
从零开始搞监控系统(2)——存储和分析原创
目录:
从零开始搞监控系统(1)——SDK
从零开始搞监控系统(2)——存储和分析
从零开始搞监控系统(3)——性能监控
一、存储
在将数据传送到后台之前,已经做了一轮清洗工作,如果有需要还可以再做一次清洗。
日志表如下所示,自增的 id 直接偷懒使用了 bigint,没有采用分表等其他技术。
CREATE TABLE `web_monitor` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`project` varchar(45) COLLATE utf8mb4_bin NOT NULL COMMENT '项目名称',
`project_subdir` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '项目的子目录,有些项目下会将活动放置在各个子目录中',
`digit` int(11) NOT NULL DEFAULT '1' COMMENT '出现次数',
`message` text COLLATE utf8mb4_bin NOT NULL COMMENT '聚合信息',
`ua` varchar(600) COLLATE utf8mb4_bin NOT NULL COMMENT '代理信息',
`key` varchar(45) COLLATE utf8mb4_bin NOT NULL COMMENT '去重用的标记',
`category` varchar(45) COLLATE utf8mb4_bin NOT NULL COMMENT '日志类型',
`source` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL COMMENT 'SourceMap映射文件的地址',
`ctime` timestamp NULL DEFAULT CURRENT_TIMESTAMP,
`identity` varchar(20) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '身份,用于连贯日志上下文',
`day` int(11) DEFAULT NULL COMMENT '格式化的天(冗余字段),用于排序,20210322',
`hour` tinyint(2) DEFAULT NULL COMMENT '格式化的小时(冗余字段),用于分组,11',
`minute` tinyint(2) DEFAULT NULL COMMENT '格式化的分钟(冗余字段),用于分组,20',
`message_status` int(11) DEFAULT NULL COMMENT 'message中的通信状态码',
