
如何干掉OOM,看这篇就够了!转载
前言
随着项目不断壮大,OOM(Out Of Memory)成为奔溃统计平台上的疑难杂症之一。
大部分业务开发人员对于线上 OOM 问题一般都是暂不处理:
一方面是因为 OOM 问题没有足够的 log,无法在短期内分析解决。
另一方面可能是忙于业务迭代、身心疲惫,没有精力去研究 OOM 的解决方案。
这篇文章将以线上 OOM 问题作为切入点,介绍常见的 OOM 类型、OOM 的原理、大厂 OOM 优化黑科技、以及主流的 OOM 监控方案。文章较长,请备好小板凳!
OOM 问题分类
很多人对于 OOM 的理解就是 Java 虚拟机内存不足,但通过线上 OOM 问题分析,OOM 可以大致归为以下 3 类:
- 线程数太多
- 打开太多文件
- 内存不足
接下来将分别围绕这三类问题进行展开分析。
线程数太多
| 报错信息
pthread_create (1040KB stack) failed: Out of memory
这个是典型的创建新线程触发的 OOM 问题。

| 源码分析
pthread_create 触发的 OOM 异常,源码(Android 9)位置如下:
http://androidxref.com/9.0.0_r3/xref/art/runtime/thread.cc
void Thread::CreateNativeThread(JNIEnv* env, jobject java_peer, size_t stack_size, bool is_daemon) {
...
pthread_create_result = pthread_create(...)
//创建线程成功
if (pthread_create_result == 0) {
return;
}
//创建线程失败
...
{
std::string msg(child_jni_env_ext.get() == nullptr ?
StringPrintf("Could not allocate JNI Env: %s", error_msg.c_str()) :
StringPrintf("pthread_create (%s stack) failed: %s",
PrettySize(stack_size).c_str(), strerror(pthread_create_result)));
ScopedObjectAccess soa(env);
soa.Self()->ThrowOutOfMemoryError(msg.c_str());
}
}pthread_create 里面会调用 Linux 内核创建线程,那什么情况下会创建线程失败呢?
查看系统对每个进程的线程数限制:
cat /proc/sys/kernel/threads-max

不同设备的 threads-max 限制是不一样的,有些厂商的低端机型 threads-max 比较小,容易出现此类 OOM 问题。
查看当前进程运行的线程数:
cat proc/{pid}/status
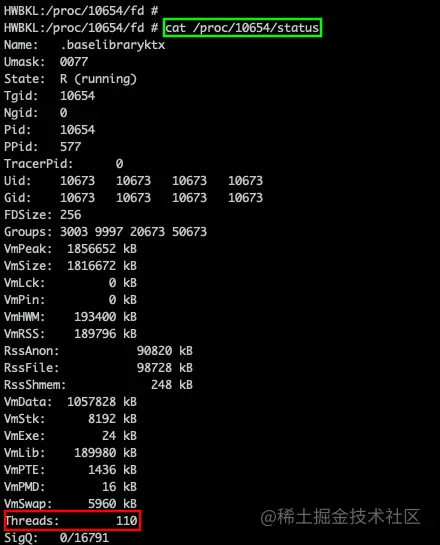
当线程数超过 /proc/sys/kernel/threads-max 中规定的上限时就会触发 OOM。
既然系统对每个进程的线程数有限制,那么解决这个问题的关键就是尽可能降低线程数的峰值。
| 线程优化
①禁用 new Thread
解决线程过多问题,传统的方案是禁止使用 new Thread,统一使用线程池,但是一般很难人为控制, 可以在代码提交之后触发自动检测,有问题则通过邮件通知对应开发人员。
不过这种方式存在两个问题:
- 无法解决老代码的 new Thread
- 对于第三方库无法控制
②无侵入性的 new Thread 优化
Java 层的 Thread 只是一个普通的对象,只有调用了 start 方法,才会调用 native 层去创建线程。
所以理论上我们可以自定义 Thread,重写 start 方法,不去启动线程,而是将任务放到线程池中去执行,为了做到无侵入性,需要在编译期通过字节码插桩的方式,将所有 new Thread 字节码都替换成 new 自定义 Thread。
步骤如下:
创建一个 Thread 的子类叫 ShadowThread 吧,重写 start 方法,调用自定义的线程池 CustomThreadPool 来执行任务。
public class ShadowThread extends Thread {
@Override
public synchronized void start() {
Log.i("ShadowThread", "start,name="+ getName());
CustomThreadPool.THREAD_POOL_EXECUTOR.execute(new MyRunnable(getName()));
}
class MyRunnable implements Runnable {
