
一次全面的性能优化,从5秒优化到1秒!转载
前言
性能优化,有时候看起来是一个比较虚的技术需求。除非代码慢的已经让人无法忍受,否则,很少有公司会有觉悟投入资源去做这些工作。
即使你有了性能指标数据,也很难说服领导做一个由耗时 300ms 降低到 150ms 的改进,因为它没有业务价值。
这很让人伤心,但这是悲催的现实。
性能优化,通常由有技术追求的人发起,根据观测指标进行的正向优化。他们通常具有工匠精神,对每一毫秒的耗时都吹毛求疵,力求完美。当然,前提是你得有时间。
正文
优化背景和目标
我们本次的性能优化,就是由于达到了无法忍受的程度,才进行的优化工作,属于事后补救,问题驱动的方式。这通常没什么问题,毕竟业务第一嘛,迭代在填坑中进行。
先说背景。本次要优化的服务,请求响应时间十分的不稳定。随着数据量的增加,大部分请求,要耗时 5-6 秒左右!超出了常人能忍受的范围。
当然需要优化。
为了说明要优化的目标,我大体画了一下它的拓扑结构。如图所示,这是一套微服务架构的服务。
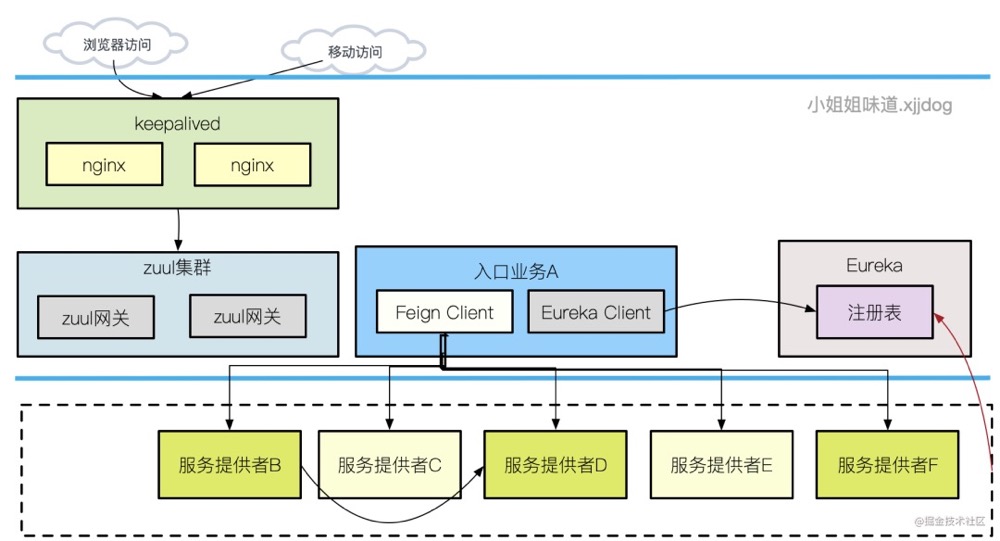
其中,我们优化的目标,就处于一个比较靠上游的服务。它需要通过 Feign 接口,调用下游非常多的服务提供者,获取数据后进行聚合拼接,最终通过 zuul 网关和 nginx,来发送到浏览器客户端。
为了观测服务之间的调用关系和监控数据,我们接入了 Skywalking 调用链平台和 Prometheus 监控平台,收集重要的数据以便能够进行优化决策。
要进行优化之前,我们需要首先看一下优化需要参考的两个技术指标:
吞吐量:单位时间内发生的次数。比如 QPS、TPS、HPS 等。
平均响应时间:每个请求的平均耗时。
平均响应时间自然是越小越好,它越小,吞吐量越高。吞吐量的增加还可以合理利用多核,通过并行度增加单位时间内的发生次数。
我们本次优化的目标,就是减少某些接口的平均响应时间,降低到 1 秒以内;增加吞吐量,也就是提高 QPS,让单实例系统能够承接更多的并发请求。
通过压缩让耗时急剧减少
我想要先介绍让系统飞起来最重要的一个优化手段:压缩。
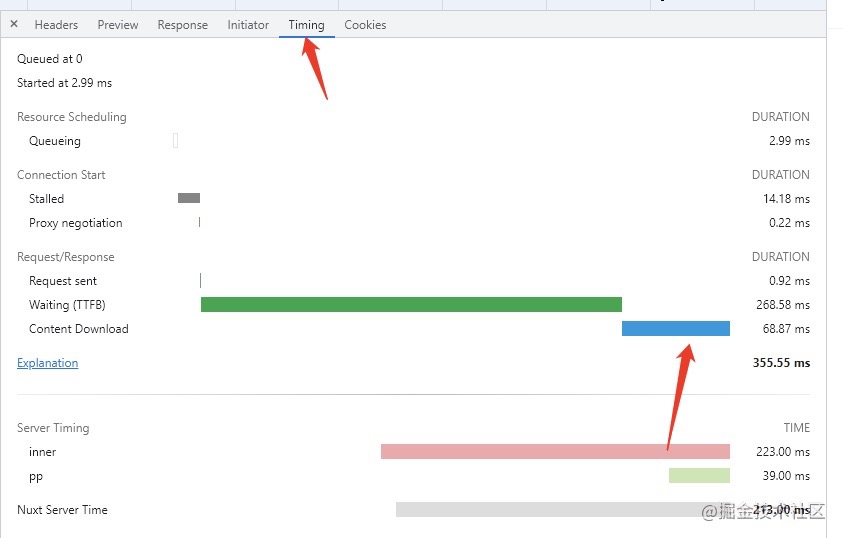
通过在 chrome 的 inspect 中查看请求的数据,我们发现一个关键的请求接口,每次要传输大约 10MB 的数据。这得塞了多少东西。
这么大的数据,光下载就需要耗费大量时间。如下图所示,是我请求 juejin 主页的某一个请求,其中的 content download,就代表了数据在网络上的传输时间。如果用户的带宽非常慢,那么这个请求的耗时,将会是非常长的。
为了减少数据在网络上的传输时间,可以启用 gzip 压缩。gzip 压缩是属于时间换空间的做法。
对于大多数服务来说,最后一环是 nginx,大多数人都会在 nginx 这一层去做压缩。
它的主要配置如下:
gzip on;
gzip_vary on;
gzip_min_length 10240;
gzip_proxied expired no-cache no-store private auth;
gzip_types text/plain text/css text/xml text/javascript application/x-javascript application/xml;
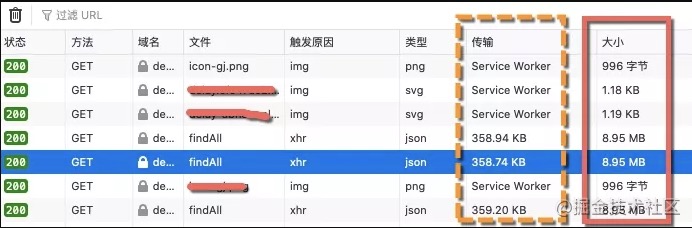
