字与样本总数进行比较,以确定每个函数在 CPU 使用率中的相对比例。
我们可以通过这个模型找到CPU消耗高的函数,然后识别CPU热点。
CPU 分析和堆分析具有相似的数据结构。两者都使用堆栈跟踪 + 统计模型。如果你使用 Go 提供的 pprof,你会发现它们的显示格式几乎相同:
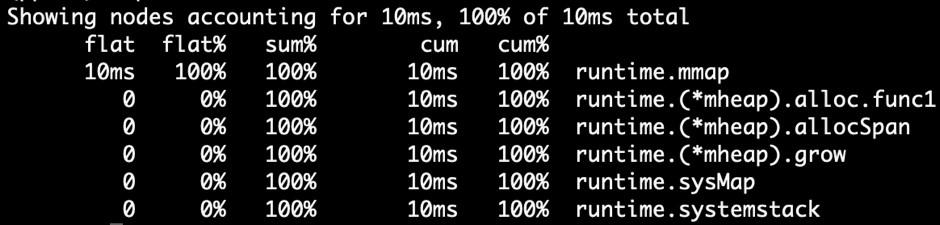
去 CPU 分析
但是,与 CPU 分析相比,堆分析不仅仅使用计时器定期收集数据。它将统计代码插入内存分配器。通常,堆分析器直接集成到内存分配器中。当应用程序分配内存时,它会获取当前堆栈跟踪并最终聚合样本。然后,我们可以知道每个函数的直接或间接内存分配。
heap profiling 堆栈跟踪 + 统计数据模型与 CPU profiling 模型一致。
接下来,我将描述几个堆分析器是如何实现和使用的。为了完整起见,我将解释每个堆分析器。如果您已经熟悉此类信息,则可以跳过它。
Go 堆分析器
在 PingCAP 工程师使用Golang作为他们的主要编程语言,因此在本文中,我将深入探讨 Go 堆分析器及其设计和实现。还将介绍其他堆分析器。但是,由于大多数堆分析器具有相同的设计,因此不会对其进行详细说明。
Go Heap Profiler 用法
Go 运行时有一个内置的分析器,堆是其中一种类型。我们可以如下打开一个调试
import _ "net/http/pprof"
go func() {
log.Print(http.ListenAndServe("0.0.0.0:9999", nil))
}()在程序运行时,我们可以使用以下命令行来获取当前的堆分析快照:
$ go tool pprof http://127.0.0.1:9999/debug/pprof/heap我们还可以直接在应用程序代码中的特定位置获取堆分析快照:
package main
import (
"log"
"net/http"
_ "net/http/pprof"
"time"
)
func main() {
go func() {
log.Fatal(http.ListenAndServe(":9999", nil))
}()
var data [][]byte
for {
data = func1(data)
time.Sleep(1 * time.Second)
}
}
func func1(data [][]byte) [][]byte {
data = func2(data)
return append(data, make([]byte, 1024*1024)) // alloc 1mb
}
func func2(data [][]byte) [][]byte {
return append(data, make([]byte, 1024*1024)) // alloc 1mbfunc1代码不断在和中分配内存func2。它每秒分配 2 MB 的堆内存。
程序运行一段时间后,我们可以执行以下命令获取配置文件快照并启动Web服务进行浏览:
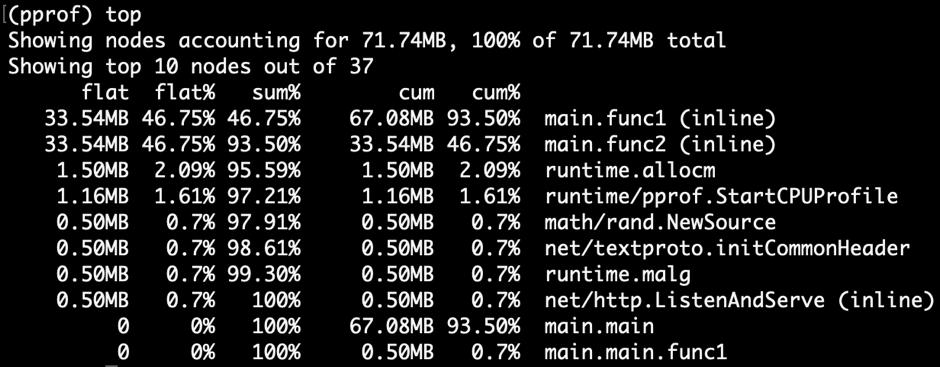
$ go tool pprof -http=":9998" localhost:9999/debug/pprof/heap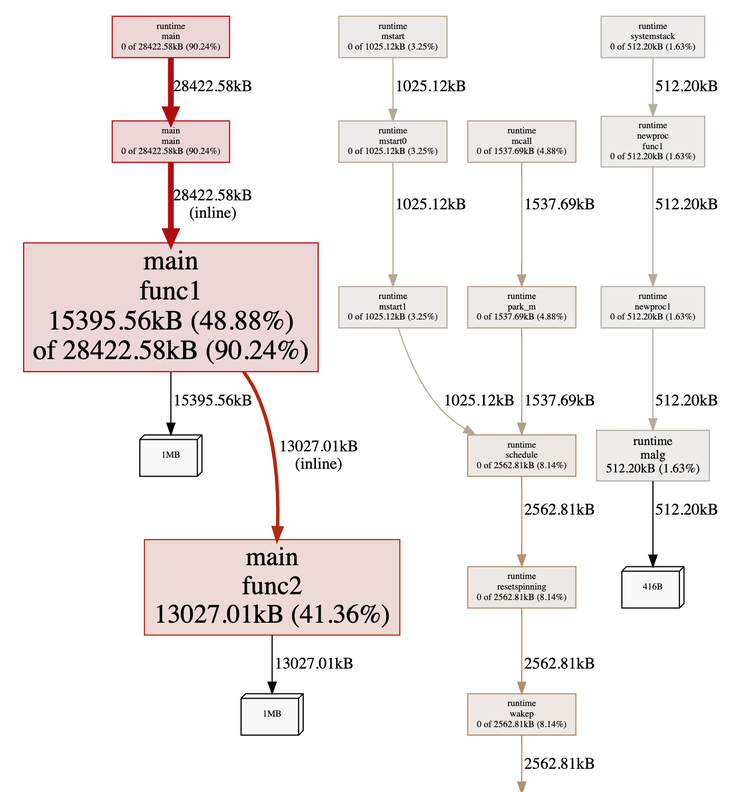
这张图告诉我们两个重要的事情。盒子越大,内存分配越大。我们还看到了函数调用之间的联系。在这个例子中,很明显func1andfunc2拥有最大的内存分配,并且func1调用func2.