String name;
public MyRunnable(String name){
this.name = name;
}
@Override
public void run() {
try {
ShadowThread.this.run();
Log.d("ShadowThread","run name="+name);
} catch (Exception e) {
Log.w("ShadowThread","name="+name+",exception:"+ e.getMessage());
RuntimeException exception = new RuntimeException("threadName="+name+",exception:"+ e.getMessage());
exception.setStackTrace(e.getStackTrace());
throw exception;
}
}
}
}在编译期,hook 所有 new Thread 字节码,全部替换成我们自定义的 ShadowThread,这个难度应该不大,按部就班,我们先确认 new Thread 和 new ShadowThread 对应字节码差异。
可以安装一个 ASM Bytecode Viewer 插件,如下所示:
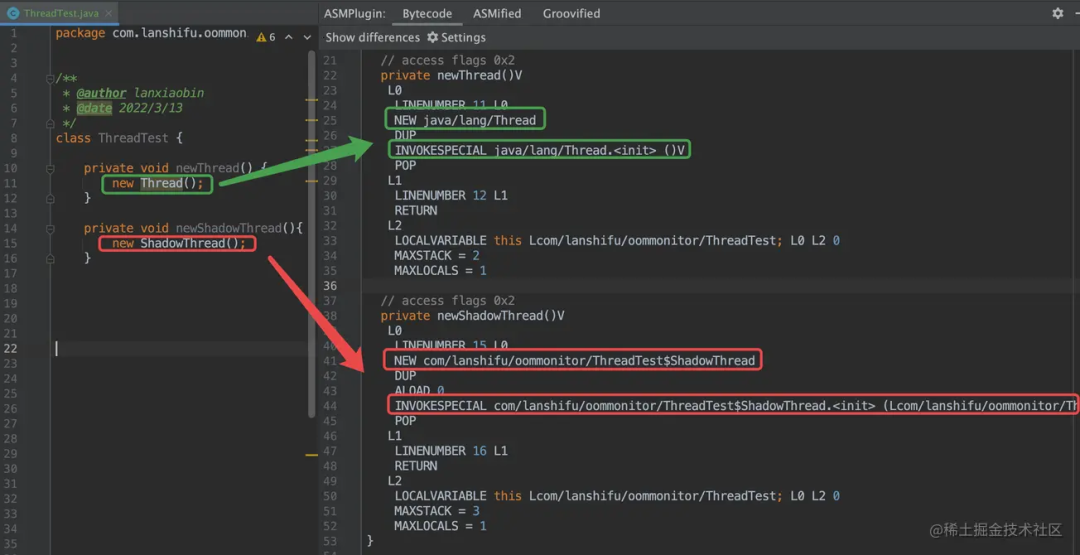
通过字节码修改,你可以简单理解为做如下替换:
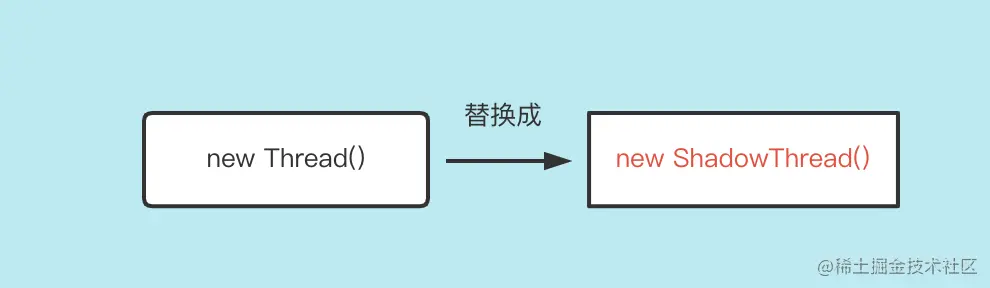
由于将任务放到线程池去执行,假如线程奔溃了,我们不知道是哪个线程出问题,所以自定义 ShadowThread 中的内部类 MyRunnable 的作用是:在线程出现异常的时候,将异常捕获,还原它的名字,重新抛出一个信息更全的异常。
测试代码:
private fun testThreadCrash() {
Thread {
val i = 9 / 0
}.apply {
name = "testThreadCrash"
}.start()
}开启一个线程,然后触发奔溃,堆栈信息如下:

可以看到原本的 new Thread 已经被优化成了 CustomThreadPool 线程池调用,并且奔溃的时候不用担心找不到线程是哪里创建的,会还原线程名。
当然这种方式有一个小问题,应用正常运行的情况下,如果你想要收集所有线程信息,那么线程名可能不太准确,因为通过 new Thread 去创建线程,已经被替换成线程池调用了,获取到的线程名是线程池中的线程的名字。
数据对比:同个场景简单测试了一下 new Thread 优化前后线程数峰值对比如下图。

对于不同 App,优化效果会有一些不同,不过可以看到这个优化确实是有效的。
③无侵入的线程池优化
随着项目引入的 SDK 越来越多,绝大部分 SDK 内部都会使用自己的线程池做异步操作,线程池的参数如果设置不对,核心线程空闲的时候没有释放,会使整体的线程数量处于较高位置。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}线程池几个参数:
- corePoolSize:核心线程数量。核心线程默认情况下即使空闲也不会释放,除非设置 allowCoreThreadTimeOut 为 true。
- maximumPoolSize:最大线程数量。任务数量超过核心线程数,就会将任务放到队列中,队列满了,就会启动非核心线程执行任务,线程数超过这个限制就会走拒绝策略。
- keepAliveTime:空闲线程存活时间。
- unit:时间单位。
- workQueue:队列。任务数量超过核心线程数,就会将任务放到这个队列中,直到队列满,就开启新线程,执行队列第一个任务。
- threadFactory:线程工厂。实现 new Thread 方法创建线程。
通过线程池参数,我们可以找到优化点如下:
- 限制空闲线程存活时间,keepAliveTime 设置小一点,例如 1-3s
- 允许核心线程在空闲时自动销毁
executor.allowCoreThreadTimeOut(true)
如何做呢?为了做到无侵入性,依然采用 ASM 操作字节码,跟 new Thread 的替换基本同理。
在编译期,通过 ASM,做如下几个操作:
- 将调用 Executors 类的静态方法替换为自定义 ShadowExecutors 的静态方法,设置 executor.allowCoreThreadTimeOut(true);
- 将调用 ThreadPoolExecutor 类的构造方法替换为自定义 ShadowThreadPoolExecutor 的静态方法,设置 executor.allowCoreThreadTimeOut(true);
