
一次因多线程使用不当导致OOM的排查过程转载
导语
多线程使用不当会导致OOM,如果没有及时发现更会导致GC,本篇是作者日常中遇到到因多线程使用不当导致的OOM排查过程,也是一篇比较经典的OOM排查实战,希望大家读后有所收获。
正文
事故描述
老规矩,我们先看下事故过程:某日,从 6 点 32 分开始少量用户访问 app 时会出现首页访问异常,到 7 点 20 分首页服务大规模不可用,7 点 36 分问题解决。
整体经过
事故的整个经过如下:
6:58,发现报警,同时发现群里反馈首页出现网络繁忙,考虑到前几日晚上门店列表服务上线发布过,所以考虑回滚代码紧急处理问题。
7:07,开始先后联系 XXX 查看解决问题。
7:36,代码回滚完,服务恢复正常。
事故根本原因
事故代码模拟如下:
public static void test() throws InterruptedException, ExecutionException {
Executor executor = Executors.newFixedThreadPool(3);
CompletionService<String> service = new ExecutorCompletionService<>(executor);
service.submit(new Callable<String>() {
@Override
public String call() throws Exception {
return "HelloWorld--" + Thread.currentThread().getName();
}
});
}
先抛出问题,我们后面会详细阐述。问题的根源就在于 ExecutorCompletionService 结果没调用 take,poll 方法。
正确的写法如下所示:
public static void test() throws InterruptedException, ExecutionException {
Executor executor = Executors.newFixedThreadPool(3);
CompletionService<String> service = new ExecutorCompletionService<>(executor);
service.submit(new Callable<String>() {
@Override