请注意,由于堆分析也被采样(默认情况下,每次内存分配器分配 512 KB 内存时都会对调用堆栈进行采样),因此此处显示的内存大小小于分配的内存大小。与 CPU profiling 一样,该值仅计算相对比例,然后找到内存分配热点。
注意: 虽然 Go 运行时有逻辑来估计采样结果的原始大小,但这个结论不一定准确。
在此图中, ' 框中的 90.24% 中的 48.88%func1表示 cum% 的 flat%。
让我们通过从左上角的菜单中选择“顶部”来更改浏览方式。走着瞧:
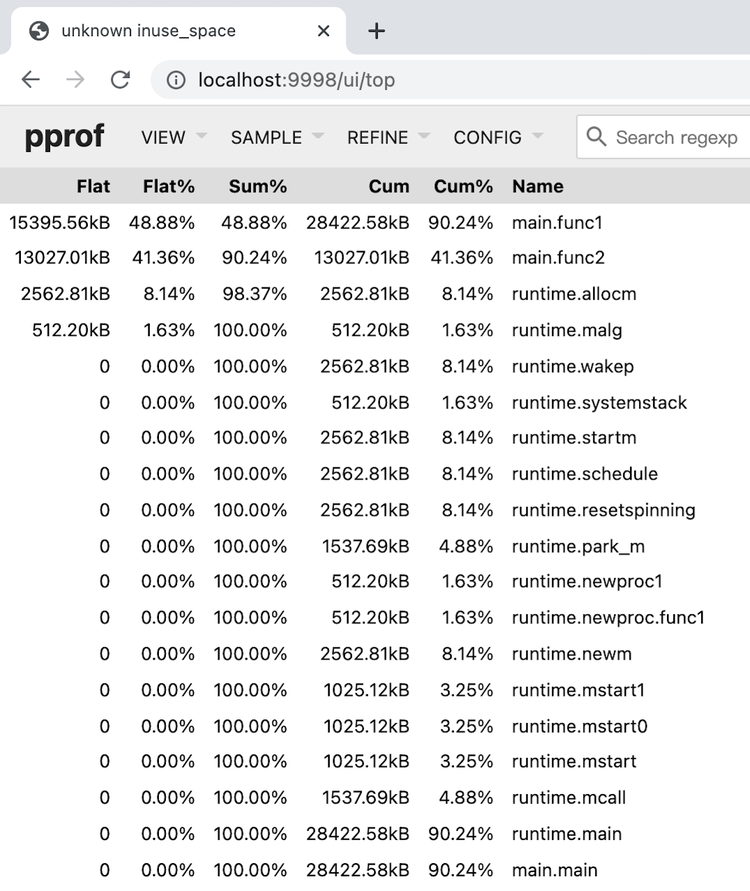
显示的字段是:
| Column | 定义 |
| Flat | 为函数分配的内存 |
| Flat% | Flat占总分配大小的比例 |
| Sum% | Flat%自上而下的累积;你可以知道从这一行到顶部分配了多少内存 |
| Cum | 为函数及其调用的子函数分配的内存 |
| Cum% | Cum占总分配大小的比例 |
| Name | 识别功能 |
通过观察 Go heap graph 中的 box size 或者查看 Go heap top list,我们可以找到一个特定的函数。Go 提供了更细粒度的代码行级分配源统计信息。在左上角,单击VIEW并在 菜单中单击Source。走着瞧:
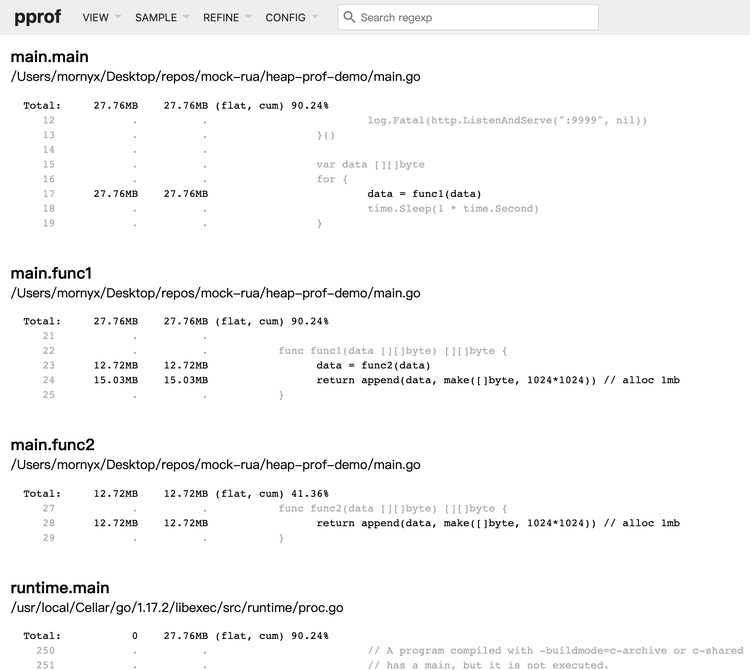
去堆源
在 CPU profiling 中,我们经常在火焰图中找到宽顶来快速识别热点函数。当然,由于数据模型的同质性,我们也可以使用火焰图来展示堆分析数据。在左上角,单击VIEW并在菜单中单击Flame Graph:
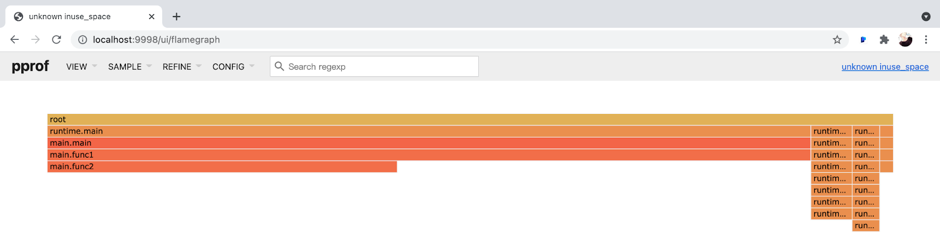
Go 堆火焰图
通过上面的方法,我们可以看到,func1并且func2拥有最高的内存分配。然而,在现实世界的案例中,我们无法轻易找到根本原因。因为我们得到了某个时刻的快照,所以这不足以识别内存泄漏问题。我们需要增量数据来判断哪个函数的内存不断增加。因此,我们可以在一段时间后再次获取堆配置文件,并观察两个结果之间的差异。
Go Heap Profiler 实现
之前,我提到过,通常堆分析器集成到内存分配器中。当应用程序分配内存时,堆分析器获取当前堆栈跟踪。围棋也是。
Go 的内存分配入口mallocgc()是src/runtime/malloc.go. 该mallocgc()函数分配一段内存。这是其代码的重要部分
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
// ...