gzip_disable "MSIE [1-6]\.";压缩率有多惊人呢?我们可以看一下这张截图。可以看到,数据压缩后,由 8.95MB 缩减到了 368KB!瞬间就能够被浏览器下载下来。
但是等等,nginx 只是最外面的一环,还没完,我们还可以让请求更快一些。
请看下面的请求路径,由于采用了微服务,请求的流转就变得复杂起来:nginx 并不是直接调用了相关得服务,它调用的是 zuul 网关,zuul 网关才真正调用的目标服务,目标服务又另外调用了其他服务。
内网带宽也是带宽,网络延迟也会影响调用速度,同样也要压缩起来。
nginx->zuul->服务A->服务E
要想 Feign 之间的调用全部都走压缩通道,还需要额外的配置。我们是 springboot 服务,可以通过 okhttp 的透明压缩进行处理。
加入它的依赖:
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-okhttp</artifactId>
</dependency>开启服务端配置:
server:
port:8888
compression:
enabled:true
min-response-size:1024
mime-types:["text/html","text/xml","application/xml","application/json","application/octet-stream"]
开启客户端配置:
feign:
httpclient:
enabled:false
okhttp:
enabled:true经过这些压缩之后,我们的接口平均响应时间,直接从 5-6 秒降低到了 2-3 秒,优化效果非常显著。
当然,我们也在结果集上做了文章,在返回给前端的数据中,不被使用的对象和字段,都进行了精简。
但一般情况下,这些改动都是伤筋动骨的,需要调整大量代码,所以我们在这上面用的精力有限,效果自然也有限。
并行获取数据,响应飞快
接下来,就要深入到代码逻辑内部进行分析了。上面我们提到,面向用户的接口,其实是一个数据聚合接口。
它的每次请求,通过 Feign,调用了几十个其他服务的接口,进行数据获取,然后拼接结果集合。
为什么慢?因为这些请求全部是串行的!Feign 调用属于远程调用,也就是网络 I/O 密集型调用,多数时间都在等待,如果数据满足的话,是非常适合并行调用的。
首先,我们需要分析这几十个子接口的依赖关系,看一下它们是否具有严格的顺序性要求。如果大多数没有,那就再好不过了。
分析结果喜忧参半,这堆接口,按照调用逻辑,大体上可以分为 A,B 类。
首先,需要请求 A 类接口,拼接数据后,这些数据再供 B 类使用。但在 A,B 类内部,是没有顺序性要求的。
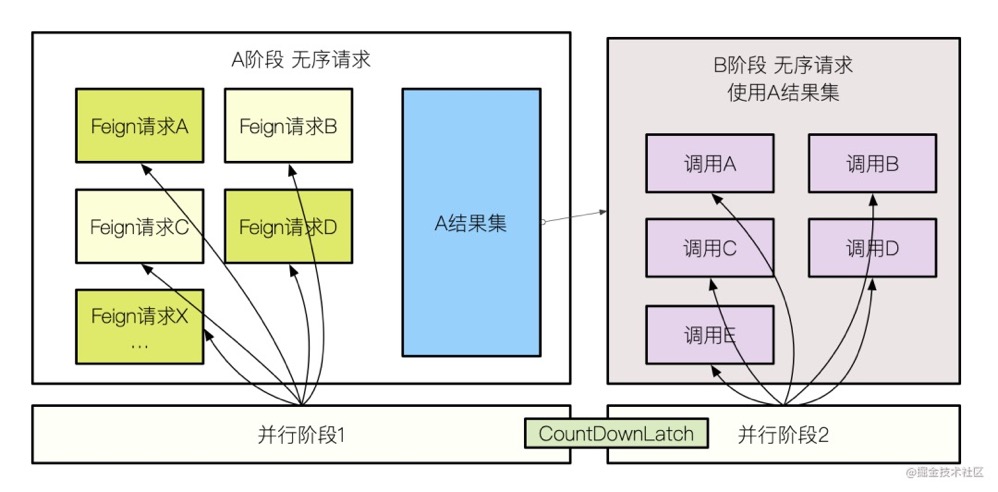
也就是说,我们可以把这个接口,拆分成顺序执行的两部分,在某个部分都可以并行的获取数据。
那就按照这种分析结果改造试试吧,使用 concurrent 包里的 CountDownLatch,很容易的就实现了并取功能。
CountDownLatch latch = new CountDownLatch(jobSize);
//submit job
executor.execute(() -> {
//job code
latch.countDown();
});
executor.execute(() -> {
latch.countDown();
});
...
//end submit