- 可以在 Application 类的 <clinit>() 中调用我们自定义的静态方法 ShadowAsyncTask.optimizeAsyncTaskExecutor() 来修改 AsyncTask 的线程池参数,调用 executor.allowCoreThreadTimeOut(true);
你可以简单理解为做如下替换:

详细代码可以参考 booster。
https://booster.johnsonlee.io/zh/guide/performance/multithreading-optimization.html#%E7%BA%BF%E7%A8%8B%E7%AE%A1%E7%90%86%E9%9D%A2%E4%B8%B4%E7%9A%84%E6%8C%91%E6%88%98
| 线程监控
假如线程优化后还存在创建线程 OOM 问题,那我们就需要监控是否存在线程泄漏的情况。
①线程泄漏监控
主要监控 native 线程的几个生命周期方法:
- pthread_create
- pthread_detach
- pthread_join
- pthread_exit
hook 以上几个方法,用于记录线程的生命周期和堆栈,名称等信息;当发现一个 joinable 的线程在没有 detach 或者 join 的情况下,执行了 pthread_exit,则记录下泄露线程信息;在合适的时机,上报线程泄露信息。
linux 线程中,pthread 有两种状态 joinable 状态和 unjoinable 状态。
joinable 状态下,当线程函数自己返回退出时或 pthread_exit 时都不会释放线程所占用堆栈和线程描述符。
只有当你调用了 pthread_join 之后这些资源才会被释放,需要 main 函数或者其他线程去调用 pthread_join 函数。
具体代码可以参考:KOOM-thread_holder。
https://github.com/KwaiAppTeam/KOOM/blob/master/koom-thread-leak/src/main/cpp/src/thread/thread_holder.cpp
②线程上报
当监控到线程有异常的时候,我们可以收集线程信息,上报到后台进行分析。
收集线程信息代码如下:
private fun dumpThreadIfNeed() {
val threadNames = runCatching { File("/proc/self/task").listFiles() }
.getOrElse {
return@getOrElse emptyArray()
}
?.map {
runCatching { File(it, "comm").readText() }.getOrElse { "failed to read $it/comm" }
}
?.map {
if (it.endsWith("\n")) it.substring(0, it.length - 1) else it
}
?: emptyList()
Log.d("TAG", "dumpThread = " + threadNames.joinToString(separator = ","))
}
接下来介绍打开太多文件导致的 OOM 问题。
打开太多文件
| 错误信息
E/art: ashmem_create_region failed for 'indirect ref table': Too many open files
Java.lang.OutOfMemoryError: Could not allocate JNI Env这个问题跟系统、厂商关系比较大。
| 系统限制
Android 是基于 Linux 内核,/proc/pid/limits 描述着 linux 系统对每个进程的一些资源限制,如下图是一台 Android 6.0 的设备,Max open files 的限制是 1024。
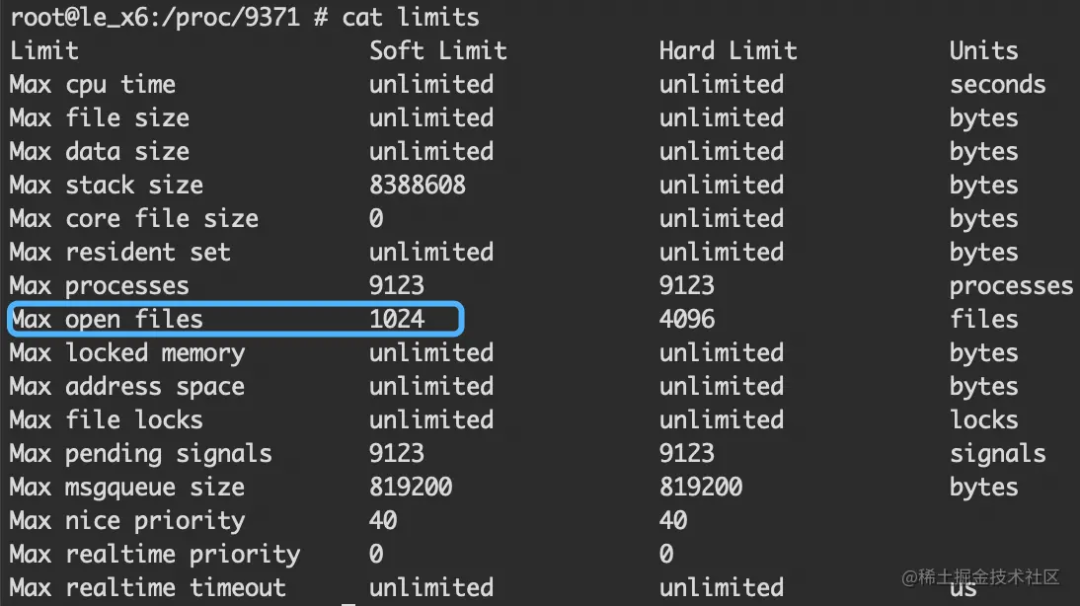
如果没有 root 权限,可以通过 ulimit -n 命令查看 Max open files,结果是一样的。
ulimit -n

Linux 系统一切皆文件,进程每打开一个文件就会产生一个文件描述符 fd(记录在 /proc/pid/fd 下面)。
cd /proc/10654/fd
ls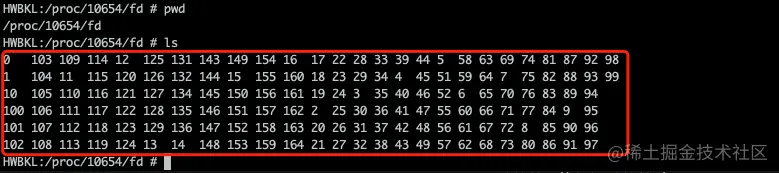
这些 fd 文件都是链接文件,通过 ls -l 可以查看其对应的真实文件路径。
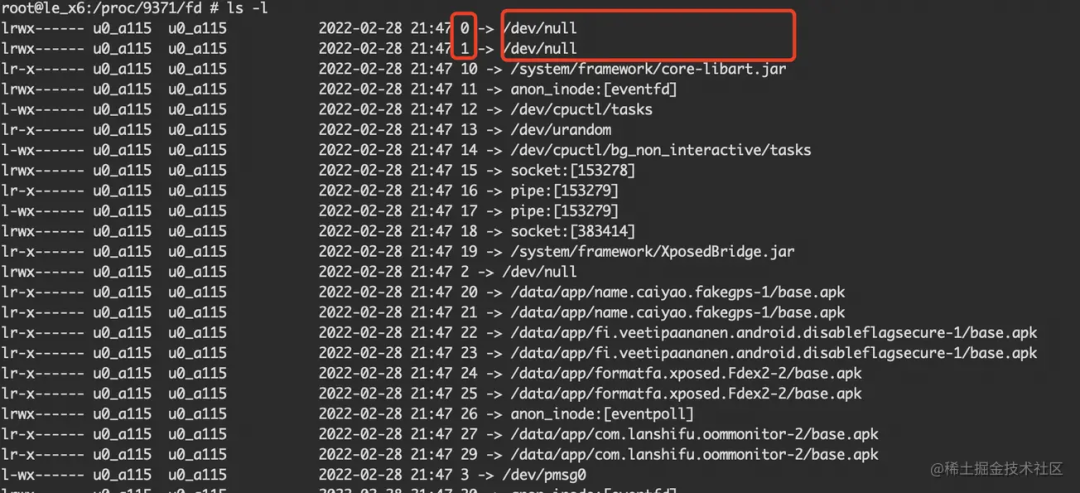
当 fd 的数目达到 Max open files 规定的数目,就会触发 Too many open files 的奔溃,这种奔溃在低端机上比较容易复现。
知道了文件描述符这玩意后,看看怎么优化。
| 文件描述符优化
对于打开文件数太多的问题,盲目优化其实无从下手,总体的方案是监控为主。
通过如下代码可以查看当前进程的 fd 信息:
private fun dumpFd() {
val fdNames = runCatching { File("/proc/self/fd").listFiles() }
.getOrElse {
return@getOrElse emptyArray()
}
?.map { file ->
runCatching { Os.readlink(file.path) }.getOrElse { "failed to read link ${file.path}" }
}
?: emptyList()
Log.d("TAG", "dumpFd: size=${fdNames.size},fdNames=$fdNames")
}| 文件描述符监控
监控策略: 当 fd 数大于 1000 个,或者 fd 连续递增超过 50 个,就触发 fd 收集,将 fd 对应的文件路径上报到后台。
这里模拟一个 bug,打开一个文件多次不关闭,通过 dumpFd,可以看到很多重复的文件名,进而大致定位到问题。
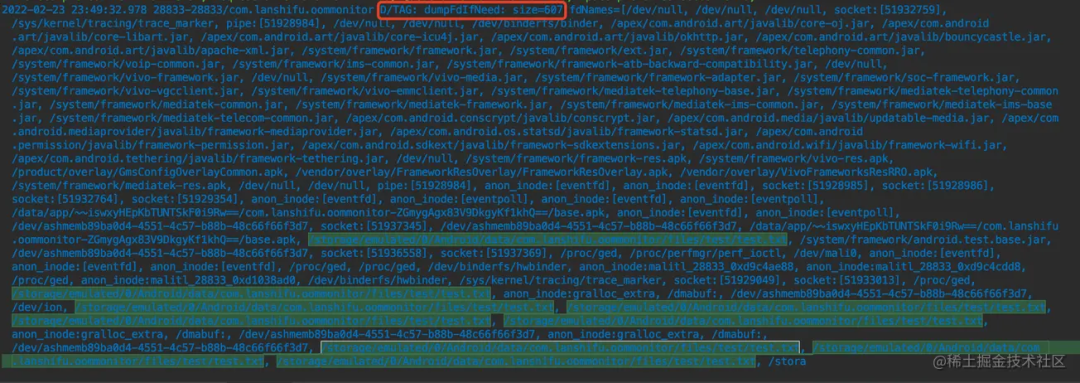
当怀疑某个文件有问题之后,我们还需要知道这个文件在哪创建,是谁创建的,这个就涉及到 IO 监控。
| IO 监控
①监控内容
监控完整的 IO 操作,包括:
open:获取文件名、fd、文件大小、堆栈、线程。
read/write:获取文件类型、读写次数、总大小,使用 buffer 大小、读写总耗时。
close:打开文件总耗时、最大连续读写时间。
②Java 监控方案
以 Android 6.0 源码为例,FileInputStream 的调用链如下:
java : FileInputStream -> IoBridge.open -> Libcore.os.open ->
BlockGuardOs.open -> Posix.openLibcore.java 是一个不错的 hook 点。
http://androidxref.com/6.0.1_r10/xref/libcore/luni/src/main/java/libcore/io/Libcore.java
package libcore.io;
public final class Libcore {
private Libcore() { }
public static Os os = new BlockGuardOs(new Posix());
}我们可以通过反射获取到这个 Os 变量,它是一个接口类型,里面定义了 open、read、write、close 方法,具体实现在 BlockGuardOs 里面。
http://androidxref.com/6.0.1_r10/xref/libcore/luni/src/main/java/libcore/io/BlockGuardOs.java
// 反射获得静态变量
Class<?> clibcore = Class.forName("libcore.io.Libcore");
Field fos = clibcore.getDeclaredField("os");通过动态代理的方式,在它所有 IO 方法前后加入插桩代码来统计 IO 信息。
// 动态代理对象
Proxy.newProxyInstance(cPosix.getClassLoader(), getAllInterfaces(cPosix), this);
beforeInvoke(method, args, throwable);
result = method.invoke(mPosixOs, args);
afterInvoke(method, args, result);此方案缺点如下:
- 性能差,IO 调用频繁,使用动态代理和 Java 的字符串操作,导致性能较差,无法达到线上使用标准。
- 无法监控 Native 代码,这个也是比较重要的。
- 兼容性差:需要根据 Android 版本做适配,特别是 Android P 的非公开 API 限制。
③Native 监控方案
int open(const char *pathname, int flags, mode_t mode);
ssize_t read(int fd, void *buf, size_t size);
ssize_t write(int fd, const void *buf, size_t size); write_cuk
int close(int fd);我们需要选择一些有调用上面几个方法的 library,例如选择 libjavacore.so、libopenjdkjvm.so、libopenjdkjvm.so,可以覆盖到所有的 Java 层的 I/O 调用。
不同版本的 Android 系统实现有所不同,在 Android 7.0 之后,我们还需要替换下面这三个方法。
open64
