
最近笔者有点忙,这次OOM事故发生过去两周前,记得笔者那天正带着家人在外地玩,正中午跟友人吃饭的时候,钉钉连续告警爆表,接着就是钉钉电话(显示广东抬头)一看就知道BBQ了,又一次故障发生了,今天把那次故障复盘一下,做个总结,也给小伙伴分享一下 我是怎么从接到告警开始,怎么一步一步分析故障,然后定位到问题,最后完美解决,成功上线解决问题的。

上述告警内容,由于笔者所在服务是用CMS垃圾回收器,当其GC次数太频繁,达到公司监控平台设置的阈值时,就会通过钉钉通知告知开发者,发送到对应的控制台上。这个异常先从字面意义上来说倒也比较明显,如果老年代里的对象太多,无法提供空间容纳年轻代传递过来的对象的时候,就会触发FULL GC。
这里我们先简单分析一下,对象什么情况下会进入老年代,以及老年代又是在什么情况下会触发FULL GC?只有先知道了原理性东西,你才能带着思路去分析,真实线上场景属于对应哪种情况
首先科普一下对象什么情况下会进入老年代?
1)躲过15次GC之后进入老年代
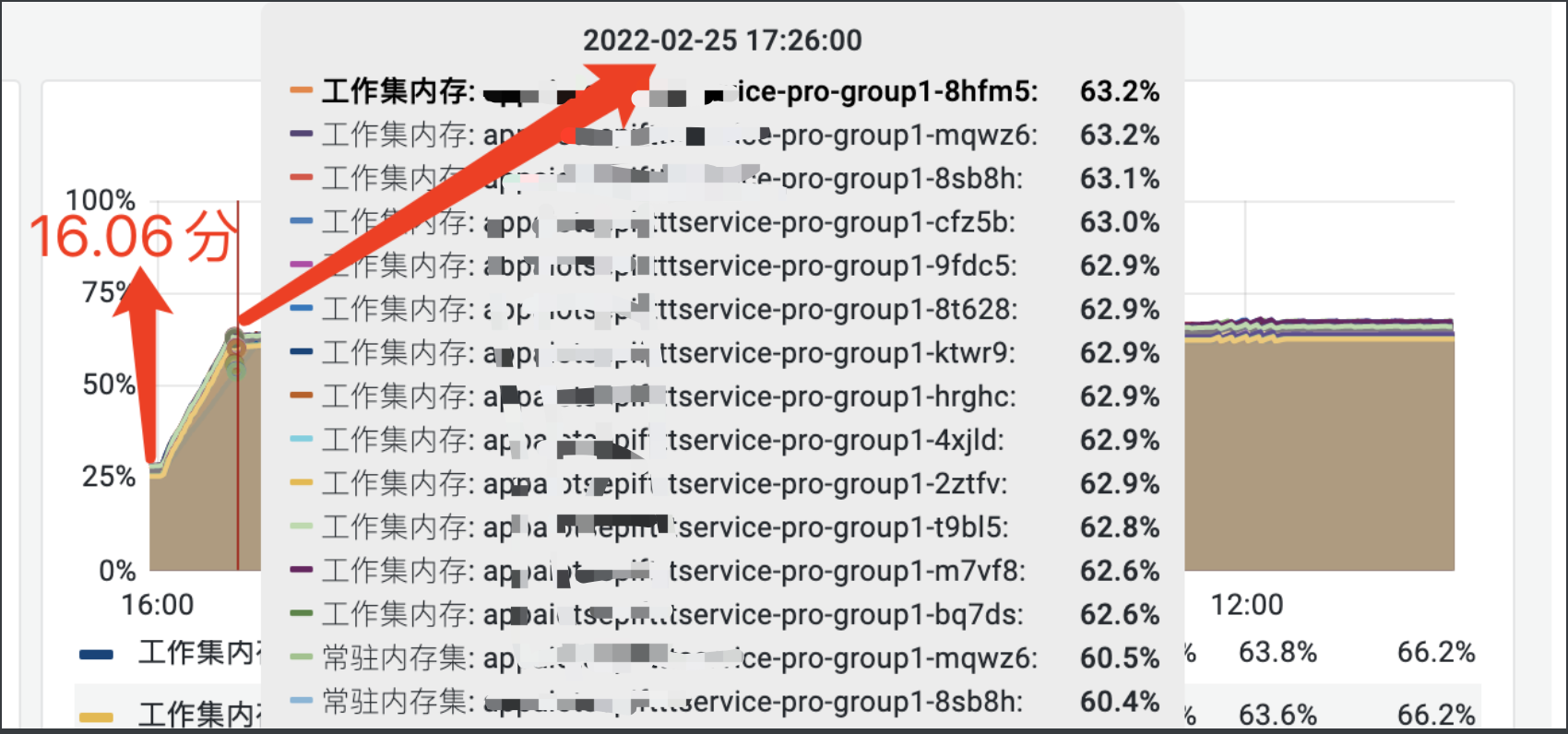