`message_path` varchar(45) COLLATE utf8mb4_bin DEFAULT NULL COMMENT 'message通信中的 path',
`message_type` varchar(20) COLLATE utf8mb4_bin DEFAULT NULL COMMENT 'message中的类别字段',
PRIMARY KEY (`id`),
KEY `idx_key_category_project_identity` (`key`,`category`,`project`,`identity`),
KEY `idx_category_project_identity` (`category`,`project`,`identity`),
KEY `index_ctime` (`ctime`),
KEY `idx_category_ctime` (`category`,`ctime`),
KEY `idx_category_project_ctime` (`category`,`project`,`ctime`),
KEY `idx_messagepath` (`message_path`),
KEY `idx_category_messagetype_ctime` (`category`,`message_type`,`ctime`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='前端监控日志'
在正式上线后,遇到了几次慢查询,阿里云给出了相关索引建议,后面就直接加上了,效果立竿见影。
1)堆栈压缩
对于数据量很大的公司,像下面这样的堆栈内容消耗的存储空间是非常可观的,因此有必要做一次压缩。
例如将重复的内容提取出来,用简短的标识进行替代,把 URL 被替换成了 # 和数字组成的标识等。
{
"type": "runtime",
"lineno": 1,
"colno": 100,
"desc": "Uncaught Error: Cannot find module \"./paramPathMap\" at http://localhost:8000/umi.js:248565:7",
"stack": "Error: Cannot find module \"./paramPathMap\"
at Object.<anonymous> (http://localhost:8000/umi.js:248565:7)
at __webpack_require__ (http://localhost:8000/umi.js:679:30)
at fn (http://localhost:8000/umi.js:89:20)
at Object.<anonymous> (http://localhost:8000/umi.js:247749:77)