__read_chk
__write_chknative hook 框架目前使用比较广泛的是爱奇艺的 xhook,以及它的改进版,字节跳动的 bhook。
https://github.com/iqiyi/xHook/blob/master/README.zh-CN.md
https://github.com/bytedance/bhook/blob/main/doc/overview.zh-CN.md
具体的 native IO 监控代码,可以参考 Matrix-IOCanary,内部使用的是 xhook 框架。
https://github.com/Tencent/matrix/blob/master/matrix/matrix-android/matrix-io-canary/src/main/cpp/io_canary_jni.cc
关于 IO 涉及到的知识非常多,后面有时间可以单独整理一篇文章。接下来看看最后一种 OOM 类型。
内存不足
| 堆栈信息

这种是最常见的 OOM,Java 堆内存不足,512M 都不够玩,发生此问题的大部分设备都是 Android 7.0,高版本也有,不过相对较少。
| 重温 JVM 内存结构
JVM 在运行时,将内存划分为以下 5 个部分:
- 方法区:存放静态变量、常量、即时编译代码
- 程序计数器:线程私有,记录当前执行的代码行数,方便在 cpu 切换到其它线程再回来的时候能够不迷路
- Java 虚拟机栈:线程私有,一个 Java 方法开始和结束,对应一个栈帧的入栈和出栈,栈帧里面有局部变量表、操作数栈、返回地址、符号引用等信息
- 本地方法栈:线程私有,跟 Java 虚拟机栈的区别在于 这个是针对 native 方法
- 堆:绝大部分对象创建都在堆分配内存
内存不足导致的 OOM,一般都是由于 Java 堆内存不足,绝大部分对象都是在堆中分配内存,除此之外,大数组、以及 Android3.0-7.0 的 Bitmap 像素数据,都是存放在堆中。
Java 堆内存不足导致的 OOM 问题,线上难以复现,往往比较难定位到问题,绝大部分设备都是 8.0 以下的,主要也是由于 Android 3.0-7.0 Bitmap 像素内存是存放在堆中导致的。
基于这个结论,关于 Java 堆内存不足导致的 OOM 问题,优化方案主要是图片加载优化、内存泄漏监控。
| 图片加载优化
1、无侵入性自动压缩图片
针对图片资源,设计师往往会追求高清效果,忽略图片大小,一般的做法是拿到图后手动压缩一下,这种手动的操作完全看个人修养。
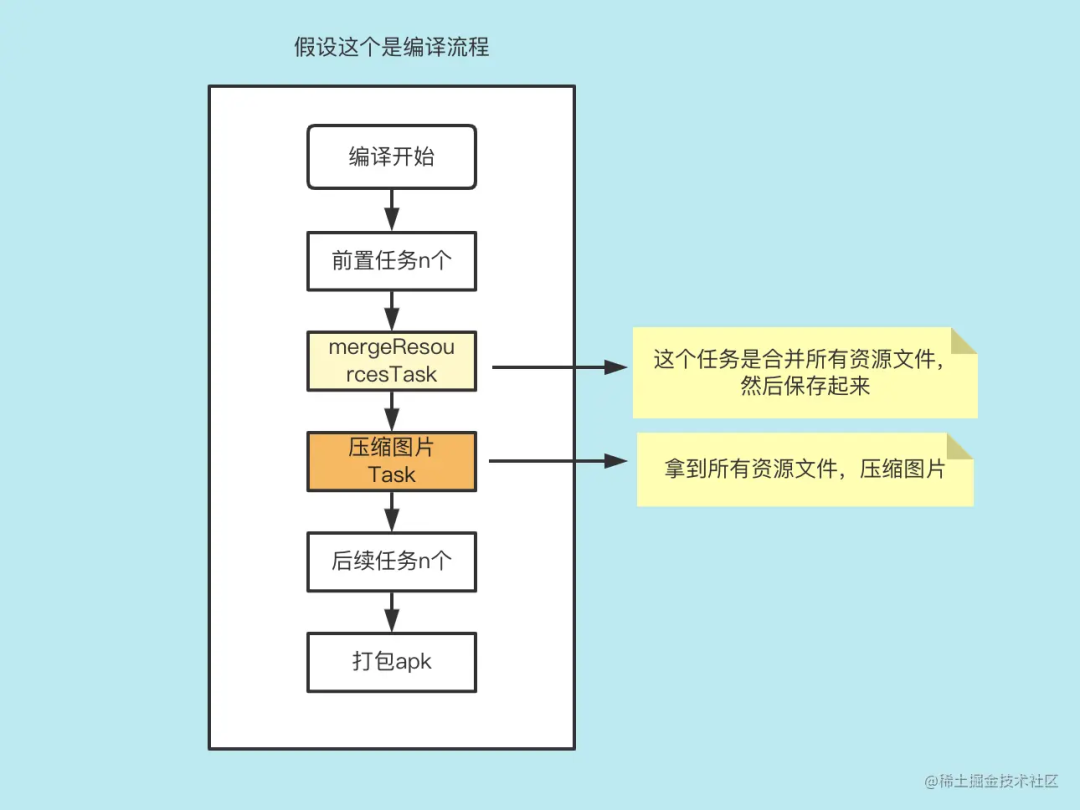
无侵入性自动压缩图片,主流的方案是利用 Gradle 的 Task 原理,在编译过程中,mergeResourcesTask 这个任务是将所有 aar、module 的资源进行合并,我们可以在 mergeResourcesTask 之后可以拿到所有资源文件。
具体做法:
在 mergeResourcesTask 这个任务后面,增加一个图片处理的 Task,拿到所有资源文件
拿到所有资源文件后,判断如果是图片文件,则通过压缩工具进行压缩,压缩后如果图片有变小,就将压缩过的图片替换掉原图
可以简单理解如下:
具体代码可以参考 McImage 这个库。
https://github.com/**allSohoSolo/McImage
| 大图监控
上文的自动压缩图片只是针对本地资源,而对于网络图片,如果加载的时候没有压缩,那么内存占用会比较大,这种情况就需要监控了。
①从图片框架侧监控
很多 App 内部可能使用了多个图片库,例如 Glide、Picasso、Fresco、ImageLoader、Coil,如果想监控某个图片框架, 那么我们需要熟读源码,找到 hook 点。
对于 Glide,可以通过 hook SingleRequest,它里面有个 requestListeners,我们可以注册一个自己的监听,图片加载完做一个大图检测。
其他图片框架,同理也是先找到 hook 点,然后进行类似的 hook 操作就可以,代码可以参考:dokit-BigImgClassTransformer。
https://github.com/didi/DoraemonKit/blob/master/Android/buildSrc/src/main/kotlin/com/didichuxing/doraemonkit/plugin/classtransformer/BigImgClassTransformer.kt
②从 ImageView 侧监控
上面是从图片加载框架侧监控大图,假如项目中使用到的图片加载框架太多,有些第三方 SDK 内部可能自己搞了图片加载。
这种情况下我们可以从 ImageView 控件侧做监控,监听 setImageDrawable 等方法,计算图片大小如果大于控件本身大小,debug 包可以弹窗提示需要修改。
方案如下:
- 自定义 ImageView,重写 setImageDrawable、setImageBitmap、setImageResource、setBackground、setBackgroundResource 这几个方法,在这些方法里面,检测 Drawable 大小
- 编译期,修改字节码,将所有 ImageView 的创建都替换成自定义的 ImageView
- 为了不影响主线程,可以使用 IdleHandler,在主线程空闲的时候再检测
最终是希望当检测到大图的时候,debug 环境能够弹窗提示开发进行修改,release 环境可以上报后台。
debug 如下效果:
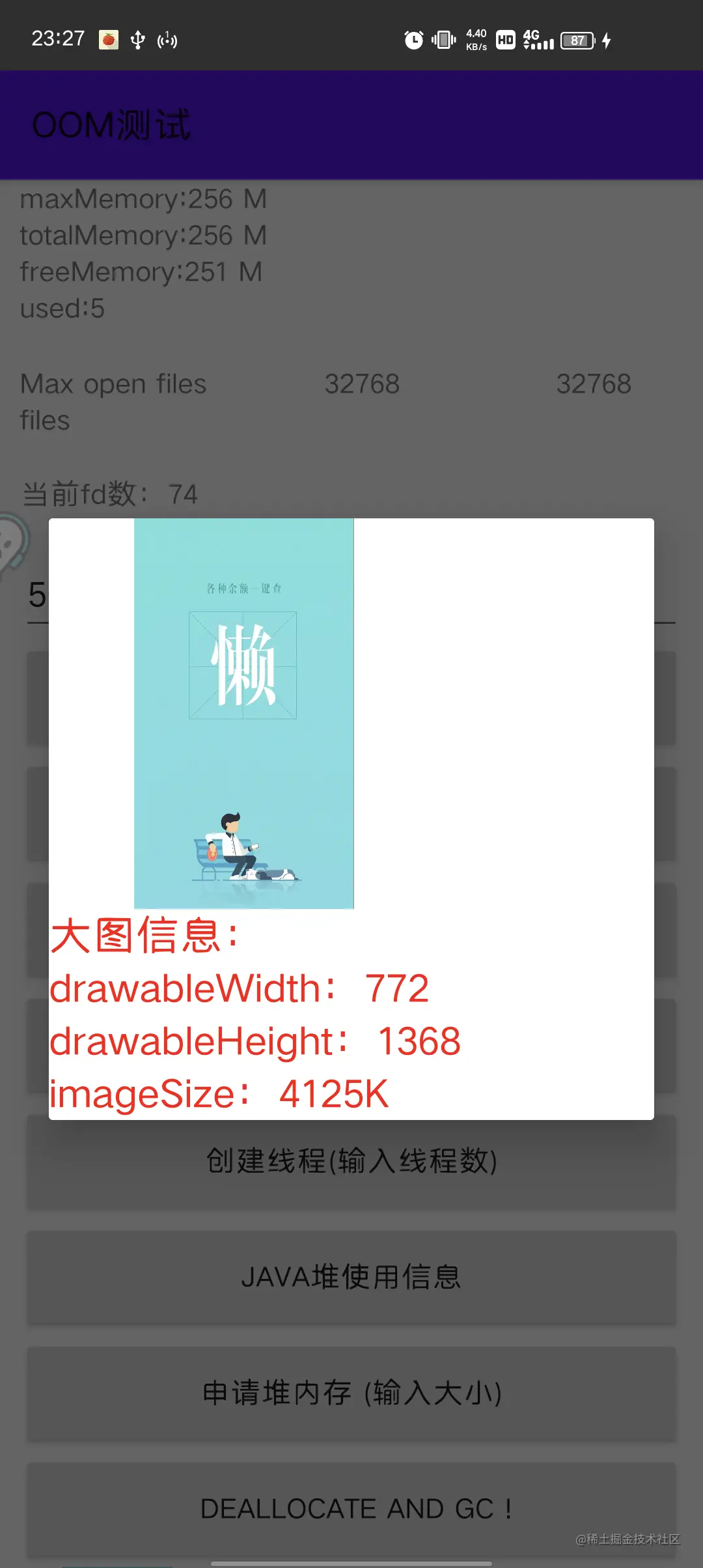
当然这种方案有个缺点:不能获取到图片 url。图片优化告一段落,接下来看看内存泄漏。
| 内存泄漏监控演进
①LeakCanary
关于内存泄漏,大家可能都知道 LeakCanary:
https://github.com/square/leakcanary/
只要添加一个依赖:
debugImplementation 'com.squareup.leakcanary:leakcanary-android:2.8.1'就能实现自动检测和分析内存泄漏,并发出一个通知显示内存泄漏详情信息。
LeakCanary 只能在 debug 环境使用,因为它是在当前进程 dump 内存快照,Debug.dumpHprofData(path); 会冻结当前进程一段时间,整个 APP 会卡死约 5~15s,低端机上可能要几十秒的时间。
②ResourceCanary
微信对 LeakCanary 做了一些改造,将检测和分析分离,客户端只负责检测和 dump 内存镜像文件,文件裁剪后上报到服务端进行分析。
具体可以看这篇文章 Matrix ResourceCanary -- Activity 泄漏及 Bitmap 冗余检测。
https://mp.weixin.qq.com/s/XL55txToSCJXM8ErwrUGMw
③KOOM
不管是 LeakCanary 还是 ResourceCanary,他们都只能在线下使用,而线上内存泄漏监控方案,目前 KOOM 的方案比较完善,下面我将基于 KOOM 分析线上内存泄漏监控方案的核心流程。
https://github.com/KwaiAppTeam/KOOM/blob/master/README.zh-CN.md
| 线上内存泄漏监控方案
基于 KOOM 源码分析:
①检测时机
间隔 5s 检测一次;触发内存镜像采集的条件。
当内存使用率达到 80% 以上:
//->OOMMonitorConfig
private val DEFAULT_HEAP_THRESHOLD by lazy {
val maxMem = SizeUnit.BYTE.toMB(Runtime.getRuntime().maxMemory())
when {
maxMem >= 512 - 10 -> 0.8f
maxMem >= 256 - 10 -> 0.85f
else -> 0.9f
}
}
两次检测时间内(例如 5s 内),内存使用率增加 5%。
②内存镜像采集
我们知道 LeakCanary 检测内存泄漏,不能用于线上,是因为它 dump 内存镜像是在当前进程进行操作,会冻结 App 一段时间。
所以,作为线上 OOM 监控,dump 内存镜像需要单独开一个进程。
整体的策略是:虚拟机 supend→fork 虚拟机进程→虚拟机 resume→dump 内存镜像的策略。
dump 内存镜像的源码如下:
//->ForkJvmHeapDumper
public boolean dump(String path) {
...
boolean dumpRes = false;
try {
//1、通过fork函数创建子进程,会返回两次,通过pid判断是父进程还是子进程
int pid = suspendAndFork();
MonitorLog.i(TAG, "suspendAndFork,pid="+pid);
if (pid == 0) {
//2、子进程返回,dump内存操作,dump内存完成,退出子进程
Debug.dumpHprofData(path);
exitProcess();
} else if (pid > 0) {
// 3、父进程返回,恢复虚拟机,将子进程的pid传过去,阻塞等待子进程结束
dumpRes = resumeAndWait(pid);
MonitorLog.i(TAG, "notify from pid " + pid);
}
}
return dumpRes;
}注释 1:父进程调用 native 方法挂起虚拟机,并且创建子进程;
注释 2:子进程创建成功,执行 Debug.dumpHprofData,执行完后退出子进程;
注释 3:得知子进程创建成功后,父进程恢复虚拟机,解除冻结,并且当前线程等待子进程结束。
