
【全网首发】关于可见性的这个例子,网上 95% 的文章都解释错了!原创
你好,我是坤哥
上周我在查阅资料时无意中搜到一篇解释 volatile 用法的博文,这篇博文排得很靠前,不过很遗憾,虽然结论是对的,但分析过程完全错误,而且我发现网上很多文章都用这个例子来解释 volatile 的用法,但绝大多数的分析过程也是错误的,所以决定写篇博文澄清一下
到底怎么回事呢,我们一起来看看,首先来看下下面这段代码有什么问题
public class Demo {
private static boolean running = true;
private static int count = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
while (running) {
count++;
}
System.out.println("count: " + count);
});
t1.start();
Thread.sleep(1000); // ①
Thread t2 = new Thread(() -> running = false);
t2.start();
t1.join();
t2.join();
}
}
我相信有一定 Java 基础的都能看问题所在:t1 线程会陷入死循环,主线程无法退出,网上很多文章说是因为可见性的原因,导致 t2 虽然修改了 running,但由于对 t1 不可见,导致 t1 中的 running 始终中 true,所以陷入了死循环,只需要在 running 前加上 volatile 即可,如下
public class Demo {
private static volatile boolean running = true;
...
}
结论(加 volatile)确实没有错,但分析过程大错特错,真实的原因其实是由于 JIT 的优化导致的,由于在线程 t2 开始前 sleep 了 1s,t1 不断地执行 while 循环,到一定次数后,JIT 会将这段代码判定为热点代码,进而会将 running 直接替换为 true,以致导致了死循环,如下:
public class Demo {
Thread t1 = new Thread(() -> {
// JIT 优化后的代码,将 running 直接替换为了 true
while (true) {
count++;
}
System.out.println("count: " + count);
});
...
}
}
那么怎么证明是因为 JIT 优化导致的死循环呢,有两种方案
关闭 JIT 优化
1。 在执行代码的时候加上如下选项来关闭 JIT 优化
java -Djava.compiler=NONE Demo
- 注释掉代码中的 Thread.sleep(1000);
这样的话线程 t1 中的 while 循环次数还未被 JIT 判定为热点代码前,由于 t2 修改了 running 为 false,由于缓存一致性协议,会将 running 值同步到 t1 中,所以循环也能正常退出
由此可知通过以上两种方案都可以让循环正常退出,那么怎么在不关闭 JIT 的情况下也能让循环正常退出呢,答案就是 volatile,众所周知,volatile 能通过添加内存屏障的方式来保证变量在各个 CPU 间的可见性,在变量前添加 volatile 也告诉 JIT 不要对其做过于激进的优化,所以循环也能正常退出