if rate := MemProfileRate; rate > 0 {
// Note cache c only valid while m acquired; see #47302
if rate != 1 && size < c.nextSample {
c.nextSample -= size
} else {
profilealloc(mp, x, size)
}
}
// ...
}
func profilealloc(mp *m, x unsafe.Pointer, size uintptr) {
c := getMCache()
if c == nil {
throw("profilealloc called without a P or outside bootstrapping")
}
c.nextSample = nextSample()
mProf_Malloc(x, size)
}代码表明,每次mallocgc()分配 512 KB 的堆内存时,都会调用profilealloc()来记录一次堆栈跟踪。
获得所有函数的准确内存分配似乎很有用,但性能开销巨大。作为用户模式库函数,malloc()经常被应用程序调用。如果每次malloc()调用都会导致堆栈回溯,那么开销几乎是无法接受的,尤其是在服务器端进行 profiling 持续很长时间的情况下。选择抽样并不是一个更好的结果,而只是一种妥协。
当然,我们也可以修改MemProfileRate变量。如果我们将其设置为1,则每次mallocgc()调用时,都会记录一次堆栈跟踪;如果我们将其设置为 0,则堆分析将关闭。您可以根据实际场景权衡性能和准确性。
请注意,当我们设置MemProfileRate为正常的采样粒度时,该值并不完全准确。相反,它是从指数分布中随机选择的MemProfileRate,平均值为
// nextSample returns the next sampling point for heap profiling. The goal is
// to sample allocations on average every MemProfileRate bytes, but with a
// completely random distribution over the allocation timeline; this
// corresponds to a Poisson process with parameter MemProfileRate. In Poisson
// processes, the distance between two samples follows the exponential
// distribution (exp(MemProfileRate)), so the best return value is a random
// number taken from an exponential distribution whose mean is MemProfileRate.
func nextSample() uintptr在许多情况下,内存分配是有规律的。如果以固定的粒度进行采样,最终的结果可能会有很大的误差。每次采样都可能存在特定类型的内存分配。这就是这里选择随机化的原因。
不仅堆分析有错误,而且各种基于采样的分析器总是有错误(例如,SafePoint Bias)。当我们审查基于抽样的分析结果时,我们必须考虑错误的可能性。
中的mProf_Malloc()函数src/runtime/mprof.go负责采样:
// Called by malloc to record a profiled block.
func mProf_Malloc(p unsafe.Pointer, size uintptr) {
var stk [maxStack]uintptr
nstk := callers(4, stk[:])
lock(&proflock)
b := stkbucket(memProfile, size, stk[:nstk], true)
c := mProf.cycle
mp := b.mp()
mpc := &mp.future[(c+2)%uint32(len(mp.future))]
mpc.allocs++
mpc.alloc_bytes += size
unlock(&proflock)
// Setprofilebucket locks a bunch of other mutexes, so we call it outside of proflock.
// This reduces potential contention and chances of deadlocks.
// Since the object must be alive during call to mProf_Malloc,
// it's fine to do this non-atomically.
systemstack(func() {
setprofilebucket(p, b)
})
}
func callers(skip int, pcbuf []uintptr) int {
sp := getcallersp()
pc := getcallerpc()
gp := getg()
var n int
systemstack(func() {
