
58同城关于ZGC的应用实践转载
导语
58同城大数据团队,鉴于目前线上大数据集群各个组件GC方面的问题,考虑逐步在适合的大数据组件上应用高版本JDK上的ZGC,目前已经在HBase集群上成功落地,在某些场景上有比较明显的效果。58同城HBase集群应用的JDK为腾讯公司开源的Tencent Kona JDK11。未来会在逐步应用ZGC的过程中,享受ZGC带来的好处。
背景
为了满足不同的业务需求,Java 的 GC 算法也在不停迭代,对于特定的应用,选择其最适合的 GC 算法,才能更高效的帮助业务实现其业务目标。很多低延迟高可用Java服务的系统可用性经常受GC停顿的困扰。GC停顿指垃圾回收期间STW(Stop The World),当STW时,所有应用线程停止活动,等待GC停顿结束。比如HBase方面,如果regionserver进程的GC停顿时间过长,会导致大量请求延迟,对客户端影响较大。对于这类延迟敏感的应用来说,GC 停顿已经成为阻碍 Java 广泛应用的一大顽疾,需要更适合的 GC 算法以满足这些业务的需求。
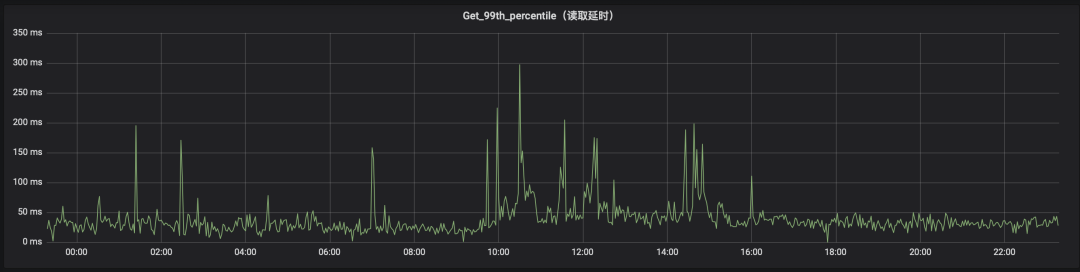
目前我们线上HBase集群应用的都是CMS作为java服务进程的垃圾回收器,在不同的应用场景下经过了多次调优之后,基本满足于一般业务场景下对延迟等方面性能的要求。但是随着业务的发展,会有某些高敏感的场景,请求延迟要求较高一些,此时集群性能就会捉襟见肘。通过线上集群监控系统查看某一台RS节点的GET请求延迟P99,发现毛刺比较多,分析对应时间内(大约24个小时)的GC信息,发现GC平均暂停时间为57.4ms(这些GC Pause中99%以上都是Allocation Failure原因产生的YongGC导致的,这里结合具体的场景,为了避免业务高并发请求的时间节点GC频率过高,配置了新生代大小为8G,大约占整个堆26.7%),GC频率整体上看比较正常(平均63.35s会发生一次GC Pause)。但是发现某些时间点gc频率会高一些,比如会达到平均4.5s发生一次GC Pause,结合平均暂停时间看对延迟敏感的业务影响较大。之前也考虑过使用G1,但是经过各种原因没有进行应用,比如G1本身存在一些问题。为了降低GC停顿对系统可用性的影响,我们考虑调研、测试和应用ZGC。
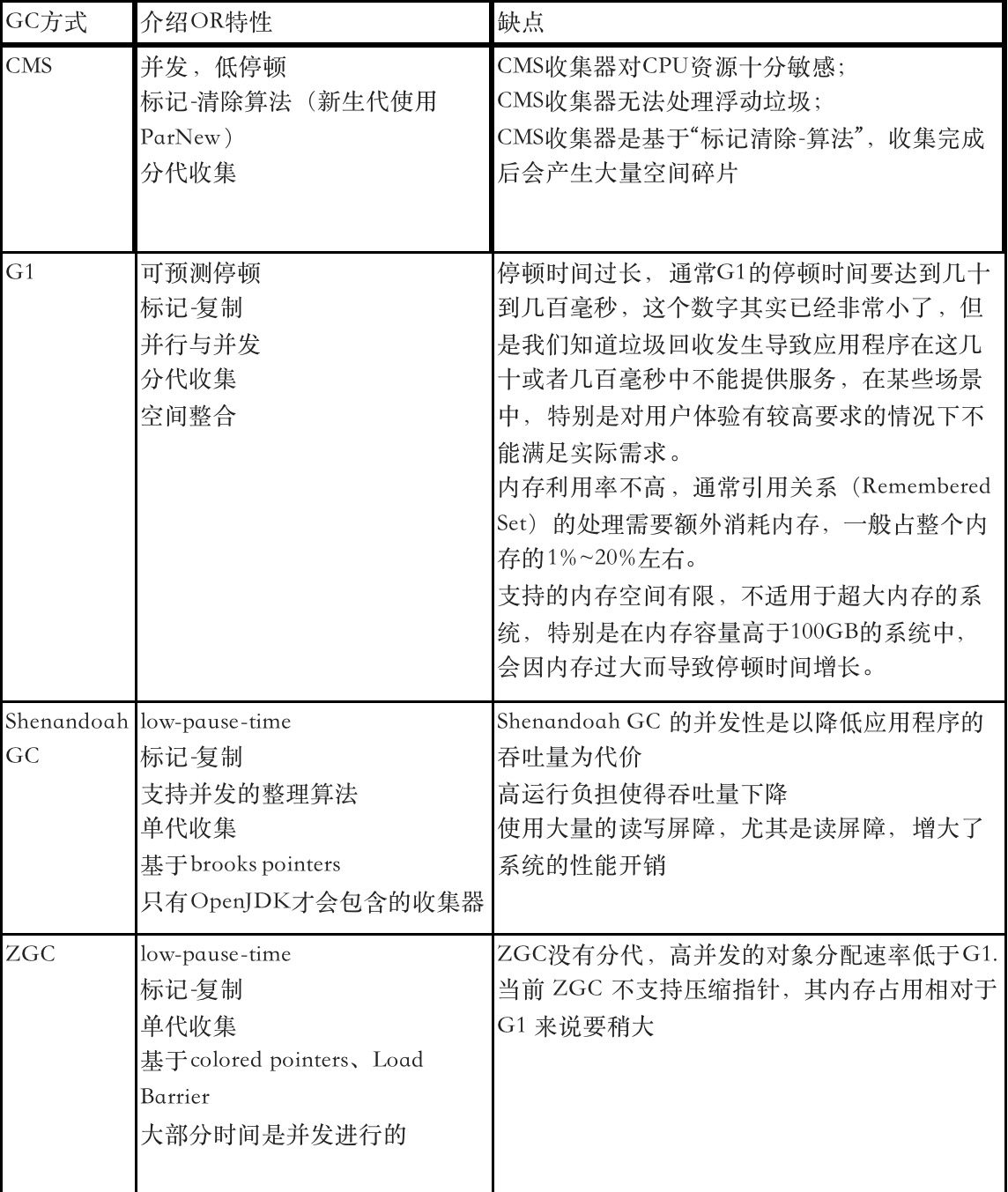
常见GC回收器介绍
在介绍ZGC之前,先简单说下CMS和G1等。CMS是基于标记-清除算法实现的(新生代为复制算法),G1从整体来看是基于“标记-整理”算法实现的,从局部(两个Region)上来看是基于“复制”算法实现的。像复制、标记-清除、标记-整理算法,也可以称为Tracing GC。所有的Tracing GC均需要以下三个步骤:
1、找出所有的 GC Roots 集合,这是 Tracing GC 算法的起点,GC Roots 主要为运行时的关键数据结构中存放的指向堆对象的指针,如线程栈上的堆对象指针等。
2、标记过程:从 GC Roots 开始遍历整个对象图,找出所有存活的对象。而剩余未被标记的对象则为死对象。
3、清理过程:将死掉的对象清理掉,释放其占用的内存。当然清理时可以直接释放对象内存,也可以将所有的活对象移动到一块连续的区域里,并将原来的内存空间释放。
上面三个步骤均需要一致的信息,为了保证一致性,需要采取同步措施,而最简单的同步措施就是暂停所有的 Java 线程,即 Stop-The-World(STW),在 STW 期间,GC 线程就可以安全的访问各种运行时数据、对象图、更新对象指针等。