线上由于比较麻烦dump线程。而且现场已经过去了,所以我还是自己写了一段压测代码(类似Jmeter效果),来压测相应的总入口,看看具体是哪个对象占了大内存
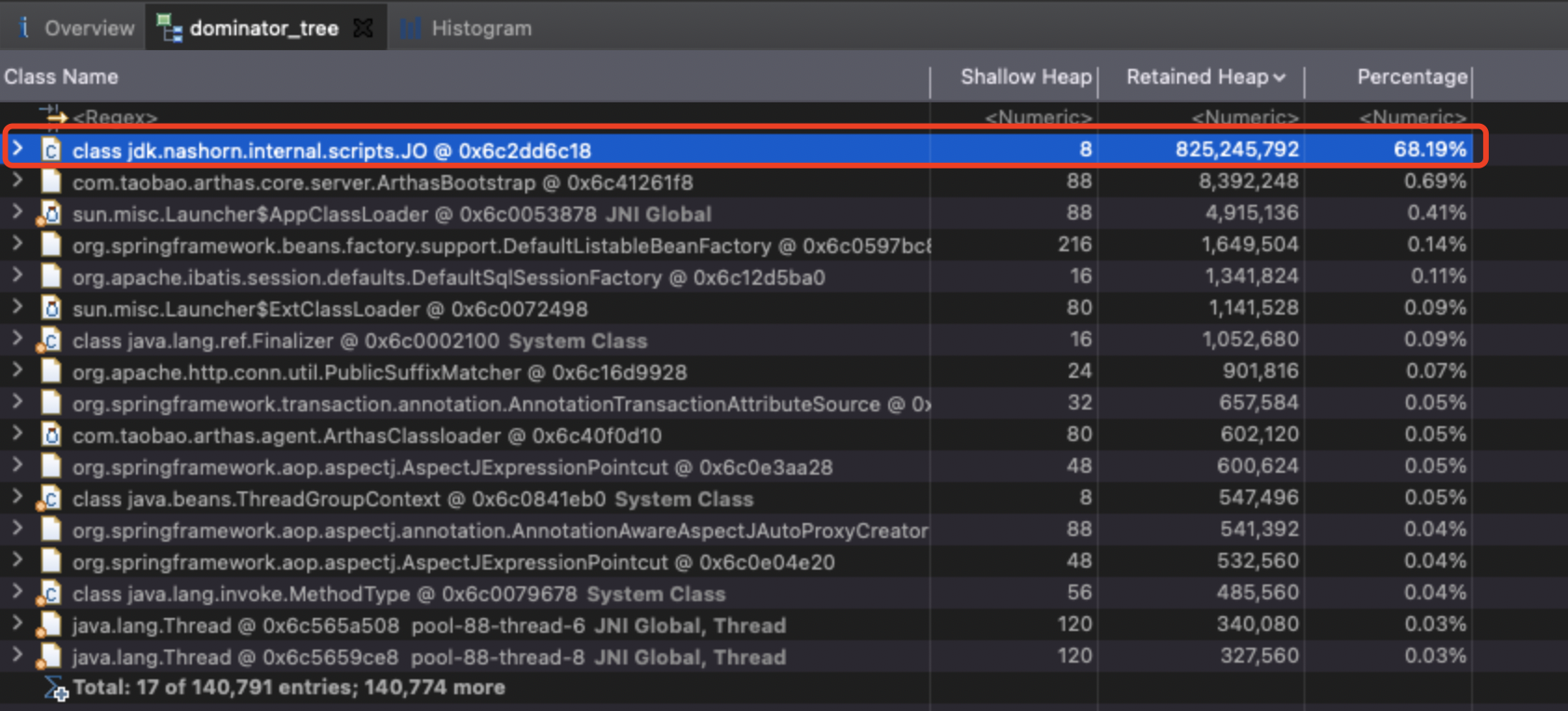
很明显是有一个nashorn相关对象占据了比较大的占比。那这个对象其实对应笔者的程序是
ScriptEngineManager manager = new ScriptEngineManager();
ScriptEngine engine = manager.getEngineByName("nashorn");
Compilable compEngine = (Compilable) engine;
try {
CompiledScript compile = compEngine.compile(script);
}catch(Exception e){
}
简单来说,Nashorn的编译入口可以从 Context.compileScript() 开始看:[ JavaScript源码 ] -> ( 语法分析器 Parser ) -> [ 