n = gentraceback(pc, sp, 0, gp, skip, &pcbuf[0], len(pcbuf), nil, nil, 0)
})
return n
}堆栈回溯是在分析器调用callers()和时gentraceback(),获取当前调用堆栈,并将其存储在stk数组中。该数组存储程序计数器地址。很多场景都使用了这种技术。例如,当程序崩溃时,堆栈会被扩展。
在上面的代码块中:
| Variable | 目的 | x86-64 寄存器 |
pc |
程序计数器 | RIP |
fp |
帧指针 | RBP |
sp |
堆栈指针 | RSP |
有一种老的调用栈回溯实现方式:x86-64平台的RBP寄存器为了调用约定必须存储函数调用时的栈基地址,RBP寄存器不作为通用寄存器使用。call 指令首先将 RIP(返回地址)压入堆栈。因此,我们只需要确保入栈的第一行数据就是当前的 RBP。然后,所有函数的栈基地址都以RBP开头,形成一个地址链表。为了得到 RIP 数组,我们只需要将每个 RBP 地址下移一个单位。
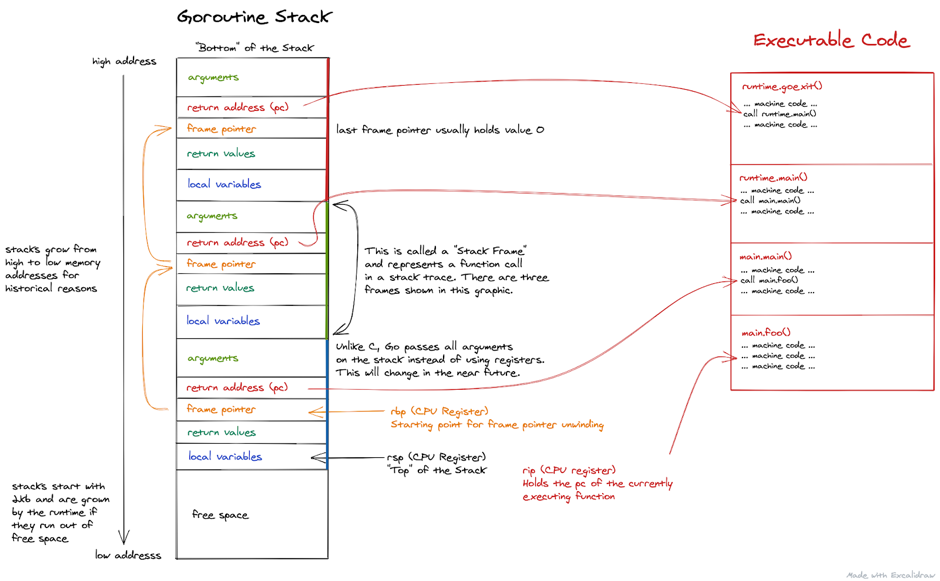
注意:在这个图中,所有的 Go 参数都是通过堆栈传递的。现在这已经过时了。从 1.17 版本开始,Go 支持寄存器传递。
因为 x86-64 将 RBP 归类为通用寄存器,GNU Compiler Collection (GCC) 等编译器默认不再使用 RBP 来保存堆栈基地址——除非它被特定选项打开。但是,Go 编译器保留了这个特性,因此在 Go 中使用 RBP 进行堆栈回溯是可行的。
但是 Go 并没有采用这种简单的解决方案,因为它在某些场景下可能会导致问题。例如,如果一个函数是内联的,那么通过 RBP 回溯获得的调用堆栈就丢失了。该方案还需要在常规函数调用之间插入额外的指令,并且占用额外的通用寄存器。即使我们不需要堆栈回溯,它也有性能开销。
每个 Go 二进制文件都包含一个gopclntab部分,它是 Go 程序计数器行表的缩写。该文件维护以下信息:
pcto的映射sp及其返回地址。这样,我们就不需要依赖fp,可以直接通过查表来完成一系列pc链表。- 是否进行了 inline 优化的信息
pc及其功能。因此,我们不会在堆栈回溯期间丢失内联函数帧。 - 符号表保存了对应的代码信息(如函数名和行号)
pc。因此,我们终于可以看到人类可读的恐慌结果或分析结果,而不是一大堆地址信息。
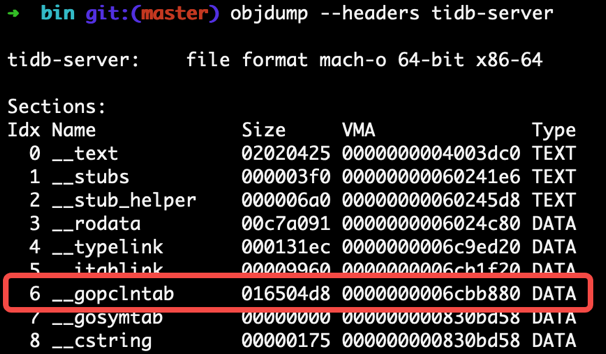
gopclntab
与 Go 不同gopclntab,DWARF 是一种标准化的调试格式。Go 编译器还将 DWARF (v4) 信息添加到其生成的二进制文件中,因此一些非 Go 生态系统外部工具可以使用它来调试 Go 程序。DWARF 中包含的信息是 gopclntab 的超集。
当我们pc通过栈回溯技术(前面代码块中的函数)得到数组时gentraceback(),我们不需要立即符号化它。符号化的成本很高。pc我们可以先通过指针地址栈来聚合数组。“聚合”是指在 hashmap 中累积具有相同数组内容的样本。
该stkbucket()函数获取对应的bucketstk作为key,然后在其中累积字段进行统计。
注意memRecord有多组memRecordCycle数据用于统计:
type memRecord struct {
active memRecordCycle
future [3]memRecordCycle
}当我们积累数据时,以全局变量为下标memRecordCycle访问一组。在每轮垃圾回收 (GC) 之后递增。然后,记录三轮GC之间的内存分配情况。当一轮 GC 完成时,将上一轮 GC 和本轮 GC 之间的内存分配和释放纳入最终显示的统计信息中。这种设计使我们无法在执行 GC 之前获取堆配置文件。因此,我们不会看到大量无用的临时内存分配。我们还可能在 GC 周期的不同时间看到不稳定的堆内存状态。mProf.cyclemProf.cycle
最后,setprofilebucket()被调用来记录bucket上mspan分配的地址,并被mProf_Free()调用来记录未来GC中相应的内存释放情况。
这样,这个桶集合就在 Go 运行时维护了。当我们执行堆分析时,例如,当我们调用 时pprof.WriteHeapProfile(),桶集合被访问并转换为 pprof 输出所需的格式。
这也是堆分析和 CPU 分析之间的区别:
- CPU 分析仅在分析时间窗口期间对应用程序具有采样开销。
- 堆分析采样不断发生。到目前为止,执行分析只是转储数据快照。
接下来,我们将进入 C/C++/ Rust的世界。幸运的是,因为大多数堆分析器都有类似 的实现原理,所以我们可以应用很多我们已经学到的东西。Go heap profiling 是从 Google TCMalloc 移植过来的,它们有类似的实现。
Gperftools 堆分析器
Gperftools (原谷歌性能工具)是一个工具包,包括堆分析器、堆检查器、CPU分析器和其他工具。
它与Go有很深的关系,所以我会在Go之后立即介绍它。
Go 运行时移植的 Google TCMalloc 有两个社区版本:
- TCMalloc,一个没有附加功能的纯 malloc 实现。
- gperftools,具有堆分析功能和其他支持工具集的 malloc 实现,包括pprof。gperftools 的主要作者是与 Jeff Dean 结对编程的 Sanjay Ghemawat。
Gperftools 堆分析器用法