至此结论真相大白,那为什么会有这么多人产生不加 volatile 以致变量在各个 CPU 间不可见这样的误解呢,其实根本原因是因为对缓存一致性协议不了解所致,接下来我们就来好好聊一下这个话题,看完本文相信你对缓存一致性的原理了解会更进一步加深。
本文将会分以下几个方面来讲解缓存一致性协议
- CPU 缓存
- MESI 缓存一致性协议
- 对 MESI 协议的改进
- 内存屏障与 volatile
CPU 缓存
我们知道, CPU 是要从内存读取数据再执行的,CPU 执行很快,而从内存读取数据很慢,为了缓解这个矛盾,于是工程师在 CPU 和内存间加了缓存
这样的话,数据先从 Memory 读取到 Cache 中,然后每次 CPU 都从 Cache 中取数据,CPU 如果要修改数据,也是先将数据写入 Cache,然后再由 Cache 刷新至 Memory 中,CPU 以 cache line(缓存行)为读写单位,即 Memory 与 Cache 数据交换的最小单元为 cache line,也就是说哪怕你只是想从 Memory 读入一个字节到 Cache 中,它也会读取包含此字节的 cache line 到 cache 中,在 x86 中,一个 cache line 的大小默认为 64 byte

cache line:Memory 与 Cache 数据交换的最小单元
我们所熟悉的 JMM(Java Memory Model)就是基于以上的模型而建的
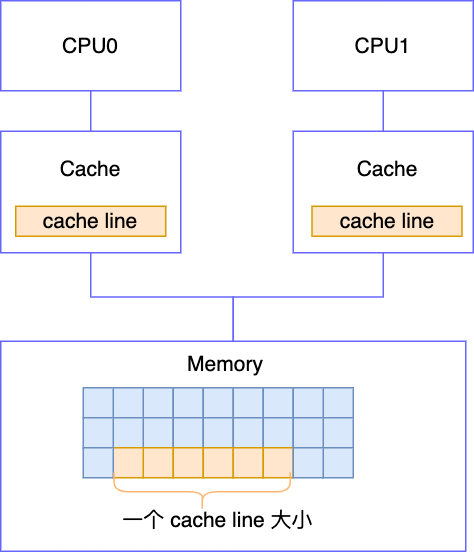
并发的线程都分配在各个 CPU 上执行,每个线程都有自己的工作内存,也就相当于 CPU 中的 Cache,共享变量的副本其实是在 cache line 中的
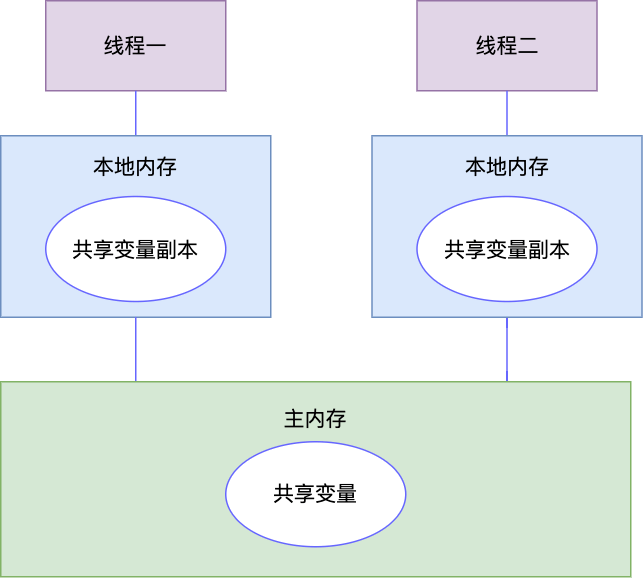
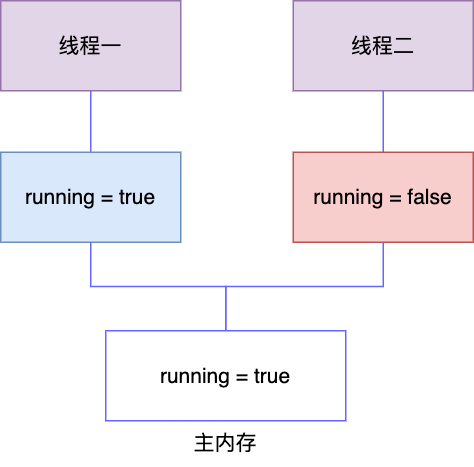
添加缓存确实有效提升了 CPU 的执行效率,但天下没有免费的午餐,添加缓存又引入了数据一致性的问题, Cache 里保存的是内存中共享变量的副本,如果 CPU 修改了 Cache 中的数据,而 Cache 没有及时刷新到 Memory,那就会造成此数据的修改对其他 CPU 不可见,就会出现问题,以开头的例子为例,t2 如果修改了 running = false,而未同步到其它 CPU ,那么情况就可能是下面这样,会导致线程一工作内存中的 running 一直是 true
很显然各个 CPU 的缓存不一致会导致各种 bug,于是为了保证 CPU 间缓存数据的一致性,科学家们引入了缓存一致性协议,比较常用的缓存一致性协议为 MESI 协议,所以接下来我们重点介绍一下 MESI 协议
MESI 缓存一致性协议
CPU 以缓存行为单位来读写数据,MESI 协议处理的对象也是缓存行,MESI 定义了 4 种不同的缓存行状态,如下
- M(Modified): 缓存行中的数据被修改,但未同步到主内存中
- E(Exclusive):当前 CPU 有此缓存行中的数据,其他 CPU 没有
- S(Shared):当前 CPU 和其他 CPU 缓存行中都有此数据