at __webpack_require__ (http://localhost:8000/umi.js:679:30)
at fn (http://localhost:8000/umi.js:89:20)
at Object.<anonymous> (http://localhost:8000/umi.js:60008:18)
at __webpack_require__ (http://localhost:8000/umi.js:679:30)
at fn (http://localhost:8000/umi.js:89:20)
at render (http://localhost:8000/umi.js:73018:200)
at Object.<anonymous> (http://localhost:8000/umi.js:73021:1)
at __webpack_require__ (http://localhost:8000/umi.js:679:30)
at fn (http://localhost:8000/umi.js:89:20)
at Object.<anonymous> (http://localhost:8000/umi.js:72970:18)
at __webpack_require__ (http://localhost:8000/umi.js:679:30)
at http://localhost:8000/umi.js:725:39
at http://localhost:8000/umi.js:728:10"
}
考虑到我所在公司的数据量不会很大,人力资源也比较紧张,为了尽快上线,所以没有使用压缩,后期有时间了再来优化。
2)去除重复
虽然没有做压缩,但是对于相同的日志还是做了一次去重操作。
去重规则也很简单,就是将项目 token、日志类别和日志内容拼接成一段字符串,再用MD5加密,下面是 Node.js 代码。
const key = crypto.createHash("md5").update(token + category + message).digest("hex");
将 key 作为条件判断数据库中是否存在这条记录,若存在就给 digit 字段加一。

在正式上线后,每秒会有几百几千次的请求发送过来。
每次在添加日志时还要做这层判断,就一度将数据库阻塞掉。因为每次在做 key 判断时要全表查询一次,旧的查询还没执行完,新的就来了。
为了解决此问题,就加上了一个基于 Redis 的队列:Kue,将判断、更新和插入的逻辑封装到一个任务中,异步执行。注意,目前此库已经不维护了,首页上推荐了替代品:Bull。
再加上索引,双重保障后,现在接收日志时未出现问题。
二、分析