注释 1 源码如下:
// ->native_bridge.cpp
pid_t HprofDump::SuspendAndFork() {
//1、暂停VM,不同Android版本兼容
if (android_api_ < __ANDROID_API_R__) {
suspend_vm_fnc_();
}
...
//2,fork子进程,通过返回值可以判断是主进程还是子进程
pid_t pid = fork();
if (pid == 0) {
// Set timeout for child process
alarm(60);
prctl(PR_SET_NAME, "forked-dump-process");
}
return pid;
}注释 3 源码如下:
//->hprof_dump.cpp
bool HprofDump::ResumeAndWait(pid_t pid) {
//1、恢复虚拟机,兼容不同Android版本
if (android_api_ < __ANDROID_API_R__) {
resume_vm_fnc_();
}
...
int status;
for (;;) {
//2、waitpid,等待子进程结束
if (waitpid(pid, &status, 0) != -1 || errno != EINTR) {
//进程异常退出
if (!WIFEXITED(status)) {
ALOGE("Child process %d exited with status %d, terminated by signal %d",
pid, WEXITSTATUS(status), WTERMSIG(status));
return false;
}
return true;
}
return false;
}
}这里主要是利用 Linux 的 waitpid 函数,主进程可以等待子进程 dump 结束,然后再返回执行内存镜像文件分析操作。
③内存镜像分析
前面一步已经通过 Debug.dumpHprofData(path) 拿到内存镜像文件,接下来就开启一个后台服务来处理。
//->HeapAnalysisService
override fun onHandleIntent(intent: Intent?) {
...
kotlin.runCatching {
//1、通过shark将hprof文件转换成HeapGraph对象
buildIndex(hprofFile)
}
...
//2、将设备信息封装成json
buildJson(intent)
kotlin.runCatching {
//3、过滤泄漏对象,有几个规制
filterLeakingObjects()
}
...
kotlin.runCatching {
// 4、gcRoot是否可达,判断内存泄漏
findPathsToGcRoot()
}
...
//5、泄漏信息填充到json中,然后结束了
fillJsonFile(jsonFile)
//通知主进程内存泄漏分析成功
resultReceiver?.send(AnalysisReceiver.RESULT_CODE_OK, null)
//这个服务是在单独进程,分析完就退出
System.exit(0);
}内存镜像分析的流程如下:
- 通过 shark 这个开源库将 hprof 文件转换成 HeapGraph 对象。
- 收集设备信息,封装成 json,现场信息很重要。
- filterLeakingObjects:过滤出泄漏的对象,有一些规制,例如已经 destroyed 和 finished 的 activity、fragment manager 为空的 fragment、已经 destroyed 的 window 等。
- findPathsToGcRoot:内存泄漏的对象,查找其到 GcRoot 的路径,通过这一步就可以揪出内存泄漏的原因。
- fillJsonFile:格式化输出内存泄漏信息。
| 小结
线上 Java 内存泄漏监控方案分析,这里小结一下:
- 挂起当前进程,然后通过 fork 创建子进程
- fork 会返回两次,一次是子进程,一次是父进程,通过返回的 pid 可以判断是子进程还是父进程
- 如果是父进程返回,则通过 resumeAndWait 恢复进程,然后当前线程阻塞等待子进程结束
- 如果子进程返回,通过 Debug.dumpHprofData(path) 读取内存镜像信息,这个会比较耗时,执行结束就退出子进程
- 子进程退出,父进程的 resumeAndWait 就会返回,这时候就可以开启一个服务,后台分析内存泄漏情况,这块跟 LeakCanary 的分析内存泄漏原理基本差不多
不画图了,结合源码看应该可以理解。
对于 Java 内存泄漏监控,线下我们可以使用 LeakCanary、线上可以使用 KOOM,而对于 native 内存泄漏应该如何监控呢?