抽象语法树(AST) ir ] -> ( 编译优化 Compiler ) -> [ 优化后的AST + Java Class文件(包含Java字节码) ] -> JVM加载和执行生成的字节码 -> [ 运行结果 ]
此过程是十分耗时的,每次执行eval 去运行js ,都需要编译成字节码、然后加载执行。同时会将编译过的字节码缓存起来,以便后续使用,因此加载的类会长时间存活,占用很大的内存空间。
所以笔者尝试将CompiledScript这一对象第一次编译完后,本地缓存起来用
private static Map<Long, CompiledScript> scriptMap = new ConcurrentHashMap<>();
缓存起来,下一次如果已经存在,就直接拿来用。
重新压测后效果还是明显的
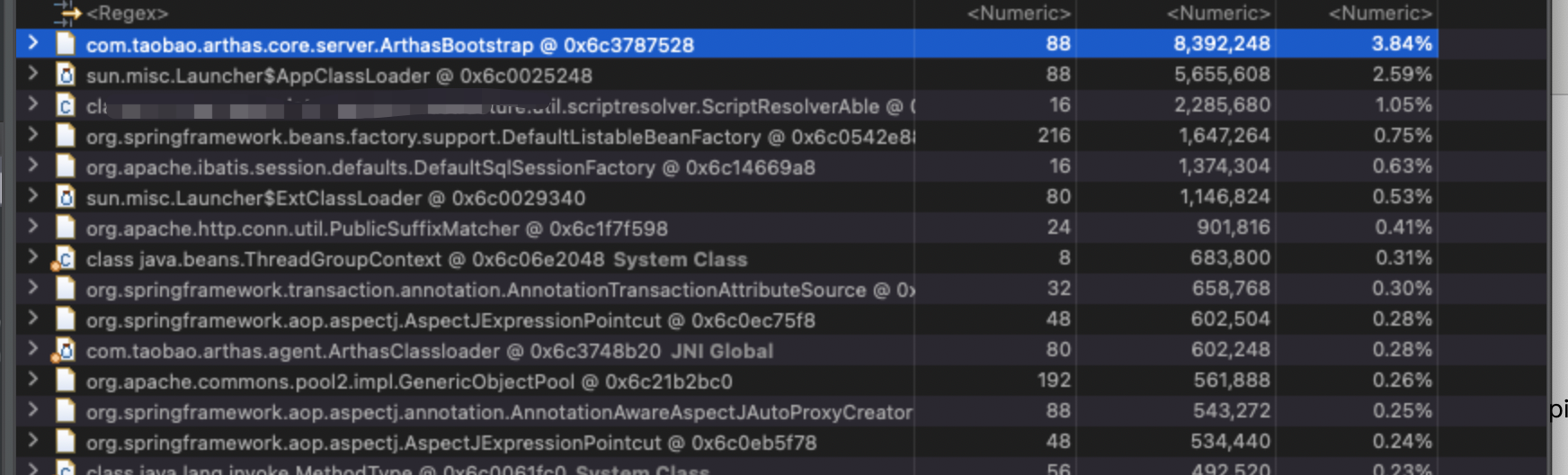
总结作者:星巴克男孩
线上场景 特别对于一些新的框架或技术 如果你的流量很大,笔者那时参与了这个项目,工期特别短,功能又特别多,想着先上线,下一步再做压测,想不到等不到下一步问题就暴露出来了😄


