
Eureka服务下线太慢,电话被告警打爆了原创
导语
某年某月的某一天,就像一张破碎的脸。。。
错了,重来。
某天,忽然发现大量的告警,经过多番调查研究考察(此处省略3000字),发现是由于 Eureka 服务下线太慢,而仍然有大量的请求打进来导致的报错。
于是,又经过了大量详细周密的考察和研究,终于找到了问题并且解决了(此处省略5000字)。
全文完。
... ...
好了,那是不可能的啦,怎么说也要意思一下写个300字凑个原创啊。
正文
为啥服务都下线了还会有那么多的请求一直进来呢?呐,我们都知道 Eureka 是 AP 模型,其实根本原因在于 Eureka 使用了三级缓存来保存服务的实例信息,如下图所示。
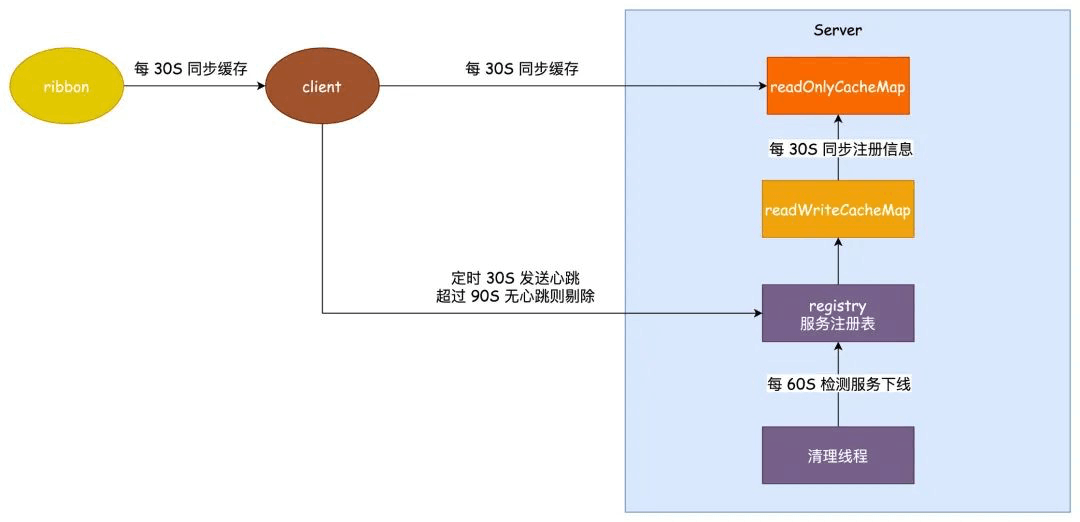
我们的服务注册的时候会和 server 保持一个心跳,这个心跳的时间是 30 秒,服务注册之后,客户端的实例信息保存到 Registry 服务注册表当中,注册表中的信息会立刻同步到 readWriteCacheMap 之中。
而客户端如果感知到这个服务,要从 readOnlyCacheMap 去读取,这个只读缓存需要 30 秒的时间去从 readWriteCacheMap 中同步。
客户端和 Ribbon 负载均衡 都保持一个本地缓存,都是 30 秒定时同步。
按照上面所说,我们来计算一下客户端感知到一个服务下线极端的情况需要多久。
1、客户端每隔 30 秒会发送心跳到服务端
2、registry 保存了所有服务注册的实例信息,他会和 readWriteCacheMap 保持一个实时的同步,而 readWriteCacheMap 和 readOnlyCacheMap 会每隔 30 秒同步一次。
3、客户端每隔 30 秒去同步一次 readOnlyCacheMap 的注册实例信息
4、考虑到如果使用 ribbon 做负载均衡的话,他还有一层缓存每隔 30 秒同步一次
如果说一个服务的正常下线,极端的情况这个时间应该就是 30+30+30+30 差不多 120 秒的时间了。
如果服务非正常下线,还需要靠每 60 秒执行一次的清理线程去剔除超过 90 秒没有心跳的服务,那么这里的极端情况可能需要 3 次 60秒才能检测出来,就是 180 秒的时间。
累计可能最长的感知时间就是:180 + 120 = 300 秒,5分钟的时间,这个时间属实有点夸张了,如果考虑到可能有些中间件画蛇添足加了点啥清理的工作,这个时间简直就是灾难性的。
那有人就问了,我在 Eureka 控制台看见服务上下线非常快啊,你这不跟我扯犊子吗?
大哥啊,控制台的显示是直接获取的 Registry 的信息,那肯定快啊,所以我们不能这样来判断。
那怎么解决呢,解决方案当然就是改这些时间了,这个时间需要根据实际生产的情况来判断修改,这里仅提供一个示例。
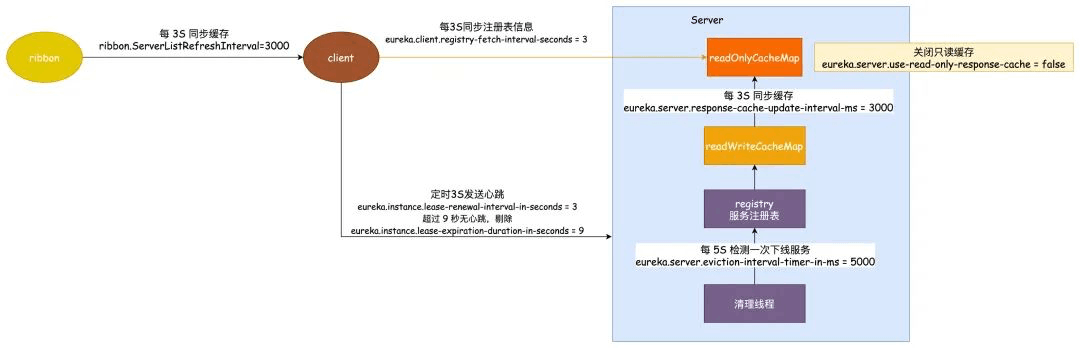
修改 ribbon 同步缓存的时间为 3 秒:ribbon.ServerListRefreshInterval = 3000
修改客户端同步缓存时间为 3 秒 :eureka.client.registry-fetch-interval-seconds = 3
心跳间隔时间修改为 3 秒:eureka.instance.lease-renewal-interval-in-seconds = 3
超时剔除的时间改为 9 秒:eureka.instance.lease-expiration-duration-in-seconds = 9
清理线程定时时间改为 5 秒执行一次:eureka.server.eviction-interval-timer-in-ms = 5000
同步到只读缓存的时间修改为 3 秒一次:eureka.server.response-cache-update-interval-ms = 3000
需要注意的是这里的只读缓存其实是可以关闭的,通过修改参数eureka.server.use-read-only-response-cache = false可以做到,
但是建议不要没有太大必要不要这样做,Eureka 本身就是 AP 模型,用它你就应该有这个觉悟了,另外这个配置只针对原生的 Eureka 生效,SpringCloud Eureka 是没有的,必须一定会从 readOnlyCacheMap 去读。
如果按照这个时间参数设置让我们重新计算可能感知到服务下线的最大时间:
正常下线就是 3+3+3+3=12 秒,非正常下线再加 15 秒为 27 秒。
OK,今天内容就到这儿了,我是艾小仙,下期见。