Google 使用 gperftools 堆分析器来分析 C++ 程序的堆内存分配。它可以:
- 确定程序堆中当前的内容。
- 查找内存泄漏。
- 寻找进行大量分配的位置。
Go 在运行时直接将采集代码硬编码到内存分配函数中。同样,gperftools 将获取代码植入 libtcmalloc 的 malloc 实现中。要替换libc默认的malloc实现,我们需要-ltcmalloc在项目编译链接阶段执行链接库。
我们可以使用 Linux 动态链接机制来替换 libc 在运行时默认的 malloc 实现:
$ pprof --gv gfs_master /tmp/profile.0100.heap当LD_PRELOAD指定libtcmalloc.so时,malloc()我们程序中默认链接的 将被覆盖。Linux 动态链接器确保LD_PRELOAD首先执行 指定的版本。
在我们运行链接到 libtcmalloc 的可执行文件之前,如果我们将HEAPPROFILE环境变量设置为一个文件名,那么当程序执行时,堆配置文件数据会写入该文件。
默认情况下,每当我们的程序分配 1 GB 内存,或者每当程序的内存使用高水位标记增加 100 MB 时,就会执行堆配置文件转储。您可以通过环境变量修改参数。
我们可以使用 gperftools 附带的 pprof 脚本来分析转储的配置文件。用法与 Go 中的用法几乎相同。
$ pprof --gv gfs_master /tmp/profile.0100.heap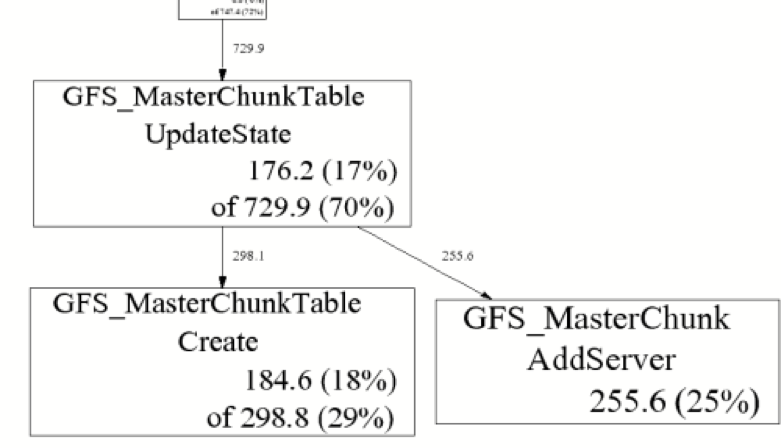
$ pprof --text gfs_master /tmp/profile.0100.heap
255.6 24.7% 24.7% 255.6 24.7% GFS_MasterChunk::AddServer
184.6 17.8% 42.5% 298.8 28.8% GFS_MasterChunkTable::Create
176.2 17.0% 59.5% 729.9 70.5% GFS_MasterChunkTable::UpdateState
169.8 16.4% 75.9% 169.8 16.4% PendingClone::PendingClone
76.3 7.4% 83.3% 76.3 7.4% __default_alloc_template::_S_chunk_alloc
49.5 4.8% 88.0% 49.5 4.8% hashtable::resize
...在上面的代码块中,从左到右依次是 Flat (MB)、Flat (%)、Sum (%)、Cum (MB)、Cum (%) 和 Name。
Gperftools 堆分析器实现
TCMalloc 将采样逻辑添加到malloc()和new运算符。当根据条件触发采样挂钩时,将RecordAlloc执行以下名为 的函数:
// Record an allocation in the profile.
static void RecordAlloc(const void* ptr, size_t bytes, int skip_count) {
// Take the stack trace outside the critical section.
void* stack[HeapProfileTable::kMaxStackDepth];
int depth = HeapProfileTable::GetCallerStackTrace(skip_count + 1, stack);
SpinLockHolder l(&heap_lock);
if (is_on) {
heap_profile->RecordAlloc(ptr, bytes, depth, stack);
MaybeDumpProfileLocked();
}
}
void HeapProfileTable::RecordAlloc(
const void* ptr, size_t bytes, int stack_depth,
const void* const call_stack[]) {
Bucket* b = GetBucket(stack_depth, call_stack);
b->allocs++;
b->alloc_size += bytes;
total_.allocs++;
total_.alloc_size += bytes;
AllocValue v;
v.set_bucket(b); // also did set_live(false); set_ignore(false)
v.bytes = bytes;
address_map_->Insert(ptr, v);
}执行过程如下:
GetCallerStackTrace()被调用以获取调用堆栈。GetBucket()以调用栈为hashmap key调用,获取对应的bucket。- 存储桶统计信息被累积。
因为没有 GC,所以这个采样过程比 Go 的要简单得多。从变量命名上,我们知道 Go 运行时中的 profiling 代码就是从这里移植过来的。
sampler.h详细描述了 gperftools 采样规则。gperftools 的平均样本步长为 512 KB,与 Go 堆分析器相同。
我们还需要添加逻辑free()或者delete算子来记录内存释放。这比使用 GC 的 Go 堆分析器要简单得多:
// Record a deallocation in the profile.