方案如下:
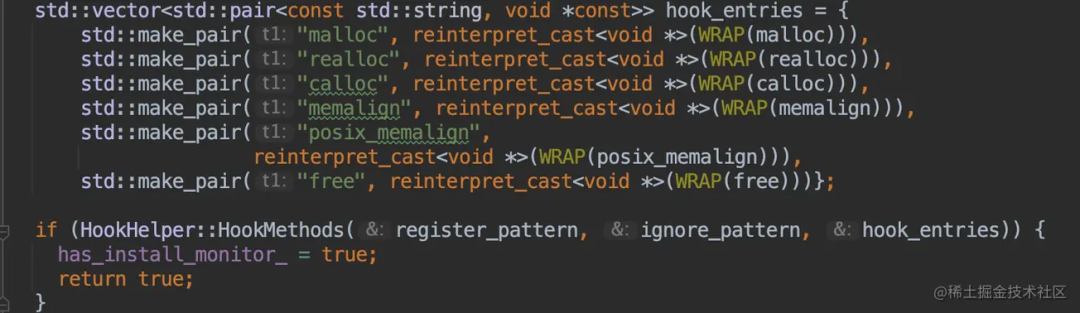
- 首先要了解 native 层。
- 申请内存的函数:malloc、realloc、calloc、memalign、posix_memalign。
- 释放内存的函数:free。
- hook 申请内存和释放内存的函数。
分配内存的时候,收集堆栈、内存大小、地址、线程等信息,存放到 map 中,在释放内存的时候从 map 中移除。
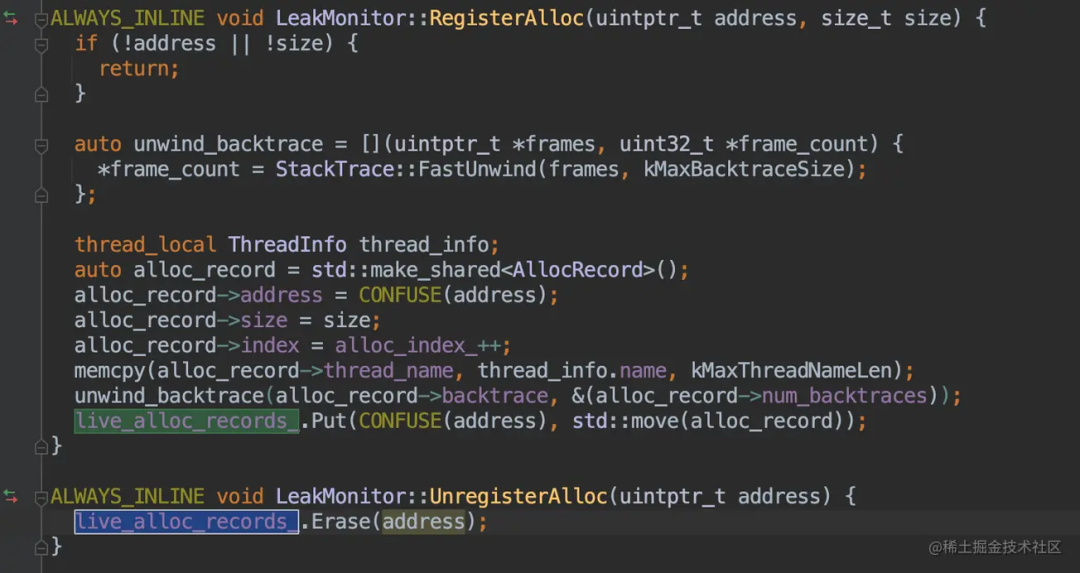
那怎么判断 native 内存泄漏呢?
周期性的使用 mark-and-sweep 分析整个进程 Native Heap,获取不可达的内存块信息「地址、大小」
获取到不可达的内存块的地址后,可以从我们的 Map 中获取其堆栈、内存大小、地址、线程等信息
具体实现可以参考:koom-native-leak。
https://github.com/KwaiAppTeam/KOOM/blob/master/koom-native-leak/README.zh-CN.md
总结
本文从线上 OOM 问题入手,介绍了 OOM 原理, 以及 OOM 优化方案和监控方案,基本上都是大厂开源出来的比较成熟的方案:
- 对于 pthread_create OOM 问题,介绍了无侵入性的 new Thread 优化、无侵入性的线程池优化、以及线程泄漏监控
- 对于文件描述符过多问题,介绍了原理以及文件描述符监控方案、IO 监控方案
- 对于 Java 内存不足导致的 OOM、介绍了无侵入性图片自动压缩方案、两种无侵入性的大图监控方案
- Java 内存泄漏监控的线下方案和线上方案、以及 native 内存泄漏监控方案。
大厂对外开源的技术非常多,但不一定最优,我们在学习过程中可以多加思考, 例如线程优化,booster 对于 new Thread 的优化只是设置了线程名,有助于分析问题,而经过我的猜想和验证,通过字节码插桩,将 new Thread 无侵入性替换成线程池调用,才是真正意义上的线程优化。
更多思考:
本篇主要介绍的是OOM的处理方法,也是目前比较全的方法,更多关于解决OOM实战的文章大家可以阅读以下内容:
原文链接:https://c1n.cn/5ug0H