public String call() throws Exception {
return "HelloWorld--" + Thread.currentThread().getName();
}
});
service.take().get();
}
一行代码引发的血案,而且不容易被发现,因为 OOM 是一个内存缓慢增长的过程,稍微粗心大意就会忽略,如果是这个代码块的调用量少的话,很可能几天甚至几个月后暴雷。
操作人回滚 or 重启服务器确实是最快的方式,但是如果不是事后快速分析出 OOM 的代码,而且不巧回滚的版本也是带 OOM 代码的,就比较悲催了。
如刚才所说,流量小了,回滚或者重启都可以释放内存;但是流量大的情况下,除非回滚到正常的版本,否则 GG。
探讨问题的根源
接下来我们来探讨问题的根源,为了更好的理解 ExecutorCompletionService 的 “套路”,我们用 ExecutorService 来作为对比,可以让我们更好的清楚,什么场景下用 ExecutorCompletionService。
先看 ExecutorService 代码:(建议 down 下来跑一跑,以下代码建议吃饭的时候不要去看,味道略重!不过便于理解 orz)
public static void test1() throws Exception{
ExecutorService executorService = Executors.newCachedThreadPool();
ArrayList<Future<String>> futureArrayList = new ArrayList<>();
System.out.println("公司让你通知大家聚餐 你开车去接人");
Future<String> future10 = executorService.submit(() -> {
System.out.println("总裁:我在家上大号 我最近拉肚子比较慢 要蹲1个小时才能出来 你等会来接我吧");
TimeUnit.SECONDS.sleep(10);
System.out.println("总裁:1小时了 我上完大号了。你来接吧");
return "总裁上完大号了";
});
futureArrayList.add(future10);
Future<String> future3 = executorService.submit(() -> {
System.out.println("研发:我在家上大号 我比较快 要蹲3分钟就可以出来 你等会来接我吧");
