
每个 Java 工程师都必须知道的五个 API 性能优化技巧转载
为什么你的 API 响应这么慢?也许你需要解决这些问题。
作为后端开发人员,我们总是在编写各种 API,无论是为前端 Web 提供数据支持的HTTP REST API ,还是提供内部使用的 RPC API。
这些 API 在服务初期可能表现不错,但随着用户数量的增长,一开始响应很快的API变得越来越慢,直到用户抱怨:“你的系统太糟糕了。我只是浏览一个网页。怎么这么慢?” 这时,您需要考虑如何优化您的 API 性能。
要提高你的API的性能,我们首先要知道什么问题会导致接口响应慢。API设计需要考虑很多方面。
开发语言级别只占很小的一部分。哪个部分设计的不好,就会成为性能瓶颈。影响API性能的因素有很多,总结如下。
- 数据库慢查询
- 复杂的业务逻辑
- 低性能代码
- 资源不足
第四点比较容易解决。如果你的系统有一定的扩展性,可以通过增加服务器来解决。对于其他需要优化的点,我们需要根据场景提出解决方案。至于低性能代码,其实我之前写过一篇Java代码性能优化的文章,感兴趣的读者可以看看。
让您的 Java 应用程序运行得更快的十个优化技巧
这些技巧可能会多次提高您的应用程序的性能。
媒体网
在这篇文章中,我总结了一些行之有效的API性能优化技巧,希望能给有需要的朋友一些帮助。
并行调用
假设我们现在有一个电子商务系统需要提交订单。该功能需要调用盘点系统进行盘点扣账,还需要获取用户地址信息。最后,调用风控系统判断本次交易没有风险。该接口的大部分设计可能会将接口设计为顺序执行接口。毕竟,我们需要获取用户地址信息并完成库存扣除,才能进行下一步。伪代码可以写成如下:
如果我们仔细分析这个函数,我们会发现几个方法调用之间没有强依赖关系。而且,这三个系统的调用都是耗时的。假设这些系统的耗时调用分布如下
//check stock
stockService.check();
//invoke addressService
addressService.getByUser();
//risk control
riskControlSerivce.check();
return doSubmitOrder(orderInfo);
}
- stockService.check()需要 150 毫秒。
- addressService.getByUser()需要 200 毫秒。
- riskControlSerivce.check()需要 300 毫秒。
如果这个API是顺序调用的,整个API的执行时间是650ms(150ms+200ms+300ms)。如果能转化为并行调用,API的执行时间为300ms,性能直接提升50%。使用并行调用,伪代码可以写成如下
//check stock
CompletableFuture<Void> stockFuture = CompletableFuture.supplyAsync(() -> {
return stockService.check();
}, executor);
//invoke addressService
CompletableFuture<Address> addressFuture = CompletableFuture.supplyAsync(() -> {
return addressService.getByUser();
}, executor);
//risk control
CompletableFuture<Void> riskFuture = CompletableFuture.supplyAsync(() -> {
return riskControlSerivce.check();
}, executor);
CompletableFuture.allOf(stockFuture, addressFuture, riskFuture);
stockFuture.get();
addressFuture.get();
riskFuture.get();
return doSubmitOrder(orderInfo);
避免大额交易
所谓大交易,就是那些需要很长时间的交易。如果使用spring@Transaction管理事务,需要注意是否不小心启动了大事务。因为spring的事务管理原理是将多个事务合并为一个执行,如果一个API中有多个数据库读写,并且这个API的并发访问量比较高,很可能大事务也会导致数据库中锁住了很多数据,造成大量block,数据库连接池连接耗尽。修改上面的例子。
public Boolean submitOrder(orderInfo orderInfo) {
//check stock
stockService.check();
//invoke addressService
addressService.getByUser();
//risk control
riskControlRpcApi.check();
orderService.insertOrder(orderInfo);
orderDetailService.insertOrderDetail(orderInfo);
return true;
}
相信这种代码已经出现在很多人写的业务中了。RPC 是一种非 DB 操作,它与持久层代码混合在一起。这种代码绝对是一笔大买卖。它不仅需要查询用户的地址和扣除库存,还需要插入订单数据和订单详情。这一系列操作需要合并到同一个事务中。如果 RPC 响应慢,当前线程会一直占用数据库连接,导致并发场景下数据库连接耗尽。不仅如此,如果事务需要回滚,你的 API 响应会因为回滚慢而变慢。
