
Java线程数过多解决之路——利用Arthas解决Jenkins线程数飙升问题原创
0. 背景
Jenkins是基于Java开发的一款持续集成工具,旨在提供一个开放易用的软件平台,使软件项目可以进行持续集成。同时,Jenkins 提供了数量庞大的各种插 件,以满足用户对于持续集成相关的需求。
比如 Jenkins 提供的influxdb 插件,可以将构建执行步骤、耗时、结果等数据,发送到 influxdb 数据库,便于后期对构建数据进行分析和展示。
Jenkins在公司内部,被广泛用于各类项目的持续集成工作,支撑3000+项目、每日近万次构建。Jenkins是CI/CD的核心链路和重要环节,保障 Jenkins 的 高可用和高性能尤为重要。
1. 问题现象
我们的Jenkins 服务在运行一段时间后,会变得异常卡顿,严重降低持续集成速度,影响研发工作效率。
出了问题后,我们第一时间查看了Jenkins 监控大盘,从监控大盘可以看到,JVM 线程数量飙升得很厉害,最高达 20K:
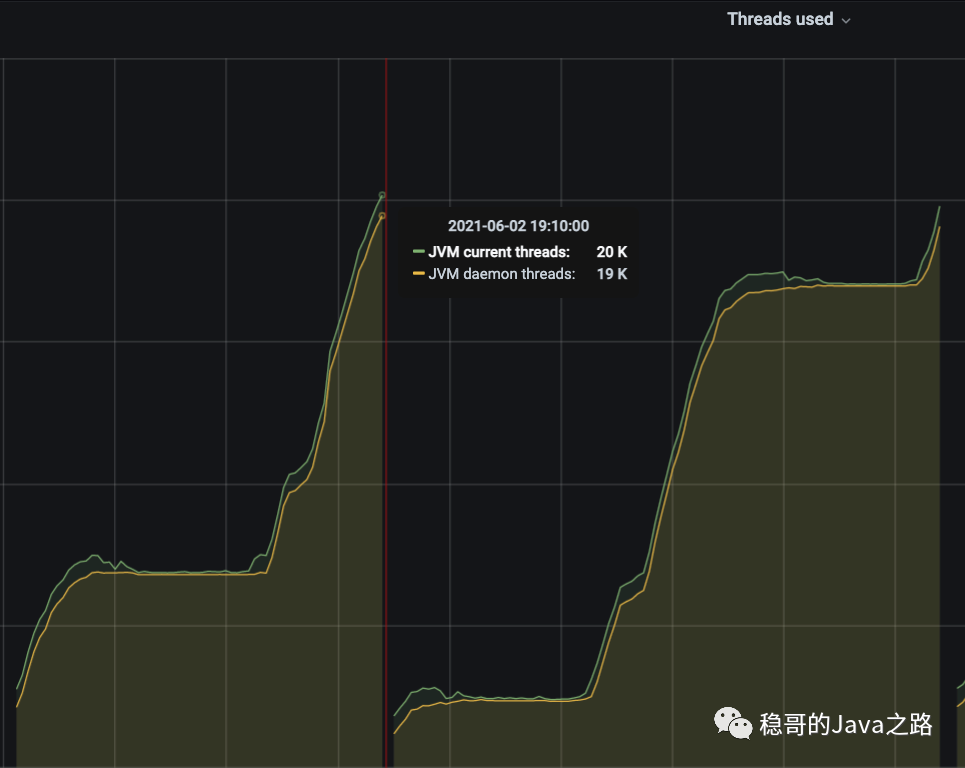
2. 问题分析
2.1 dump 线程栈
发现问题后,登上Jenkins机器,dump下jvm的线程栈。
# 获取 Java 进程 id
jps -l
19768 /home/maintain/jenkins-bin/jenkins/jenkins.war
# dump 线程栈
jstack 19768 > jstack.txt2.2 分析线程栈
拿到这个dump后的线程栈,我们借助 https://fastthread.io/ 这个网站,分析下jvm线程栈。
大致的结果如下:
-
Total Threads count: 20215
-
Thread Group:RxNewThreadScheduler 18600 threads
从以上信息可以知道,jvm总共有20215个线程,其中有18600 个都是RxNewThreadScheduler这个线程组创建的线程。
2.3 定位线程来源
JVM的线程栈中,出现了大量的 RxNewThreadScheduler 这个线程组,从字面上来看,猜测应该是RxJava相关的线程。
为了验证这个猜测,我们决定查阅下 RxJava 框架的源码,看看 RxNewThreadScheduler 这个线程到底是不是从RxJava 框架生成的。
在GitHub上rxjava 的源码中搜索了下RxNewThreadScheduler,如下:
-
代码:https://github.com/ReactiveX/RxJava/search?q=RxNewThreadScheduler
-
结果:
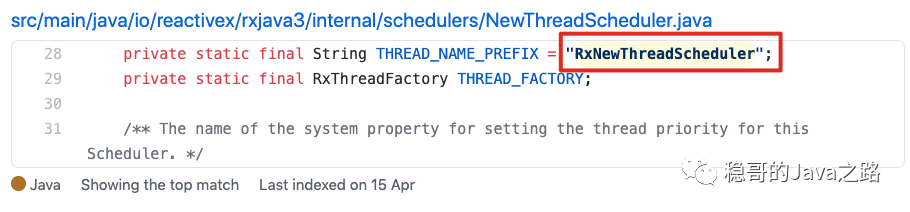
确实, RxJava 项目里包含有线程名前缀是 RxNewThreadScheduler 的线程池,代码在 NewThreadScheduler 类中,证实了我们的猜测。
3. 解决之路
3.1 排查思路
验证 RxNewThreadScheduler 线程名属于 RxJava 后,大概率确定线程数飙升问题是由RxJava导致的。问题是RxJava是怎么跟Jenkins关联起来的呢?是不是 Jenkins的某个插件引入了RxJava呢?