static void RecordFree(const void* ptr) {
SpinLockHolder l(&heap_lock);
if (is_on) {
heap_profile->RecordFree(ptr);
MaybeDumpProfileLocked();
}
}
void HeapProfileTable::RecordFree(const void* ptr) {
AllocValue v;
if (address_map_->FindAndRemove(ptr, &v)) {
Bucket* b = v.bucket();
b->frees++;
b->free_size += v.bytes;
total_.frees++;
total_.free_size += v.bytes;
}
}然后,我们需要找到对应的bucket和freesummary相关的字段。
现代 C、C++ 和 Rust 程序通常依赖 libunwind 库来获取调用堆栈。与 Go 的栈回溯原理类似,libunwind 不选择帧指针回溯模式,它依赖于程序特定部分中记录的展开表。不同之处在于 Go 依赖于gopclntab在其自己的生态系统中创建的特定节,而 C、C++ 和 Rust 程序依赖于.debug_frame节或.eh_frame节。
.debug_frame由 DWARF 标准定义。Go 编译器也包含此信息,但它本身不使用,仅保留给第三方工具使用。GNU 编译器集合 (GCC) 仅在启用参数.debug_frame时将调试信息写入。-g
.eh_frame更现代,并在Linux Standard Base中定义。它让编译器在程序集的相应位置插入一些伪指令,包括CFI 指令和调用帧信息。这些指令帮助汇编器生成.eh_frame包含展开表的最后部分。
以下面的代码为例:
// demo.c
int add(int a, int b) {
return a + b;
}我们cc -S demo.c用来生成汇编代码;您可以使用 GCC 或 Clang 编译器。请注意,-g此处未使用该参数。
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 11, 0 sdk_version 11, 3
.globl _add ## -- Begin function add
.p2align 4, 0x90
_add: ## @add
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl -4(%rbp), %eax
addl -8(%rbp), %eax
popq %rbp
retq
.cfi_endproc
## -- End function
.subsections_via_symbols生成的汇编代码包括许多.cfi_以 - 为前缀的伪指令,它们是 CFI 指令。
Jemalloc 堆分析器
默认情况下,TiKV使用 jemalloc 作为其内存分配器。
Jemalloc 堆分析器用法
Jemalloc 包含堆分析功能,但默认情况下未启用。当我们编译代码时,我们需要指定--enable-prof参数。
./autogen.sh
./configure --prefix=/usr/local/jemalloc-5.1.0 --enable-prof
make
make install就像我们对 TCMalloc 所做的那样,我们可以通过 jemalloc 将 jemalloc 链接到程序,或者用 jemalloc through-ljemalloc覆盖 libc 。malloc()LD_PRELOAD
我们以 Rust 程序为例,展示如何通过 jemalloc 进行堆 profiling:
fn main() {
let mut data = vec![];
loop {
func1(&mut data);
std::thread::sleep(std::time::Duration::from_secs(1));
}
}
fn func1(data: &mut Vec<Box<[u8; 1024*1024]>>) {
data.push(Box::new([0u8; 1024*1024])); // alloc 1mb
func2(data);
}
fn func2(data: &mut Vec<Box<[u8; 1024*1024]>>) {
data.push(Box::new([0u8; 1024*1024])); // alloc 1mb
}我们在 Rust 中每秒分配 2 MB 的堆内存:每个 1 MB 用于func1和func2。func1来电func2。
我们使用rustc不带任何参数来编译文件。要启动程序,我们执行以下命令:
$ export MALLOC_CONF="prof:true,lg_prof_interval:25"
$ export LD_PRELOAD=/usr/lib/libjemalloc.so
$ ./demoMALLOC_CONF指定jemalloc相关参数。prof:true启用分析器,log_prof_interval:25每次分配 2^25 字节 (32 MB) 的堆内存时转储一个配置文件。
有关更多MALLOC_CONF选项,请参阅此文档。
一段时间后,我们可以看到生成了一些profile文件。

jemalloc 提供了 jeprof,一个类似于 TCMalloc pprof 的工具。事实上,它是从 pprof Perl 脚本派生出来的。我们可以使用 jeprof 来查看配置文件。
$ jeprof ./demo jeprof.7262.0.i0.heap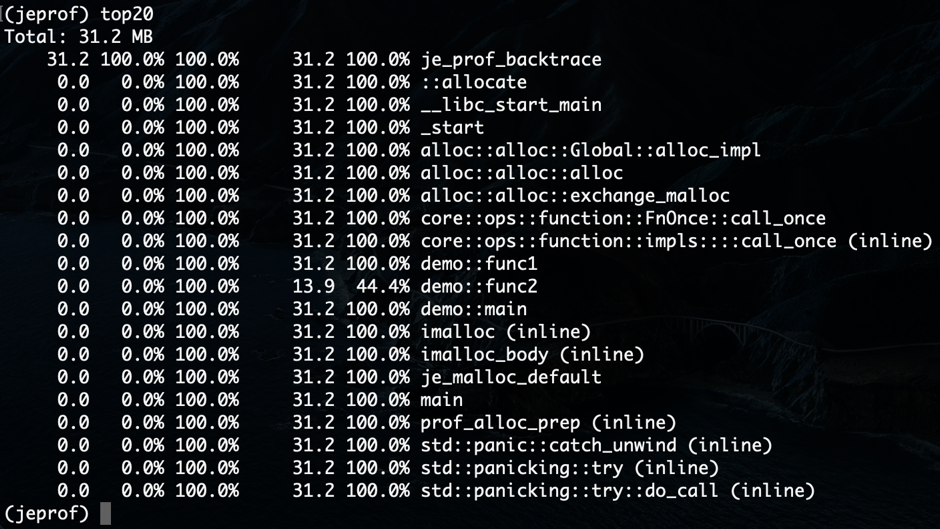
杰普夫
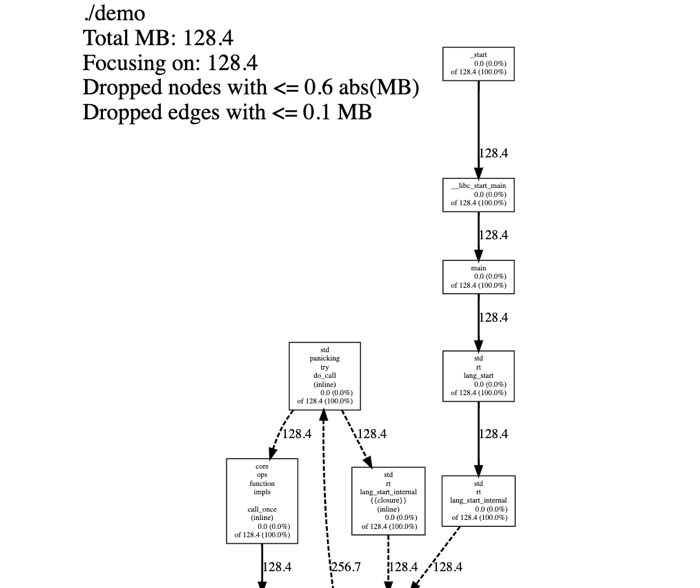
jeprof 可以生成与 Go 和 gperftools 相同的图:
$ jeprof --gv ./demo jeprof.7262.0.i0.heap
Jemalloc Heap Profiler 使用实现
与 TCMalloc 类似,jemalloc 将采样逻辑添加到malloc():
JEMALLOC_ALWAYS_INLINE int
imalloc_body(static_opts_t *sopts, dynamic_opts_t *dopts, tsd_t *tsd) {
// ...