TimeUnit.SECONDS.sleep(3);
System.out.println("研发:3分钟 我上完大号了。你来接吧");
return "研发上完大号了";
});
futureArrayList.add(future3);
Future<String> future6 = executorService.submit(() -> {
System.out.println("中层管理:我在家上大号 要蹲10分钟就可以出来 你等会来接我吧");
TimeUnit.SECONDS.sleep(6);
System.out.println("中层管理:10分钟 我上完大号了。你来接吧");
return "中层管理上完大号了";
});
futureArrayList.add(future6);
TimeUnit.SECONDS.sleep(1);
System.out.println("都通知完了,等着接吧。");
try {
for (Future<String> future : futureArrayList) {
String returnStr = future.get();
System.out.println(returnStr + ",你去接他");
}
Thread.currentThread().join();
} catch (Exception e) {
e.printStackTrace();
}
}三个任务,每个任务执行时间分别是 10s、3s、6s。
通过 JDK 线程池的 submit 提交这三个 Callable 类型的任务:
step1:主线程把三个任务提交到线程池里面去,把对应返回的 Future 放到 List 里面存起来,然后执行“都通知完了,等着接吧。”这行输出语句。
step2:在循环里面执行 future.get() 操作,阻塞等待。
最后结果如下:

先通知到总裁,也是先接总裁,足足等了 1 个小时,接到总裁后再去接研发和中层管理,尽管他们早就完事儿了,也得等总裁拉完~~
耗时最久的-10s 异步任务最先进入 list 执行,所以在循环过程中获取这个 10s 的任务结果的时候,get 操作会一直阻塞,直到 10s 异步任务执行完毕。即使 3s、5s 的任务早就执行完了,也得阻塞等待 10s 任务执行完。
看到这里,尤其是做网关业务的同学可能会产生共鸣,一般来说网关 RPC 会调用下游 N 多个接口,如下图:
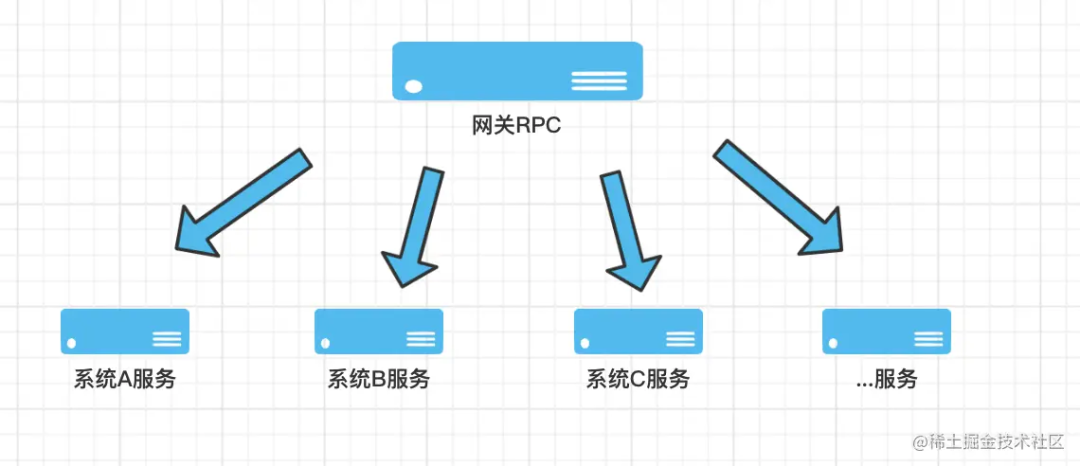
如果都按照 ExecutorService 这种方式,并且恰巧前几个任务调用的接口耗时比较久,同时阻塞等待,那就比较悲催了。
所以 ExecutorCompletionService 应景而出。它作为任务线程的合理管控者,“任务规划师”的称号名副其实。
相同场景 ExecutorCompletionService 代码:
public static void test2() throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
ExecutorCompletionService<String> completionService = new ExecutorCompletionService<>(executorService);
System.out.println("公司让你通知大家聚餐 你开车去接人");
completionService.submit(() -> {
System.out.println("总裁:我在家上大号 我最近拉肚子比较慢 要蹲1个小时才能出来 你等会来接我吧");
TimeUnit.SECONDS.sleep(10);
System.out.println("总裁:1小时了 我上完大号了。你来接吧");
return "总裁上完大号了";
});
completionService.submit(() -> {
System.out.println("研发:我在家上大号 我比较快 要蹲3分钟就可以出来 你等会来接我吧");
TimeUnit.SECONDS.sleep(3);
System.out.println("研发:3分钟 我上完大号了。你来接吧");
return "研发上完大号了";
});
completionService.submit(() -> {
System.out.println("中层管理:我在家上大号 要蹲10分钟就可以出来 你等会来接我吧");
TimeUnit.SECONDS.sleep(6);
System.out.println("中层管理:10分钟 我上完大号了。你来接吧");
return "中层管理上完大号了";
});
TimeUnit.SECONDS.sleep(1);
System.out.println("都通知完了,等着接吧。");
//提交了3个异步任务)