这时候,我们就需要考虑缩减业务。我们可以将非事务性操作和事务性操作分开,像这样
private OrderDaoService orderDaoService;
public Boolean submitOrder(OrderInfo orderInfo) {
//invoke addressService
addressService.getByUser();
//risk control
riskControlRpcApi.check();
return orderDaoService.doSubmitOrder(orderInfo);
}
@Service
public class OrderDaoService{
@Transactional(rollbackFor=Exception.class)
public Boolean doSubmitOrder(OrderInfo orderInfo) {
//check stock
stockService.check();
orderService.insertOrder(orderInfo);
orderDetailService.insertOrderDetail(orderInfo);
return true;
}
}
或者,您可以使用 spring 的 programmatic transaction TransactionTemplate。
private TransactionTemplate transactionTemplate;
public void submitOrder(OrderInfo orderInfo) {
//invoke addressService
addressService.getByUser();
//risk control
riskControlRpcApi.check();
return transactionTemplate.execute(()->{
return doSubmitOrder(orderInfo);
})
}
public Boolean doSubmitOrder(OrderInfo orderInfo) {
//check stock
stockService.check();
orderService.insertOrder(orderInfo);
orderDetailService.insertOrderDetail(orderInfo);
return true;
}
添加适当的索引
当我们的服务处于运营初期,系统需要存储的数据量很小。可能是数据库没有添加索引来快速存储和访问数据。但是可以发现,随着业务的增长,单表数据量不断增加,数据库的查询性能变差。这时候,我们应该给你的数据库表添加合适的索引。可以通过命令查看表的索引(这里以MySQL为例)。
显示来自
your_table_name的索引;
ALTER TABLE通过命令添加索引。
ALTER TABLE
your_table_nameADD INDEX index_name(username);
有时,即使添加了一些索引,数据查询仍然很慢。这时候可以使用explain命令查看执行计划,判断你的SQL语句是否命中了索引。例如
解释 select * from product_info where type=0;
你会得到一个分析结果:
一般来说,缺少索引的情况有几种。
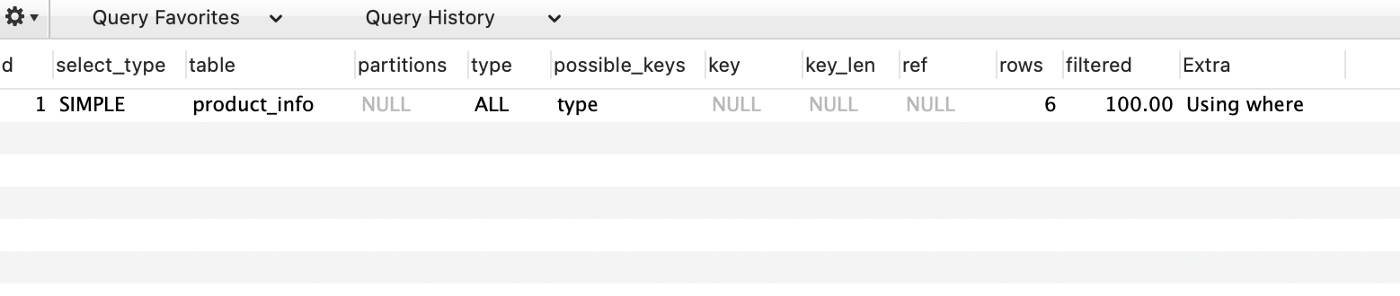
- 不满足最左前缀原则。例如,您idx(a,b,c)为tb1. 但是你的 SQL 语句是这样写的select * from tb1 where b=‘xxx’ and c=‘xxxx’;。
- 索引列具有算术运算。select * from tb1 where a%10=0;
- 索引列使用函数。select * from tb1 where date_format(a,’%m-%d-%Y’)=‘2022-08-06’;
- like使用关键字的模糊查询。select * from tb1 where a like ‘%aaa’;
- 使用not in或not exist关键字。
返回更少的数据
如果我们查询大量符合条件的数据,我们不需要返回所有数据。我们可以以分页的形式增量地提供数据。这样,我们需要通过网络传输的数据更少,编码和解码数据的时间更少,API响应更快。
然而,传统的limit offset方法用于分页(select * from product limit 10000,20)。当页数很大时,查询会越来越慢。这是因为使用的原理limit offset是找出10000条数据,然后丢弃之前的9980条数据。我们可以通过使用延迟关联来优化这个 SQL。
使用缓存
缓存是一种以空间换时间的解决方案。一些用户经常访问的数据直接缓存在内存中。因为内存的读取速度比磁盘IO快很多,所以我们也可以使用适当的缓存来提高API的性能。简单来说,我们可以使用Java HashMap、ConcurrentHashMap,也可以使用caffeine等本地缓存,也可以使用Memcached、Redis等分布式缓存中间件。
最后
我在这里列出了五个通用的 API 性能优化技巧。这些技巧只有在系统有一定的并发压力时才有效。如果您的系统访问量不大,请慎重考虑以上建议。您应该寻找其他更有效的解决方案。最后,希望这篇文章对你有所帮助。如果你想了解更多关于Java和系统架构设计的知识,请关注我。