- I(Invalid):当前 CPU 中的缓存行数据无效,这往往是由于其他 CPU 对缓存行中的数据进行修改导致的,当前 CPU 如果去缓存中读数据的话,由于数据已经无效,会重新从内存中加载缓存行
接下来我们来举例看看 MESI 协议如何让 CPU 间的缓存保持一致,我们假设有两个 CPU ,CPU0 和 CPU 1,然后来看看当对这两个 CPU 执行一系列的读写操作时
CPU0 执行读操作
由于其它 CPU 无 a=0 的缓存行,所以其缓存行状态为 E
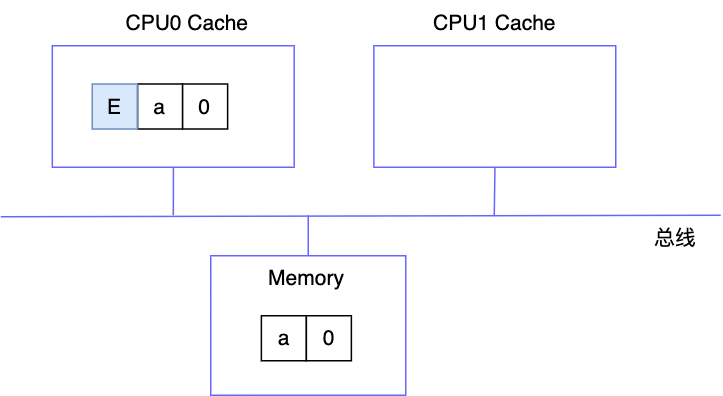
CPU0 将数据 a=1 写入 cache 中
此时缓存块被修改了,但由于其他 CPU 无此缓存块,所以修改后的数据无需同步至内存中,所以 CPU0 中缓存行的状态为 M
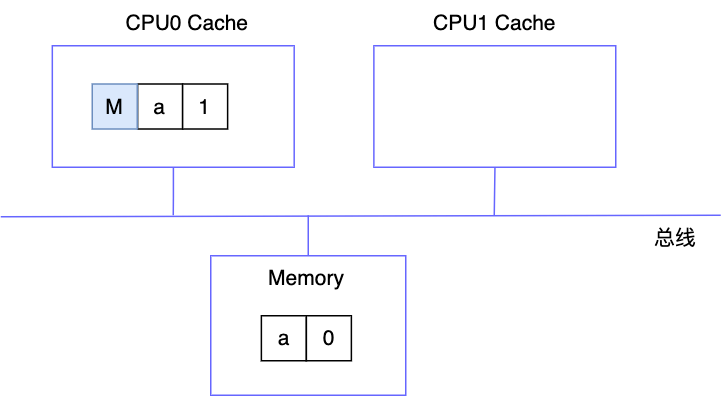
CPU1 读取数据 a
CPU1 读取 a 时,首先会通过总线向其他 CPU 广播一下读请求,然后 CPU0 发现自己的缓存块为 M,于是首先会将 a=1 刷新至内存,并将自己的缓存块标志位置为 S,然后才允许 CPU1 从内存中读数据,读取后由于 CPU0 也有此数据,所以会将其缓存行状态置为 S
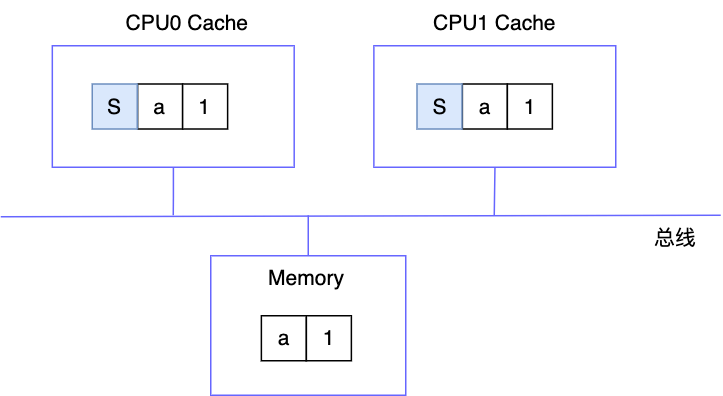
CPU1 写数据 a=2
由于 CPU1 中的缓存行状态为 S,所以它首先会往总线上广播一条 invalidate 消息,其他 CPU 收到消息后,会将其缓存行置为 I,然后发一个 invalidate ack 消息给 CPU2,CPU2 收到此消息后会将 a=2 写入缓存行中,然后再同步到内存,最后会将缓存行状态置为 E(因为其它 CPU 缓存行都失效了,所以缓存行为此 CPU 独有)
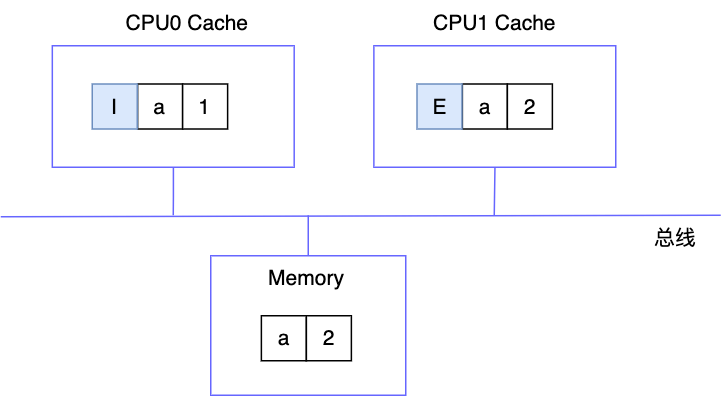
5.CPU0 读数据
由于 CPU0 的缓存块为 I,为已失效,所以它会广播一个读请求,CPU1 的缓存行状态为 E,所以它会将缓存行状态置为 S,并且将缓存行同步到 CPU0 中,注意这里是 CPU 间的缓存行传输,这样比起从内存读显然传输更快
MESI 协议很复杂,以上只是列表了 MESI 协议的一部分,实际上 MESI 协议的状态有几十种,转换状态也很复杂,完全列举是不可能的,大家知道其基本思想即可
对 MESI 协议的改进
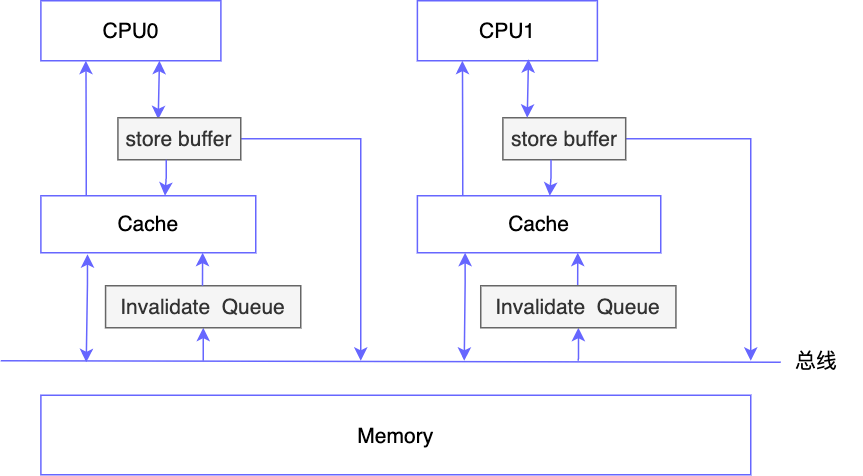
store buffer
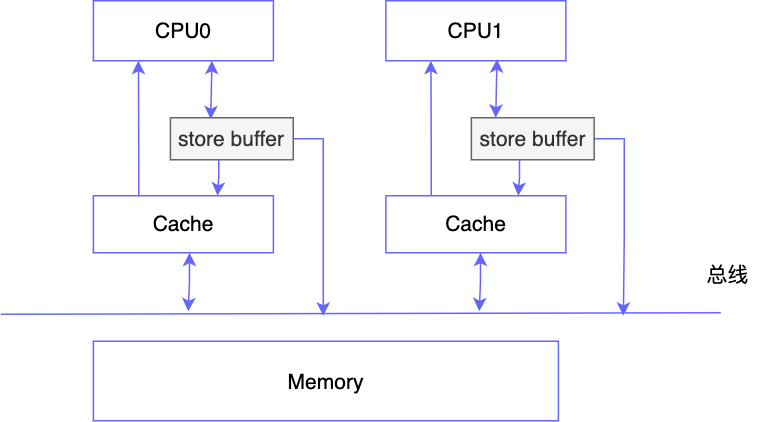
如果 CPU 之间严格遵循 MESI 协议,那其实也没 volatile 什么事了,但问题是如果严格遵循 MESI 协议的话,CPU 的执行效率会受到严重影响,因为每次要修改缓存,如果缓存行状态为 S 的话都要先发一个 invalidate 的广播,再等其他 CPU 将缓存行设置为无效后返回 invalidate ack 才能写到 Cache 中,那如果 CPU 频繁地修改数据,就会不断地发送广播消息,CPU 只能被动同步地等待其他 CPU 的消息,显然会对执行效率产生影响,为了解决此问题,工程师在 CPU 和 cache 之间又加了一个 store buffer