for (int i = 0; i < 3; i++) {
String returnStr = completionService.take().get();
System.out.println(returnStr + ",你去接他");
}
Thread.currentThread().join();
}
跑完结果如下:

这次就相对高效了一些,虽然先通知的总裁,但是根据大家上大号的速度,谁先拉完先去接谁,不用等待上大号最久的总裁了(现实生活里,建议采用第一种,不等总裁的后果 emmm 哈哈哈)。

放在一起对比下输出结果:
两段代码的差异非常小,获取结果的时候 ExecutorCompletionService 使用了:
completionService.take().get();
为毛要用 take() 然后再 get() 呢????我们看看源码:
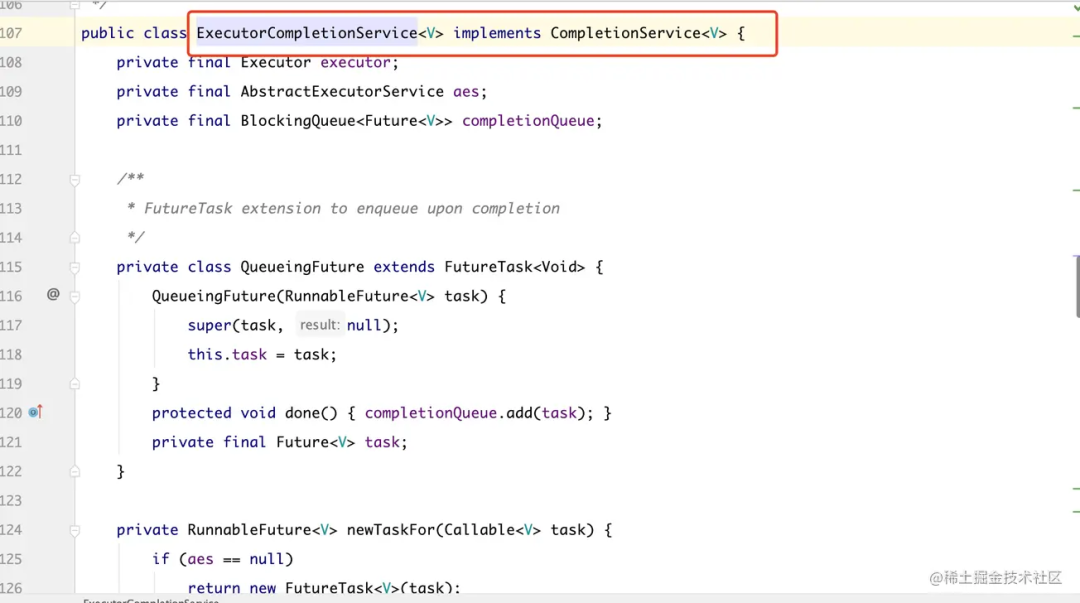
| CompletionService 接口以及接口的实现类
ExecutorCompletionService 是 CompletionService 接口的实现类:
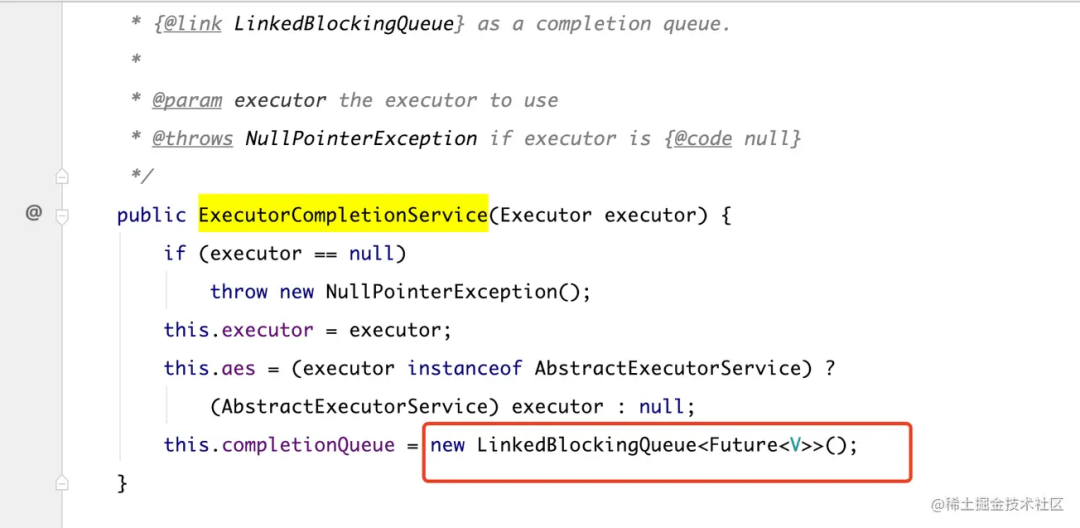
接着跟一下 ExecutorCompletionService 的构造方法,可以看到入参需要传一个线程池对象,默认使用的队列是 LinkedBlockingQueue,不过还有另外一个构造方法可以指定队列类型,如下两张图,两个构造方法。
默认 LinkedBlockingQueue 的构造方法:
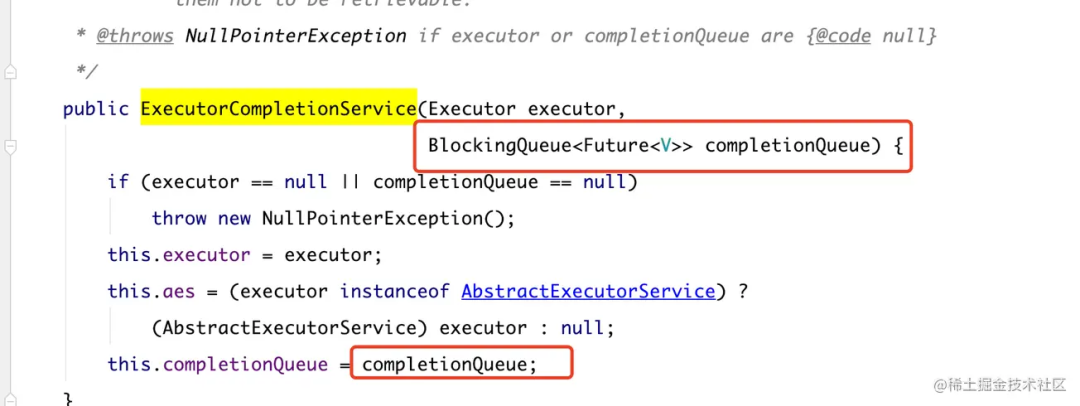
可选队列类型的构造方法:
submit 任务提交的两种方式,都是有返回值的,我们例子中用到的就是第一种 Callable 类型的方法。
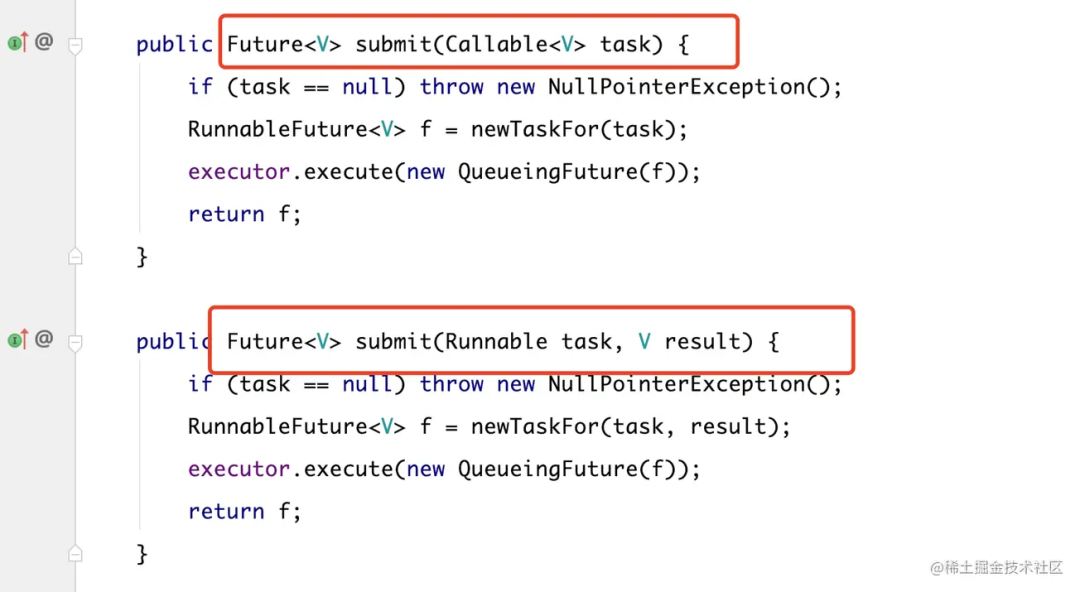
对比 ExecutorService 和 ExecutorCompletionService submit 方法,可以看出区别。
ExecutorService:
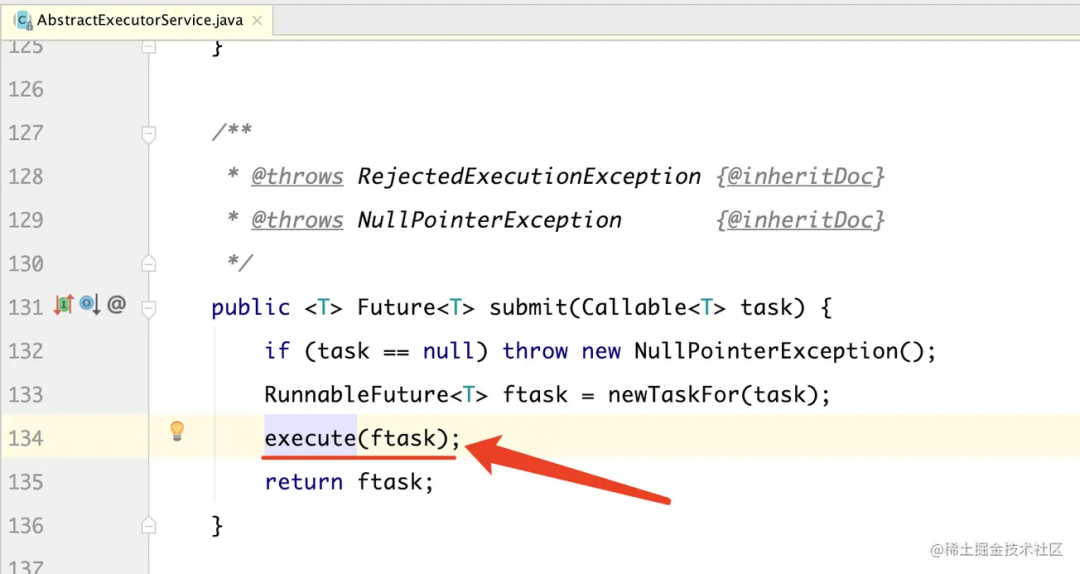
ExecutorCompletionService:
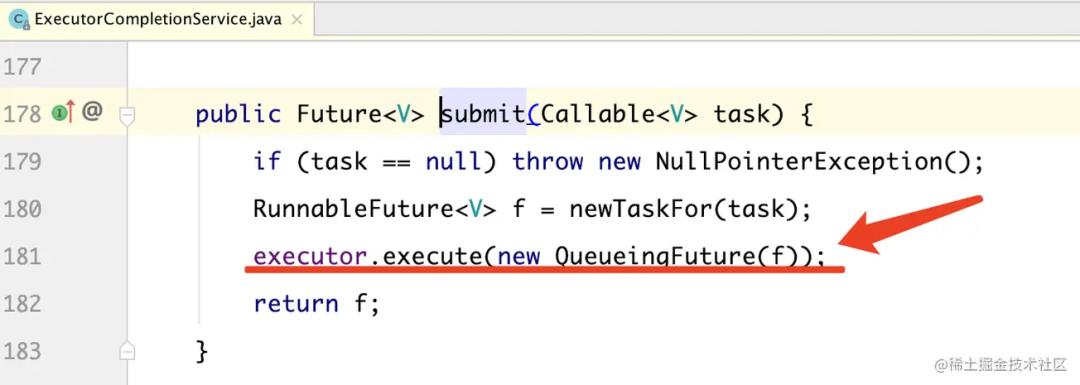
差异就在 QueueingFuture,这个到底作用是啥?