不同的 GC 算法实现,其 STW 阶段需要完成的任务大相径庭,造成不同 GC 算法 STW 时长的不同。每种GC都有一定的实现目标和应用场景,比如CMS 和 G1 致力于以较小的吞吐率损失换取较小的停顿和较高的响应;ZGC 和 ShenandoahGC 则关注极致停顿,尽一切可能减少 STW 的工作量,从而实现 ms 级别的停顿时间。我们看下不同的GC方式的简单对比介绍、特性、缺点,如下列表所示:
遇到的问题
在XX公司负责HDFS集群维护工作时,线上HDFS集群Namenode进程(大内存)经过了应用CMS、G1和尝试应用Shenandoah GC的过程,下面简单说下应用CMS、G1和Shenandoah GC遇到过的一些问题(只是对遇到的问题大概地整理)。
1. 应用CMS期间,出现了System.GC()导致的Full GC问题:早期应用CMS GC运行一段时间,期间不断调优gc配置,但是也发现了一些问题,比如会出现System.gc()导致的full gc问题(具体原因当时没有完全确定),可以通过XX:+DisableExplicitGC参数直接禁用这类GC(亦可以通过-XX:+ExplicitGCInvokesConcurrent参数减缓这类GC),后面在测试环境测试对比CMS和G1之后,考虑在线上环境直接应用G1。
2. 应用G1期间,出现了长时间GC的问题: 应用G1在调优之后在很长的一段时间之内,运行还算稳定,但是随着常驻内存逐渐变大等因素出现了长时间GC的问题,没有达到G1的停顿可控的设计目标,问题原因是Scan RSet时间过高,长时间的GC几乎所有的时间消耗都在Scan Rset上,线上环境经过不断调高G1RSetRegionEntries解决了Scan Rset时间过长问题,但是这种解决方案会导致进程堆外内存过高,所以是以提高内存占用为代价来保证GC稳定。
3. 尝试应用Shenandoah GC: 应用G1出现长时间暂停的问题后,考虑使用新的GC方式,在测试环境测试Shenandoah GC性能,并和G1进行对比后,发现Shenandoah GC的暂停时间基本上能达到官网上描述的低停顿的目标, 尝试在生产环境上应用,应用后发现每天流量高峰时,大量rpc请求延迟。在测试环境测试批量创建对象,发现应用Shenandoah GC比应用G1慢一些,具体细节原因没有继续跟进,直接在生产环境更换回G1方式。
ZGC介绍与实现原理
ZGC(The Z Garbage Collector)是JDK 11中推出的一款低延迟垃圾回收器,它的设计目标包括:
- 停顿时间不超过10ms;
- 停顿时间不会随着堆的大小,或者活跃对象的大小而增加;
- 支持8MB~4TB级别的堆(未来支持16TB)。
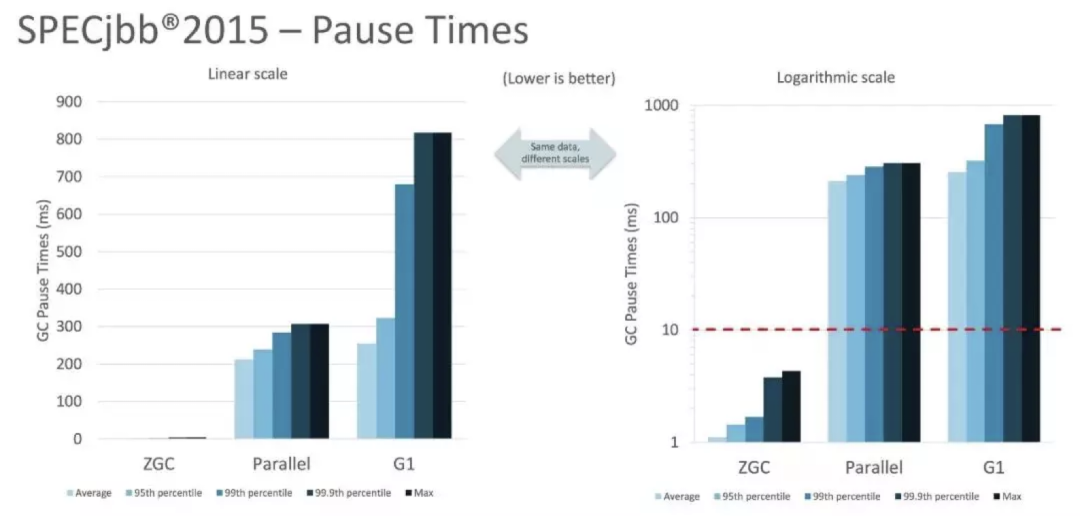
由设计目标可知,ZGC 主要是为现在及未来大堆的管理问题服务,致力于以最小的性能损失换取最大的停顿优势。从 Oracle 发布的测试数据来看,SPECjbb2015基准测试,使用128G堆,暂停时间ZGC远低于Parallel GC 和 G1GC,如下图所示。
与CMS中的ParNew和G1类似,ZGC也采用标记-复制算法,不过ZGC对该算法做了重大改进:ZGC在标记、转移和重定位阶段几乎都是并发的,这是ZGC实现停顿时间小于10ms目标的最关键原因。所以,ZGC 几乎在所有地方并发执行的,停顿时间几乎就耗费在初始标记上,这部分的时间是非常少的。ZGC的执行过程可以细分为6个阶段,如下图所示:
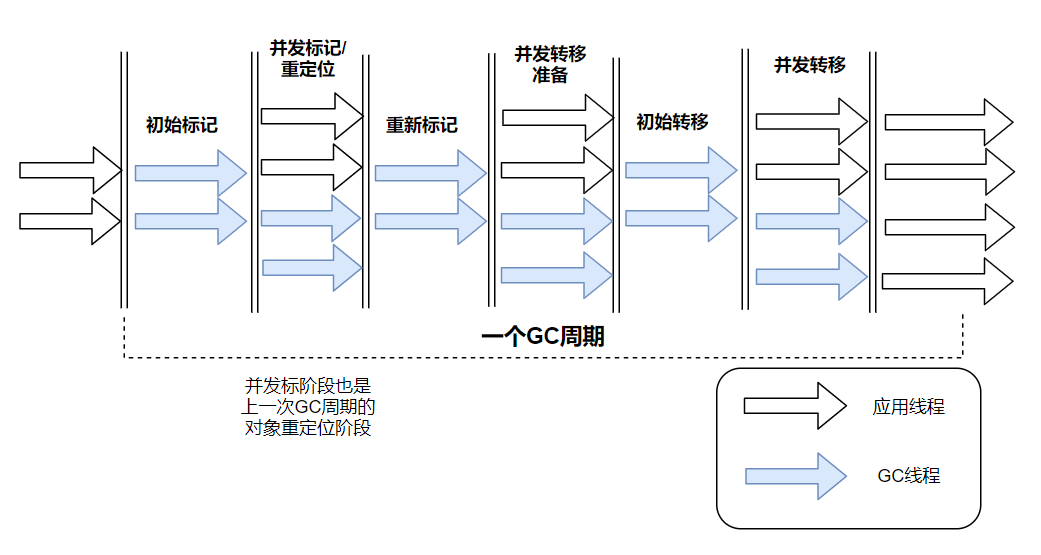
- 第一个阶段是初始标记,标记gc roots直接引用的对象。
- 第二个阶段是并发标记/重定位:与G1一样,并发标记是遍历对象图可达性分析的阶段,标记存活对象。同时上一轮 GC 的指针更新(Remap)放到当前阶段执行,从而减少对对象图的遍历。
- 第三个阶段是重新标记:重新标记那些在并发标记阶段发生变化的对象。
- 第四个阶段是并发转移准备:这个阶段需要根据特定的查询条件统计得出本次收集过程要清理哪些Region,将这些Region组成重分配集(Relocation Set)。ZGC每次回收都会扫描所有的Region,用范围更大的扫描成本换取省去G1中记忆集的维护成本。
- 第五个阶段是初始转移:迁移Root中的对象,在Forwarding Tables中记录新老地址的映射,不会停顿太长时间。
- 第六个阶段是并发转移:并发的搬移对象,在Forwarding Tables中记录新老地址的映射。
如上所示(其中红色标记的阶段是需要STW的阶段),ZGC只有三个STW阶段:初始标记,重新标记,初始转移。其中,初始标记和初始转移分别都只需要扫描所有GC Roots,其处理时间和GC Roots的数量成正比,一般情况耗时非常短;再标记阶段STW时间很短,最多1ms,超过1ms则再次进入并发标记阶段。即,ZGC几乎所有暂停都只依赖于GC Roots集合大小,停顿时间不会随着堆的大小或者活跃对象的大小而增加。与ZGC对比,G1的转移阶段完全STW的,且停顿时间随存活对象的大小增加而增加。
一些实现上的细节点说明:
1. 与G1不同的是,ZGC的标记是在指针上而不是在对象上进行的,标记阶段会更新着色指针中的 Marked0、Marked1标志位。记录在指针的好处就是对象回收之后,这块内存就可以立即使用。存在对象上的时候就不能马上使用,因为它上面还存放着一些垃圾回收的信息,需要清理完成之后才能使用。
2. 重映射(Remap),把所有已迁移活跃对象的引用重新指向新的正确地址。实现上,由于想要将所有引用都修正过来需要跟Mark阶段一样遍历整个对象图,所以把Remap放到下一次的GC的并发标记阶段中执行(上边已经做了简单说明)。
3. 重分配(即阶段五和阶段六)是 ZGC执行过程中的核心阶段,这个过程要把重分配集中的存活对象复制到新的 Region上,并为重分配集中的每个 Region维护了一个转发表(Forward Table),记录从旧对象到新对象的转换关系。ZGC收集器能仅从引用上就明确得知一个对象是否处于重分配集中,如果用户线程此时并发访问了位于重分配集中的对象,这次访问将会被预置的内存屏障所截获,然后立即根据 Region上的转发表记录将访问转到新复制的对象上,并同时修正更新该引用的值,使其直接指向新对象,ZGC将这种行为称为指针的“自愈”(Self-Healing)能力。
ZGC特征总结如下(细节不做过多说明):
- 所有阶段几乎都是并发执行的
- 并发执行的保证机制,就是Colored Pointer(着色指针) 和 Load Barrier(读屏障)
- 像G1一样划分Region,但更加灵活
- 和G1一样会做Compacting-压缩
- 没有G1占内存的Remember Set,没有Write Barrier的开销
- 支持Numa架构
- 并行
- 单代
上面介绍了ZGC的回收流程以及特征,下面说下ZGC的关键技术。
ZGC关键技术