这样的话 CPU 要修改数据,先写入 store buffer 中,然后马上返回,之后再由 store buffer 异步执行发送广播消息和写入 cache 的操作,于是 CPU 执行写的效率就得到了极大的提升,另外为了确保 CPU 读取数据的正确性,它问题会先从 store buffer 中读取,然后再从 cache 中读取
这里需要注意一下 Cache 和 store buffer 的区别,Cache 一般指数据的副本,如果 Cache 中的数据没了,还可以从 Memory 中加载,但 store buffer 则不是,它更像是蓄水池的作用,先存储一堆数据,然后再异步执行操作,我们可以把它想像成课代表,先把所有同学的作业收集好再一次性交给老师,如果 store buffer 中的数据丢了,那就彻底丢失了
store buffer 的存储容量是有限的,前面我们介绍了,由 store buffer 来发送 invalidate 广播消息,然后其它 CPU 收到消息后,先将缓存行状态置为 I,然后再回复 invalidate ack 消息,但很有可能其他 CPU 在收到 invalidate 消息时正在忙其他事,还来不及将缓存行状态置为 I,这样就会造成 store buffer 不断堆积,直至溢出
针对此问题,科学家们又设计了 Invalidate Queue
Invalidate Queue
如图下,在 Cache 和总线间又加入了一个 Invalidate Queue,这样的话一旦 CPU 收到 invalidate 广播消息,就将此消息存储在 invalidate queue 中,然后立即回复 invalidate ack 消息给发出广播的那个 CPU,之后 invalidate queue 再异步执行将缓存行失效(设置状态为 I)的操作
这样的话 store buffer 就能节省写操作的时间,可以及时清空
store buffer 和 Invalidate Queue 的引入相当于对 MESI 缓存一致性协议进行了改造,这样的改造本质上是为了提高 CPU 的执行效率(尤其是写的效率),但天下没有免费的午餐,这样的方式又造成了数据的短暂不一致,举个例子,假设 CPU0 和 CPU1 的状态如下
此时 CPU0 执行了对 a 的写操作 a = 2,由于此操作会先写入 store buffer,然后再由 store buffer 执行异步的操作,那么从 store buffer 发送 invalidate 广播到 invalidate queue 让缓存行失效期间,CPU 1 读取 a 的值都是老值(即 a = 1),这就造成了短暂的不一致,当然最终还是会一致的,我们把这种协议称为弱一致性或者说最终一致性协议
内存屏障与 volatile
store buffer 与写屏障
由上一节可知 store buffer 和 Invalidate Queue 的引入提升了 CPU 的执行效率,但也让 MESI 协议由原来的强一致性变成了弱一致性,有可能会导致一些意想不到的问题,考虑以下代码:
// CPU0
void foo() {
a = 1; // ①
b = 1; // ②
}
// CPU1
void bar() {
while (b == 0) continue; // ③
assert(a == 1); // ④
}
假设 CPU0 执行完 foo 后,CPU1 执行 bar,那么当 CPU1 执行完 ③ 跳出循环后(意味着 b=1)再执行 ④ 时,a 的值是多少?可能很多人会误解为是 1,因为在 foo 中 a = 1 是排在 b = 1 前面的