latch.await(timeout, TimeUnit.MILLISECONDS);
结果非常让人满意,我们的接口耗时,又减少了接近一半!此时,接口耗时已经降低到 2 秒以下。
并发编程一定要小心,尤其是在业务代码中的并发编程。我们构造了专用的线程池,来支撑这个并发获取的功能。
final ThreadPoolExecutor executor = new ThreadPoolExecutor(100, 200, 1,
TimeUnit.HOURS, new ArrayBlockingQueue<>(100)); 压缩和并行化,是我们本次优化中,最有效的手段。它们直接砍掉了请求大半部分的耗时,非常的有效。但我们还是不满足,因为每次请求,依然有 1 秒钟以上呢。
缓存分类,进一步加速
我们发现,有些数据的获取,是放在循环中的,有很多无效请求,这不能忍。
for(List){
client.getData();
}如果将这些常用的结果缓存起来,那么就可以大大减少网络 IO 请求的次数,增加程序的运行效率。
缓存在大多数应用程序的优化中,作用非常大。但由于压缩和并行效果的对比,缓存在我们这个场景中,效果不是非常的明显,但依然减少了大约三四十毫秒的请求时间。
我们是这么做的。
首先,我们将一部分代码逻辑简单,适合 Cache Aside Pattern 模式的数据,放在了分布式缓存 Redis 中。
具体来说,就是读取的时候,先读缓存,缓存读不到的时候,再读数据库;更新的时候,先更新数据库,再删除缓存(延时双删)。
使用这种方式,能够解决大部分业务逻辑简单的缓存场景,并能解决数据的一致性问题。
但是,仅仅这么做是不够的,因为有些业务逻辑非常的复杂,更新的代码发非常的分散,不适合使用 Cache Aside Pattern 进行改造。
我们了解到,有部分数据,具有以下特点:
- 这些数据,通过耗时的获取之后,在极端的时间内,会被再次用到
- 业务数据对它们的一致性要求,可以控制在秒级别以内
- 对于这些数据的使用,跨代码、跨线程,使用方式多样
针对于这种情况,我们设计了存在时间极短的堆内内存缓存,数据在 1 秒之后,就会失效,然后重新从数据库中读取。加入某个节点调用服务端接口是 1 秒钟 1k 次,我们直接给降低到了 1 次。
在这里,使用了 Guava 的 LoadingCache,减少的 Feign 接口调用,是数量级的。
LoadingCache<String, String> lc = CacheBuilder
.newBuilder()
.expireAfterWrite(1,TimeUnit.SECONDS)
.build(new CacheLoader<String, String>() {
@Override
public String load(String key) throws Exception {
return slowMethod(key);
}});
MySQL 索引的优化
我们的业务系统,使用的是 MySQL 数据库,由于没有专业 DBA 介入,而且数据表是使用JPA生成的。在优化的时候,发现了大量不合理的索引,当然是要优化掉。
由于 SQL 具有很强的敏感性,我这里只谈一些在优化过程中碰到的索引优化规则问题,相信你一样能够在自己的业务系统中进行类比。
索引非常有用,但是要注意,如果你对字段做了函数运算,那索引就用不上了。
常见的索引失效,还有下面两种情况:
- 查询的索引字段类型,与用户传递的数据类型不同,要做一层隐式转换。比如 varchar 类型的字段上,传入了 int 参数
- 查询的两张表之间,使用的字符集不同,也就无法使用关联字段作为索引
MySQL 的索引优化,最基本的是遵循最左前缀原则,当有 a、b、c 三个字段的时候,如果查询条件用到了 a,或者 a、b,或者 a、b、c,那么我们就可以创建(a,b,c)一个索引即可,它包含了 a 和 ab。当然,字符串也是可以加前缀索引的,但在平常应用中较少。
有时候,MySQL 的优化器,会选择了错误的索引,我们需要使用 force index 指定所使用的索引。
在 JPA 中,就要使用 nativeQuery,来书写绑定到 MySQL 数据库的 SQL 语句,我们尽量的去避免这种情况。
另外一个优化是减少回表。由于 InnoDB 采用了 B+ 树,但是如果不使用非主键索引,会通过二级索引(secondary index)先查到聚簇索引(clustered index),然后再定位到数据。
多了一步,产生回表。使用覆盖索引,可以一定程度上避免回表,是常用的优化手段。
具体做法,就是把要查询的字段,与索引放在一起做联合索引,是一种空间换时间的做法。
JVM 优化
我通常将 JVM 的优化放在最后一环。而且,除非系统发生了严重的卡顿,或者 OOM 问题,都不会主动对其进行过度优化。
很不幸的是,我们的应用,由于开启了大内存(8GB+),在 JDK1.8 默认的并行收集器下,经常发生卡顿。虽然不是很频繁,但动辄几秒钟,已经严重影响到部分请求的平滑性。
程序刚开始,是光秃秃跑在 JVM 下的,GC 信息,还有 OOM,什么都没留下。为了记录 GC 信息,我们做了如下的改造。
第一步,加入 GC 问题排查的各种参数。
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/xxx.hprof -DlogPath=/opt/logs/ -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintTenuringDistribution -Xloggc:/opt/logs/gc_%p.log -XX:ErrorFile=/opt/logs/hs_error_pid%p.log
这样,我们就可以拿着生成的 GC 文件,上传到 gceasy 等平台进行分析。可以查看 JVM 的吞吐量和每个阶段的延时等。
第二步,开启 SpringBoot 的 GC 信息,接入 Promethus 监控。
在 pom 中加入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
然后配置暴露点就可以了。这样,我们就拥有了实时的分析数据,有了优化的依据。
management.endpoints.web.exposure.include=health,info,prometheus
在观测了 JVM 的表现之后,我们切换成了 G1 垃圾回收器。G1 有最大停顿目标,可以让我们的 GC 时间更加的平滑。
它主要有以下几个调优参数:
- -XX:MaxGCPauseMillis:设置目标停顿时间,G1 会尽力达成。
- -XX:G1HeapRegionSize:设置小堆区大小。这个值为 2 的次幂,不要太大,也不要太小。如果是在不知道如何设置,保持默认。
- -XX:InitiatingHeapOccupancyPercent:当整个堆内存使用达到一定比例(默认是 45%),并发标记阶段就会被启动。