目前的分析部分也比较简单,只包括一个监控看板、趋势分析、日志列表和定时任务等。
1)监控看板
在监控看板中包含今日数据和往期趋势折线图,本来想用 EChart.js 作图,不过后面集成时出了点问题,并且该库比较大,要500KB以上,于是换了另一个更小的库:Chart.js,只有60KB。
今日数据有今日和昨日的日志总数、错误总数和影响人数,通信、事件、打印和跳转等总数。
其中错误总数会按照 category:“error” 的 sum(digit) 来求和,而影响人数只会按照记录的个数来计算。
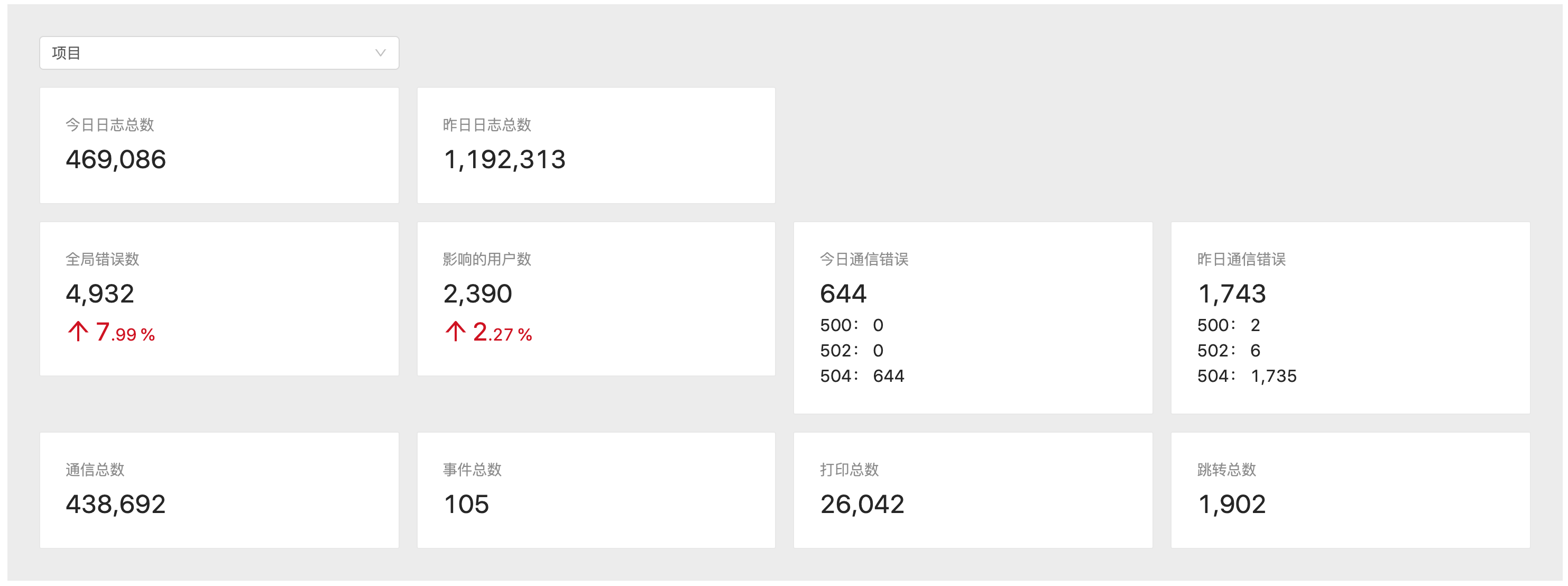
今日的数量是实时计算的,在使用中发现查询特别慢,要好几分钟才能得到结果,于是为几个判断条件中的字段加了个二级索引后(例如为 ctime 和 category 加索引),就能缩短到几秒钟响应。
ALTER TABLE `web_monitor` ADD INDEX `idx_category_ctime` (`category`, `ctime`);
SELECT count(*) AS `count` FROM `web_monitor`
WHERE (`ctime` >= '2021-03-25 16:00:00' AND `ctime` < '2021-03-26 16:00:00')
AND `category` = 'ajax';
在往期趋势中,会展示错误、500、502 和 504 错误、日志总数折线图,这些数据会被保存在一张额外的统计表中,这样就不必每次实时计算了。折线的颜色值取自 AntDesign。
计算了一下出现 504 的通信占全部的 0.2%,接下来需要将这个比例再往下降。
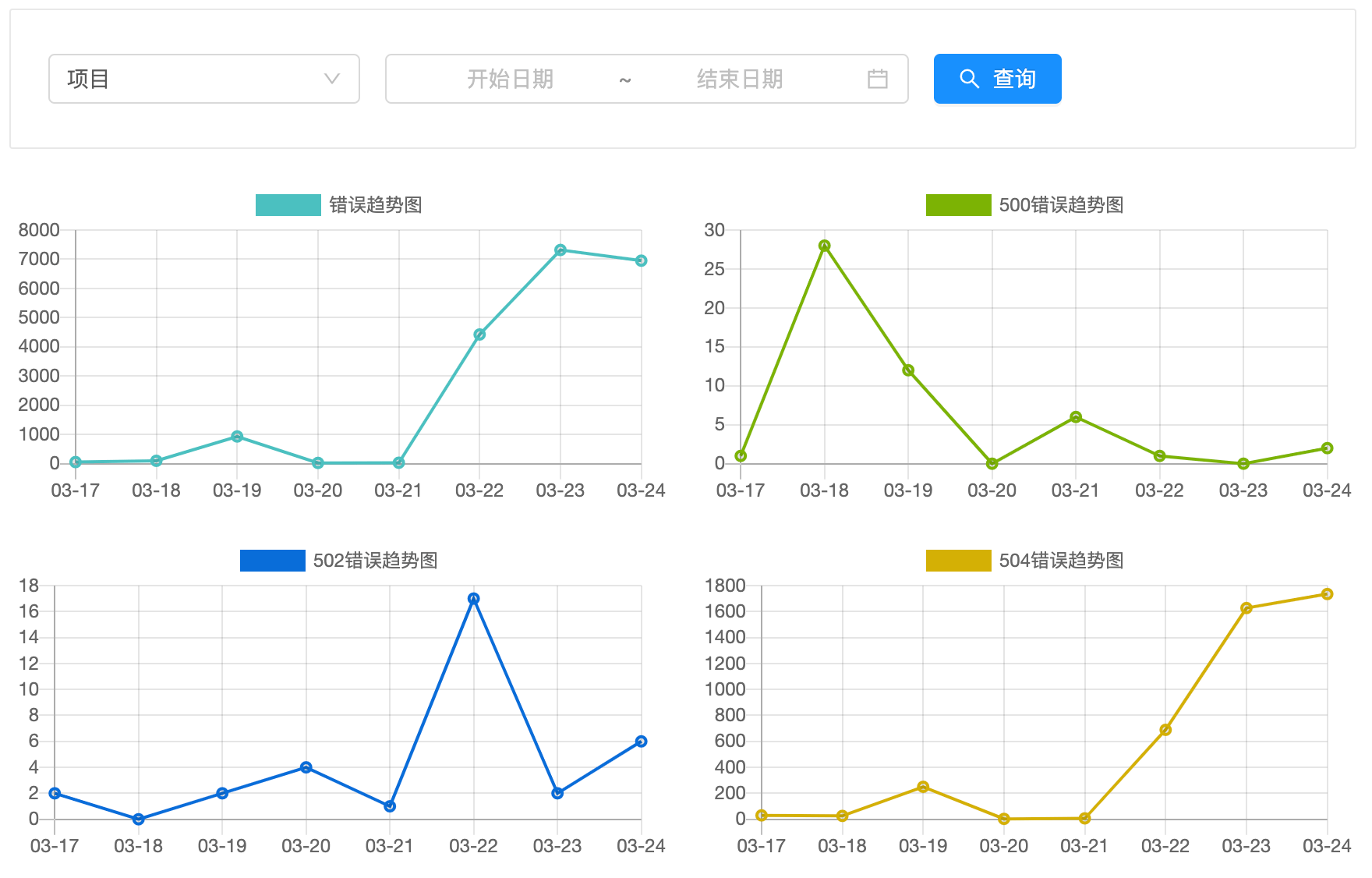
在看板中,展示的错误日志每天在七八千左右,为了减少到几百甚至更低的范围,可采取的措施有:
- 过滤掉无意义的错误,例如SyntaxError: Unexpected token ‘,’,该错误占了 55%~60% 左右。
- 优化页面和接口逻辑,504通信错误占了25%~30% 左右。
- 将这两个大头错误搞定,再针对性优化剩下的错误,就能将错误控制目标范围内。
从日志中可以查看到具体的接口路径,然后就能对其进行针对性的优化。
例如有一张活动页面,在进行一个操作时会请求两个接口,并且每个接口各自发送 3 次通信,这样会很容易发生 504 错误(每天大约有1500个这样的请求),因此需要改造该逻辑。
首先是给其中一张表加索引,然后是将两个接口合并成一个,并且每次返回 20 条以上的数据,这样就不用频繁的发起请求了。
经过改造后,每日的 504 请求从 1500 个左右降低到 200 个左右,减少了整整 7.5 倍,效果立竿见影,大部分的 504 集中在 22 点到 0 点之间,这段时间的活跃度比较高。
还有一个令人意外的发现,那就是监控日志的量每天也减少了 50W 条。
2021年9月,在监控看板中新增了504的接口统计查询,可以倒序看到每个504接口出现的次数,便于我们主动排查问题。
2022年3月,在监控看板中新增错误数量的统计查询,可以倒序看到每个错误出现的次数,也是为了便于我们主动排查问题而添加的。
2022年4月,在监控看板中留意到了打印总数,每天大约有17W条记录,而其中很大一部分都是遗留的调试数据,线上其实并不需要,所以很有必要剔除掉。
2)日志列表
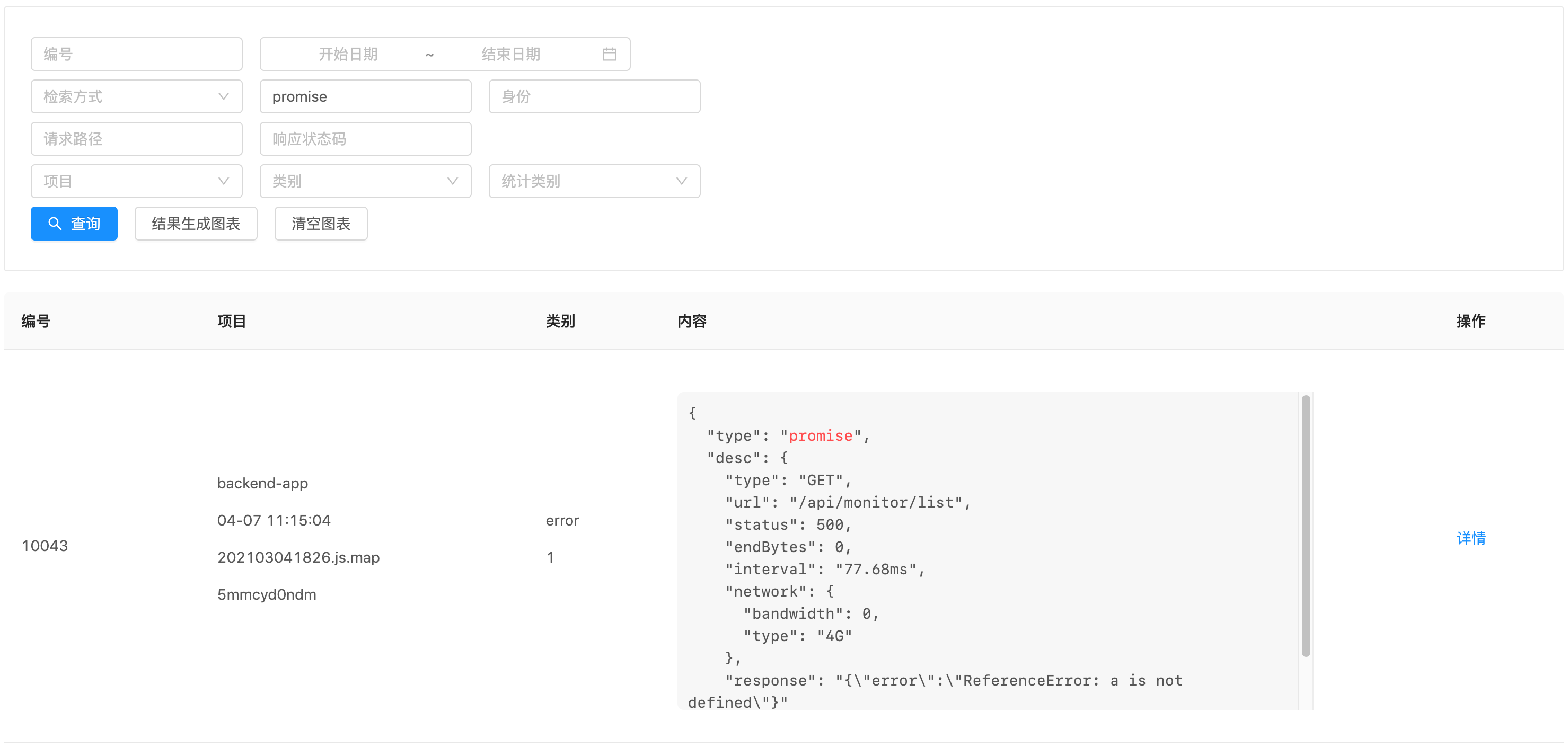
在日志列表中会包含几个过滤条件:编号、关键字、日期范围、项目、日志类型和身份标识等。
如果输入了关键字,那么会在监控日志搜索结果列表中为其着色,这样更便于查看,用正则加字符串的 replace() 方法配合实现的。
在数据量上去后,当对内容(MYSQL 中的类型是 TEXT)进行模糊查询时,查询非常慢,用 EXPLAIN 分析SQL语句时,发现在做全表查询。
经过一番搜索后,发现了全文索引(match against 语法),在 5.7.6 之前的 MYSQL 不支持中文检索,好在大部分情况要搜索的内容都是英文字符。
SELECT * FROM `web_monitor` WHERE MATCH(message) AGAINST('+*test*' IN BOOLEAN MODE)
在建完这个索引后,表的容量增加了 3G 多,当前表中包含 1400W 条数据。
CREATE FULLTEXT INDEX ft_message ON web_monitor(message)
有时候还是需要模糊匹配的,所以想了下加个下拉选项,来手动命令后台使用哪种方式的查询,但如果是模糊匹配,必须选择日期来缩小查找范围。
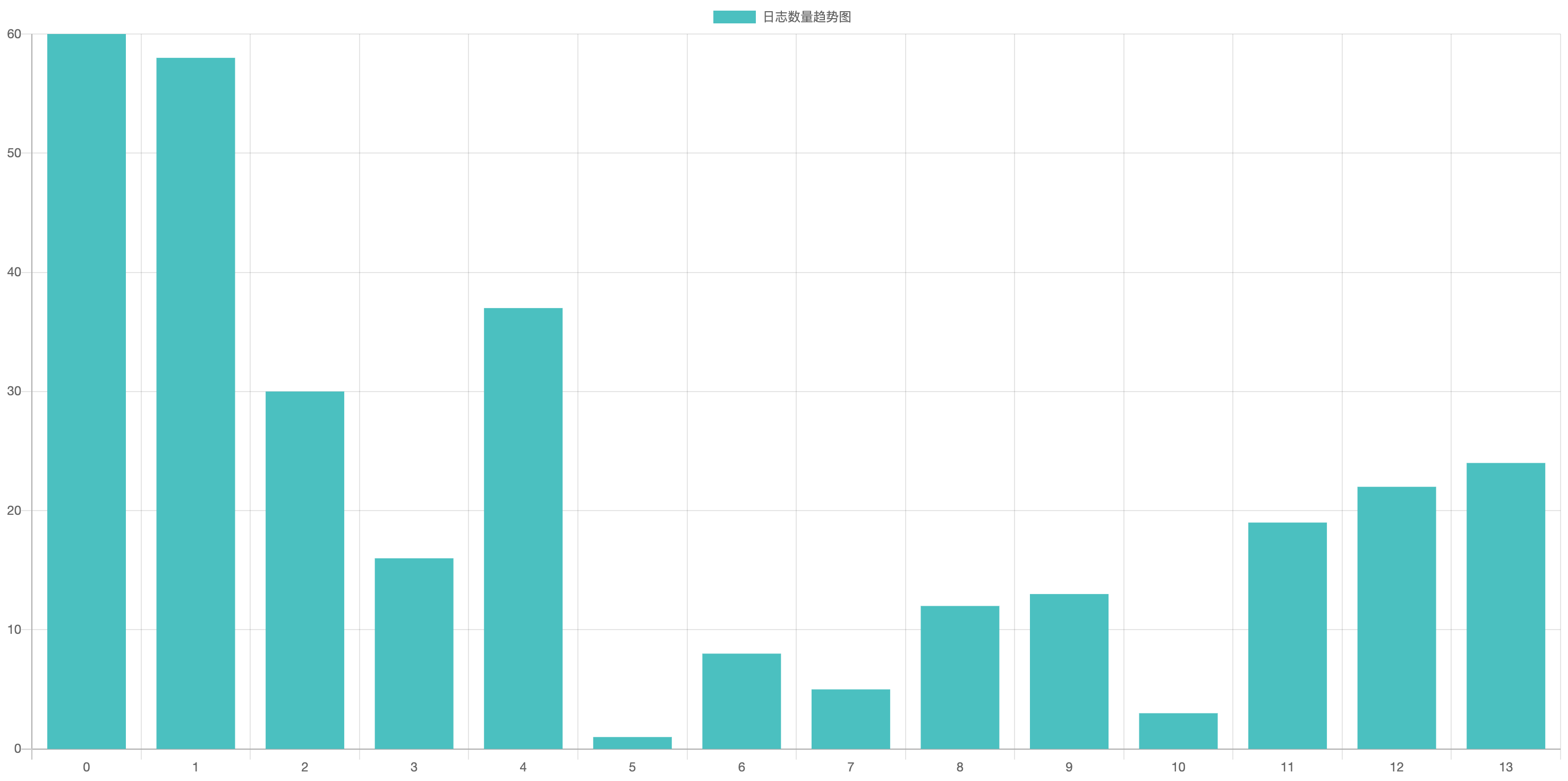
在实际使用时,又发现缺张能直观展示峰值的图表,例如我想知道在哪个时间段某个特定错误的数量最多,于是又加了个按钮和柱状图,支持跨天计算。
身份标识可以查询到某个用户的一系列操作,更容易锁定错误发生时的情境。
每次查询列表时,在后台就会通过Source Map文件映射位置,注意,必须得有列号才能还原,并且需要安装 source-map 库。
const sourceMap = require("source-map");
/**
* 读取指定的Source-Map文件
*/
function readSourceMap(filePath) {
let parsedData = null;
try {
parsedData = fs.readFileSync(filePath, "utf8");
parsedData = JSON.parse(parsedData);
} catch (e) {
logger.info(`sourceMap:error`);
}
return parsedData;
}
/**
* 处理映射逻辑
*/
async function getSourceMap(row) {
// 拼接映射文件的地址
const filePath = path.resolve(
__dirname,
config.get("sourceMapPath"),
process.env.NODE_ENV + "-" + row.project + "/" + row.source
);
let { message } = row;
message = JSON.parse(message);
// 不存在行号或列号
if (!message.lineno || !message.colno) {
return row;
}
// 打包后的sourceMap文件
const rawSourceMap = readSourceMap(filePath);
if (!rawSourceMap) {
return row;
}
const errorPos = {
line: message.lineno,
column: message.colno
};
// 过传入打包后的代码位置来查询源代码的位置
const consumer = await new sourceMap.SourceMapConsumer(rawSourceMap);
// 获取出错代码在哪一个源文件及其对应位置
const originalPosition = consumer.originalPositionFor({
line: errorPos.line,
column: errorPos.column
});
// 根据源文件名寻找对应源文件
const sourceIndex = consumer.sources.findIndex(
(item) => item === originalPosition.source
);
const sourceCode = consumer.sourcesContent[sourceIndex];
if (sourceCode) {
row.sourceInfo = {
code: sourceCode,
lineno: originalPosition.line,
path: originalPosition.source
};
}
// 销毁,否则会报内存访问超出范围
consumer.destroy();
return row;
}
点击详情,就能在弹框中查看到代码具体位置了,编码着色采用了 highlight.js。
而每行代码的行号使用了一个扩展的 highlight-line-numbers.js,柔和的淡红色的色值是 #FFECEC。