// If profiling is on, get our profiling context.
if (config_prof && opt_prof) {
bool prof_active = prof_active_get_unlocked();
bool sample_event = te_prof_sample_event_lookahead(tsd, usize);
prof_tctx_t *tctx = prof_alloc_prep(tsd, prof_active,
sample_event);
emap_alloc_ctx_t alloc_ctx;
if (likely((uintptr_t)tctx == (uintptr_t)1U)) {
alloc_ctx.slab = (usize <= SC_SMALL_MAXCLASS);
allocation = imalloc_no_sample(
sopts, dopts, tsd, usize, usize, ind);
} else if ((uintptr_t)tctx > (uintptr_t)1U) {
allocation = imalloc_sample(
sopts, dopts, tsd, usize, ind);
alloc_ctx.slab = false;
} else {
allocation = NULL;
}
if (unlikely(allocation == NULL)) {
prof_alloc_rollback(tsd, tctx);
goto label_oom;
}
prof_malloc(tsd, allocation, size, usize, &alloc_ctx, tctx);
} else {
assert(!opt_prof);
allocation = imalloc_no_sample(sopts, dopts, tsd, size, usize,
ind);
if (unlikely(allocation == NULL)) {
goto label_oom;
}
}
// ...
}
调用累加hashmapprof_malloc_sample_object()中prof_malloc()对应的调用栈记录:
void
prof_malloc_sample_object(tsd_t *tsd, const void *ptr, size_t size,
size_t usize, prof_tctx_t *tctx) {
// ...
malloc_mutex_lock(tsd_tsdn(tsd), tctx->tdata->lock);
size_t shifted_unbiased_cnt = prof_shifted_unbiased_cnt[szind];
size_t unbiased_bytes = prof_unbiased_sz[szind];
tctx->cnts.curobjs++;
tctx->cnts.curobjs_shifted_unbiased += shifted_unbiased_cnt;
tctx->cnts.curbytes += usize;
tctx->cnts.curbytes_unbiased += unbiased_bytes;
// ...
}jemalloc注入的逻辑free()与TCMalloc类似。jemalloc 还使用 libunwind 进行堆栈回溯
Bytehound 堆分析器
Bytehound 是用 Rust 编写的,是 Linux 平台的内存分析器。由于它的高性能开销,我们不能在 TiKV 中使用它。但是,我们将简要介绍其用法。我们的重点是如何实施。
Bytehound 堆分析器用法
我们可以在 Bytehound 的 Releases 页面下载 Bytehound 的二进制动态库,仅 Linux 平台支持。
然后,像 TCMalloc 或 jemalloc 一样,Bytehound 通过LD_PRELOAD. 在这里,我们假设我们正在运行相同的 Rust 程序,但在 Bytehound 堆分析器部分存在内存泄漏:
$ LD_PRELOAD=./libbytehound.so ./demo接下来,memory-profiling_*.dat在程序的工作目录中生成一个文件。这是 Bytehound 的堆分析的产物。与其他堆分析器不同,此文件会不断更新,而不是每次特定时间生成一个新文件。
然后,我们执行下面的命令打开一个web端口来实时分析上面的文件:
$ ./bytehound server memory-profiling_*.dat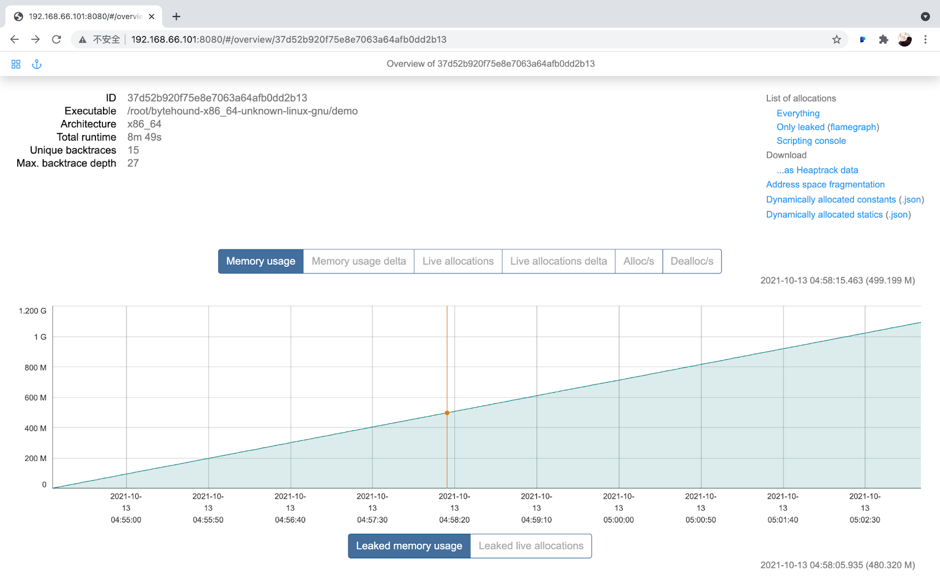
我们可以点击右上角的Flamegraph来查看flamegraph:

从火焰图中,我们可以看到,demo::func1并且demo::func2是内存热点。
要了解有关 Bytehound 的更多信息,请参阅其文档。
Bytehound 堆分析器实现
Bytehound 替换了用户默认的 malloc 实现。但是,它没有实现内存分配器;它是基于 jemalloc 打包的。
// Entry
#[cfg_attr(not(test), no_mangle)]
pub unsafe extern "C" fn malloc( size: size_t ) -> *mut c_void {
allocate( size, AllocationKind::Malloc )
}
#[inline(always)]
unsafe fn allocate( requested_size: usize, kind: AllocationKind ) -> *mut c_void {
// ...
// Call jemalloc for memory allocation
let pointer = match kind {
AllocationKind::Malloc => {
if opt::get().zero_memory {
calloc_real( effective_size as size_t, 1 )
} else {
malloc_real( effective_size as size_t )
}
},
// ...
};
// ...
// Stack traceback
let backtrace = unwind::grab( &mut thread );
// ...
// Record samples
on_allocation( id, allocation, backtrace, thread );
pointer
}
// xxx_real links to jemalloc implementation
#[cfg(feature = "jemalloc")]
extern "C" {
#[link_name = "_rjem_mp_malloc"]
fn malloc_real( size: size_t ) -> *mut c_void;
// ...