这个问题排查起来似乎没有头绪了:我们的Jenkins安装的插件有几十个,一个一个去看源码不仅费时费力,而且不一定起作用:Jenkins的插件源码中,不 一定会直接写引用了RxJava。
我们只知道一个线程名以及他所属的应用RxJava,怎么去定位到底是哪里引入了这个问题呢?
从thread的dump信息里面来看,基本没有价值:
"RxNewThreadScheduler-2"
#4079 daemon prio=5 os_prio=0 tid=0x00007fa2402a1000 nid=0x5eaf waiting on condition [0x00007fa12a9ae000] java.lang.Thread.State: TIMED_WAITING (parking) at
sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00007fa637001810> (a java.util.concurrent.locks. AbstractQueuedSynchronizer$ConditionObject) at
java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215) at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos
(AbstractQueuedSynchronizer.java:2078) at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor. java:1093) at
java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor. java:809) at
java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134) at
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)问题排查之路似乎走不下去了:山穷水复疑无路。
换个思路想想,既然问题是 RxJava 引入的,我们能不能看看Jenkins到底是怎么把这个 RxJava 给加载进去的呢?毕竟 RxJava 的相关代码,最终还是要运 行在Jenkins对应的JVM里的。
有没有什么工具,能够比较方便、直观的查看 JVM 加载的类、jar包信息呢?Arthas 提供了方便快捷的工具。
3.2 Arthas 简介
援引 Arthas 官网 https://arthas.aliyun.com/doc/index.html 的介绍:Arthas 是Alibaba开源的Java诊断工具,深受开发者喜爱。
Arthas可以帮助解决以下问题:
-
这个类从哪个 jar 包加载的?
-
遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
-
怎样直接从JVM内查找某个类的实例?