与传统的标记对象算法相比,ZGC通过Colored Pointers(着色指针)在指针上做标记,在访问指针时加入Load Barrier(读屏障),实现了并发转移。比如当对象正在被GC移动,但对象地址未及时更新,那么应用线程可能访问到旧地址而出错。ZGC在应用线程访问对象时增加“读屏障”,通过着色指针判定对象是否被移动过。如果发现对象被移动了,读屏障就会先把指针更新到新地址再返回(如果还在迁移中,业务线程会协助GC线程迁移)。因此,只有单个对象读取时有概率被减速,而不存在为了保持应用与GC一致而粗暴整体的Stop The World。
Colored Pointers(着色指针)
着色指针是一种将信息存储在指针中的技术。
在64位系统中,ZGC利用了对象引用中4bit进行着色标记(低42位:对象的实际地址),结构如下:
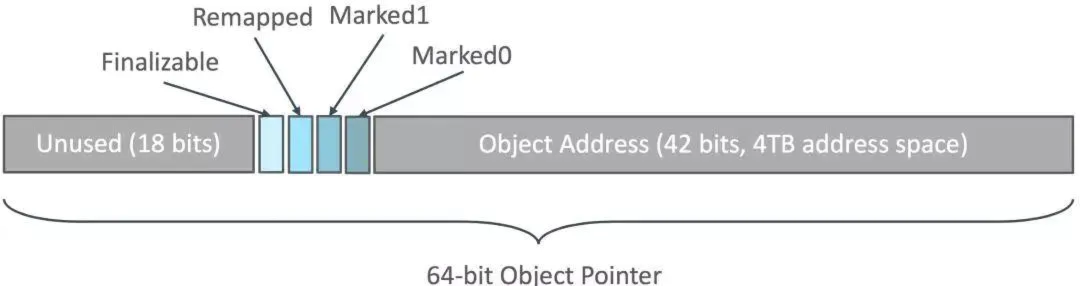
Colored Pointers(着色指针)用以下几个bits表示:
- Marked0/marked1: 判断对象是否已标记,GC周期交替时更换标记位,使上次GC周期标记的状态失效,所有引用都变为未标记
- Remapped: 判断指针是否已指向新的地址,不再通过转移表Forwarding Tables映射
- Finalizable: 判断对象是否只能被Finalizer访问,即是否实现了finalize()方法
Colored Pointers(着色指针)001、100、010在三种状态循环交替
- 001:Marked0作为标记位,标记活跃对象
- 100:Relocation Set中对象迁移完成后记为100,表示迁移完成
- 010:下一个GC周期,切换Marked1作为标记位,把标记为100(上个GC周期迁移的对象)、001(上个周期标记的活跃对象)更新为010
注意事项:由于ZGC利用64位的对象指针,因此,ZGC无法支持32位的操作系统,同样也无法支持压缩指针(CompressedOops)
Load Barrier(读屏障)
读屏障是JVM向应用代码插入一小段代码的技术。当应用线程从堆中读取对象引用时,就会执行这段代码。需要注意的是,仅“从堆中读取对象引用”才会触发这段代码。
读屏障示例:
String n = person.name; // Loading an object reference from heap
// 从堆中加载对象引用,需要先加一个Load Barrier,判断当前指针是否Bad Color,即对象是否在GC时被移动了,如果移动了,修正指针
<load barrier needed here>
String p = n; // No barrier, not a load from heap
n.isEmpty(); // No barrier, not a load from heap
int age = person.age; // No barrier, not an object reference
ZGC中读屏障的代码作用:在对象标记和转移过程中,用于确定对象的引用地址是否满足条件,并作出相应动作。
G1只有写屏障没有读屏障,复制移动的过程需要stop the world,而ZGC通过读屏障、remark标记和重定向表来并发拷贝非GC Roots对象,减少了STW,所以ZGC的停顿比G1的停顿少很多。
优缺点总结:
ZGC主要优点如下(相比G1):
- 更低延迟:GC停顿时间更短,不超过 10ms
- 更大内存:堆内存支持范围更大(8MB-16TB)
ZGC做为一个较新的垃圾回收器,有比较明显的优点,当然也存在一些缺点或者问题:
- 分代对提高吞吐量意义重大,分代可以提高对象内存分配和垃圾回收的效率,ZGC没有分代,高并发的对象分配速率低于G1.
- 当前 ZGC 不支持压缩指针,其内存占用相对于 G1 来说要稍大。
ZGC应用场景:
前边已经提到过了,ZGC适用于大内存低延迟服务的内存管理和回收。ZGC最大的优势就是无论多大的堆内存场景下都能够保证停顿时间在10ms以下,但是这种超低停顿的实现是以性能损失和内存消耗为代价的。ZGC没有分代,一些场景会影响吞吐量,当前 ZGC 不支持压缩指针,其内存开销会比G1大一些。了解每种gc方式的优劣,结合场景的特点选择适合的GC方式,才能让应用达到比较好的服务性能。推荐以下两种应用可以使用ZGC来提升业务体验。
- 超大堆的应用,超大堆(百G以上)下,使用CMS或者G1如果发生Full GC,停顿时间会很长,可能会造成业务的中断,这种场景使用ZGC可以有效的避免长时间的暂停,比如大数据方面的hdfs大集群的namnode进程。
- 延迟要求高的应用,一些请求延迟要求较高的应用,比如大数据方面,业务读写延迟P99要求较高的HBase组件,可以考虑采用ZGC来降低停顿时间。
ZGC调优介绍
和其他垃圾收集器一样,ZGC也需要根据服务的具体特点进行调优,调优目的是提高服务的质量(可用性和性能方面), 在内存使用和GC频率之间找到平衡,不能过度调优,系统CPU使用率不宜过高,避免产生风险问题,影响服务。
调优的量化指标:
请求延迟
系统吞吐率
下面分别从降低请求延迟和提高系统吞吐量两个方面进行调优举例说明:
- 请求延迟方面
出现请求延迟增加,一般是服务进程运行一段时间之后,或者是请求流量增加幅度较大。
请求延迟方面调优主要有以下几种情况:
A. 单次GC STW时间较长,大大超过了ZGC的设计目标的10ms
这种情况分析STW的三个阶段的时间消耗相关信息,根据具体情况进行调优。
比如:发现Pause Mark Start时间较长,可以查看GC统计信息中GC ROOT相关的信息,Pause Roots ClassLoaderDataGraph耗时、Pause Roots CodeCache耗时等等,根据具体的情况进行优化。
B. 发生了一些内存分配阻塞(Allocation Stall)
内存分配阻塞:当内存不足时线程会阻塞等待GC完成,关键字是"Allocation Stall"。一般是自适应算法计算的GC触发间隔较长,导致GC触发不及时,引起了内存分配阻塞,导致停顿,这种情况需要确认GC的执行频率:
a. 如果GC执行频率很高,说明应用进程的内存资源确实有一些不足,如果资源允许情况下可以调整配置增加堆的大小。
b. 如果GC执行频率较低,可以具体分为以下几种情况:
b1. GC触发机制和出发条件阈值导致GC触发较晚,调整触发机制,调整触发条件阈值,尽早地执行GC。
一般自适应算法计算的GC触发间隔较长,导致GC触发不及时,引起了内存分配阻塞,导致停顿。调整的方法主要有:
1)可以选择开启”基于固定时间间隔“的GC触发机制:-XX:ZCollectionInterval。比如调整为5秒,甚至更短。
2)增大修正系数-XX:ZAllocationSpikeTolerance,更早触发GC。ZGC采用正态分布模型预测内存分配速率,模型修正系数ZAllocationSpikeTolerance默认值为2,值越大,越早的触发GC,Zeus中所有集群设置的是5。
b2. GC触发及时,但是GC并发阶段执行时间过长,比如Concurrent Mark时间过长,导致GC执行频率低。