}每次分配内存时,Bytehound 都会执行堆栈回溯和记录。没有采样逻辑。on_allocation挂钩将分配记录发送到通道。统一处理器线程消费通道中的记录并异步处理记录。
pub fn on_allocation(
id: InternalAllocationId,
allocation: InternalAllocation,
backtrace: Backtrace,
thread: StrongThreadHandle
) {
// ...
crate::event::send_event_throttled( move || {
InternalEvent::Alloc {
id,
timestamp,
allocation,
backtrace,
}
});
}
#[inline(always)]
pub(crate) fn send_event_throttled< F: FnOnce() -> InternalEvent >( callback: F ) {
EVENT_CHANNEL.chunked_send_with( 64, callback );
}EVENT_CHANNEL的实现是Mutex<Vec>:
pub struct Channel< T > {
queue: Mutex< Vec< T > >,
condvar: Condvar
}
测试堆分析器性能开销
在本节中,我们将测量上述堆分析器的性能开销。测量方法基于场景。
我们分别在相同的测试环境中运行测试:
| 关键模块 | 规格 |
| Host | 英特尔 NUC11PAHi7 |
| 中央处理器 | Intel Core i7-1165G7 2.8GHz~4.7GHz 4核8线程 |
| 内存 | 金士顿 64G DDR4 3200MHz |
| 硬盘 | 三星 980PRO 1T SSD PCIe4。 |
| 操作系统 | Arch Linux Kernel-5.14.1 |
Go
在 Go 中,我们使用TiDB(一个开源的分布式 SQL 数据库)+ unistore 来部署单个节点,调整runtime.MemProfileRate参数,并使用 sysbench 来衡量性能。
相关软件版本及压力测试参数为:
| 软件 | Version |
| Go | 1.17.1 |
| TiDB | v5.3.0-alpha-1156-g7f36a07de |
| Commit hash | 7f36a07de9682b37d46240b16a2107f5c84941ba |
| Sysbench parameter | 规格 |
| Version | 1.0.20 |
| Tables | 8 |
| 表大小 | 100,000 |
| 线程 | 128 |
| Operation | oltp_read_only |
我们得到以下结果:
| MemProfileRate | 结果 |
| 0:不记录 | 事务:1,505,224(每秒 2,508.52)查询:24,083,584(每秒 40,136.30)延迟(AVG):51.02 毫秒延迟(P95):73.13 毫秒 |
| 512 KB:记录样本 | 事务:1,498,855(每秒 2,497.89)查询:23,981,680(每秒 39,966.27)延迟(AVG):51.24 毫秒延迟(P95):74.46 毫秒 |
| 1:全记录 | 事务:75,178(每秒 125.18)查询:1,202,848(每秒 2,002.82)延迟(AVG):1,022.04 毫秒延迟(P95):2,405.65 毫秒 |
与“不记录”相比,无论是每秒事务数 (TPS)、每秒查询数 (QPS) 还是 P95 延迟,512 KB 采样记录的性能开销一般都在 1% 以内。
我们预计全记录带来的性能开销会非常高;但是,出乎意料的高:TPS 和 QPS 下降了 20 倍,P95 延迟增加了 30 倍。
因为 heap profiling 是一个通用特性,所以我们无法准确衡量所有场景下的通用性能开销,只有在具体项目中的衡量结论才是有价值的。TiDB是一个计算密集型应用程序。但是,它可能不会像某些内存密集型应用程序那样频繁地分配内存。因此,本文所有结论只能作为参考,大家可以根据自己的应用场景来衡量开销。
TCMalloc 和 jemalloc 测试结果
我们基于 TiKV 测量了 TCMalloc 和 jemalloc,TiKV 是 TiDB 的分布式事务键值存储引擎。我们在机器上部署了一个Placement Driver (PD)进程(管理元数据的 TiDB 集群组件)和一个 TiKV 进程,并使用 go-ycsb 进行压力测试。重要参数如下:
threadcount=200
recordcount=100000
operationcount=1000000
fieldcount=20在我们开始 TiKV 之前,我们曾经LD_PRELOAD注入不同的 malloc hooks。TCMalloc 使用默认配置,类似于 Go 的 512 KB 采样;jemalloc 使用默认的采样策略并在每次分配 1 GB 堆内存时转储一个配置文件。
我们得到了以下结果,以每秒操作数 (OPS) 为单位。
| 分配器 | 测试结果 |
| 默认内存分配器 | OPS:119,037.2平均(微秒):4,186 P99(微秒):14,000 |
| TCMalloc | OPS:113,708.8平均(微秒):4,382 P99(微秒):16,000 |
| jemalloc | OPS:114,639.9平均(微秒):4,346 P99(微秒):15,000 |
TCMalloc 和 jemalloc 的性能几乎是一样的。与默认内存分配器相比,它们的 OPS 下降了约 4%,P99 延迟增加了约 10%。
我们了解到 TCMalloc 的实现与 Go heap pprof 的实现几乎相同,但是这里测得的数据并不一致。这可能是因为 TiKV 和 TiDB 分配内存的方式不同。我们无法准确衡量所有场景下的一般性能开销。我们的结论仅适用于具体项目。
Bytehound 测试结果
我没有将 Bytehound、TCMalloc 和 jemalloc 放在同一部分。这是因为我们在 TiKV 上使用 Bytehound 时,在启动过程中会出现死锁问题。
我推测由于Bytehound 的性能开销非常高,理论上它不能应用在 TiKV 生产环境中。我们只需要证明我的推测是否属实。
我的推测是基于 Bytehound 不包含示例逻辑的事实。每次采集到的数据通过channel发送到后台线程处理,channel简单的用Mutex+Vec封装。
我们使用一个名为mini-redis的简单项目来测量 Bytehound 的性能开销。因为目标只是确认是否能满足 TiKV 生产环境的要求,而不是准确测量数据,我们只统计比较 TPS。驱动代码片段如下:
var count int32
for n := 0; n < 128; n++ {
go func() {
for {
key := uuid.New()
err := client.Set(key, key, 0).Err()
if err != nil {
panic(err)
}
err = client.Get(key).Err()
if err != nil {
panic(err)
}
atomic.AddInt32(&count, 1)
}
}()
}我们启用 128 goroutine 来读取和写入服务器。读或写被认为是一个完整的操作。只计算次数,不测量延迟等指标。我们将总次数除以执行时间,得到启用 Bytehound 前后不同的 TPS。
结果如下:
| 配置 | 测试结果 |
| 默认配置 | 计数:11,784,571 时间:60 秒 TPS:196,409 |
| 启用Bytehound | 计数:5,660,952 时间:60 秒 TPS:94,349 |
TPS 下降了 50% 以上。
原文地址:https://dzone.com/articles/troubleshooting-memory-leaks-deep-dive-into-common-heap-profilers
原文作者:

