
前端性能精进之浏览器(五)——JavaScript原创
JavaScript 是一种通过解释执行的高级编程语言,同时也是一门动态、弱类型的直译脚本语言,适合面向对象(基于原型)和函数式的编程风格。
直译语言可以直接在解释器中运行,而与直译语言相对应的编译语言(例如 C++),要先将代码编译为机器码,然后才能运行。
不过直译语言有一个弱点,就是如果有一条不能运行,那么下面的也不能运行了。
JavaScript 主要运行在一个内置 JavaScript 解释器的客户端中(例如 Web 浏览器),能够处理复杂的计算,操控文档的内容、样式和行为。
能在客户端完成的操作(例如输入验证、日期计算等)尽量都由 JavaScript 完成,这样就能减少与服务器的通信,降低服务器的负载。
JavaScript 作为现今前端开发最为核心的一部分,处理的不好就很容易影响网页性能和用户体验。
因此有必要了解一些 JavaScript 的代码优化。本文所用的示例代码已上传至 Github。
一、代码优化
完整的JavaScript由3部分组成,如下所列:
- ECMAScript,定义了该语言的语法和语义。
- DOM(Document Object Model)即文档对象模型,处理文档内容的编程接口。
- BOM(Browser Object Model)即浏览器对象模型,独立于内容与浏览器进行交互的接口。
对其优化,也会围绕这 3 部分展开。
1)相等运算符
相等(==)和全等(===)这两个运算符都用来判断两个操作数是否相等,但它们之间有一个最大的区别。
就是“==”允许在比较中进行类型转换,而“===”禁止类型转换。
各种类型之间进行相等比较时,执行的类型转换是不同的,在 ECMAScript 5 中已经定义了具体的转换规则。
下表将规则以表格的形式展示,第一列表示左边操作数“X”的类型,第一行表示右边操作数“Y”的类型。
在表格中,Number() 函数用简写 N() 表示,ToPrimitive() 函数用简写 TP() 表示。
| X == Y | 数字 | 字符串 | 布尔值 | null | undefined | 对象 |
| 数字 | N(Y) | N(Y) | 不等 | 不等 | TP(Y) | |
| 字符串 | N(X) | N(Y) | 不等 | 不等 | TP(Y) | |
| 布尔值 | N(X) | N(X) | N(X) | N(X) | N(X) | |
| null | 不等 | 不等 | N(Y) | 相等 | 相等 | TP(Y) |
| undefined | 不等 | 不等 | N(Y) | 相等 | 相等 | TP(Y) |
| 对象 | TP(X) | TP(X) | N(Y) | TP(X) | TP(X) |
当判断对象和非对象是否相等时,会先让对象执行 ToPrimitive 抽象操作,再进行相等判断。
ToPrimitive 抽象操作就是先检查是否有 valueOf() 方法,如果有并且返回基本类型的值,就用它的返回值;如果没有就改用 toString() 方法,再用它的返回值。
由于相等会进行隐式的类型转换,因此会出现很多不确定性,ESLint 的规则会建议将其替换成全等。
顺带说一句,弱类型有着代码简洁、灵活性高等优势,但它的可读性差、不够严谨等劣势也非常突出。
在编写有点规模的项目时,推荐使用强类型的 TypeScript,以免发生不可预测的错误。
2)位运算
在内存中,数字都是按二进制存储的,位运算就是直接对更低层级的二进制位进行操作。
由于位运算不需要转成十进制,因此处理速度非常快。
常见的运算符包括按位与(&)、按位或(|)、按位异或(^)、按位非(~)、左移(<<)、带符号右移(>>)等。
位运算常用于取代纯数学操作,例如对 2 取模(digit%2)判断偶数与奇数、数字交换,如下所示。
if (digit & 1) { // 奇数(odd) } else { // 偶数(even) } // 数字交换 a = a^b; b = b^a; a = a^b;
位掩码技术是使用单个数字的每一位来判断选项是否成立。注意,每项值都是 2 的幂,如下所示。
const OPTION_A = 1, OPTION_B = 2, OPTION_C = 4, OPTION_D = 8, OPTION_E = 16; //用按位或运算创建一个数字来包含多个设置选项 const options = OPTION_A | OPTION_C | OPTION_D; //接下来可以用按位与操作来判断给定的选项是否可用 //选项A是否在列表中 if(options & OPTION_A) { //... }
用按位左移(<<)做乘法,用按位右移做除法(>>),例如 digit * 2 可以替换成 digit << 2。
位运算的应用还有很多,此处只做抛砖引玉。
顺便说一句,推荐在 JavaScript 中使用原生方法,例如数学计算就调用 Math 中的方法。
当年,jQuery 为了抹平浏览器之间的 DOM 查询,自研了一款 CSS 选择器引擎(sizzle),源码在 2500 多行。
而现在,浏览器内置了 querySelector() 和 querySelectorAll() 选择器方法,若使用基础功能,完全可以替代 sizzle。
浏览器和规范的不断发展,使得原生方法也越来越完善,在性能方面也在越做越好。
3)存储
在早期,网页的数据存储都是通过 Cookie 完成的,不过 Cookie 最初的作用是保持 HTTP 请求的状态。
随着网页交互的复杂度越来越高,它的许多缺陷也暴露了出来,例如:
- 每个 HTTP 请求都会带上 Cookie 信息,增加了 HTTP 首部的内容,如果网站访问量巨大,将会很影响带宽。
- Cookie 不适合存储一些隐私敏感信息(例如用户名、密码等),因为 Cookie 会在网络中传递,很容易被劫持,劫持后可以伪造请求,执行一些危险操作(例如删除或修改信息)。
- Cookie 的大小被浏览器限制在 4KB 左右,只能存储一点简单的信息,不能应对复杂的存储需求,例如缓存表单信息、数据同步等。
为了解决这些问题,HTML5 引入了 Web 存储:本地存储(local storage)和会话存储(session storage)。
它们的存储容量,一般在 2.5M 到 10M 之间(大部分是 5M),在 Chrome DevTools 的 Application 面板可以查看当前网页所存储的内容。
它不会作为请求报文中的额外信息传递给服务器,因此比较容易实现网页或应用的离线化。
若存储的数据比较大,那么就需要 IndexedDB,这是一个嵌入在浏览器中的事务数据库,但不像关系型数据库使用固定列。
而是一种基于 JavaScript 对象的数据库,类似于 NoSQL。
4)虚拟 DOM
在浏览器中,DOM 和 JavaScript 是两个独立的模块,在 JavaScript 中访问 DOM 就好比穿过要收费的跨海大桥。
访问次数越多,过桥费越贵,最直接的优化方法就是减少过桥次数,虚拟 DOM 的优化思路与此类似。
所谓虚拟DOM(Virtual DOM),其实就是构建在真实 DOM 之上的一层抽象。
它先将 DOM 元素映射成内存中的 JavaScript 对象(即通过 React.createElement() 得到的 React 元素),形成一棵 JavaScript 对象树。
再用算法找出新旧虚拟 DOM 之间的差异,随后只更新真实 DOM 中需要变化的节点,而不是将整棵 DOM 树重新渲染一遍,过程参考下图。

虚拟 DOM 还有一大亮点,那就是将它与其他渲染器配合能够集成到指定的终端。
例如将 React 元素映射成对应的原生控件,既可以用 react-dom 在 Web 端渲染,还可以使用 react-native 在手机端渲染。
5)Service Worker
Service Worker 是浏览器和服务器之间的代理服务器,可拦截网站所有请求,根据自定义条件采取适当的动作,例如读取响应缓存、将请求转发给服务器、更新缓存的资源等。
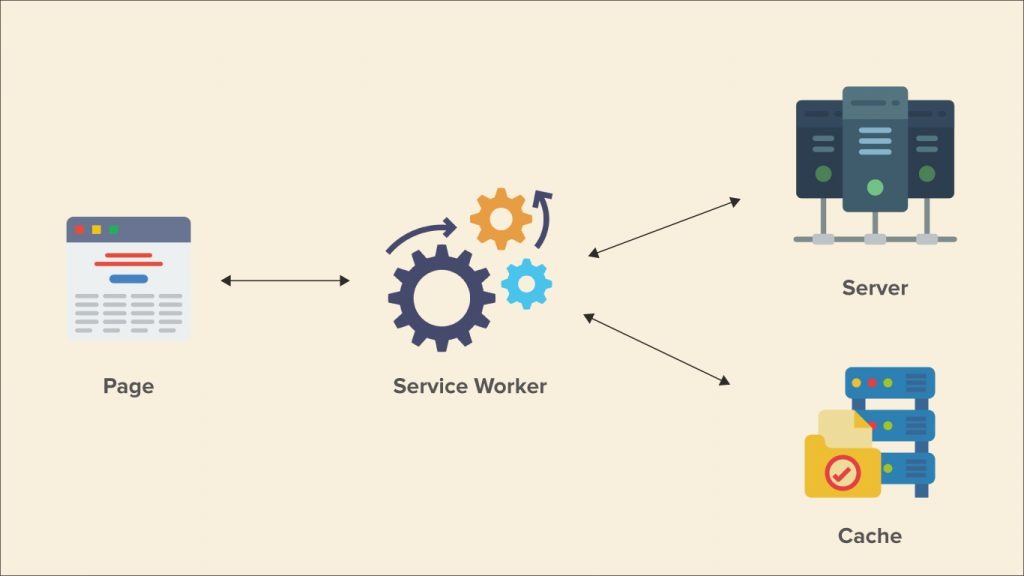
Service Worker 运行在主线程之外,提供更细粒度的缓存管理,虽然无法访问 DOM,但增加了离线缓存的能力。
当前,正在使用 Service Worker 技术的网站有 google、微博等。
每个 Service Worker 都有一个独立于 Web 页面的生命周期,如下图所示,其中 Cache API 是指 CacheStorage,可对缓存进行增删改查。
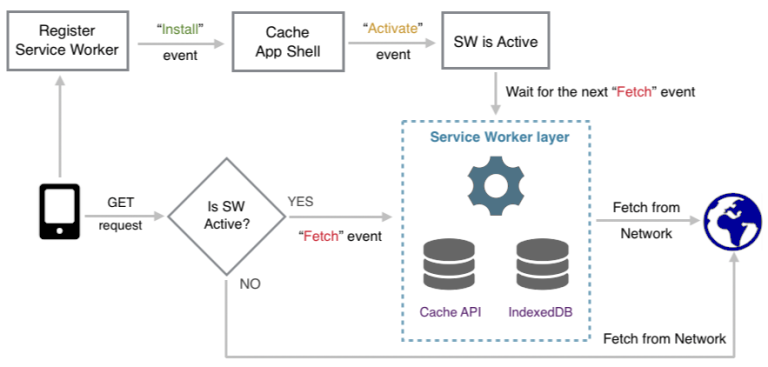
在主线程中注册 Service Worker 后,触发 install 事件,安装 Service Worker 并且解析和执行 Service Worker 文件(常以 sw.js 命名)。
当 install 事件回调成功时,触发 activate 事件,开始激活 Service Worker,然后监听指定作用域中页面的资源请求,监听逻辑记录在 fetch 事件中。
接下来用一个例子来演示 Service Worker 的使用,首先在 load 事件中注册 Service Worker,如下所示。
因为注册的脚本是运行在主线程中的,为了避免影响首屏渲染,遂将其移动到 load 事件中。
window.addEventListener("load", () => {
// 注册一个 sw.js,通知浏览器为该页面分配一块内存,然后就会进入安装阶段
navigator.serviceWorker
.register("/sw.js")
.then((registration) => {
console.log("service worker 注册成功");
})
.catch((err) => {
console.log("servcie worker 注册失败");
});
});
sw.js 是一个 Service Worker 文件,将其放置在根目录中,这样就能监控整个项目的页面。若放置在其他位置,则需要配置 scope 参数,如下所示。
navigator.serviceWorker.register("/assets/js/sw.js", { scope: '/' })
但是在访问 sw.js 时会报错(如下所示),需要给它增加 Service-Worker-Allowed 首部,然后才能在整个域中工作,默认只能在其所在的目录和子目录中工作。
The path of the provided scope ('/') is not under the max scope allowed ('/assets/js/').
Adjust the scope, move the Service Worker script, or use the Service-Worker-Allowed HTTP header to allow the scope
在 sw.js 中注册了 install 和 fetch 事件(如下所示),都是比较精简的代码,caches 就是 CacheStorage,提供了 open()、match()、addAll() 等方法。
在 then() 方法中,当存在 response 参数时,就直接将其作为响应返回,它其实就是一个 Response 实例。
// 安装 self.addEventListener("install", e => { e.waitUntil( caches.open("resource").then(cache => { cache.addAll(["/assets/js/demo.js"]).then(() => { console.log("资源都已获取并缓存"); }).catch(error => { console.log('缓存失败:', error); }); }) ); }); // 拦截 self.addEventListener("fetch", e => { e.respondWith( caches.match(e.request).then(response => { // 响应缓存 if (response) { console.log("fetch cache"); return response; } return fetch(e.request); }) ); });
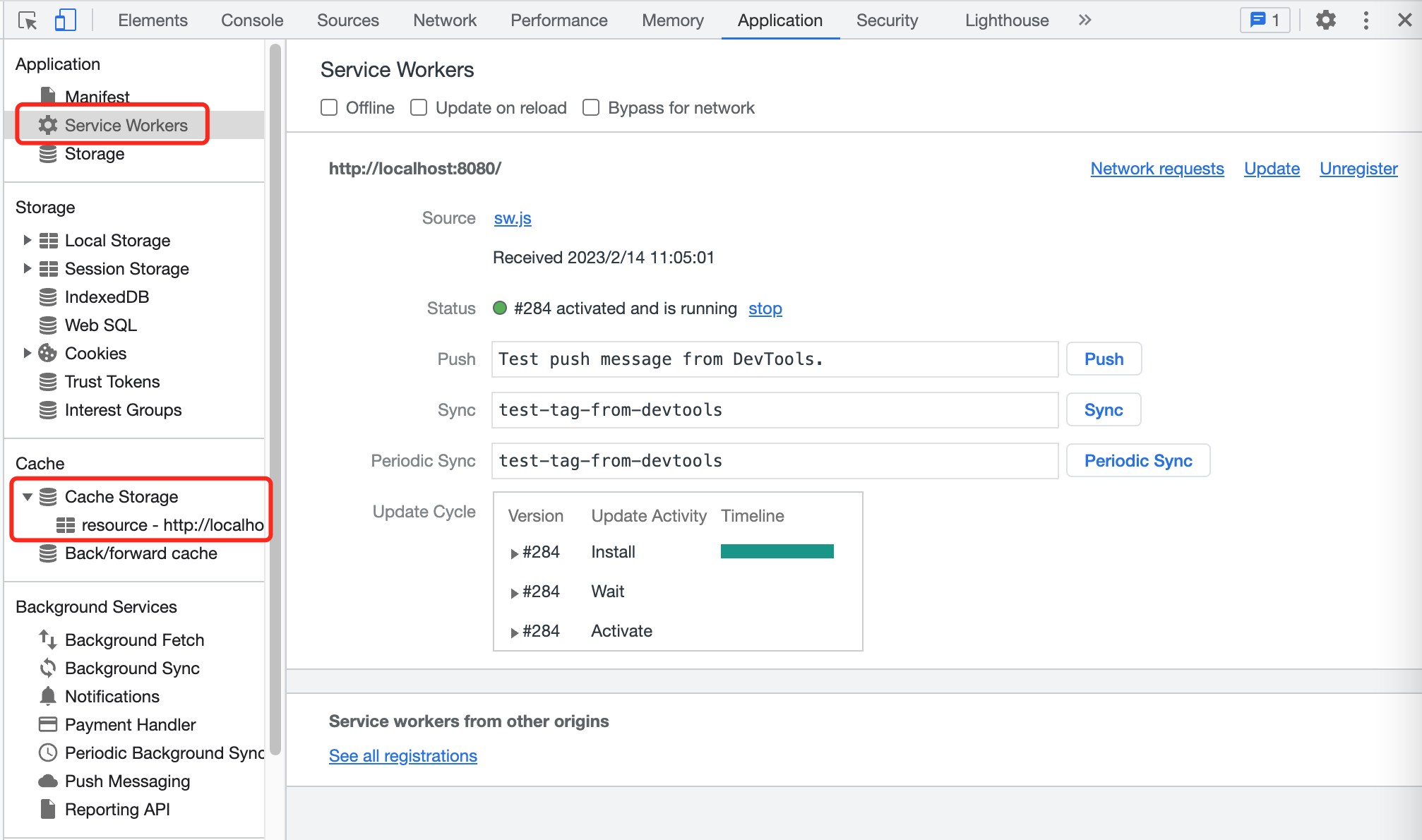
运行网页后,在 Chrome DevTools 的 Application 面板中的 Service Workers 菜单中,就能看到注册成功的 Service Worker,如下图所示。
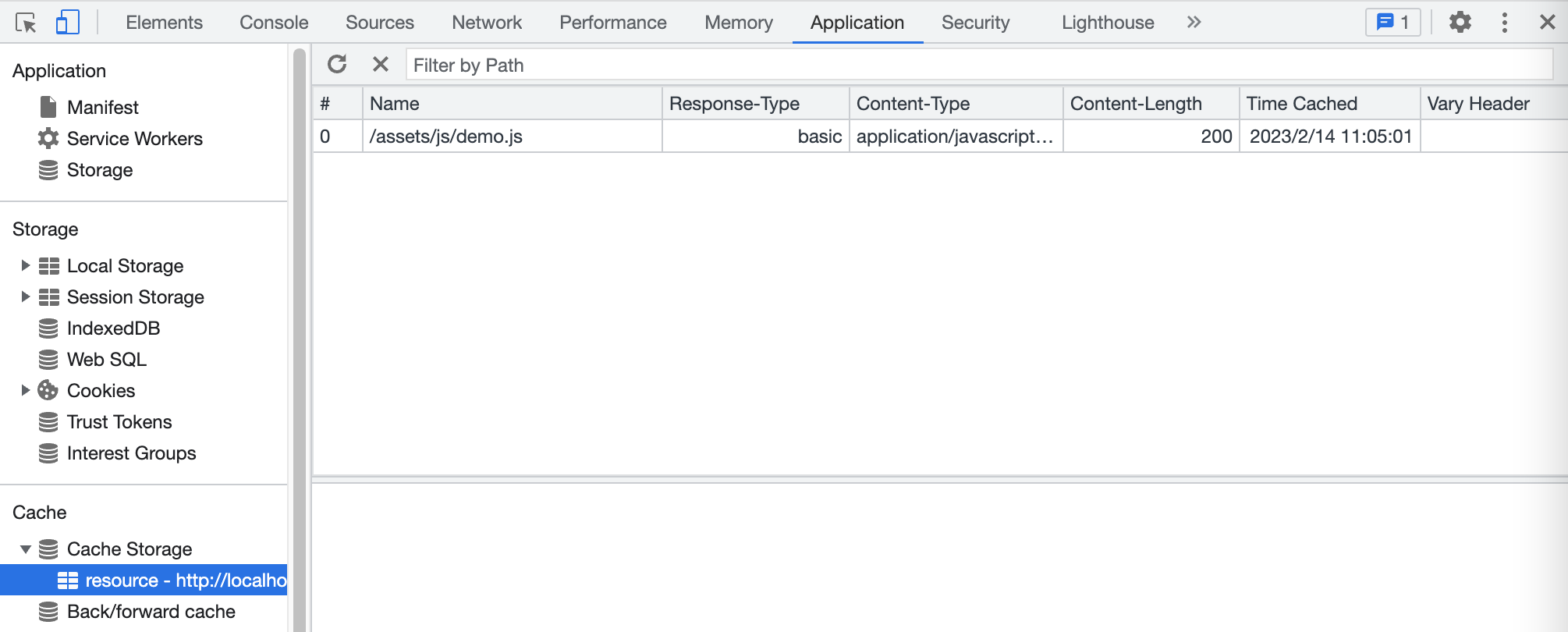
在 Cache Storage 菜单中,就能看到添加的缓存资源,如下图所示。
关闭页面,再次打开,查看 demo.js 的网络请求,size 那列显示的就不是文件尺寸,而是 Service Worker,如下图所示。
worker.html 没有进行缓存,所以将请求转发给服务器。

2022 年 HTTP Archive 预估网站中 Service Worker 的使用率在桌面端和移动端分别有 1.63% 和 1.81%,从数据中可知,使用率并不高。
虽然 Service Worker 的兼容性除了 IE 之外,主流的浏览器都已兼容,但是在实际使用中,还是要慎重。
首先得做到引入 Service Worker 后带来某些方面的性能提升,但不能让另一些方面的性能降低,需要考虑成本和收益。
其次网页的运行不能依赖 Service Worker,它的作用只是锦上添花,而不是业务必须的。
对于不能运行 Service Worker 的浏览器,也要确保网页的呈现和交互都是正常的。
二、函数优化
函数(function)就是一段可重复使用的代码块,用于完成特定的功能,能被执行任意多次。
它是一个 Function 类型的对象,拥有自己的属性和方法。
JavaScript 是一门函数式编程语言,它的函数既是语法也是值,能作为参数传递给一个函数,也能作为一个函数的结果返回。
与函数相关的优化有许多,本文选取其中的 3 种进行讲解。
1)记忆函数
记忆函数是指能够缓存先前计算结果的函数,避免重复执行不必要的复杂计算,是一种用空间换时间的编程技巧。
具体的实施可以有多种写法,例如创建一个缓存对象,每次将计算条件作为对象的属性名,计算结果作为对象的属性值。
下面的代码用于判断某个数是否是质数,在每次计算完成后,就将计算结果缓存到函数的自有属性 digits 内。
质数又叫素数,是指一个大于1的自然数,除了1和它本身外,不能被其它自然数整除的数。
function prime(number) { if (!prime.digits) { prime.digits = {}; //缓存对象 } if (prime.digits[number] !== undefined) { return prime.digits[number]; } var isPrime = false; for (var i = 2; i < number; i++) { if (number % i == 0) { isPrime = false; break; } } if (i == number) { isPrime = true; } return (prime.digits[number] = isPrime); } prime(87); prime(17); console.log(prime.digits[87]); //false console.log(prime.digits[17]); //true
2)惰性模式
惰性模式用于减少每次代码执行时的重复性分支判断,通过对对象重定义来屏蔽原对象中的分支判断。
惰性模式按触发时机可分为两种,第一种是在文件加载后立即执行对象方法来重定义。
在早期为了统一 IE 和其他浏览器之间注册事件的语法,通常会设计一个兼容性函数,下面示例采用的是第一种惰性模式。
var A = {}; A.on = (function (dom, type, fn) { if (dom.addEventListener) { return function (dom, type, fn) { dom.addEventListener(type, fn, false); }; } else if (dom.attachEvent) { return function (dom, type, fn) { dom.attachEvent("on" + type, fn); }; } else { return function (dom, type, fn) { dom["on" + type] = fn; }; } })(document);
第二种是当第一次使用方法对象时来重定义,同样以注册事件为例,采用第二种惰性模式,如下所示。
A.on = function (dom, type, fn) { if (dom.addEventListener) { A.on = function (dom, type, fn) { dom.addEventListener(type, fn, false); }; } else if (dom.attachEvent) { A.on = function (dom, type, fn) { dom.attachEvent("on" + type, fn); }; } else { A.on = function (dom, type, fn) { dom["on" + type] = fn; }; } //执行重定义on方法 A.on(dom, type, fn); };
3)节流和防抖
节流(throttle)是指预先设定一个执行周期,当调用动作的时刻大于等于执行周期则执行该动作,然后进入下一个新周期,示例如下。
function throttle(fn, wait) { let start = 0; return () => { const now = +new Date(); if (now - start > wait) { fn(); start = now; } }; }
适用于 mousemove、resize 和 scroll 事件。之前做过一个内部系统的表格,希望在左右滚动时能将第一列固定在最左边。
为了让操作能更流畅,在 scroll 事件中使用了节流技术,如下图所示。
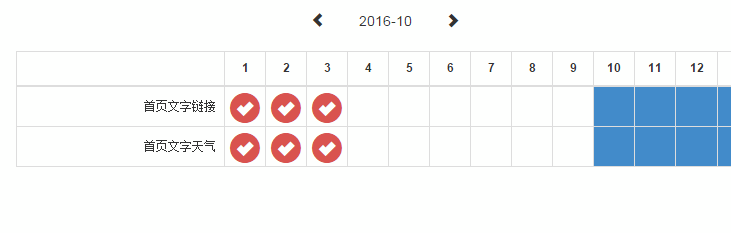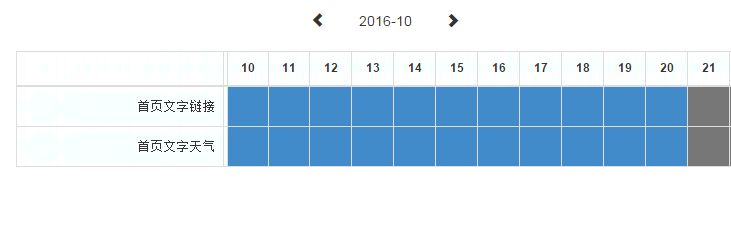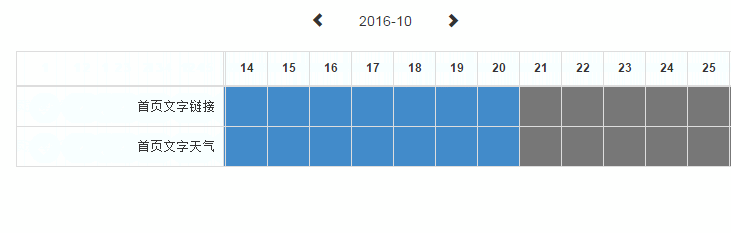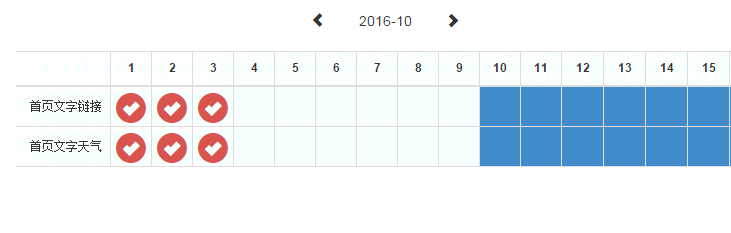
值得一提的是,在未来会有一个 scrollend 事件,专门监听滚动的结束,待到浏览器支持,就可以不用再大费周章的节流了。
防抖(debounce)是指当调用动作 n 毫秒后,才会执行该动作,若在这 n 毫秒内又调用此动作则将重新计算执行时间,示例如下。
function debounce(fn, wait) { let start = null; return () => { clearTimeout(start); start = setTimeout(fn, wait); }; }
适用于文本输入的 keydown 和 keyup 两个事件,常应用于文本框自动补全。
节流与防抖最大的不同的地方就是在计算最后执行时间的方式上,著名的开源工具库 underscore 中有内置了两个方法。
三、内存优化
JavaScript 并没有提供像 C 语言那样底层的内存管理函数,例如 malloc() 和 free()。
而是在创建变量(对象,字符串等)时自动分配内存,并且在不使用它们时自动释放,释放过程称为垃圾回收。
虽然垃圾回收器很智能,但是若处理不当,还是有可能发生内存泄漏的。
1)垃圾回收器
Node.js 是一个基于 V8 引擎的 JavaScript 运行时环境,而 Node.js 中的垃圾回收器(GC)其实就是 V8 的垃圾回收器。
这么多年来,V8 的垃圾回收器(Garbage Collector,简写GC)从一个全停顿(Stop-The-World),慢慢演变成了一个更加并行,并发和增量的垃圾回收器。
本节内容参考了 V8 团队分享的文章:Trash talk: the Orinoco garbage collector。
在垃圾回收中有一个重要术语:代际假说(The Generational Hypothesis),这个假说不仅仅适用于 JavaScript,同样适用于大多数的动态语言,Java、Python 等。
代际假说表明很多对象在内存中存在的时间很短,即从垃圾回收的角度来看,很多对象在分配内存空间后,很快就变得不可访问。
在 V8 中,会将堆分为两块不同的区域:新生代(Young Generation)和老生代(Old Generation)。
新生代中存放的是生存时间短的对象,大小在 1~ 8M之间;老生代中存放的生存时间久的对象。
对于这两块区域,V8 会使用两个不同的垃圾回收器:
- 副垃圾回收器(Scavenger)主要负责新生代的垃圾回收。如果经过垃圾回收后,对象还存活的话,就会从新生代移动到老生代。
- 主垃圾回收器(Full Mark-Compact)主要负责老生代的垃圾回收。
无论哪种垃圾回收器,都会有一套共同的工作流程,定期去做些任务:
- 标记活动对象和非活动对象,前者是还在使用的对象,后者是可以进行垃圾回收的对象。
- 回收或者重用被非活动对象占据的内存,就是在标记完成后,统一清理那些被标记为可回收的对象。
- 整理内存碎片(不连续的内存空间),这一步是可选的,因为有的垃圾回收器不会产生内存碎片。
V8 为新生代采用 Scavenge 算法,会将内存空间划分成两个区域:对象区域(From-Space)和空闲区域(To-Space)。
副垃圾回收器在清理新生代时:
- 会先将所有的活动对象移动(evacuate)到连续的一块空闲内存中(这样能避免内存碎片)。
- 然后将两块内存空间互换,即把 To-Space 变成 From-Space。
- 接着为了新生代的内存空间不被耗尽,对于两次垃圾回收后还活动的对象,会把它们移动到老生代,而不是 To-Space。
- 最后是更新引用已移动的原始对象的指针。上述几步都是交错进行,而不是在不同阶段执行。
主垃圾回收器负责老生代的清理,而在老生代中,除了新生代中晋升的对象之外,还有一些大的对象也会被分配到此处。
主垃圾回收器采用了 Mark-Sweep(标记清除)和 Mark-Compact(标记整理)两种算法,其中涉及三个阶段:标记(marking),清除(sweeping)和整理(compacting)。
- 在标记阶段,会从一组根元素开始,递归遍历这组根元素。其中根元素包括执行堆栈和全局对象,浏览器环境下的全局对象是 window,Node.js 环境下是 global。
- 在清除阶段,会将非活动对象占用的内存空间添加到一个叫空闲列表的数据结构中。
- 在整理阶段,会让所有活动的对象都向一端移动,然后直接清理掉那一端边界以外的内存。
2)内存泄漏
内存泄漏(memory leak)是计算机科学中的一种资源泄漏,主因是程序的内存管理失当,因而失去对一段已分配内存的控制。
程序继续占用已不再使用的内存空间,或是存储器所存储对象无法透过执行代码而访问,令内存资源空耗,简单地说就是内存无法被垃圾回收。
下面会罗列几种内存泄漏的场景:
第一种是全局变量,它不会被自动回收,而是会常驻在内存中,因为它总能被垃圾回收器访问到。
第二种是闭包(closure),当一个函数能够访问和操作另一个函数作用域中的变量时,就会构成一个闭包,即使另一个函数已经执行结束,但其变量仍然会被存储在内存中。
如果引用闭包的函数是一个全局变量或某个可以从根元素追溯到的对象,那么就不会被回收,以后不再使用的话,就会造成内存泄漏。
第三种是事件监听,如果对某个目标重复注册同一个事件,并且没有移除,那么就会造成内存泄漏。
第四种是缓存,当缓存中的对象属性越来越多时,长期存活的概率就越大,垃圾回收器也不会清理,部分不需要的对象就会造成内存泄漏。
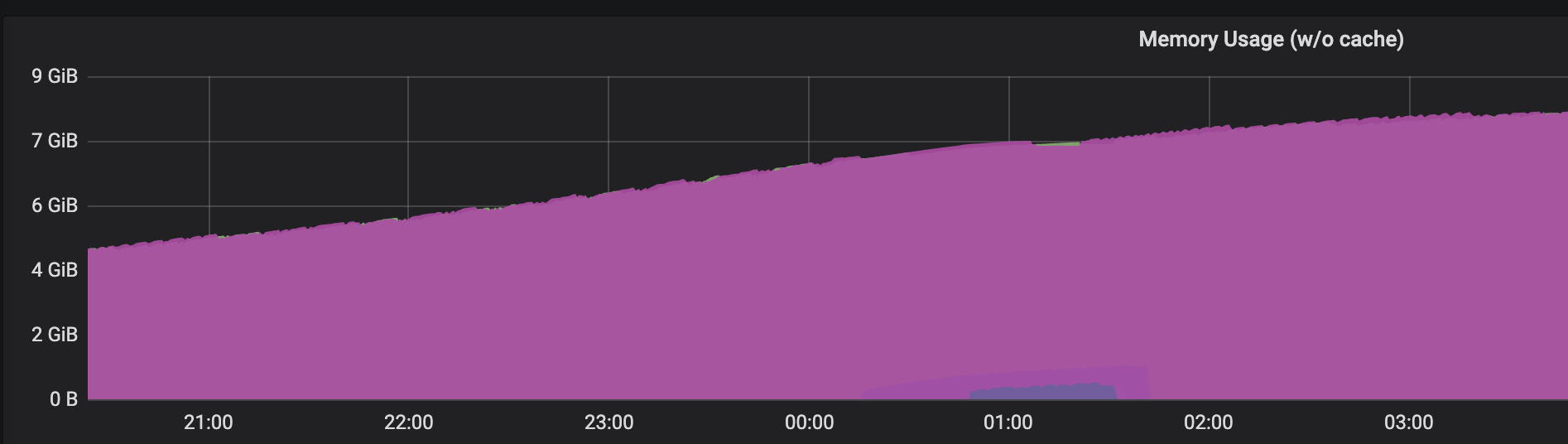
在实际开发中,曾遇到过第三种内存泄漏,如下图所示,内存一直在升。
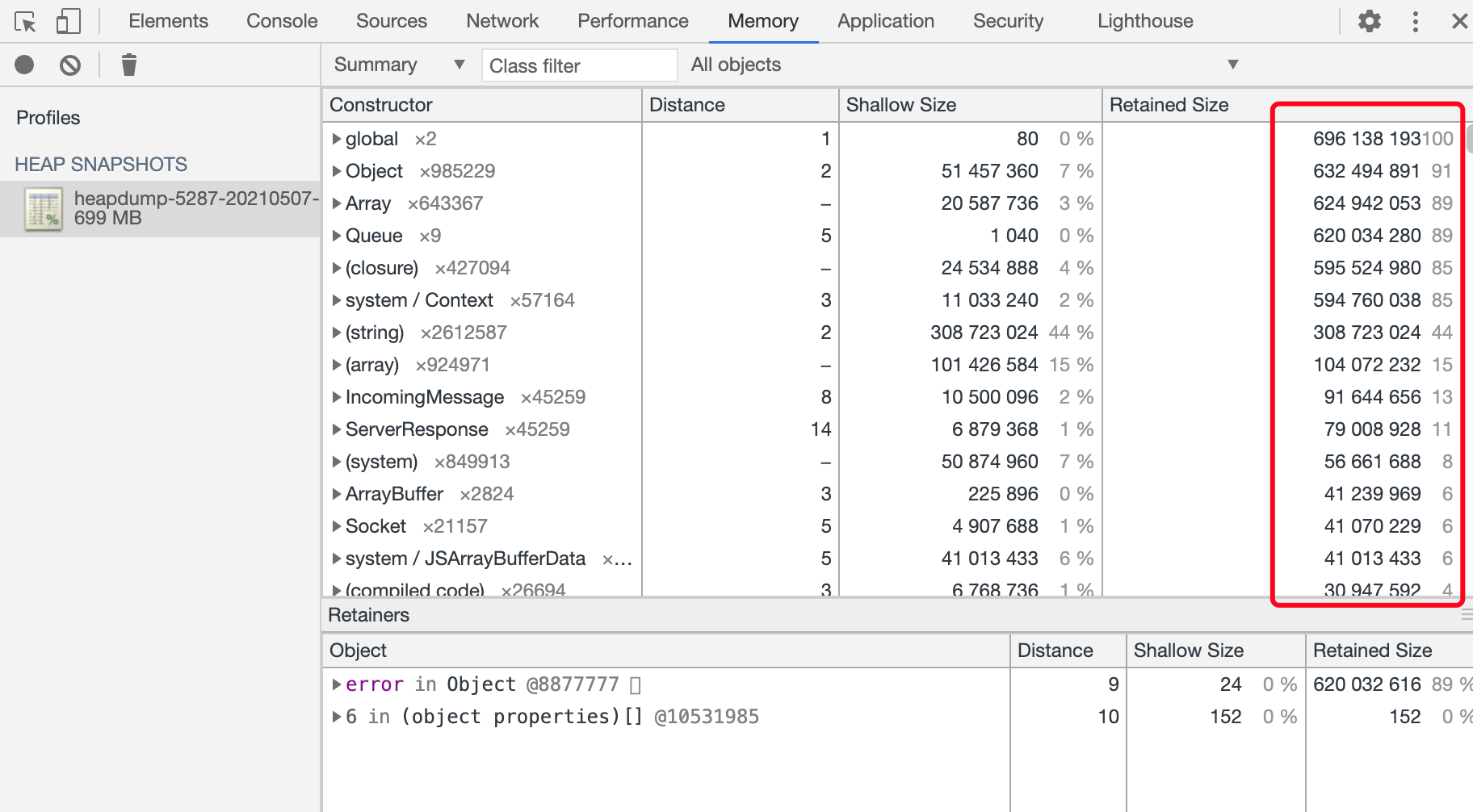
要分析内存泄漏,首先需要下载堆快照(*.heapsnapshot文件),然后在 Chrome DevTools 的 Memory 面板中载入,可以看到下图内容。
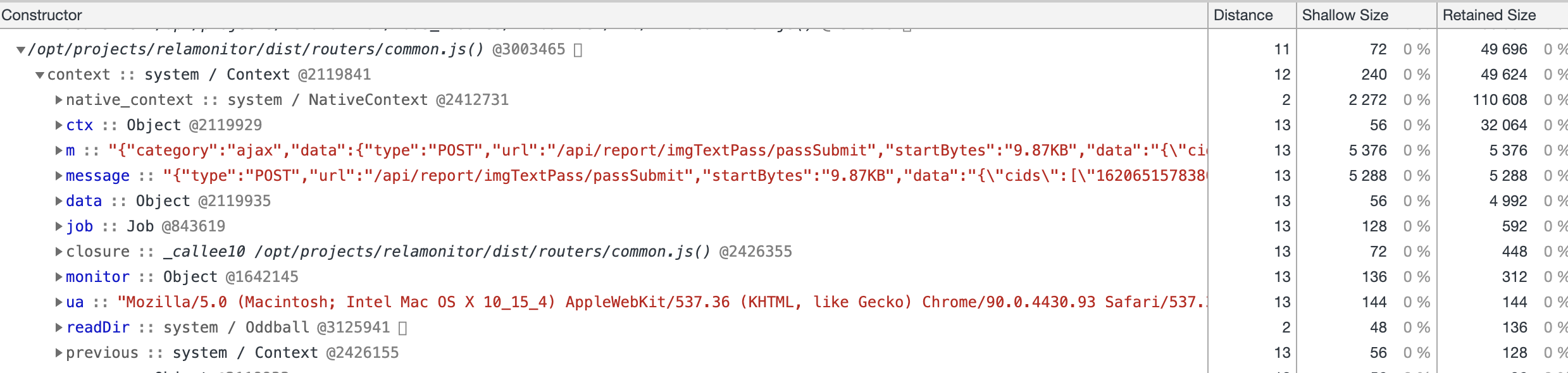
在将堆快照做缜密的分析后发现,请求的 ma.gif 地址中的变量不会释放,其内容如下图所示。
仔细查看代码后,发现在为外部的 queue 对象反复注册一个 error 事件,如下所示。
import queue from "../util/queue"; router.get("/ma.gif", async (ctx) => { queue.on('error', function( err ) { logger.trace('handleMonitor queue error', err); }); });
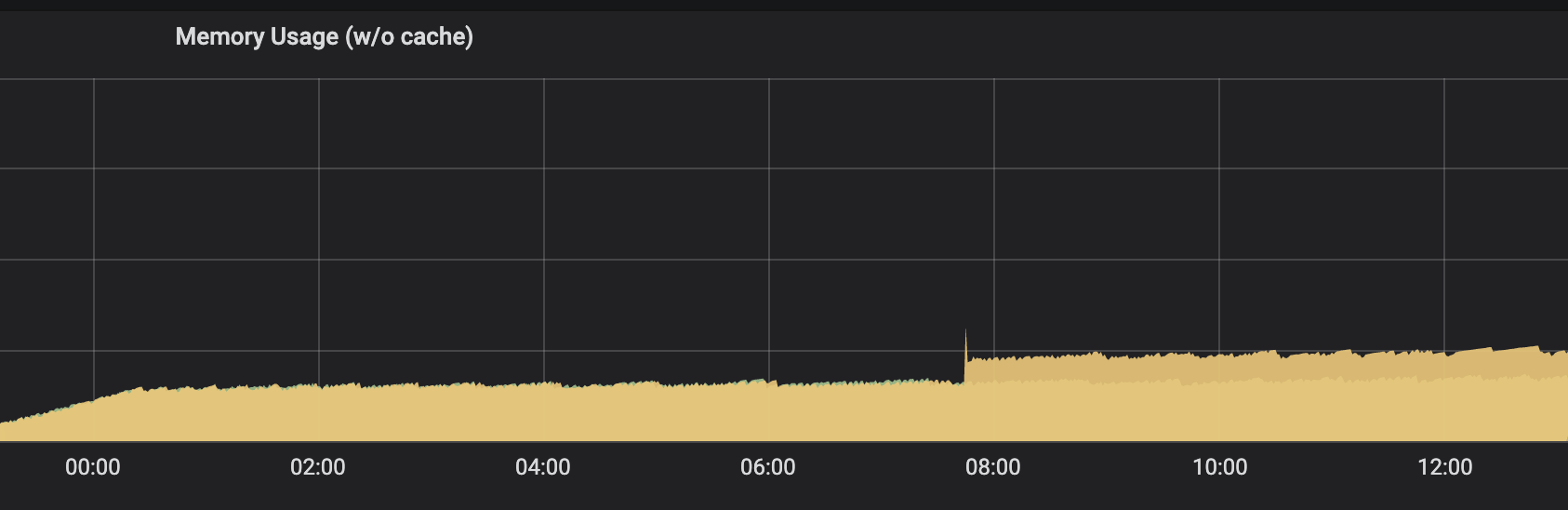
将这段代码去除后,内存就恢复了平稳,没有出现暴增的情况,如下图所示。
总结
本文首先分析了相等和全等两个运算符的差异,然后再介绍了几种位运算的巧妙用法。
再介绍了目前主流的几种 Web 存储,以及虚拟 DOM 解决的问题,并且讲解了 Service Worker 管理缓存的过程。
在第二节中主要分析了三种函数优化,分别是记忆函数、惰性模式、节流和防抖。
其中节流和防抖在实际项目中有着广泛的应用,很多知名的库也都内置这两个函数。
最后讲解了 V8 对内存的管理,包括垃圾回收,以及用一个实例演示了内存泄漏后简单的排查过程。