图中还有个上下文的 tab,这是一个很有用的功能,可以查询到当前这条记录前面和后面的所有日志。
本以为万事大吉,但是没想到在检索时用模糊查询,直接将数据库跑挂了。
无奈,从服务器上将日志数据拉下来,导入本地数据库中,在本地做查询优化,2000W条数据倒了整整两个小时。
和数据组的同事沟通后,他们说可以引入 ElasticSearch 做检索功能。当他们看到我的 message 字段中的内容时,他们建议我先做关键字优化。
就是将我比较关心的内容放到单独的字段中,提升命中率,而将一些可变的或不重要的数据再放到另一个字段中,单纯的做存储。
例如通信内容中,我比较关心的是 url 和 status,那么就将它们抽取出来,并且去除无关紧要的信息(例如错误的 stack、通信的 headers)给 message 字段瘦身,最多的能减少三分之二以上。
{
"type": "GET",
"url": "/api/monitor/list?category=error&category=script&msg=",
"status": 200,
"endBytes": "0.15KB",
"interval": "22.07ms",
"network": {
"bandwidth": 0,
"type": "3G"
},
}
最后决定报表统计的逻辑仍然用 MySQL,而检索改成 ElasticSearch,由大数据组的同事提供接口,我们这边传数据给他们。
而之前的检索方式也可以弃用了,MySQL中存储的日志数据也从 14 天减少到 7 天。
在使用过程中遇到了几个问题:
没有将所有的数据传递到ES库中,丢失了将近33%的数据,后面排查发现有些数据传递到了预发环境,而预发环境中有个参数没配置导致无法推送。
在检索时,返回的列表会漏几条记录,在一个可视化操作界面中输入查询条件可以得到连续的数据。经过排查发现,可能是在后台查询时,由于异步队列的原因,那几条数据还未推送,这样的话就会得不到那几条记录,导致不连续。
通过日志列表中的通信和点击事件,可以计算出业务方日常工作的耗时,这个值可以作为指标,来验证对业务优化后,前后的对比,这样的量化能让大家知道自己工作给业务方带来了多少提升。
3)定时任务
每天的凌晨4点,统计昨天的日志信息,保存到 web_monitor_statis 表中。
CREATE TABLE `web_monitor_statis` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`date` int(11) NOT NULL COMMENT '日期,格式为20210318,一天只存一条记录',
`statis` text COLLATE utf8mb4_bin NOT NULL COMMENT '以JSON格式保存的统计信息',
PRIMARY KEY (`id`),
UNIQUE KEY `date_UNIQUE` (`date`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='前端监控日志统计信息表';
在 statis 字段中,保存的是一段JSON数据,类似于下面这样,key 值是项目的 token。
{
"backend-app": {
allCount: 0,
errorCount: 1,
errorSum: 1,
error500Count: 0,
error502Count: 0,
error504Count: 1,
ajaxCount: 20,
consoleCount: 0,
eventCount: 0,
redirectCount: 0
}
}
还有个定时任务会在每天的凌晨3点,将一周前的数据清除(web_monitor),并将三周前的 map 文件删除。
之所以有个时间差是为了避免一周内的数据中还有需要引用两周前的 map 文件,当然这个时间差还可以更久。
注意,MySQL中表的数据通过 delete 命令删除,如果使用的是 InnoDB 存储引擎,那么是不会释放磁盘空间的,需要执行 optimize 语句,例如:
optimize table `web_monitor`
原先每日的数据量在180W左右,每条数据在 800B 左右,每天占用空间 1.3G 左右。
后面优化了请求量,过滤掉重复和无意义的请求后(例如后台每次都要发的身份验证的请求、活动页面的埋点请求等),每天的日志量控制在 100W 左右。
而在经过上述活动的504优化后,请求量降到了 50W 左右,优化效果很喜人。
保存 map 文件的空间在100G,应该是妥妥够的。
在未来会将监控拓展到小程序,并且会加上告警机制,在合适的时候用邮件、飞书、微信或短信等方式通知相关人员,后面还有很多扩展可做。
叙述的比较简单,但过程还说蛮艰辛的,修修补补,加起来的代码大概有4、5千行的样子。
4)服务迁移
在使用时发现监控日志的服务比较占用CPU和内存,于是将其单独抽取做来,独立部署。
经过这波操作后,整体的504错误,从 800 多渐渐降到了 100 左右。其中有一半的请求是埋点通信,业务请求降到了有史以来的最低点。
但CPU和内存并没有按预期下降,这部分涉及到了一次详细的内存泄漏的摸查过程,在下文会详细分析。
5)飞书告警
首先需要注册飞书开放平台,并创建应用。
然后在开放平台找到凭证,记录 app_id 和 app_secret。
接着在应用功能中,启用机器人,由机器人来发送告警。


再获取 tenant_access_token(需要 app_id 和 app_secret),最后通过另一个接口发送消息。
下一步就是制订告警规则。