我们继续跟进去看:
- QueueingFuture 继承自 FutureTask,而且红线部分标注的位置,重写了 done() 方法。
- 把 task 放到 completionQueue 队列里面,当任务执行完成后,task 就会被放到队列里面去了。
- 此时此刻 completionQueue 队列里面的 task 都是已经 done() 完成了的 task,而这个 task 就是我们拿到的一个个的 future 结果。
- 如果调用 completionQueue 的 task 方法,会阻塞等待任务。等到的一定是完成了的 future,我们调用 .get() 方法就能立马获得结果。
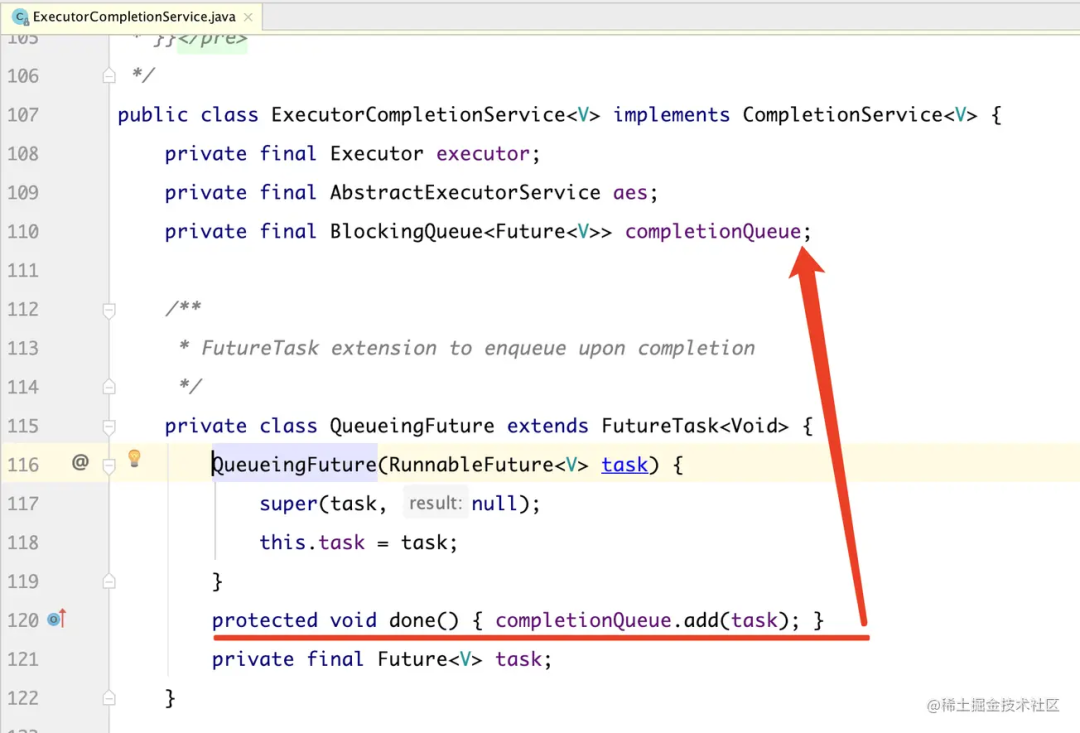
看到这里,相信大家伙都应该多少明白点了:
我们在使用 ExecutorService submit 提交任务后需要关注每个任务返回的 future,然而 CompletionService 对这些 future 进行了追踪,并且重写了 done 方法,让你等的 CompletionQueue 队列里面一定是完成了的 task。
作为网关 RPC 层,我们不用因为某一个接口的响应慢拖累所有的请求,可以在处理最快响应的业务场景里使用 CompletionService。
| but,注意、注意、注意,也是本次事故的核心
当只有调用了 ExecutorCompletionService 下面的 3 个方法的任意一个时,阻塞队列中的 task 执行结果才会从队列中移除掉,释放堆内存。
由于该业务不需要使用任务的返回值,则没进行调用 take,poll 方法。从而导致没有释放堆内存,堆内存会随着调用量的增加一直增长。

所以,业务场景中不需要使用任务返回值的 别没事儿使用 CompletionService,假如使用了,记得一定要从阻塞队列中移除掉 task 执行结果,避免 OOM!
总结
知道事故的原因,我们来总结下方**,毕竟孔子他老人家说过:自省吾身,常思己过,善修其身!
上线前:
- 严格的代码 review 习惯,一定要交给 back 人去看,毕竟自己写的代码自己是看不出问题的,相信每个程序猿都有这个自信(这个后续事故里可能会反复提到,很重要)
- 上线记录-备注好上一个可回滚的包版本(给自己留一个后路)
- 上线前确认回滚后,业务是否可降级,如果不可降级,一定要严格拉长这次上线的监控周期
上线后:
- 持续关注内存增长情况(这部分极容易被忽略,大家对内存的重视度不如 CPU 使用率)
- 持续关注 CPU 使用率增长情况
- GC 情况、线程数是否增长、是否有频繁的 FullGC 等
- 关注服务性能报警,tp99、999 、max 是否出现明显的增高
更多思考:
本篇是一篇思路很清晰的OOM排查实战,更多关于OOM的内容大家可以阅读以下内容:
首次排查 OOM 实录
导致程序出现OOM的因素,夜深人静的时候,程序OOM异常追踪
原文链接:https://c1n.cn/PzfgJ