当然,arthas 能解决的不止以上问题,更多内容请参见官方文档。
这里面的第一个问题,恰好就是我们遇到的问题,我们要知道RxJava 相关的类,是被哪个 jar 包加载的。
3.3 解决之道 - Arthas Classloader
我们借用arthas来帮助排查问题(arthas安装方法官方文档都有,这里不赘述),Arthas提供了查看类加载相关信息的功能:classloader -l。
java -jar arthas-boot.jar
classloader -l | tee /home/shared/log/arthas.log从arthas的输出中查到了 RxJava:

可以看到,RxJava 是由 influxdb 插件引入的。注:引入influxdb是做Jenkins构建数据统计,没想到会有这个坑,考虑改用prometheus等采集数据。
到这一步感觉就是:柳暗花明又一村。
3.4 问题解决
知道问题是由influxdb插件引入的之后,我们先把influxdb插件禁用,并重启 Jenkins,稳定运行一段时间后,再观察Jenkins的线程数量:
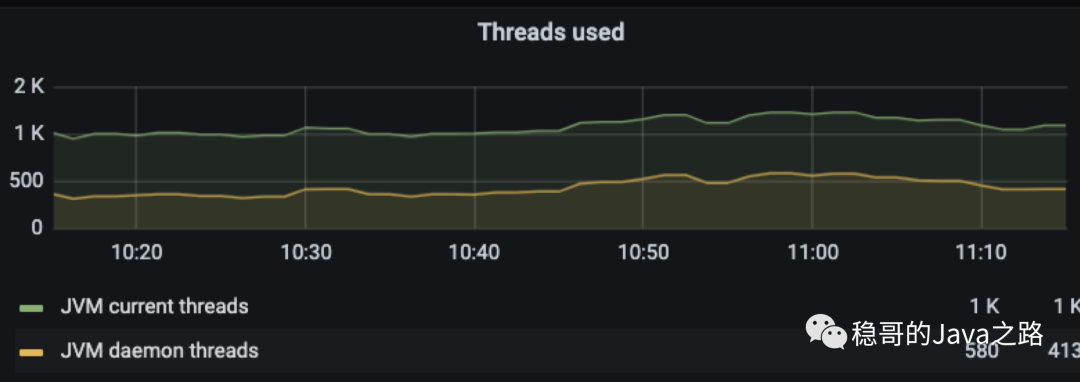
可以看到Jenkins的线程数稳定在1K左右,没有暴增了。同时,查看Jenkins任务构建情况,也恢复到了正常水平,没有卡顿、延迟现象。
4. 源码及根因分析
Jenkins 中引入 influxdb 插件,是为了对Jenkins构建的job数据做存储和分析。为什么influxdb 插件会导致Jenkins线程数飙升呢?这个问题的根因,还得看插件源码。
4.1 influxdb 上报统计数据
在Jenkins Job构建时,influxdb 插件会将统计数据,通过HTTP请求,存储到influxdb数据库中。Influxdb插件在执行HTTP请求时,利用 OkHttp + RxJava 的方式完成。下面将对 influxdb 插件上报统计数据到influxdb 数据库的关键流程源码做分析:
在Jenkins每次构建完成后, influxdb 插件都会调用 writeToInflux 方法,上报相应的数据,如下图:
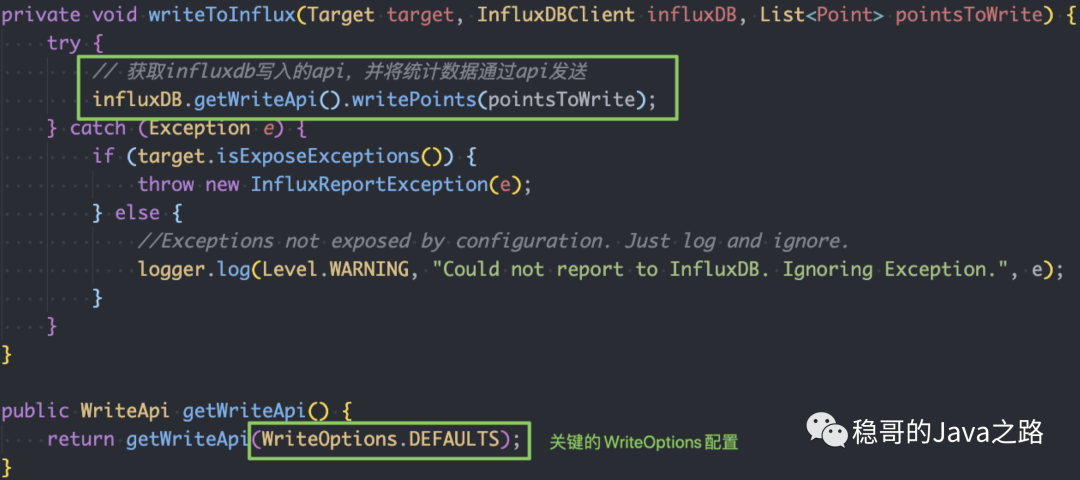
获取 influxdb 写入的api,并将统计数据通过api发送 比较关键的就是这个写 API 的配置:WriteOptions.DEFAULTS,我们看下他具体的配置:
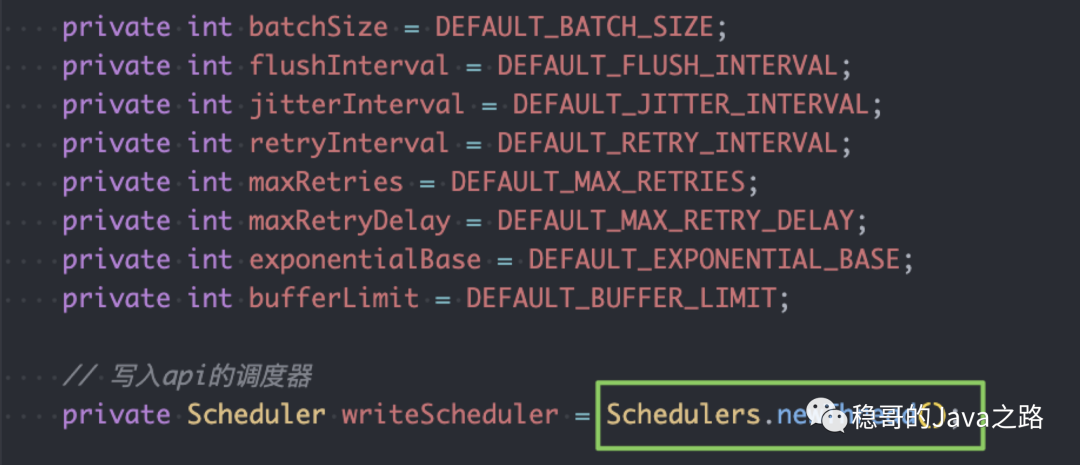
其中比较关键的是 I/O 线程调度器Scheduler,这个是 RxJava 中提供的,他的实现是Schedulers.newThread(),相应代码如下:

在Schedulers.newThread() 方法中,看到了 RxJava 的身影,真正的处理逻辑,交给 newThreadScheduler 去处理:
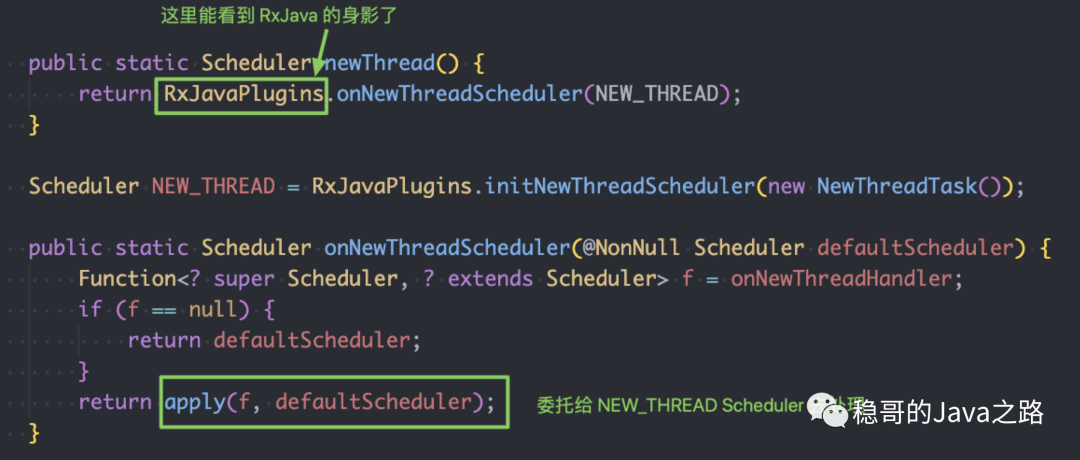
newThreadScheduler 的初始化中,创建了一个NewThreadTask,真正的线程处理逻辑交给他。
4.2 NewThreadScheduler 调度器线程模型
我们先看下NewThreadTask 的定义:
static final class NewThreadHolder {
static final Scheduler DEFAULT = new NewThreadScheduler();
}
static final class NewThreadTask implements Callable<Scheduler> {
@Override
public Scheduler call() throws Exception {
return NewThreadHolder.DEFAULT;
}
}可以看到,这个类实现了Callable 接口并重写了 call 方法,所以真正执行时,会调用该类的 call 方法,而call 方法中,返回的调度器 是NewThreadScheduler 这个调度器。而NewThreadScheduler 这个类,正好是我们在 GitHub 中搜索线程名RxNewThreadScheduler 时出现的那个类。
NewThreadScheduler 调度器的核心代码:
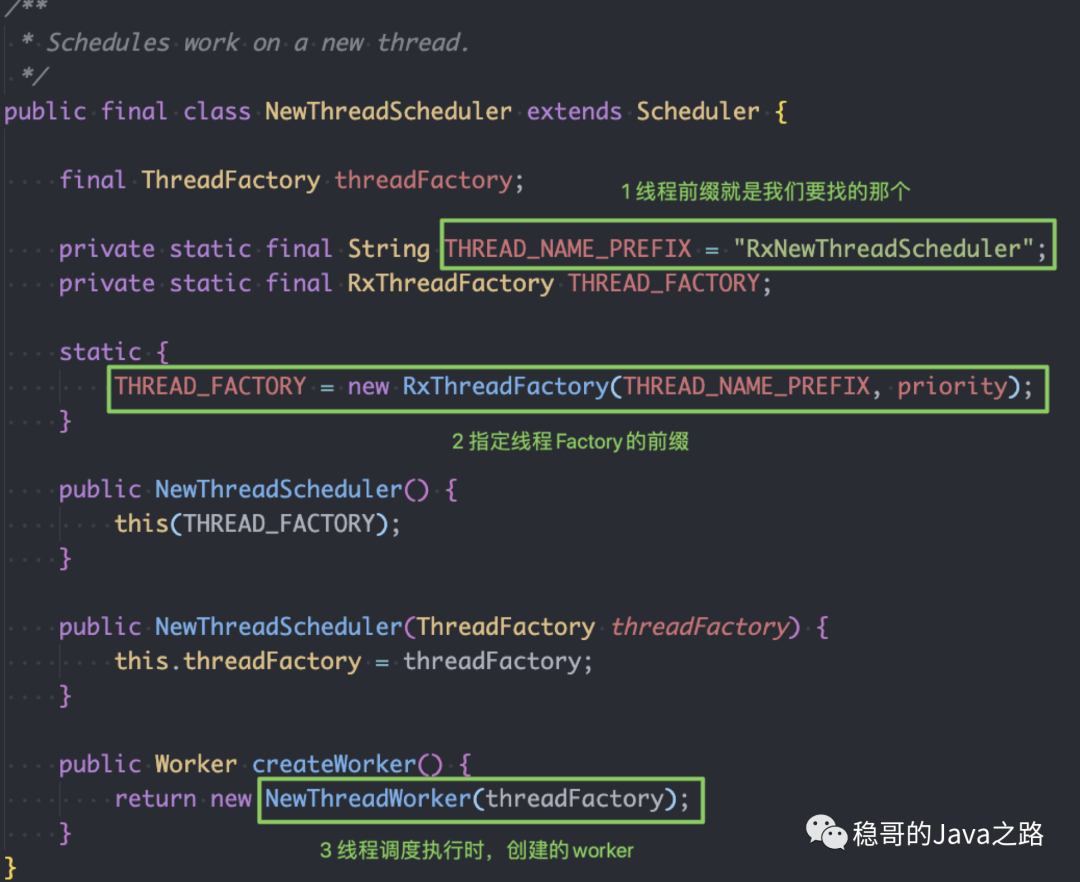
到这里,我们看到,influxdb 是如何与RxNewThreadScheduler 这个线程池给关联上的了:THREAD_FACTORY = new RxThreadFactory ("RxNewThreadScheduler", priority)。
NewThreadScheduler 这个调度器,在真正执行工作的时候,会创建一个NewThreadWorker,其核心代码如下:NewThreadWorker 所使用的线程池,最终创建出来的是一个最大线程池数量特别巨大(Integer.MAX_VALUE)、队列大小为16的线程池。
当Jenkins Job构建量飙升时,influxdb的写入量也飙升,而influxdb所用的IO线程调度器RxJava,创建的线程池是几乎没有上限的,这就导致influxdb在写 入量很高时,创建的线程数也多,最终导致Jenkins线程数飙升。
5. Jenkins数据统计新方案
目前来看,使用influxdb插件来做数据统计,在Job大量构建时会遇到线程数飙升的问题。使用influxdb做数据统计不是唯一可选,业界成熟通用的方案有 prometheus,我们考虑后续将数据统计切换到prometheus。
6. 感想
-
这次排查问题的唯一线索就是线程名RxNewThreadScheduler,所以当你要创建线程池的时候,一定要取个好点的名字,遇到问题时排查问题的同学 会十分感谢你;
-
创建线程池,一定要记住把控maxPoolSize 和 queueSize,不要创建无限界的线程池;
-
工欲善其事,必先利其器;掌握 Arthas 等利器,能够快速定位于解决问题。