但实际上由于以下两个原因 b=1 有可能会先于 a=1 先写入缓存的
CPU 的乱序执行
现代 CPU 普遍是是采用流水线机制动作的,为了提升运行效率和提高缓存命中率,会采用乱序执行( ① 和 ② 执行顺序可能互换)
由于 store buffer 的原因可能导致 b=1 先写入缓存,而 a =1 后写入缓存
我们之前说过 CPU 进行写操作时会先写入 store buffer,store buffer 再进行异步写缓存操作,所以即便 a = 1 先写入 store buffer,但由于 store buffer 是异步执行的,所以 b=1 也有可能先于 a=1 先写入缓存,这样的话当 CPU1 执行 ③ 时,b=1 跳出循环,但在执行 ④ 时有可能 store buffer 还未将 a=1 写入缓存,也就导致了 a 读取的依然是旧值 0,从而导致程序的执行结果与我们认为的有偏差
怎么解决这个问题呢,答案是使用内存屏障
// CPU0
void foo() {
a = 1; // ①
smp_wb(); // 插入写屏障,wb 代表 write barrier,即写屏障
b = 1; // ②
}
// CPU1
void bar() {
while (b == 0) continue; // ③
assert(a == 1); // ④
}
如上代码所示,在 ① 和 ② 之间插入了一个内存屏障,smp_wb 代表多核体系结构下的内存写屏障,它的主要作用是保证 ① 和 ② 不会乱序,同时也按我们看到的顺序将 ① 和 ② 依次写入缓存再同步到内存中,也就是说内存屏障的主要作用是让其他 CPU 能依次观察到 CPU0 按我们期望的顺序更新变量
以上我们在 foo 中的两个赋值语句中插入了一个屏障,我们称其为写屏障,写屏障的主要是为了解决 CPU 乱序执行 和 store buffer 异步写导致的数据更新与我们观察到的不一致的问题
Invalidate queue 与读屏障
那么以上在 foo 中插入写屏障后,bar 中在执行 ④ 时 a 的值就能正确读到 1 的值了吗,答案是也不一定
这主要是因为 CPU1 在收到 Invalidate 消息后是先把消息存在 Invalidate Queue 中,然后 Invalidate Queue 再异步执行让缓存行失败的操作,如果在执行 ④ 时,Invalidate Queue 还未将 a 所在的缓存行置为失效状态,那么 CPU1 就会从缓存行中读取 a=0 这个未更新的值,为了保证能正常读取到 a=1,我们需要在 ③ 和 ④ 之间插入读屏障,如下所示
// CPU0
void foo() {
a = 1; // ①
smp_wb(); // 插入写屏障,wb 代表 write barrier,即写屏障
b = 1; // ②
}
// CPU1
void bar() {
while (b == 0) continue; // ③
smp_rb(); // 插入读屏障,rb 代表 read barrier,即读屏障
assert(a == 1); // ④
}
通过插入读屏障,首先保证了 ③ 和 ④ 不会乱序,其次 CPU1 会保证 Invalidate Queue 中的失效消息处理完之后(此例中即将 a 对应的缓存行设置为失效状态)会执行步骤 ④,这样的话可以确保 a 能从内在中读到最新的值 1 了