- -XX:ConcGCThreads:并发垃圾收集器使用的线程数量。默认值随 JVM 运行的平台不同而不同。不建议修改。
切换成 G1 之后,这种不间断的停顿,竟然神奇的消失了!期间,还发生过很多次内存溢出的问题,不过有 MAT 这种神器的加持,最终都很 easy 的被解决了。
其他优化
在工程结构和架构方面,如果有硬伤的话,那么代码优化方面,起到的作用其实是有限的,就比如我们这种情况。
但主要代码还是要整一下容得。有些处于高耗时逻辑中的关键的代码,我们对其进行了格外的关照。按照开发规范,对代码进行了一次统一的清理。其中,有几个印象比较深深刻的点。
有同学为了能够复用 map 集合,每次用完之后,都使用 clear 方法进行清理。
map1.clear();
map2.clear();
map3.clear();
map4.clear();这些 map 中的数据,特别的多,而 clear 方法有点特殊,它的时间复杂度事 O(n) 的,造成了较高的耗时。
public void clear() {
Node<K,V>[] tab;
modCount++;
if ((tab = table) != null && size > 0) {
size = 0;
for (int i = 0; i < tab.length; ++i)
tab[i] = null;
}
}同样的线程安全的队列,有 ConcurrentLinkedQueue,它的 size() 方法,时间复杂度非常高,不知怎么就被同事给用上了,这都是些性能杀手。
public int size() {
restartFromHead: for (;;) {
int count = 0;
for (Node<E> p = first(); p != null;) {
if (p.item != null)
if (++count == Integer.MAX_VALUE)
break; // @see Collection.size()
if (p == (p = p.next))
continue restartFromHead;
}
return count;
}
}
另外,有些服务的 web 页面,本身响应就非常的慢,这是由于业务逻辑复杂,前端 JavaScript 本身就执行缓慢。
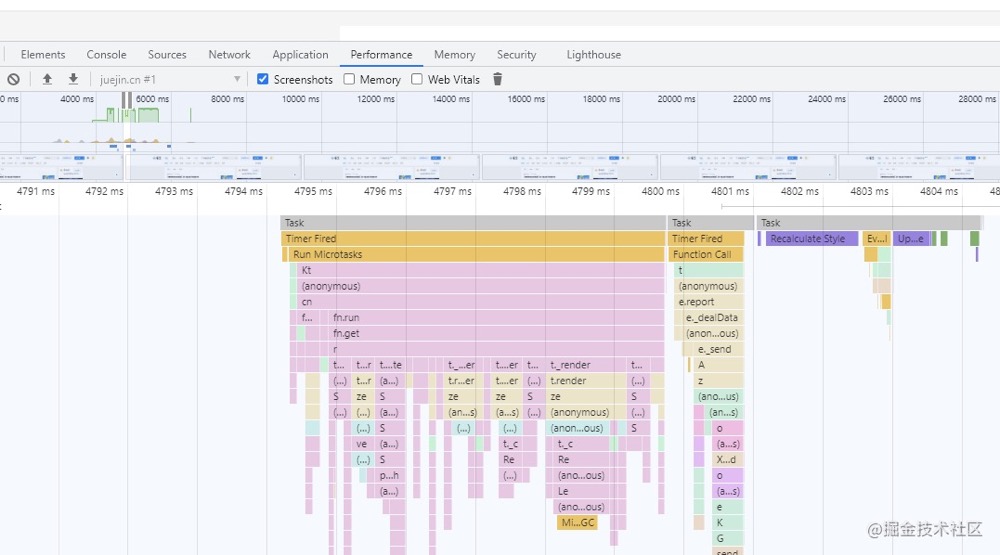
这部分代码优化,就需要前端的同事去处理了,如图,使用 chrome 或者 firefox 的 performance 选项卡,可以很容易发现耗时的前端代码。
总结
性能优化,其实也是有套路的,但一般团队都是等发生了问题才去优化,鲜有未雨绸缪的。但有了监控和 APM 就不一样,我们能够随时拿到数据,反向推动优化过程。
有些性能问题,能够在业务需求层面,或者架构层面去解决。凡是已经带到代码层,需要程序员介入的优化,都已经到了需求方和架构方不能再乱动,或者不想再动的境地。
性能优化首先要收集信息,找出瓶颈点,权衡 CPU、内存、网络、、IO 等资源,然后尽量的减少平均响应时间,提高吞吐量。
缓存、缓冲、池化、减少锁冲突、异步、并行、压缩,都是常见的优化方式。在我们的这个场景中,起到最大作用的,就是数据压缩和并行请求。
当然,加上其他优化方法的协助,我们的业务接口,由 5-6 秒的耗时,直接降低到了 1 秒之内,这个优化效果还是非常可观的。估计在未来很长一段时间内,都不会再对它进行优化了。