调整方法:增大-XX:ConcGCThreads,加快并发标记和回收速度。ConcGCThreads默认值是核数的1/8,8核机器,默认值是1。该参数影响系统吞吐,一般情况下如果GC间隔时间大于GC周期,不建议调整该参数,具体要结合业务场景的特点去调整此参数,比如一些流量高峰时产生了内存分配阻塞问题,GC间隔时间较短,但是其他时间段GC间隔时间很长的情况下,为了提高GC效率,建议也要调高此参数,提高GC效率,避免出现内存分配阻塞的问题。
2. 吞吐率方面
一般ZGC频率过高或者参数设置不合理会对应用进程吞吐率方面影响较大。
a. 控制GC执行频率, 如果GC执行频率过高,会导致多占用CPU资源;
调整方法:结合业务进程运行情况,可以适当调整触发机制,调整触发阈值,可以使GC触发晚一点, 调整的力度需要结合请求延迟方面综合考虑。
b. 并发阶段占用CPU资源相关的配置-XX:ConcGCThreads,结合业务情况合理配置。
调整方法:合理适当的配置-XX:ConcGCThreads。
综上,ZGC调优需要结合多个方面进行综合考虑,明确调优目的,统计分析GC信息,按照一些调优策略逐步地进行优化,线上环境不宜单次调整过大,避免带来一些其他影响,调整前需要综合多个方面评估影响。
ZGC应用
ZGC是JDK11版本推出的垃圾回收器,所以在JDK11 以及之后的版本的jdk下才能应用ZGC,目前一般使用的JDK8版本较多一些,所以应用ZGC涉及到更换JDK,有一定的升级成本,需要检查和升级项目的相关低版本依赖,比如jetty、jruby等,还需要解决一些其他相关的报错问题等等。
选择JDK版本
经过对比,我们选择了腾讯开源的Tencent Kona JDK11,此jdk主要的优化项目有有向量计算(Vector API)、开箱即用的ZGC、超大堆和内存成本优化策略。
编译&运行测试
我们使用的HBase版本是基于社区1.4.11基础上开发的版本,不支持JDK11及以上版本环境下的编译和运行,所以需要解决一些问题。主要遇到了如下的一些问题:
A. 依赖的组件包不支持JDK11,如Jetty、Jruby等。需要升级对应的组件到高版本;
B. 个别类找不到,需要找到替换类或者依赖包。
C. 一些类无法访问,比如jdk.internal.misc.Unsafe,需要在对应的子moudle的pom里的maven-compiler-plugin插件configuration配置上添加--add-exports=java.base/jdk.internal.misc=ALL-UNNAMED,包括如果运行时出错,还需要在启动参数上添加上--add-opens=java.base/jdk.internal.misc=ALL-UNNAMED。
D. 其他问题,比如hbase shell中的一些warn log等,通过调整代码解决。
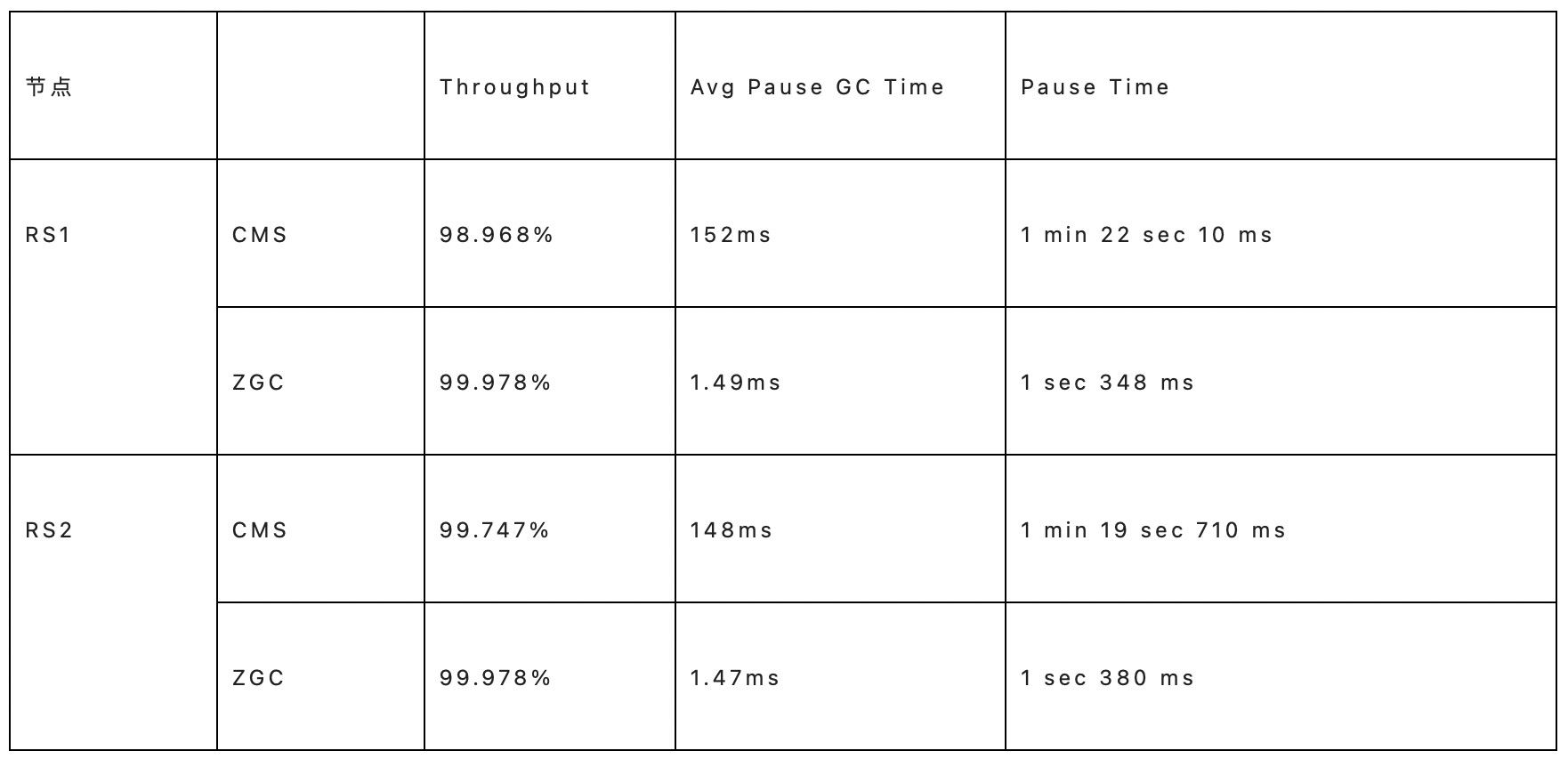
ZGC性能测试(对比CMS)
在测试集群分别应用CMS和ZGC进行压测,测试HBase集群3台服务器(1 master、2 rs),测试Client 在master节点上(避免和rs抢占系统资源,影响测试效果)
GC性能对比
考虑写入过程会memstore占用内存资源,构造写压力场景,对比GC性能。
ZGC平均GC暂停时间比CMS短了很多,总的GC暂停时间少了很多,吞吐率稍高一点。
服务性能对比
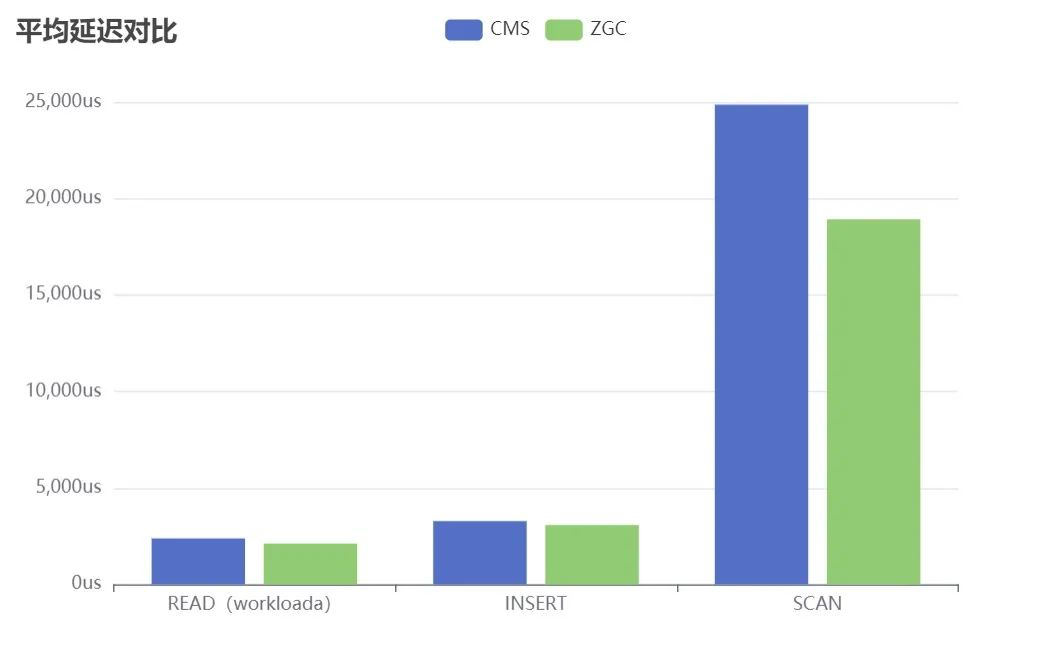
读写平均延时对比
读写吞吐量对比
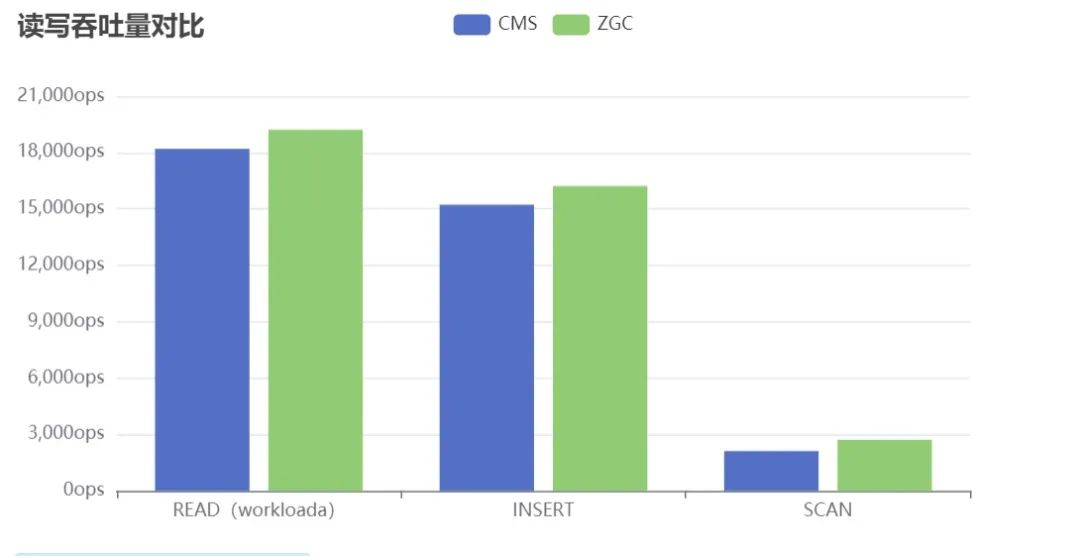