至此我相信你应该能猜到 volatile 的作用了,没错,被 volatile 修饰的变量其实就相当于在变量写的时候添加了写屏障,避免了 volatile 变量写与在其之前其它变量写的排序,在变量读的时候添加了读屏障,避免了 volatile 读与在其之后的变量读的排序(在上面的例子中 b 是被 volatile 修饰的)
不过 volatile 在实现上和我们认识的稍有区别,用 volatile 修饰的变量,在编译成机器指令时会在写操作后面,加上一条特殊的指令:“lock addl #0x0, (%rsp)”,这条指令会将 CPU 对此变量的修改,立即写入内存,并通知其他 CPU 将缓存行置为无效状态,这里的 lock 主要是用来锁总线的,锁总线期间其他 CPU 的读写请求都会被阻塞,直到锁释放
荎此,我相信你明白了以下代码中,当 CPU0 执行完后,CPU1 的执行会与我们预期一致的原因
private int a = 0;
volatile int b = 0;
// CPU0
void foo() {
a = 1; // ①
b = 1; // ②
}we
// CPU1
void bar() {
while (b == 0) continue; // ③
assert(a == 1); // ④
}
原因其实就是因为在 foo 中由于 b 被 volatile 修饰了, ① 和 ② 间会插入写屏障,而在 bar 中 ③ 和 ④ 间会插入读屏障,这里面其实隐含了一个 happens before 规则:在时序上,如果对一个 volatile 变量的写操作,先于后面的对这个变量的读操作执行,那么,volatile 读操作必定能读到 volatile 写操作的结果
画外音:happens before 规则,简单理解即之前的操作对之后的操作可见,比如如果 「a = 1」 happens before 「对 a 读的操作」,那么「对 a 的读」一定能获取到 a=1 的值
除此之外,你会发现 a 虽然没有被 volatile 修饰,但是 ④ 中对 a 的读操作依然能能正确读到 ① 中 对 a 的赋值 1,这其实是基于 happens before(以下简称 hb) 的传导性,如果 a hb b,b hb c,那么 a hb c,在我们的这个例子,由于 ① hb ②,② hb ③,而 ③ hb ④,所以 ① hb ④,即 「a = 1」 hb 「a==1」,所以 ④ 能看到 a 的赋值 1
总结
本文由一道经典但误解率极高的 volatile 面试题出发,一步步地阐述了 volatile 被引入的成因:首先为了解决 CPU 从 内存读取数据的瓶颈,引入了 Cache,这样虽然提高了 CPU 的执行效率,但又引入了数据的一致性问题,于是为了解决这个问题,工程师又引入了 MESI 缓存一致性,但如果 CPU 间严格的遵守 MESI 协议,会导致执行效率大幅度降低,于是为了妥协又引入了 store buffer 和 Invalidate Queue,不过这样的话数据就由强一致性变成了弱一致性,可能会造成短时间内读取数据的不一致,会导致 bug,于是又引入了内存屏障来保证了数据的可见性,volatile 其实就是用来在变量前后添加内存屏障以保障可见性的