写入压测(100%WRITE): 粗略计算ZGC比CMS提升6.15%的性能。
workloada(50%WRITE,50%READ):粗略计算整体读写ZGC比CMS提升5.21%的性能, 粗略计算READ性能提升11%。
workloade(95%SCAN,5%WRITE): 粗略计算ZGC比CMS提升24%的性能。
以上测试对比结果在不同的压测场景或者不同集群环境下可能会有所不同,不代表线上真实环境上的表现情况。下面说下在线上环境应用ZGC后各方面的总结。
线上应用总结
线上HBase集群升级新版本, 应用ZGC,在个别分组上出现了请求延迟增加或过高的问题,经过不断的调优,目前线上集群的所有节点都已全部应用了ZGC。应用ZGC之后,总结下服务性能、GC性能方面应用ZGC的效果,同时也总结下遇见的问题以及解决办法。
GC性能方面效果:
文章开头介绍了一个regionserver节点的gc情况,我们那这个节点regionserver进程应用CMS和ZGC进行对比说明。
ZGC平均GC暂停时间比CMS短很多,大概为应用CMS的6.46%,总的GC暂停时间少了很多,大概为应用CMS的63%,吞吐率稍高一点。
服务性能方面效果:
一些HBase表的put或者get请求延迟方面有一定效果,升级后可以有效降低请求延迟峰值,减少延迟时间。下面会列出一部分进行说明。
1. 一张核心HBase表(公司大部分业务均在使用,请求量较高)的批量写入延迟P99 峰值减少了一些,大概为升级前76.5%。
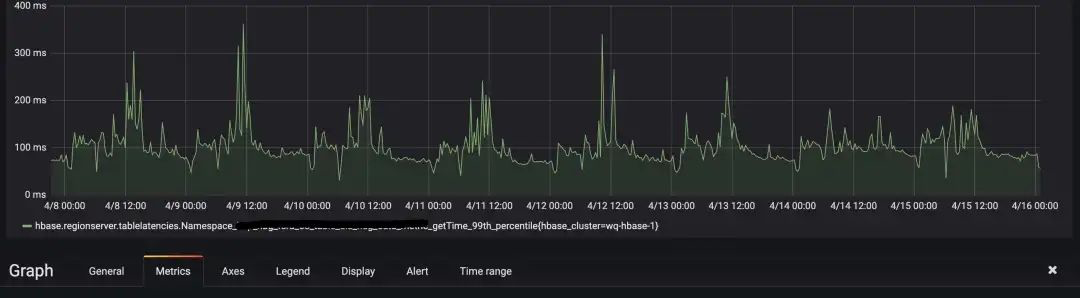
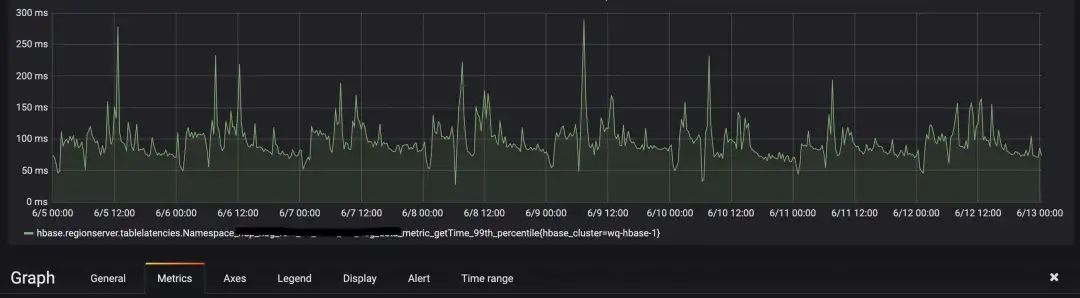
2. 对比应用ZGC前后的两个时间段,个别HBase表在读流量增长近10倍的情况下,升级应用ZGC后Get请求延迟P99相较反而更加平稳一些,耗时峰值更少一些, 如下两个截图所示。
升级前:
升级后:
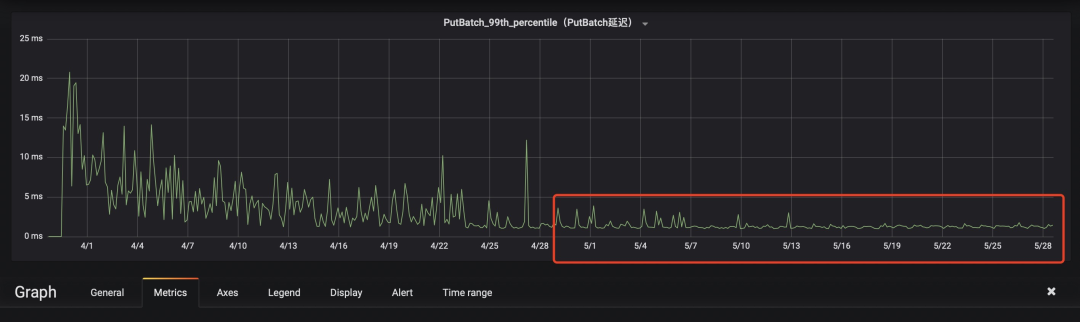
3. 个别分组下的节点应用ZGC后批量写入延迟方面效果较明显,批量写入延迟P99稳定了很多,且整体降低了很多,如下两个截图所示(图中红框标记的是升级后的监控数据):
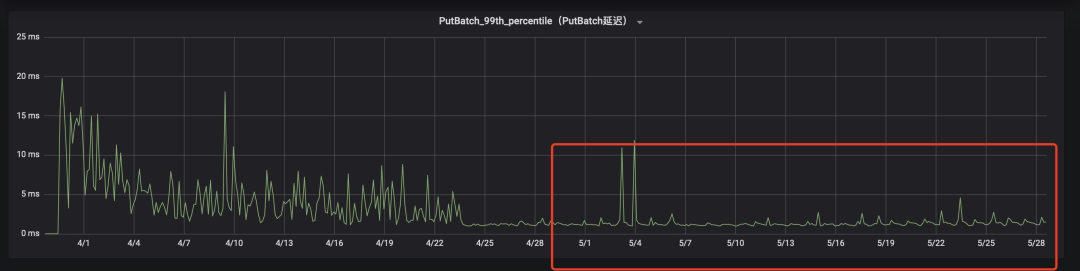
遇见的问题&解决办法
个别分组在应用ZGC后,出现了请求延迟的问题,下面列出一个分组应用ZGC后出现的问题以及解决方式
此分组请求特点分析:读写请求量较高,大部分为put写入请求。
此分组下节点应用ZGC后,出现了一些请求延迟过高的问题。经过排查是内存分配阻塞的问题(gc log中出现了一些Allocation Stall)导致请求延迟较高。继续分析gc log,发现gc的耗时几乎都在Concurrent Mark阶段。所以考虑的解决办法一般有:
A. 直接增加内存,相当于多预留一定大小的内存,可以避免或者缓解内存分配阻塞的问题。
B. 优化GC参数,加快Concurrent Mark阶段的执行速度,减少一次完整GC的执行时间,提高GC的执行效率。
调整过程:
1. 首先选择了第二种解决办法,优化GC参数,加快Concurrent Mark阶段的执行速度,同时调优了一些其他参数:
目前去掉了固定GC间隔时间参数,调高了正态分布模型预测系数ZAllocationSpikeToleranceZAllocationSpikeTolerance(默认值为2,值越大,越早的触发GC),优化后调整到了10,同时调高了ConcGCThreads参数来加快Concurrent Mark阶段的执行,ConcGCThreads参数经过几次调优后调整到了12。
2. 经过第一步调优后,发现有时还会有内存分配阻塞导致的请求延迟问题,然后调整内存大小,由-Xmx30g -Xms30g 调整到了-Xmx40g -Xms40g。
ZGC问题总结
经过具体的实践应用,结合一些技术资料,总结下ZGC的一些问题:
1. 单代GC吞吐低:最显著的问题是Concurrent Mark阶段都需要全堆标记(耗时长),导致回收速度跟不上对象分配速度
1.1 会出现分配停顿(Allocation Stall),需要启动一次新的ZGC,这次ZGC周期内所有应用线程都要暂停下来
1.2 最坏情况甚至发生OOM:Concurrent Relocate阶段如果剩余的空间依然不够,就会抛出OOM;
2. GC线程并发运行导致CPU偏高
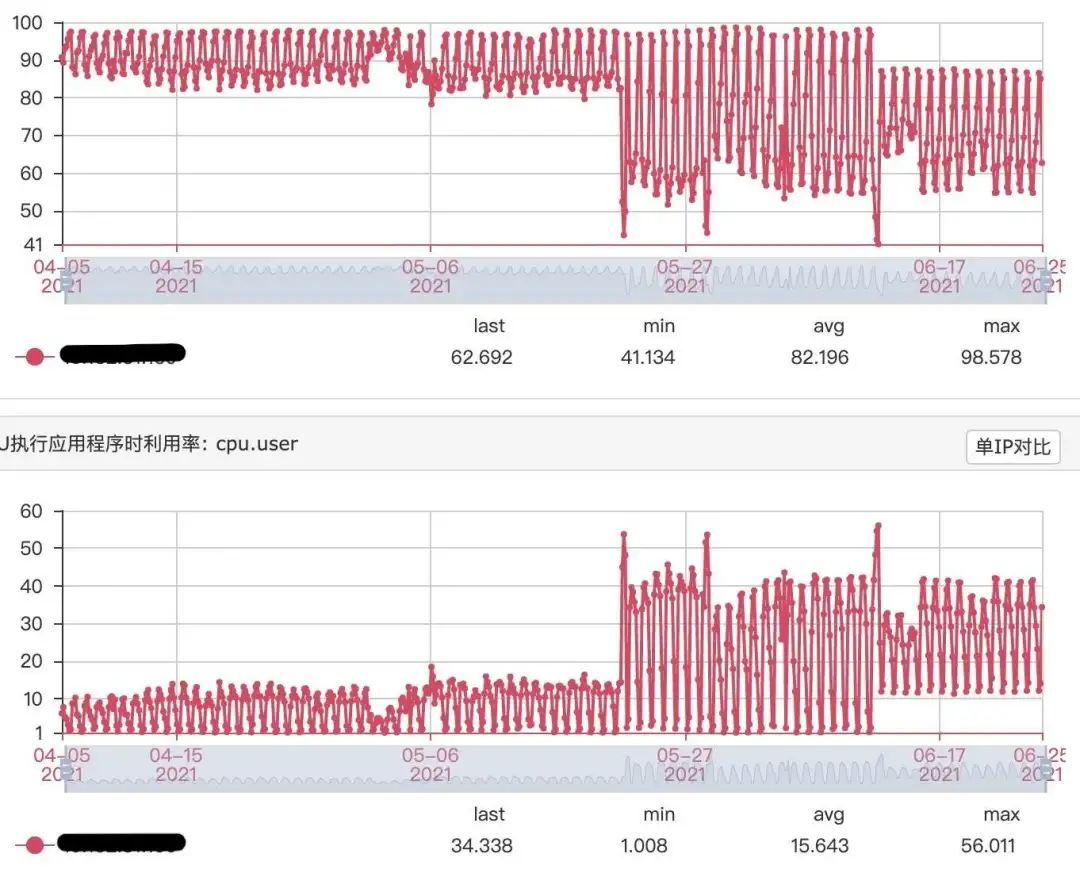
为了加快并发标记阶段的执行,避免出现内存分配阻塞问题,线上环境一些分组配置的ConcGCThreads参数大一些,比如如下统计的节点的cpu数据,cpu.user会从原来的峰值大约18.47%升高到应用ZGC时的峰值大约56.01%,大概为原来的300%。
3. 对象分配卡顿问题
4. RSS非常高问题,这是由于目前Linux内核的RSS统计对这种ZGC应用的多重映射机制(multi-mapping)考虑的不是很完整导致的。
ZGC 采用multi-mapping 实现了三份虚拟内存指向同一份物理内存,理论上在内核使用小页的Linux版本上,使用ZGC的java进程RSS会比真实占用的高出3倍,这种异常的统计会带来一定的困扰。而在内核使用大页的 Linux 版本上,有不同的表现,这部分三映射的物理内存会算在hugetlbfs inode上,而不会统计到当前 Java 进程上。
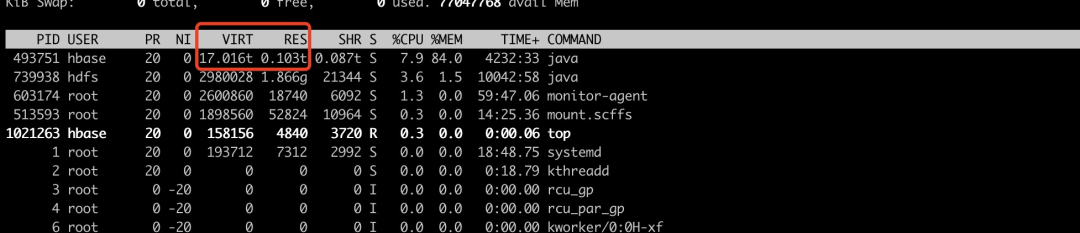
同时通过top命令查看,发下VIRT和RES高很多。
经过实践,可以说明ZGC适合大内存进程,或者对单次请求延迟耗时要求较高的场景。最好再预留一部分内存的情况下,可以有效避免内存分配阻塞的问题。
总结
本篇文章简单介绍了 ZGC 的运行流程和特点,然后简单分析了 ZGC 的一些核心技术,如着色指针、读屏障等。并在相同的 YCSB 压测场景下,分别测试了 CMS 和 ZGC 在HBase上GC 的表现能力,从 GC 停顿时间和读写吞吐、延迟等方面,做了比较详细的对比。然后又总结了在生产环境上的应用效果及问题等,HBase使用ZGC在一些场景下可以有效的降低了服务端的延时。
未来58大数据平台将会逐步地在适合的应用场景上使用ZGC,更好的服务于公司各个业务。HBase方面也会持续进行优化,提高HBase服务的SLA,在服务好离线业务的同时,未来可以逐步地扩展HBase在58在线业务方面的使用。最后推荐大家升级ZGC,ZGC作为下一代垃圾回收器,性能非常优秀,非常适合对延迟较敏感的业务场景。
参考文献:
[1] The Design of ZGC.
http://cr.openjdk.java.net/~pliden/slides/ZGC-PLMeetup-2019.pdf
[2] ZGC官网:https://wiki.openjdk.java.net/display/zgc/Main
更多思考:
本篇内容详解了ZGC的干货运用到实践,希望大家能够有所收获。更多关于JAVA实战的内容可以阅读以下内容:


